SpiderKeeper的使用
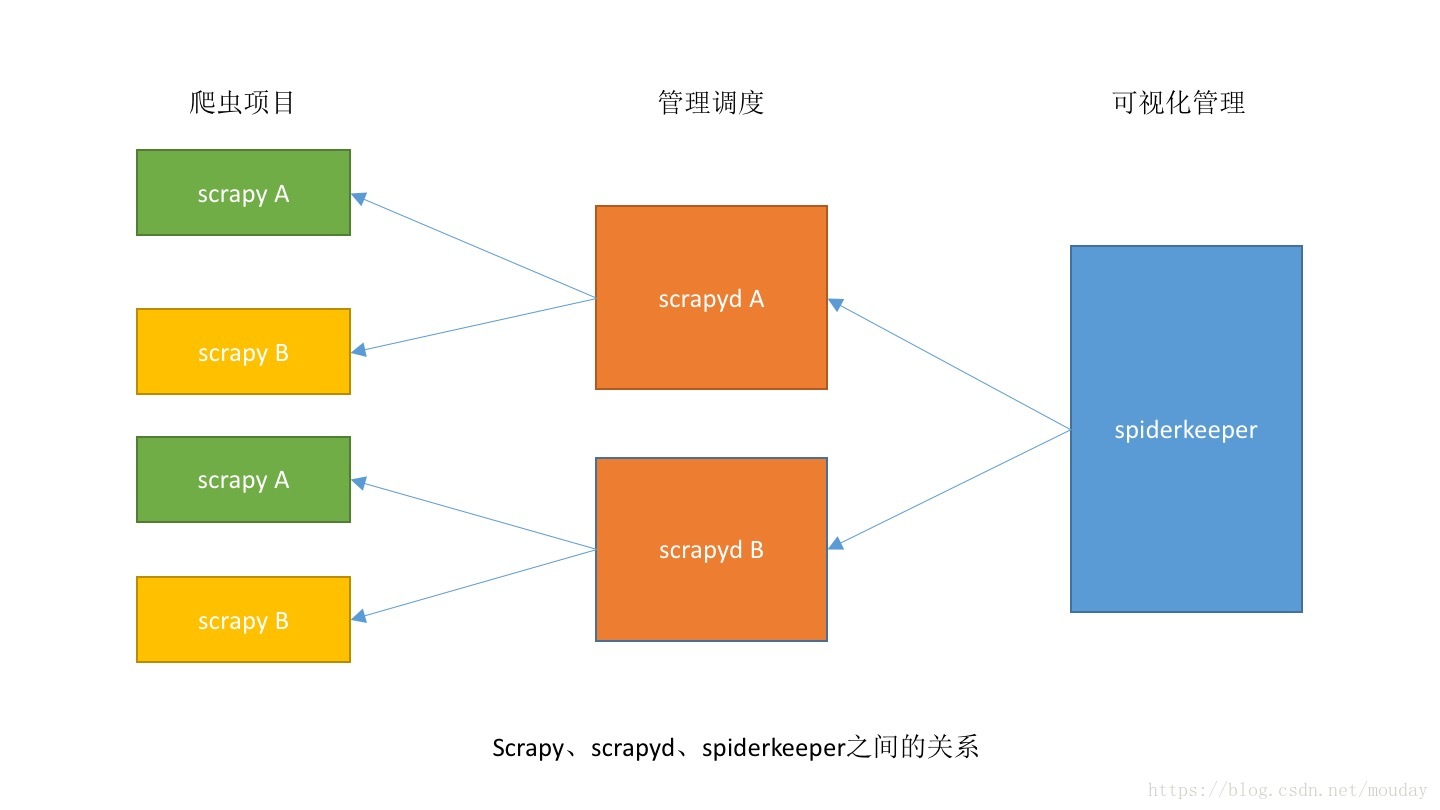
之前有一篇文章是讲解scrapyd的使用,但是scrapyd是纯命令行操作,显然很麻烦,现介绍一个开源免费使用的可视化系统。
环境准备
pip install scrapy
pip install scrapyd
pip install scrapyd-client
pip install spiderkeeper
这里作者是在Linux下配置的
新建一个文件夹,进入到文件夹后,输入scrapyd启动scrapyd服务:

然后再启动spiderkeeper,命令行输入spiderkeeper:

注:这里只介绍最简单的启动方式,带参数的自定义方法可查阅官方文档。
打开浏览器访问spiderkeeper的地址,我这里是192.168.0.101:5000,然后输入用户名、密码,默认都是admin
至此,环境准备完毕。
部署爬虫
我的爬虫程序是在自己的windows电脑上的,打开命令行进入到爬虫根目录:
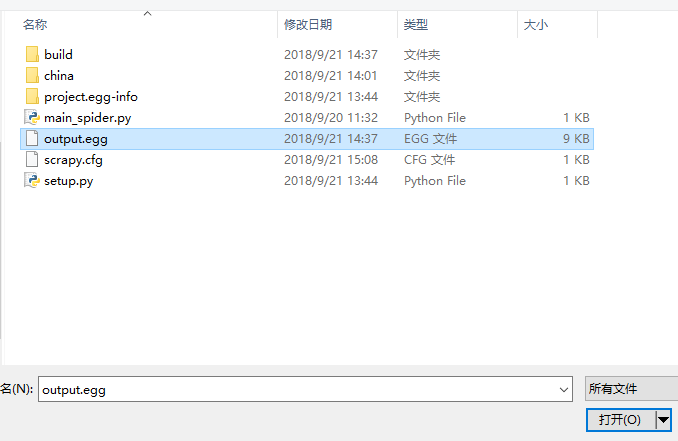
执行命令:scrapyd-deploy --build-egg output.egg生成egg文件。(这里如果不懂建议去看:Scrapyd使用教程)
然后在spiderkeeper可视化界面点击creat project:
随便输入一个名字:
点击创建,跳到这个界面:
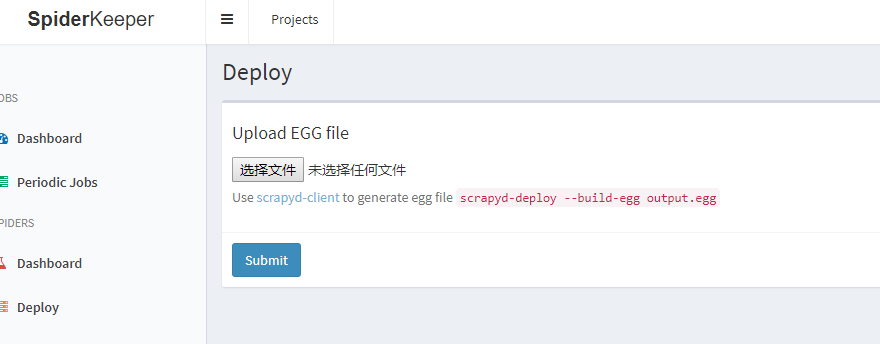
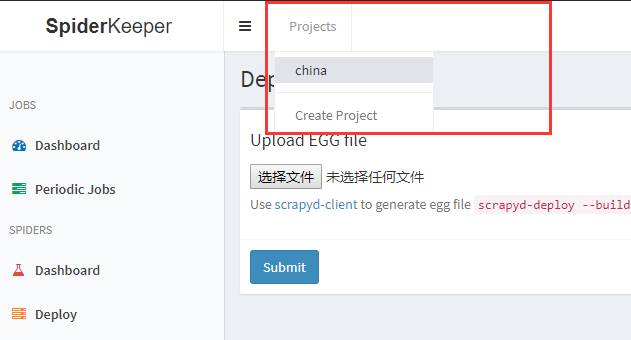
注意:此时我们系统中只有一个首次创建的名为china的项目,如果系统中已经有多个项目了,现在又建了一个,这时要先选择项目,再上传对应的egg文件,选择项目点这里:
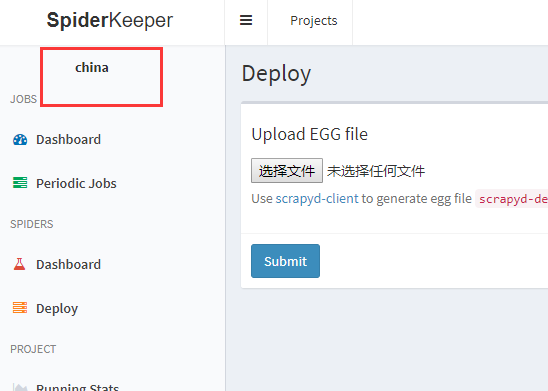
这时可以看到已经切换到china项目:
上传egg文件:
不要忘记点击提交:
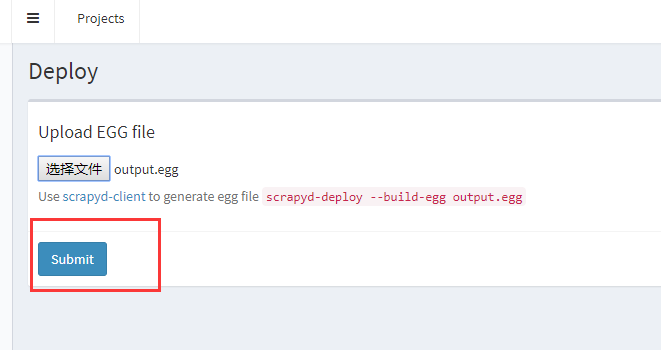
上传成功:
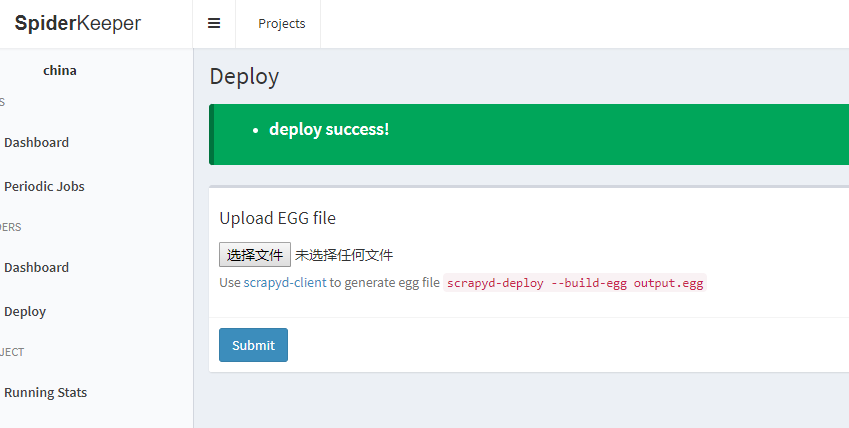
此时,部署完成。
运行爬虫
部署完后,点击 Dashboard 这个按钮,再选择 china 项目,然后点击 RunOnce 按钮创建爬虫:

这里参数都默认即可:
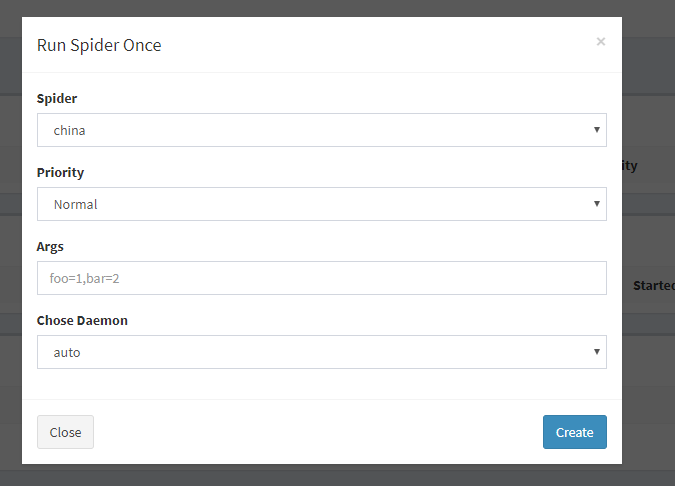
点击创建爬虫按钮:然后刷新网页,
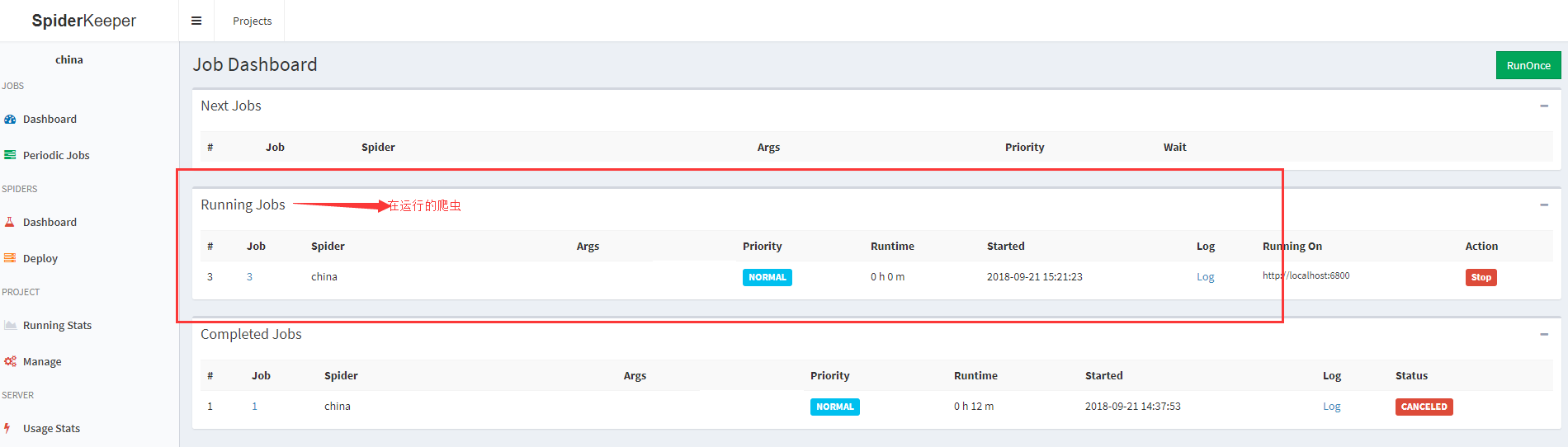
至此,爬虫运行完毕。
查看日志点 log 即可,停止爬虫点 stop 即可,其他操作请查看官方文档:https://github.com/DormyMo/SpiderKeeper。
如果本文有不懂的地方欢迎评论区留言,点赞~ 祝好~。
SpiderKeeper的使用相关推荐
- spiderkeeper 管理scrapy爬虫(定时执行)
文章目录 一.关于 spiderkeeper 安装 二.使用 1.运行 spiderkeeper 2.项目生成.egg文件 3.启动 scrapyd 三.管理项目 1.访问管理界面 2.创建项目 3. ...
- Linux环境下使用scrapyd+spiderkeeper部署scrapy爬虫
声明:本文只作学习研究,禁止用于非法用途,否则后果自负,如有侵权,请告知删除,谢谢! 项目场景: 当我们入手爬虫工作的时候,一开始可能就是几个爬虫,我们可以手动调度部署,日积月累后,可能从十个到一百个 ...
- flask 学习实战项目实例
ScrapydWeb:用于 Scrapyd 集群管理的 web 应用 Tcloud云测平台后端服务 (flask 前后端分离) SpiderKeeper:A scalable admin ui for ...
- scrapyd部署爬虫项目到LINUX服务器
1,首先把scrapy爬虫项目上传到服务器 我的服务器架设在公司内网里.所以在这里使用WinSCP作为上传工具. 2,修改项目的配置文件scrapy.cfg 给爬虫项目指定分组,具体方法是在deplo ...
- 小白也能看懂!教你如何快速搭建实用的爬虫管理平台
写在前面:本篇文章内容较多,涉及知识较广,读完需要大约 20 分钟,请读者耐心阅读. 如今大多数企业都离不开爬虫,它是获取数据的一种有效方式.但是对爬虫有着规模量级要求的企业或个人需要同时处理不同类别 ...
- 这可能是你见过的最全的网络爬虫总结
前段时间参加了一场 Python 网络爬虫主题的分享活动,主要以直播的形式分享了我从事网络爬虫相关研究以来的一些经验总结.整个分享分为三个阶段,第一阶段先介绍了自己从大学以来从事编程开发以来的相关历程 ...
- 干货下载:可能是你见过的最全的网络爬虫总结
昨天的时候我参加了一场 Python 网络爬虫主题的分享活动,主要以直播的形式分享了我从事网络爬虫相关研究以来的一些经验总结,整个直播从昨天下午 1 点一直持续到下午 5 点,整整四个小时. 整个分享 ...
- 【爬虫】从零开始使用 Scrapy
一. 概述 最近有一个爬虫相关的需求,需要使用 scrapy 框架来爬取数据,所以学习了一下这个非常强大的爬虫框架,这里将自己的学习过程记录下来,希望对有同样需求的小伙伴提供一些帮助. 本文主要从下面 ...
- 关于学术文献推荐系统的调研报告
关于学术文献推荐系统的调研报告 1 引言 1.1 研究背景 随着大数据时代的到来,互联网在给人们的生活带来丰富多彩的同时,海量信息也导致了"信息过载"问题.对于信息使用者来说,如何 ...
最新文章
- python爬图片教程_python爬去妹子网整个图片资源教程(最详细版)
- 都说 HashMap 是线程不安全的,到底体现在哪儿?
- Python二十个小技巧
- StringBuilder的toString方法
- 怎么求平均数_EXCEL怎么求企业连续几年业绩的平均增长率
- 【华为云技术分享】云小课 | SAP S/4HANA高可用之实战演练
- TensorFlow学习笔记03:单变量线性回归
- VS2010~2015番茄助手VA_X 2073 重新安装时遇到问题The security key for this program currently stored on your system
- 【三】Jmeter:测试片段
- MyEclipse Hibernate反向工程生成实体类
- OpenSesame-史上最详细教程
- 【禁忌搜索算法】基于禁忌搜索算法求解函数极值问题含Matlab源码
- 简单好用的ImageAI编程库!选择最适合你的!
- SHA-512摘要算法(带示例)
- 陈风莲(帮别人名字作诗)
- java base64转图片打不开_解决通过 Base64 解码得到的图片无法打开查看的问题
- 【计算机组织与体系结构】实验二:给定指令系统的处理器设计
- keras之权重初始化
- 图像分类竞赛——添翼杯人工智能应用创新大赛——rank4解决方案
- java 卷轴式_天堂1 java 编写活动卷轴方法
热门文章
- lsof 列出谁在使用某个端口
- linux 导出 excel文件名乱码,excel导出,文件名称中文乱码问题 · 大腿的博客
- word字体放大后只显示一半_太实用了!5个Word冷门技巧!第3个你肯定不知道!...
- w10无法连到家庭组计算机,一键W10装机版无法进入家庭组如何处理
- mysql 返回自增id_mysql 返回自增id
- 异或加密的java算法_Java使用异或运算实现简单的加密解密算法实例代码
- 西门子uss通讯实例_西门子plc1200系列的功能特点有哪些?
- java分布式_分布式锁的四种JAVA实现方式
- linux选择usb功能,USB gadget设备驱动解析(1)——功能体验
- php实验cookie,PHP实验一、二(cookie和session)