KMP算法详解 转帖
个人觉得这篇文章是网上的介绍有关KMP算法更让人容易理解的文章了,确实说得很“详细”,耐心地把它看完肯定会有所收获的~~,另外有关模式函数值next[i]确实有很多版本啊,在另外一些面向对象的算法描述书中也有失效函数 f(j)的说法,其实是一个意思,即next[j]=f(j-1)+1,不过还是next[j]这种表示法好理解啊:
KMP字符串模式匹配详解
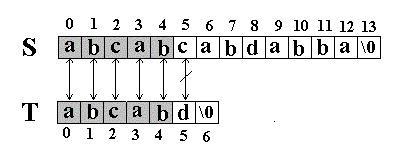
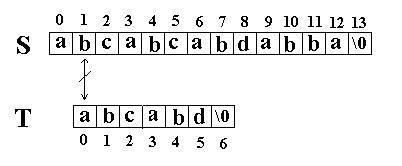
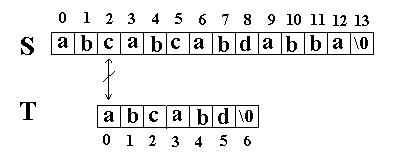
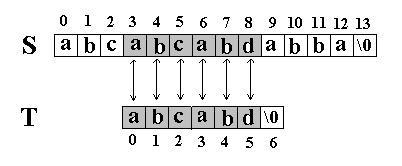
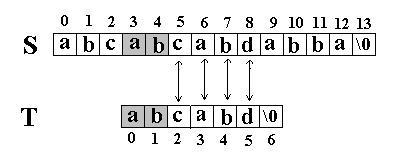
此算法的思想是直截了当的:将主串 S 中某个位置 i 起始的子串和模式串 T 相比较。即从 j=0 起比较 S[i+j] 与 T[j] ,若相等,则在主串 S 中存在以 i 为起始位置匹配成功的可能性,继续往后比较 ( j 逐步增 1 ) ,直至与 T 串中最后一个字符相等为止,否则改从 S 串的下一个字符起重新开始进行下一轮的 " 匹配 " ,即将串 T 向后滑动一位,即 i 增 1 ,而 j 退回至 0 ,重新开始新一轮的匹配。
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
a
|
c
|
|
next
|
-1
|
0
|
0
|
-1
|
1
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
a
|
b
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
T
|
a
|
b
|
a
|
b
|
c
|
a
|
a
|
b
|
c
|
|
next
|
-1
|
0
|
-1
|
0
|
2
|
-1
|
1
|
0
|
2
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
b
|
C
|
a
|
b
|
C
|
a
|
d
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
4
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
d
|
C
|
a
|
d
|
C
|
a
|
d
|
|
next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
0
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
|
T
|
a
|
b
|
a
|
b
|
c
|
a
|
a
|
b
|
c
|
|
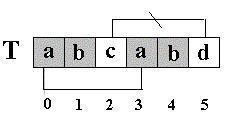
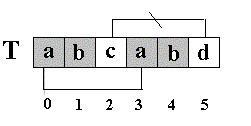
(1) next
|
-1
|
0
|
-1
|
0
|
2
|
-1
|
1
|
0
|
2
|
|
(2) next
|
-1
|
0
|
0
|
1
|
2
|
0
|
1
|
1
|
2
|
|
(3) next
|
0
|
1
|
0
|
1
|
3
|
0
|
2
|
1
|
3
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
|
T
|
a
|
b
|
c
|
A
|
c
|
|
(1)next
|
-1
|
0
|
0
|
-1
|
1
|
|
(2)next
|
-1
|
0
|
0
|
0
|
1
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
|
T
|
a
|
d
|
C
|
a
|
d
|
C
|
a
|
d
|
|
(1)next
|
-1
|
0
|
0
|
-1
|
0
|
0
|
-1
|
0
|
|
(2)next
|
-1
|
0
|
0
|
0
|
1
|
2
|
3
|
4
|
KMP算法详解 转帖相关推荐
- KMP算法详解及各种应用
KMP算法详解: KMP算法之所以叫做KMP算法是因为这个算法是由三个人共同提出来的,就取三个人名字的首字母作为该算法的名字.其实KMP算法与BF算法的区别就在于KMP算法巧妙的消除了指针i的回溯问题 ...
- 字符串匹配之KMP算法详解
kmp算法又称"看毛片"算法,是一个效率非常高的字符串匹配算法.不过由于其难以理解,所以在很长的一段时间内一直没有搞懂.虽然网上有很多资料,但是鲜见好的博客能简单明了地将其讲清楚. ...
- KMP算法详解P3375 【模板】KMP字符串匹配题解
KMP算法详解: KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt(雾)提出的. 对于字符串匹配问题(such as 问你在abababb中有多少个 ...
- KMP算法详解及代码
KMP算法详解及代码 KMP算法详解及代码 定义及应用 理论 基本概念 next 数组 总结 注意 代码 KMP算法详解及代码 最近正好在看字符串相关的算法内容,就顺便把KMP算法回顾了一下.相应的代 ...
- 奇淫巧技的KMP算法--详解
奇淫巧技的KMP算法–详解 花了一下午时间,看了十几个博客,终于拿下了KMP高地,现在总结下下自己对KMP的理解和实现. 情景1 假如你是一名生物学家,现在,你的面前有两段 DNA 序列 S 和 T, ...
- KMP 算法详解(CPP 实现)
转载请标明出处:https://blog.csdn.net/kiss0tql/article/details/81416283 本文来自:deemo的博客 说明 kmp 算法思想 next 数组计算 ...
- 【KMP算法详解——适合初学KMP算法的朋友】
相信很多人(包括自己)初识KMP算法的时候始终是丈二和尚摸不着头脑,要么完全不知所云,要么看不懂书上的解释,要么自己觉得好像心里了解KMP算法的意思,却说不出个究竟,所谓知其然不知其所以然是也. 经过 ...
- 【转】KMP算法详解
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任. http://billhoo.blog.51cto.com/2337751/411486 ...
- [数据结构]模式匹配算法--KMP算法详解
目录 一. 模式匹配 二. 模式匹配算法 1. 朴素模式匹配算法 2. KMP算法 1). KMP算法的优势 2). KMP算法的原理 3). next数组的构造 4). 利用next数组匹配的过程 ...
最新文章
- vue中弹窗input框聚焦_Vue 中如何让 input 聚焦?(包含视频讲解)
- 6.OSI七层网络模型与TCP/IP四层网络模型
- 只能匹配第一列吗_VLOOKUP会用了吗?不会的抓紧看
- thrift介绍及应用(二)—简单应用
- python文件路径改了需要重新配置环境吗_Django 设置多环境配置文件载入问题
- Android的Broadcase的使用(读取短信和创建通知)
- Java毕业设计-医院药品管理系统
- 热炉法则:规章制度面前人人平等 | 每天成就更大成功
- php用户注册审核,php 之 注册审核(0523)
- 可移动磁盘双击打不开怎么办
- 微信公众号文章阅读数和点赞数采集接口
- 【边缘计算】刘阳:边缘计算发展中的若干热点问题及思考
- Emacs指北(做一个搬运工好累)
- Only the original thread that created a view hierarchy can touch its views. 是怎么产生的
- 2022:RadiAnt DICOM Viewer-PC+CD[U盘]
- HTML常用标签或属性 英文全称和中文释义
- 上游模式用于实验室用冷冻机压力和真空度的高精度控制
- Unity_太阳月亮地球的自转公转脚本
- Kubernetes网络与CNI插件介绍
- 金蝶EAS BOS F7按钮自定义弹窗