11203 RAC(asm)恢复一例
|
1
2
3
4
5
6
7
8
9
|
Thu May 08 20:51:07 2014
Dumping diagnostic data in directory=[cdmp_20140508205107], requested by (instance=1, osid=13828272), summary=[incident=77085].
Abort recovery for domain 0
Aborting crash recovery due to error 354
Errors in file /oracle/db/diag/rdbms/hiatmpdb/hiatmpdb1/trace/hiatmpdb1_ora_13828272.trc:
ORA-00354: corrupt redo log block header
ORA-00353: log corruption near block 67856 change 13820540000932 time 05/08/2014 13:12:44
ORA-00312: online log 3 thread 2: '+DATA/hiatmpdb/onlinelog/group_3.269.830653613'
ORA-00312: online log 3 thread 2: '+DATA/hiatmpdb/onlinelog/group_3.268.830653613'
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
=====================
PARSING IN CURSOR #4574130432 len=142 dep=1 uid=0 oct=3 lid=0 tim=237352129855 hv=361892850 ad='700000160cd5178' sqlid='7bd391hat42zk'
select /*+ rule */ name,file#,block#,status$,user#,undosqn,xactsqn,scnbas,scnwrp,DECODE(inst#,0,NULL,inst#),ts#,spare1 from undo$ where us#=:1
END OF STMT
PARSE #4574130432:c=9,e=14,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=3,plh=4258302260,tim=237352129854
BINDS #4574130432:
Bind#0
oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00
oacflg=08 fl2=0001 frm=00 csi=00 siz=24 off=0
kxsbbbfp=110a3acb8 bln=22 avl=02 flg=05
value=3
EXEC #4574130432:c=47,e=88,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=3,plh=4258302260,tim=237352130029
FETCH #4574130432:c=8,e=13,p=0,cr=2,cu=0,mis=0,r=1,dep=1,og=3,plh=4258302260,tim=237352130065
STAT #4574130432 id=1 cnt=1 pid=0 pos=1 obj=15 op='TABLE ACCESS BY INDEX ROWID UNDO$ (cr=2 pr=0 pw=0 time=10 us)'
STAT #4574130432 id=2 cnt=1 pid=1 pos=1 obj=34 op='INDEX UNIQUE SCAN I_UNDO1 (cr=1 pr=0 pw=0 time=5 us)'
CLOSE #4574130432:c=3,e=5,dep=1,type=1,tim=237352130125
PARSE #4574130432:c=5,e=9,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=3,plh=4258302260,tim=237352130158
BINDS #4574130432:
Bind#0
oacdty=02 mxl=22(22) mxlc=00 mal=00 scl=00 pre=00
oacflg=08 fl2=0001 frm=00 csi=00 siz=24 off=0
kxsbbbfp=110a3ab88 bln=22 avl=02 flg=05
value=4
EXEC #4574130432:c=44,e=71,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=3,plh=4258302260,tim=237352130278
FETCH #4574130432:c=7,e=12,p=0,cr=2,cu=0,mis=0,r=1,dep=1,og=3,plh=4258302260,tim=237352130308
CLOSE #4574130432:c=2,e=3,dep=1,type=3,tim=237352130335
WAIT #4573319128: nam='db file sequential read' ela= 6947 file#=3 block#=176 blocks=1 obj#=0 tim=237352137334
DDE rules only execution for: ORA 1110
----- START Event Driven Actions Dump ----
---- END Event Driven Actions Dump ----
----- START DDE Actions Dump -----
Executing SYNC actions
----- START DDE Action: 'DB_STRUCTURE_INTEGRITY_CHECK' (Async) -----
Successfully dispatched
----- END DDE Action: 'DB_STRUCTURE_INTEGRITY_CHECK' (SUCCESS, 0 csec) -----
Executing ASYNC actions
----- END DDE Actions Dump (total 0 csec) -----
WAIT #4573319128: nam='control file sequential read' ela= 258 file#=0 block#=1 blocks=1 obj#=0 tim=237352138057
WAIT #4573319128: nam='control file sequential read' ela= 205 file#=1 block#=1 blocks=1 obj#=0 tim=237352138319
WAIT #4573319128: nam='control file sequential read' ela= 190 file#=0 block#=40 blocks=1 obj#=0 tim=237352138539
WAIT #4573319128: nam='control file sequential read' ela= 251 file#=0 block#=42 blocks=1 obj#=0 tim=237352138818
WAIT #4573319128: nam='control file sequential read' ela= 192 file#=0 block#=48 blocks=1 obj#=0 tim=237352139044
WAIT #4573319128: nam='control file sequential read' ela= 255 file#=0 block#=113 blocks=1 obj#=0 tim=237352139328
WAIT #4573319128: nam='KSV master wait' ela= 1 p1=0 p2=0 p3=0 obj#=0 tim=237352139400
Byte offset to file# 3 block# 176 is unknown
Incident 115456 created, dump file: /oracle/db/diag/rdbms/hiatmpdb/hiatmpdb1/incident/incdir_115456/hiatmpdb1_ora_12583082_i115456.trc
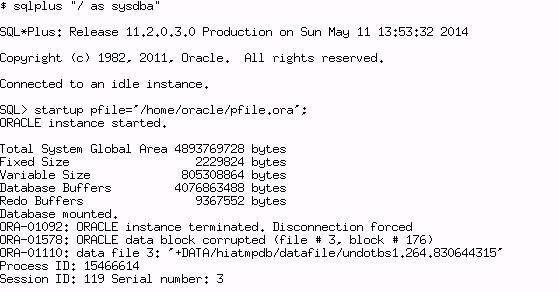
ORA-01578: ORACLE data block corrupted (file # 3, block # 176)
ORA-01110: data file 3: '+DATA/hiatmpdb/datafile/undotbs1.264.830644315'
ORA-01578: ORACLE data block corrupted (file # 3, block # 176)
ORA-01110: data file 3: '+DATA/hiatmpdb/datafile/undotbs1.264.830644315'
ORA-01578: ORACLE data block corrupted (file # 3, block # 176)
ORA-01110: data file 3: '+DATA/hiatmpdb/datafile/undotbs1.264.830644315'
|
|
1
2
3
4
5
|
alter session set "_smu_debug_mode" = 4;
alter rollback segment "_SYSSMU3_83481414$" offline;
drop rollback segment "_SYSSMU3_83481414$" ;
alter rollback segment "_SYSSMU4_2115859630$" offline;
drop rollback segment "_SYSSMU4_2115859630$" ;
|
|
1
2
3
4
5
6
7
8
9
10
11
|
continued from file: /oracle/db/diag/rdbms/hiatmpdb/hiatmpdb2/trace/hiatmpdb2_ora_13959382.trc
ORA-01578: ORACLE 数据块损坏 (文件号 97, 块号 373505)
ORA-01110: 数据文件 97: '+DATA/hiatmpdb/datafile/hiatmpts_in06.dbf'
========= Dump for incident 197185 (ORA 1578) ========
*** 2014-05-11 16:38:55.665
dbkedDefDump(): Starting incident default dumps (flags=0x2, level=3, mask=0x0)
----- Current SQL Statement for this session (sql_id=47bt6vfv19g6z) -----
select t.nid ,t.cpic1path,t.cpic2path from HIATMP.DETECT_SPEED_DATA_EHL_EXTEND t where t.cdevicecode like '%44900100000001%' and row
num < 200
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
** 2014-05-11 18:51:21.074
Start dump data blocks tsn: 6 file#:97 minblk 373505 maxblk 373505
Block dump from cache:
Dump of buffer cache at level 4 for tsn=6 rdba=407220993
BH (0x70000012ef08528) file#: 97 rdba: 0x1845b301 (97/373505) class: 8 ba: 0x70000012e5fe000
set: 33 pool: 3 bsz: 8192 bsi: 0 sflg: 2 pwc: 1575,18
dbwrid: 0 obj: 90762 objn: 90762 tsn: 6 afn: 97 hint: f
hash: [0x700000157972b00,0x700000157972b00] lru: [0x70000012ef09348,0x70000012ef091d0]
ckptq: [NULL] fileq: [NULL] objq: [0x70000012ef087b0,0x70000014153f8a0] objaq: [0x70000012ef087c0,0x70000014153f890]
st: SCURRENT md: NULL fpin: 'ktspfwh13: ktspGetNextL1ForScan' tch: 4 le: 0x700000043fd8780
flags: auto_bmr_tried
LRBA: [0x0.0.0] LSCN: [0x0.0] HSCN: [0xffff.ffffffff] HSUB: [65535]
Block dump from disk:
buffer tsn: 6 rdba: 0x1845b301 (97/373505)
scn: 0x0c91.d8604ed8 seq: 0xff flg: 0x04 tail: 0x4ed845ff
frmt: 0x02 chkval: 0xcafb type: 0x45=NGLOB: Lob Extent Header
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x0000000110AEA800 to 0x0000000110AEC800
110AEA800 45A20000 1845B301 D8604ED8 0C91FF04 [E....E...`N.....]
110AEA810 CAFB0000 B9138F29 9DC40000 05B6CCDA [.......)........]
|
11203 RAC(asm)恢复一例相关推荐
- oracle asm spfile丢失,Oracle 11g RAC ASM磁盘全部丢失后的恢复
Oracle 11g RAC ASM磁盘全部丢失后的恢复,Oracle 11.2.0.3 RAC ON Oracle Linux 6 x86_64,只有一个ASM外部冗余磁盘组mdash;m 一.环境 ...
- Oracle RAC ASM disk header 备份 恢复 与 重建 示例说明
一. 准备知识 RAC ASM由于其高度的封装性,使得我们很难知道窥探其内部的原理.ASM如果一旦出现问题,通常都很难处理.即便在有很完备的RMAN备份的情况下,恢复起来都可能需要很长的时间. 而AS ...
- 【Oracle RAC+DG实验】Oracle RAC+ASM+DataGuard配置实验记录+常见问题
[Oracle RAC+DG实验]Oracle RAC+ASM+DataGuard配置实验记录+常见问题 1.环境规划: ---RAC环境介绍(primary database) ...
- RAC数据库恢复到单实例数据库
RAC数据库恢复到单实例数据库的基本步骤如下: a.准备单实例服务器,pfile文件,启动到nomount b.备份rac数据库 c.将备份文件拷贝到单实例服务器 d.在单实例服务器上还原.恢复 e. ...
- 用Shell脚本在推出的RAC节点上批量部署32个Oracle11gR2 RAC备份恢复案例场景的方法PART2...
8.11 9d_当前控制文件损坏_只读user表空间完全恢复_用控制文件脚本_不需备份 在PXE推送端主机上运行: [root@server1 ~]# bcl --RACGRID11g13 9d 场景 ...
- oracle没用过元数据,案例:Oracle RAC asm备份元数据之md_backup和md_restore 好处与
天萃荷净 Oracle rAC asm备份元数据之md_backup和md_restore好处与坏处 在11g的asm中增加了md_backup和md_restore命令,用来备份和还原asm的元数据 ...
- oracle 11.2.0.3 asm非rac双机,oracle11.2.0.4 rac asm启动故障
现场人员反映一套库启动失败,集群资源启动失败,发截图和日志过来分析 分析日志后发现: ASM没有启动 OCR等不能启动 问题1: 2018-05-08 11:59:39.980: [? OCRASM] ...
- 在Linux 6上使用UDEV解决RAC ASM存储设备名问题
Maclean一直是使用UDEV替代ASMLIB做RAC存储设备名绑定的拥护者,相关的专题文章可以作为读者的预读知识是: Why ASMLIB and why not? 利用UDEV服务解决RAC A ...
- Oracle 11g RAC ASM 错误之(1)
Oracle 11g RAC ASM 错误之(1) 系统环境: 操作系统:RedHat EL5.5 集群软件: GI (11.2.0.1) 数据库软件:Oracle 11g(11.2.0.1) 故障 ...
最新文章
- SCRIPT LOAD lua文件
- Everyday a English
- 服务器硬件及RAID配置
- ubuntu下Samba服务器的搭建
- DOS下从硬盘安装XP系统方法与要点
- 合法整数集(51Nod-1315)
- linux 日志乱码_这些 Linux 技巧大大提高你的工作效率
- MVC4 数据验证、特性、自动属性总结
- vscode 格式化某一段代码_vscode 如何自动格式化代码?
- vijos1846 [NOIP2013] 华容道【最短路】
- 大学计算机实验vfp,Visual FoxPro程序设计上机实验(第2版)
- 标准正态分布表(scipy.stats)
- SAP MTO生产模式和计划策略组
- 制作一个网站需要工具, 步骤
- MikroTik路由器配置
- Ext Gantt甘特图1.2破解及方法
- Aspose.word设置页眉
- Mybatis中如何实现一对一,一对多的关联查询?
- 计算机维修工技能培训课程,计算机维修工基本技能培训大纲.doc
- Gateway—网关服务