hadoop源码解析---INodeReference机制
本文主要介绍了hadoop源码中hdfs的INodeReference机制。
在hdfs2.6版本中,引入了许多新的功能,一些原有的源代码设计也有一定的改造。一个重要的更新就是引入了快照功能。但是当HDFS文件或者目录处于某个快照中,并且这个文件或者目录被重命名或者移动到其他路径时,该文件或者目录就会存在多条访问路径。INodeReference就是为了解决这个问题产生的。
问题描述
/a是hdfs中的一个普通目录,s0为/a的一个快照,在/a目录下有一个文件test。根据快照的定义,我们可以通过/a/test以及/a/snapshot/s0/test访问test文件。
但是当用户将/a/test文件重命名成/x/test1时,通过快照路径/a/snapshot/s0/test将无法访问test文件,这种情况是不符合快照规范的。
引入INodeReference
为了解决上述问题,hdfs引入了INodeReference类。图1-1给出了INodeReference的继承关系图。这里的WithName,WithCoount,DstReference都是INodeReference的子类,同时也是INodeReference的内部类。WithName对象用于替代重命名操作前源路径中的INode对象,DstReference对象则用于替代重命名操作后目标路径中的INode对象,WithName和DstReference共同指向了一个WithCount对象,WithCount对象则指向了文件系统目录树中真正的INode对象。
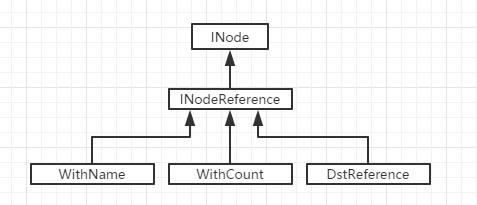
图1
INodeReference代码实现
INodeReference是一个抽象类,它拓展自INode类,所以INodeReference及其子类是可以添加到文件系统目录树中以替代原有的INodeFile节点的。INodeReference定义了referred字段,这个字段用于保存当前INodeReference类指向的INode节点,所以WithName和RstReference,referred字段就指向了WithCount对象,对于WithCount,referred指向了真正的INode对象。INodeReference还定义了getReferredINode()方法,在文件系统目录树的操作中,如果判断当前节点是一个引用节点,则会调用getReferredINode()方法获取INodeReference指向的INode对象。
public abstract class INodeReference extends INode {private INode referred;//指向的INode节点public INodeReference(INode parent,INode referred){super(parent);this.referred = referred;}public final INode getReferredINode() { //获取指向的INode节点return referred;}public final void setReferredINode(INode referred) {this.referred = referred;}//...
}然后,我们在来看看WithCount类的实现。
WithCount类定义了一个集合字段withNameList用于保存所有指向这个WithCount对象的WithName对象集合。WithCount类还定义了addReference()方法,任何指向WithCount对象的WithName对象以及DstReference对象都需要调用这个方法来添加指向关系。对于指向这个WithCount对象的DstReference对象,addReference()方法会将这个对象设置为自己的父INode节点;而对于WithName对象,addReference()方法则将这个对象放入withNameList集合中保存。
public static class WithCount extends INodeReference {//保存所有指向这个WithCount对象的WithName对象的集合private final List<WithName> withNameList = new ArrayList<WithName>();public WithCount(INodeReference parent,INode referred) {super(parent,referred); //调用父类的构造方法,指向文件系统目录树中的INodePreconditions.checkArgument(!referred.isReference());refferred.setParentReferenct(this); //设置真实INode的父节点为当前WithCount对象}public void addReferenct(INodeReference ref){if ( ref instanceof WithName) { //如果是WithName对象,则加入withNameListWithName refWithName = (WithName) ref;int i = Collections.binarySearch(withNameList, refWithName,WITHNAME_COMPARATOR);Preconditions.checkState(i<0);withNameList.add(-i-1,refWithName);} else if (ref instanceof DstReference) { //如果是DstReference对象,则设置为父节点setParentReference(ref);}}//...
}看完WithCount后,在看看WithName和DstReference。WithName类定义了name字段用于保存重命名前文件的名称,同事定义了lastSnapshotId字段用于保存WithName对象构造时源路径的快照版本号。DstReference类的实现就更简单了,只定义了一个dstSnapshotId字段用于保存重命名操作前目标路径的最新快照的版本号。WithName和DstReference在构造时都会调用父类的构造方法指向WithCount对象,同时还会调用WithCount.addReference()方法配置WithCount对象。
public static class WithName extend INodeReference {private final byte[] name;//重命名前的文件名private final int lastSnapshotId;public WithName(INodeDirectory parent,WithCount referred,bytep[] name,int lastSnapshotId){super(parent,referred); //调用父类构造方法,指向WithCount节点this.name = name;this.lastSnapshotId = lastSnapshotId;referred.addReferenct(this); //调用WithCount.addReferenct()}//...
}public static class DstReference extends INodeReference {private final int dstSnapshotId;public DstReference (INodeDirectory parent,WithCount referred,final int dstSnapshotId){super(parent,referred);this.lastSnapshotId = lastSnapshotId;referred.addReferenct(this); //调用WithCount.addReferenct()}//..
}转载于:https://blog.51cto.com/xlows/1811689
hadoop源码解析---INodeReference机制相关推荐
- Hadoop源码解析之: TextInputFormat如何处理跨split的行
Hadoop源码解析之: TextInputFormat如何处理跨split的行 转载于:https://blog.51cto.com/taikongren/1742425
- 源码解析——消息机制
映象笔记的链接:源码解析--消息机制 本文转自wauoen51CTO博客,原文链接: http://blog.51cto.com/7183397/1968269,如需转载请自行联系原作者
- Hadoop源码解析
一.hadoop的Job 提交流程源码 流程图: 1.从我们编写的mapreduce的代码中进入job提交源码 支线一:进入connect(); 2.支线二:进入submitter.submitJob ...
- Dubbo源码解析-——SPI机制
文章目录 一.什么是SPI机制 二.Java原生的SPI机制 2.1.javaSPI示例 2.1.1.编写接口和实现类 2.1.2.编写配置文件 2.1.3.通过SPI机制加载实现类 2.1.4.JA ...
- Set接口的源码解析+扩容机制
Set集合 Set的接口介绍 无序(添加和需要的顺序是不一样的)没有索引 不允许重复元素,所以最多包含一个null 添加和取出的顺序是不固定的. 虽然不是添加的顺序,但是顺序是固定的 Set的常用方法 ...
- Storm的BaseBasicBolt源码解析ack机制
我们在学习ack机制的时候,我们知道Storm的Bolt有BaseBasicBolt和BaseRichBolt. 在BaseBasicBolt中,BasicOutputCollector在emit数据 ...
- Hadoop源码解析之Mapper数量计算公式
前言 据说,自0.20.0版本开始,Hadoop同时提供了新旧两套MapReduce API,并在后续版本中也同时支持这两种API的使用.新版本MR API在旧的基础进行了扩展,也制定了新的split ...
- dubbo源码解析-SPI机制
SPI,Service Provider Interface,服务提供者接口,是一种服务发现机制. JDK 的 SPI 规范 JDK 的 SPI 规范规定: 接口名:可随意定义 实现类名:可随 ...
- 筑基期第一式:SpringMVC源码解析
文章目录 SpringMVC源码解析 SPI机制 案例 SpringMVC中SPI的使用 初始化IOC容器与九大组件 初始化容器 初始化九大组件 小结 SpringMVC如何处理一个请求 doDisp ...
最新文章
- android 虚拟机快捷键中英列表
- NoSQL(1)之 Redis的五大数据类型使用方法的详细介绍
- 在WPF程序中使用多线程技术
- Java当中TreeMap用法
- Docker 制作自定义化的Tomcat镜像
- 直接在安装了redis的Linux机器上操作redis数据存储类型--hash类型
- web应用的跨域访问解决方案
- 汉王考勤机管理系统服务器,汉王考勤管理系统7
- sql 2008 R2 备份和还原
- Seat分布式事务学习
- 第十四章 ESP32 新建一个WIFI热点
- windows+Texstudio+languagetool修改语法错误
- 桌面图标icon替换客制图标。图标要比原始图标大,要求一致。应用图标去掉四周白边,保持原有比例。
- Windows电脑内存不足解决问题
- 51单片机和315M无线发射模块编码与解码
- 从零搭建移动H5开发项目实战
- HBuilder git使用教程
- javah命令详解与idea使用javah一键编译JNI的.头文件
- 64位系统下同时使用64位和32位的eclipse
- JSON 与 XML 对比
热门文章
- ImageIO 框架详细解析
- 随便玩玩系列之一:SPOJ-RNG+51nod 算法马拉松17F+51nod 1034 骨牌覆盖v3
- CentOS 开机自启动配置方法
- 文件上传input简便美化方案
- 360私有云平台Elasticsearch服务初探
- 求出所有这些四位数是素数的个数cnt,再把所有满足此条件的四位数依次存入数组b中,然后对数组b中的四位数按从小到大的顺序进行排序
- RocketMQ源码解析-PullConsumer取消息(2)
- linux socket 加锁,Linux使用openssl对socket加密【1】
- Dubbo项目基本业务基础构建
- SourceTree的基本使用 - 天字天蝎 - 博客园