决策树入门【西瓜书】
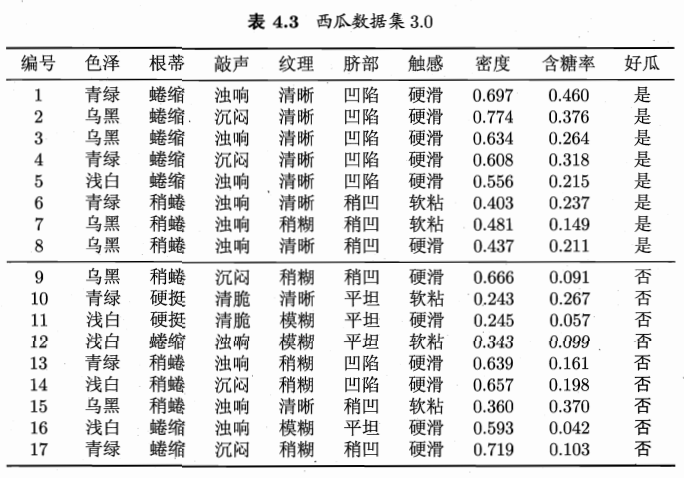
当一个有经验的老农看一个瓜是不是好瓜时,他可能会先看下瓜的颜色,一看是青绿的,心想有可能是好瓜;接着他又看了下根蒂,发现是蜷缩着的,老农微微点头,寻思着五成以上是好瓜;最后他又敲了下瓜,一听发出浑浊的响声,基本确定这个瓜是个好瓜!
决策树便是模拟“老农判瓜”的过程,通过对属性的层层筛选从而得到当前样本的分类。
可是,问题在于,老农判瓜依据的是其多年判瓜经验,计算机如何获得这些“识瓜经验”呢?又如何知道哪些属性是更为重要的属性呢?这便是实现决策树需要解决的重要问题。
信息熵
信息熵是度量样本集合纯度最常用的一种指标,信息熵 E n t ( D ) Ent(D) Ent(D) 的值越小,则样本 D D D 的纯度越高【即越有序,比如 D D D 中全是好瓜,则其信息熵就会很小】
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D)=-\sum_{k=1}^{\vert y\vert}p_klog_2p_k\\ Ent(D)=−k=1∑∣y∣pklog2pk
其中 ∣ y ∣ \vert y\vert ∣y∣ 是分类个数,如最终分类为好瓜/坏瓜,则 ∣ y ∣ \vert y\vert ∣y∣ 为 2 2 2; D D D 为样本集,在训练数据时即为整个训练集 p k p_k pk 即在样本 D D D 中分类为 k k k 的可能性
信息增益
假定离散属性 a a a 有 V V V个可能的取值 { a 1 , a 2 , . . , a V } \{a^1,a^2,..,a^V\} {a1,a2,..,aV} 【如色泽可以为青绿,乌黑,浅白】,若使用 a a a 来对样本集合 D D D 进行划分,则会产生 V V V 个分支结点【如色泽会分为三部分】,其中第 v v v 个分支节点包含了 D D D 中所有在属性 a a a 上取值为 a v a^v av 的样本,记为 D v D^v Dv 【如色泽乌黑的样本】。
我们可以根接新的样本集计算出新的信息熵【注意:信息熵的 k k k 对应的是分类,即好瓜与坏瓜】,再考虑到不同的分支结点所包含样本数不同,给分支结点赋予权重 ∣ D v ∣ ∣ D ∣ \dfrac{\vert D^v\vert}{\vert D\vert} ∣D∣∣Dv∣ 【如色泽乌黑的瓜在所有瓜中的比重】,即样本数越多的分支节点造成的影响越大。
由此可以计算出用属性 a a a 对样本集 D D D 进行划分所获得的信息增益
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum_{v=1}^{V}\dfrac{\vert D^v \vert}{\vert D \vert}Ent(D^v)\\ Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
一般而言,信息增益越大,则意味着使用属性 a a a 来进行划分所获得的纯度提升越大,因此我们可以使用信息增益来进行决策树的划分属性选择,著名的 I D 3 ID3 ID3 算法就是以信息增益为准则来选择划分属性

西瓜书 P 75 P75 P75 页中通过信息增益选择了纹理作为第一个节点
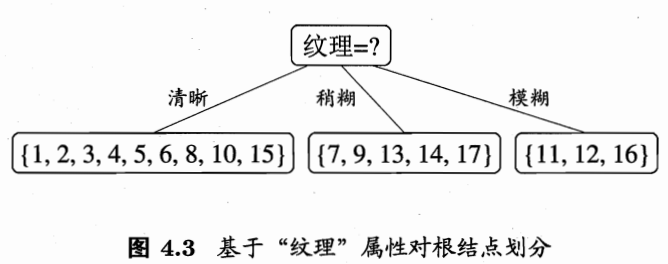
在选择了纹理属性后,接下来在纹理清晰这一分支中应该选择哪一属性继续划分,即计算各个属性在此分支的信息增益,此处以色泽属性为例,演示如何得到西瓜书 P 77 P77 P77 的 G a i n ( D 1 , c o l o r s ) = 0.043 Gain(D^1,colors)=0.043 Gain(D1,colors)=0.043,为避免上标下标混淆,下边 D 1 D_1 D1 代表纹理为清晰的样本集, D v D^{v} Dv 代表在纹理清晰的情况下,色泽 c o l o r s colors colors 属性为 v v v 的样本集
如下是已知纹理清晰的情况下,对属性色泽 c o l o r s colors colors 进一步进行决策,求此时的信息增益
G a i n ( D 1 , c o l o r s ) = E n t ( D 1 ) − ∑ v = 1 3 ∣ D v ∣ ∣ D 1 ∣ E n t ( D v ) Gain(D_1,colors)=Ent(D_1)-\sum_{v=1}^{3}\dfrac{\vert D^v \vert}{\vert D_1\vert}Ent(D^v)\\ Gain(D1,colors)=Ent(D1)−v=1∑3∣D1∣∣Dv∣Ent(Dv)
色泽 c o l o r s colors colors 有 3 3 3 种取值,所以 v v v 最大值为 3 3 3 ; D v D^v Dv 代表色泽属性值为 v v v 的样本集
∴ E n t ( D 1 ) = − ( 7 9 l o g 2 7 9 + 2 9 l o g 2 2 9 ) = 0.7642 E n t ( D 1 ) = − ( 3 4 l o g 2 3 4 + 1 4 l o g 2 1 4 ) = 0.8113 E n t ( D 2 ) = − ( 3 4 l o g 2 3 4 + 1 4 l o g 2 1 4 ) = 0.8113 E n t ( D 3 ) = − ( 1 1 l o g 2 1 1 + 0 1 l o g 2 0 1 ) = 0 \therefore Ent(D_1)=-(\dfrac{7}{9}log_2\dfrac{7}{9}+\dfrac{2}{9}log_2\dfrac{2}{9})=0.7642\\ Ent(D^1)=-(\dfrac{3}{4}log_2\dfrac{3}{4}+\dfrac{1}{4}log_2\dfrac{1}{4})=0.8113\\ Ent(D^2)=-(\dfrac{3}{4}log_2\dfrac{3}{4}+\dfrac{1}{4}log_2\dfrac{1}{4})=0.8113\\ Ent(D^3)=-(\dfrac{1}{1}log_2\dfrac{1}{1}+\dfrac{0}{1}log_2\dfrac{0}{1})=0 ∴Ent(D1)=−(97log297+92log292)=0.7642Ent(D1)=−(43log243+41log241)=0.8113Ent(D2)=−(43log243+41log241)=0.8113Ent(D3)=−(11log211+10log210)=0
计算信息熵时约定,若 p = 0 p=0 p=0 ,则 p l o g 2 p = 0 plog_2p=0 plog2p=0
∴ G a i n ( D 1 , c o l o r s ) = 0.7212 − ( 4 9 ∗ 0.8113 + 4 9 ∗ 0.8113 + 1 9 ∗ 0 ) = 0.043 \therefore Gain(D_1,colors)=0.7212-(\dfrac{4}{9}*0.8113+\dfrac{4}{9}*0.8113+\dfrac{1}{9}*0)=0.043\\ ∴Gain(D1,colors)=0.7212−(94∗0.8113+94∗0.8113+91∗0)=0.043
同理,其他属性的信息增益也可以通过上述方法得到,选择信息增益最大的作为新的划分点,即根蒂
增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C 4.5 C4.5 C4.5 决策树算法不直接使用信息增益,而是使用信息增益率
G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ ∣ D ∣ Gain\_ratio(D,a)=\dfrac{Gain(D,a)}{IV(a)}\\ IV(a)=-\sum_{v=1}^{V}\dfrac{\vert D^v \vert}{\vert D\vert}log_2\dfrac{\vert D^v\vert}{\vert D\vert}\\\\ Gain_ratio(D,a)=IV(a)Gain(D,a)IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
以选择根节点为例,计算属性色泽 c o l o r s colors colors 的信息增益率
G a i n _ r a t i o ( D , c o l o r s ) = G a i n ( D , c o l o r s ) I V ( c o l o r s ) G a i n ( D , c o l o r s ) = E n t ( D ) − ∑ v = 1 3 ∣ D v ∣ ∣ D ∣ E n t ( D v ) E n t ( D ) = − ( 8 17 l o g 2 8 17 + 9 17 l o g 2 9 17 ) = 0.998 E n t ( D 1 ) = − ( 3 6 l o g 2 3 6 + 3 6 l o g 2 3 6 ) = 1 E n t ( D 2 ) = − ( 4 6 l o g 2 4 6 + 2 6 l o g 2 2 6 ) = 0.9183 E n t ( D 3 ) = − ( 1 5 l o g 2 1 5 + 4 5 l o g 2 4 5 ) = 0.7219 ∴ G a i n ( D , c o l o r s ) = 0.998 − ( 6 17 ∗ 1 + 6 17 ∗ 0.9183 + 5 17 ∗ 0.7219 ) = 0.1087 I V ( c o l o r s ) = − ( 6 17 l o g 2 6 17 + 6 17 l o g 2 6 17 + 5 17 l o g 2 5 17 ) = 1.580 ∴ G a i n _ r a t i o ( D , c o l o r s ) = 0.1087 1.580 = 0.0689 Gain\_ratio(D,colors)=\dfrac{Gain(D,colors)}{IV(colors)}\\ Gain(D,colors)=Ent(D)-\sum_{v=1}^{3}\dfrac{\vert D^v\vert}{\vert D\vert}Ent(D^v)\\ Ent(D)=-(\dfrac{8}{17}log_2\dfrac{8}{17}+\dfrac{9}{17}log_2\dfrac{9}{17})=0.998\\ Ent(D^1)=-(\dfrac{3}{6}log_2\dfrac{3}{6}+\dfrac{3}{6}log_2\dfrac{3}{6})=1\\ Ent(D^2)=-(\dfrac{4}{6}log_2\dfrac{4}{6}+\dfrac{2}{6}log_2\dfrac{2}{6})=0.9183\\ Ent(D^3)=-(\dfrac{1}{5}log_2\dfrac{1}{5}+\dfrac{4}{5}log_2\dfrac{4}{5})=0.7219\\ \therefore Gain(D,colors)=0.998-(\dfrac{6}{17}*1+\dfrac{6}{17}*0.9183+\dfrac{5}{17}*0.7219)=0.1087\\\\ IV(colors)=-(\dfrac{6}{17}log_2\dfrac{6}{17}+\dfrac{6}{17}log_2\dfrac{6}{17}+\dfrac{5}{17}log_2\dfrac{5}{17})=1.580\\ \therefore Gain\_ratio(D,colors)=\dfrac{0.1087}{1.580}=0.0689 Gain_ratio(D,colors)=IV(colors)Gain(D,colors)Gain(D,colors)=Ent(D)−v=1∑3∣D∣∣Dv∣Ent(Dv)Ent(D)=−(178log2178+179log2179)=0.998Ent(D1)=−(63log263+63log263)=1Ent(D2)=−(64log264+62log262)=0.9183Ent(D3)=−(51log251+54log254)=0.7219∴Gain(D,colors)=0.998−(176∗1+176∗0.9183+175∗0.7219)=0.1087IV(colors)=−(176log2176+176log2176+175log2175)=1.580∴Gain_ratio(D,colors)=1.5800.1087=0.0689
需要注意的是,增益率准则对可取值数目较少的属性有所偏好,因此 C 4.5 C4.5 C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择信息增益率最高的。
基尼指数
C A R T CART CART 决策树【二叉树形式,如对色泽 c o l o r s colors colors 只有两个属性,青绿,非青绿】使用基尼指数来选择划分属性,数据集 D D D 的纯度可用基尼值来度量。
基尼值反映了从数据集中随机抽取两个样本,其类别标记不一致的概率【即预测错误的概率】,因此基尼值越小,数据集 D D D 的纯度越高
G i n i ( D ) = ∑ k = 1 ∣ y ∣ ∑ k ′ ≠ k p k p k ′ = ∑ k = 1 ∣ y ∣ p k ( 1 − p k ) = 1 − ∑ k = 1 ∣ y ∣ p k 2 Gini(D)=\sum_{k=1}^{\vert y\vert}\sum_{k^{'}\ne k}^{}p_kp_k^{'} =\sum_{k=1}^{\vert y\vert}p_k(1-p_k)=1-\sum_{k=1}^{\vert y\vert}p_k^{2} Gini(D)=k=1∑∣y∣k′=k∑pkpk′=k=1∑∣y∣pk(1−pk)=1−k=1∑∣y∣pk2
其中 ∑ k ′ ≠ k p k ′ \sum_{k^{'}\ne k}^{}p_k^{'} ∑k′=kpk′ 意思为类别不为 k k k 的所有概率之和,实则就是 1 − p k 1-p_k 1−pk
另外,由于共有 ∣ y ∣ \vert y\vert ∣y∣ 种类别【在 C A R T CART CART 决策树中其值为 2 2 2 ,即好瓜、坏瓜】,
∴ p 1 + p 2 + . . . + p ∣ y ∣ = 1 \therefore p_1+p_2+...+p_{\vert y\vert}=1 ∴p1+p2+...+p∣y∣=1
由此我们可以得到基尼指数的定义:
G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini\_index(D,a)=\sum_{v=1}^{V}\dfrac{\vert D^v\vert}{\vert D\vert}Gini(D^v) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
其中 a a a 属性有 V V V 个取值, G i n i ( D v ) Gini(D^v) Gini(Dv) 是取值为 v v v 时对应数据集的基尼值
于是,我们在候选属性集合 A A A【表4.1 西瓜数据集2.0】 中,选择那个使得划分后基尼指数最小的属性作为划分属性
a ∗ = a r g min a ∈ A G i n i _ i n d e x ( D , a ) a_*=arg\min\limits_{a\in A} Gini\_index(D,a) a∗=arga∈AminGini_index(D,a)
我们再次使用色泽 c o l o r s colors colors 属性进行举例,计算此时的基尼指数
G i n i _ i n d e x ( D , c o l o r s ) = ∑ v = 1 3 ∣ D v ∣ ∣ D ∣ G i n i ( D v ) G i n i ( D 1 ) = 1 − ( ( 3 6 ) 2 + ( 3 6 ) 2 ) = 1 2 G i n i ( D 2 ) = 1 − ( ( 4 6 ) 2 + ( 2 6 ) 2 ) = 4 9 G i n i ( D 3 ) = 1 − ( ( 1 5 ) 2 + ( 4 5 ) 2 ) = 8 25 ∴ G i n i _ i n d e x ( D , c o l o r s ) = 6 17 ∗ 1 2 + 6 17 ∗ 4 9 + 5 17 ∗ 8 25 = 0.4275 Gini\_index(D,colors)=\sum_{v=1}^{3}\dfrac{\vert D^v\vert}{\vert D\vert}Gini(D^v)\\ Gini(D^1)=1-((\dfrac{3}{6})^2+(\dfrac{3}{6})^2)=\dfrac{1}{2}\\ Gini(D^2)=1-((\dfrac{4}{6})^2+(\dfrac{2}{6})^2)=\dfrac{4}{9}\\ Gini(D^3)=1-((\dfrac{1}{5})^2+(\dfrac{4}{5})^2)=\dfrac{8}{25}\\ \therefore Gini\_index(D,colors)=\dfrac{6}{17}*\dfrac{1}{2}+\dfrac{6}{17}*\dfrac{4}{9}+\dfrac{5}{17}*\dfrac{8}{25}=0.4275 Gini_index(D,colors)=v=1∑3∣D∣∣Dv∣Gini(Dv)Gini(D1)=1−((63)2+(63)2)=21Gini(D2)=1−((64)2+(62)2)=94Gini(D3)=1−((51)2+(54)2)=258∴Gini_index(D,colors)=176∗21+176∗94+175∗258=0.4275
假设在所有属性的基尼指数中,色泽的基尼指数最小,接下来我们比较三种划分带权重的基尼值情况
5 17 G i n i ( D 3 ) < 6 17 G i n i ( D 2 ) < 6 17 G i n i ( D 1 ) \dfrac{5}{17}Gini(D^3)<\dfrac{6}{17}Gini(D^2)<\dfrac{6}{17}Gini(D^1) 175Gini(D3)<176Gini(D2)<176Gini(D1)
所以选择的色泽属性为浅白,非浅白
剪枝
剪枝是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好”了,以致于把训练集自身得一些特点当成所有数据都具有得一般兴致而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合得风险。
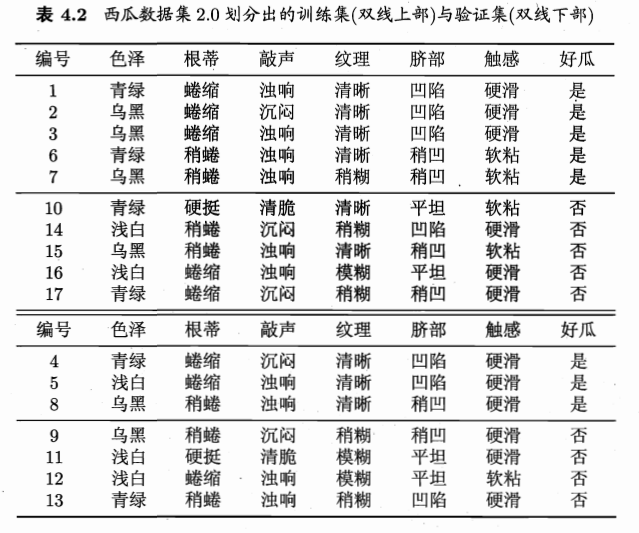
根据信息增益准则生成的决策树
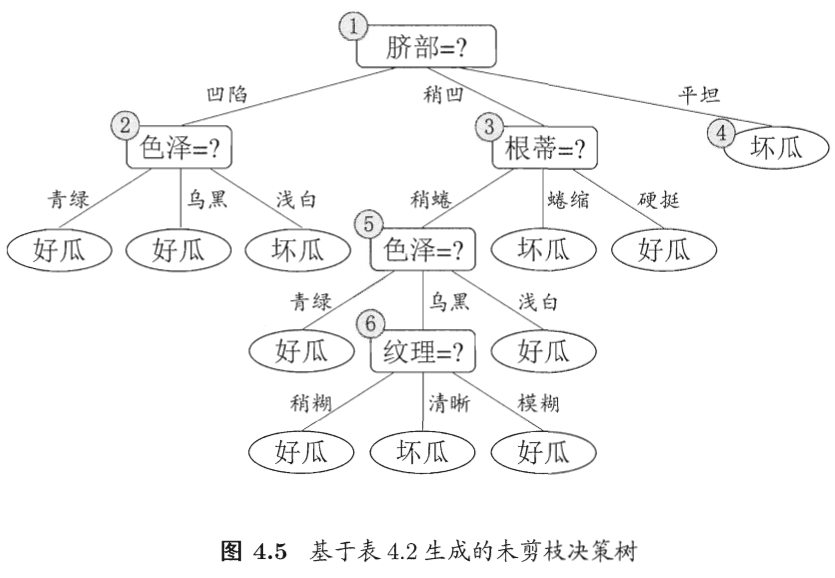
预剪枝
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点得划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点
西瓜书中对于脐部的计算已有详细步骤,因此不多赘述。此处对色泽属性是否需要划分进行计算,即计算划分前与划分后的验证集精度【测试集中预测正确的占比】
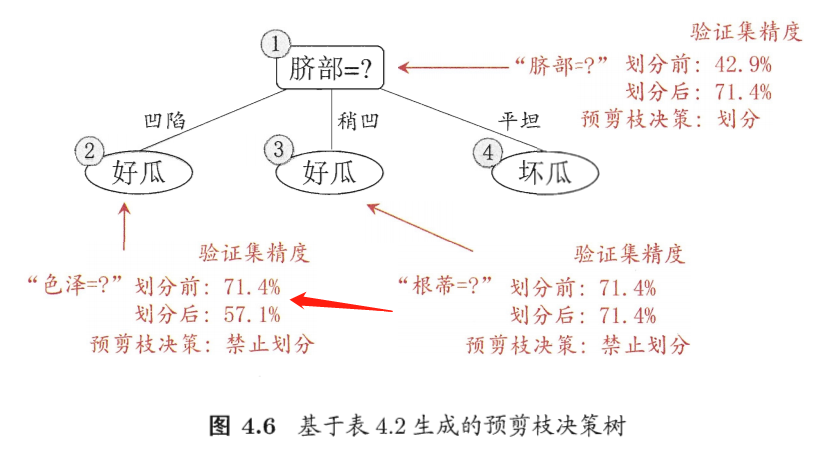
通过训练集发现,凹陷后色泽为青绿,乌黑的为好瓜,浅白的为坏瓜
当做此划分后,凹陷且青绿预测为好瓜,凹陷且乌黑预测为好瓜,凹陷且浅白预测为坏瓜
稍凹预测为好瓜,平坦预测为坏瓜
剪枝前的精确率: a c c u r a c y _ b e f o r e _ c u t = 1 + 1 + 2 7 = 4 7 = 57.1 % accuracy\_before\_cut=\dfrac{1+1+2}{7}=\dfrac{4}{7}=57.1\% accuracy_before_cut=71+1+2=74=57.1%
对色泽进行剪枝后即将所有脐部凹陷,稍凹的都预测为好瓜,平坦的预测为坏瓜
剪枝后的精确率: a c c u r a c y _ a f t e r _ c u t = 5 7 = 71.4 % accuracy\_after\_cut=\dfrac{5}{7}=71.4\% accuracy_after_cut=75=71.4%
剪枝之后精确率提升, ∴ \therefore ∴ 色泽属性应该剪去,即禁止划分色泽属性
后剪枝
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶子结点
计算方法与预剪枝类似,西瓜书上也有详细步骤,不做过多赘述
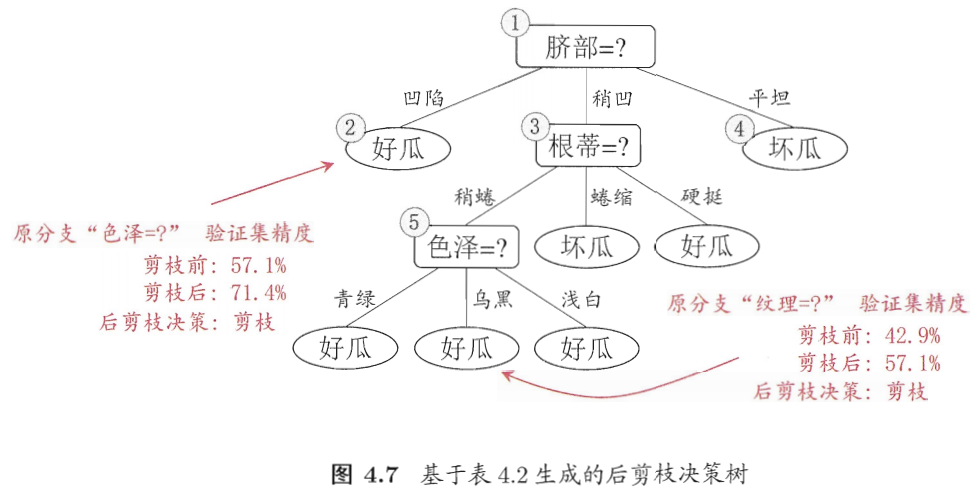
剪枝总结
- 预剪枝和后剪枝唯一的区别就是前者在决策树生成过程中决定是否剪枝,后者在决策树构造完成后再次遍历各属性结点决定是否剪枝
- 一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多
- 预剪枝和后剪枝的算法有多种,这里只是展示了最简单的两种,不过基本思想都是一致的,即通过对比剪枝前后的某个指标来决定是否进行剪枝
连续值
由于连续属性的可取值数目不再有限,因此,不能直接根据连续属性的可取值来对结点进行划分。此时,连续属性离散化技术可派上用场。最简单的策略是采用二分法对连续属性进行处理,这正是 C 4.5 C4.5 C4.5 决策树算法中采用的机制
比如我们现在相对密度属性进行划分,则操作如下
首先获得划分点集合: T a = { a i + a i + 1 2 ∣ 1 ≤ i ≤ n − 1 } T_a=\{\dfrac{a^i+a^{i+1}}{2}\vert 1\le i\le n-1\} Ta={2ai+ai+1∣1≤i≤n−1}
即对连续属性a的所有可能取值进行排序,接着取相邻值得平均值作为划分点集合 T a T_a Ta 的元素
在上述训练集中,密度 d e n s i t y density density 的划分点集合如下
决策树入门【西瓜书】相关推荐
- 机器学习入门-西瓜书总结笔记第十五章
西瓜书第十五章-规则学习 一.基本概念 二.序贯覆盖 三.剪枝优化 四.一阶规则学习 五.归纳逻辑程序设计 1.最小一般泛化 2.逆归结 一.基本概念 机器学习中的 "规则"(ru ...
- 机器学习入门-西瓜书总结笔记第十一章
西瓜书第十一章-特征选择与稀疏学习 一.子集搜索与评价 二.过滤式选择 三.包裹式选择 四.嵌入式选择与 L 1 L_1 L1正则化 五.稀疏表示与字典学习 六.压缩感知 一.子集搜索与评价 将属性 ...
- 机器学习入门-西瓜书总结笔记第十六章
西瓜书第十六章-强化学习 一.任务与奖赏 二.K-摇臂赌博机 1.探索与利用 2. ϵ \epsilon ϵ-贪心 3.Softmax 三.有模型学习 1.策略评估 2.策略改进 3.策略迭代与值迭代 ...
- 决策树(西瓜书学习)
算法是死的,思想才是活的! 1. 基本流程 决策树(decision tree):一般的,一棵决策树包含一个根结点.若干个内部结点和若干个叶结点:叶结点对应于决策结果,其他每个结点则对应于一个属性测试 ...
- 西瓜书学习记录-决策树(第四章)
西瓜书学习记录-决策树(第四章) 第四章啦 知乎黄耀鹏-决策树算法的Python实现: https://zhuanlan.zhihu.com/p/20794583 一般分布例子如下:(见下具体例题) ...
- ++代码实现 感知机的原理_决策树ID3原理及R语言python代码实现(西瓜书)
决策树ID3原理及R语言python代码实现(西瓜书) 摘要: 决策树是机器学习中一种非常常见的分类与回归方法,可以认为是if-else结构的规则.分类决策树是由节点和有向边组成的树形结构,节点表示特 ...
- 【DataWhale学习】Day10~13-4章决策树——西瓜书学习摘录笔记
[DataWhale学习]Day10~13-4章决策树--西瓜书学习摘录笔记 本文参考了周志华老师的西瓜书,李航老师的统计学习方法,谢文睿大佬的南瓜书(无推导尿点,仅加深理解食用) 决策树模型 决 ...
- 西瓜书重温(四): 决策树手推版
1. 写在前面 今天复习的决策树模型, 对应的是西瓜书的第四章内容, 关于决策树模型,重要性不言而喻了, 这个是后面集成学习模型的基础, 集成学习里面不管是bagging家族里面的代表随机森林,还是b ...
- 【机器学习】入门到实战笔记系列 | 西瓜书
机器学习 南京大学周志华教授亲讲<机器学习初步>!跟着大佬从入门到实战 机器学习的本质就是寻找一个函数function,来寻找一个输入input与输出output之间的映射关系.可以是输入 ...
最新文章
- mySql 主从复制linux配置
- 抗侧力构件弹性位移如何计算_穿心棒法盖梁施工计算书(工字钢)
- python3 判断进程是否存在
- 成功打开华三模拟器后,创建设备完成却启动设备失败
- Linux中添加pycharm源,linux下python+pycharm安装
- GetModuleHandle,AfxGetInstanceHandle使用区别
- 自动生成网络拓扑图开源_为视频自动生成字幕,一款神奇的开源工具!
- 云原生之上,亚马逊云科技发布多项容器与Serverless服务,持续发力现代化应用
- 分组背包(信息学奥赛一本通-T1272)
- vue3——ref reactive函数
- Python 爬虫---(3)Urllib库使用介绍
- 从不同步的代码块中调用了对象同步方法。_Java中Synchronized的用法
- mysql怎么查主键是否重复数据库_数据库插入前判断主键重复与否的方法
- 多媒体技术简答题和论述题
- 中文简历表格提取,手写汉字识别(Python+OpenCV)
- ssis使用Excel目标的坑
- intel 电脑棒一代linux,拆解:英特尔黑科技——电脑棒
- 短除法求解最大公约数c语言,[编程入门]最大公约数与最小公倍数-题解(C语言代码)(短除法)...
- 微信小程序获取手机号,TP6 后端电话短信验证
- 网站常用的favicon.ico文件