ESMM、MMOE-推荐系统小结
ESMM、MMOE-推荐系统小结
1.多任务学习
多任务学习的优势在于通过部分参数共享,联合训练,能在保证“还不错”的前提下,实现多目标共同提升。原因有以下几种:
- 任务互助:对于某个任务难学到的特征,可通过其他任务学习
- 隐式数据增强:不同任务有不同的噪声,一起学习可抵消部分噪声
- 学到通用表达,提高泛化能力:模型学到的是对所有任务都偏好的权重,有助于推广到未来的新任务
- 正则化:对于一个任务而言,其他任务的学习对该任务有正则化效果
最早的多任务学习模型是底层共享结构(Shared-Bottom):
优点:
- 浅层参数共享,互相补充学习,任务相关性越高,模型loss优化效果越明显,也可以加速训练。
缺点:
- 任务不相关甚至优化目标相反时(例如新闻的点击与阅读时长),可能会带来负收益,多个任务性能一起下降。
一般把Shared-Bottom的结构称作“参数硬共享”,多任务学习网络结构设计的发展方向便是如何设计更灵活的共享机制,从而实现“参数软共享”。
2.阿里ESMM
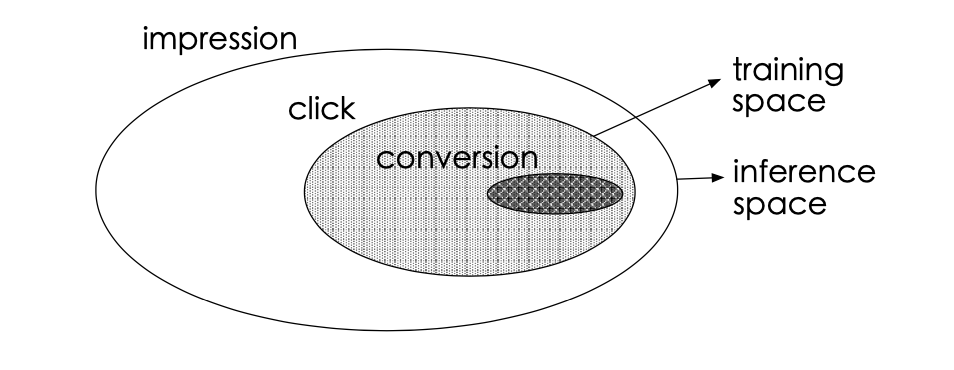
传统的CVR预估问题存在着两个主要的问题:样本选择偏差和稀疏数据。下图的白色背景是曝光数据,灰色背景是点击行为数据,黑色背景是购买行为数据。传统CVR预估使用的训练样本仅为灰色和黑色的数据。
这会导致两个问题:
- 样本选择偏差(sample selection bias,SSB):如图所示,CVR模型的正负样本集合={点击后未转化的负样本+点击后转化的正样本},但是线上预测的时候是样本一旦曝光,就需要预测出CVR和CTR以排序,样本集合={曝光的样本}。构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中训练数据和测试数据独立同分布的假设。
- 训练数据稀疏(data sparsity,DS):点击样本只占整个曝光样本的很小一部分,而转化样本又只占点击样本的很小一部分。如果只用点击后的数据训练CVR模型,可用的样本将极其稀疏。
解决方案
其中x表示曝光,y表示点击,z表示转化:
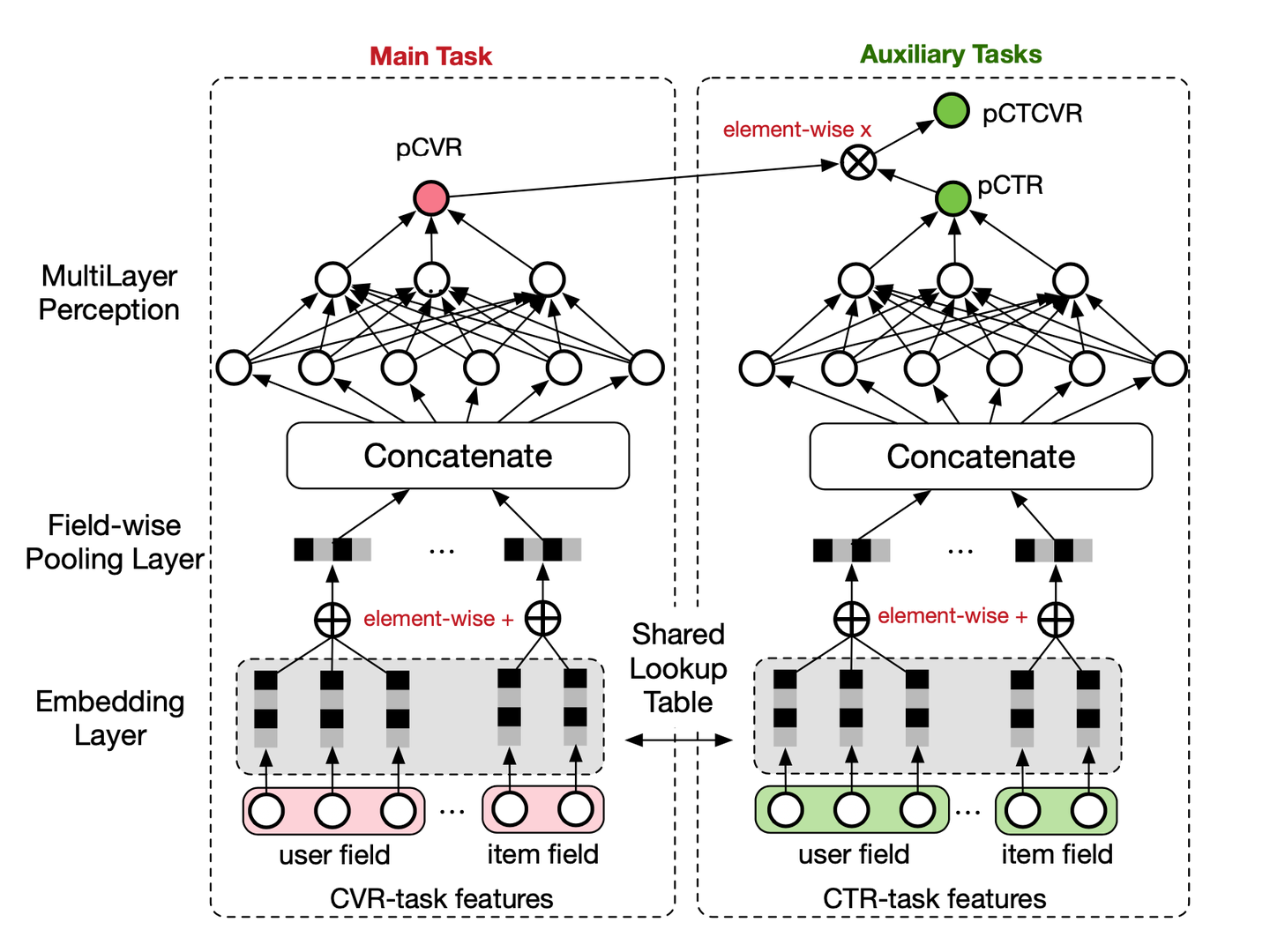
pCTCVR是指,当用户已经点击的前提下,用户会购买的概率;pCVR是指如果用户点击了,会购买的概率。
三个任务之间的关系为:
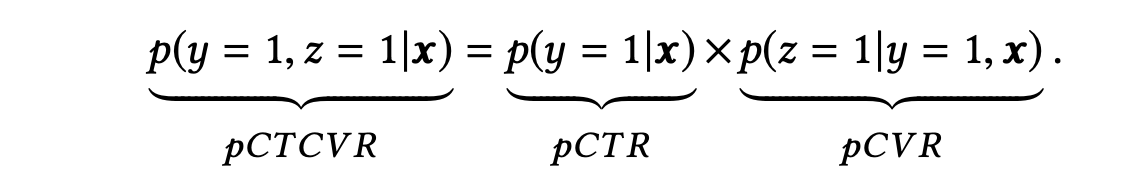
如图,主任务和辅助任务共享特征,不同任务输出层使用不同的网络,将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数:
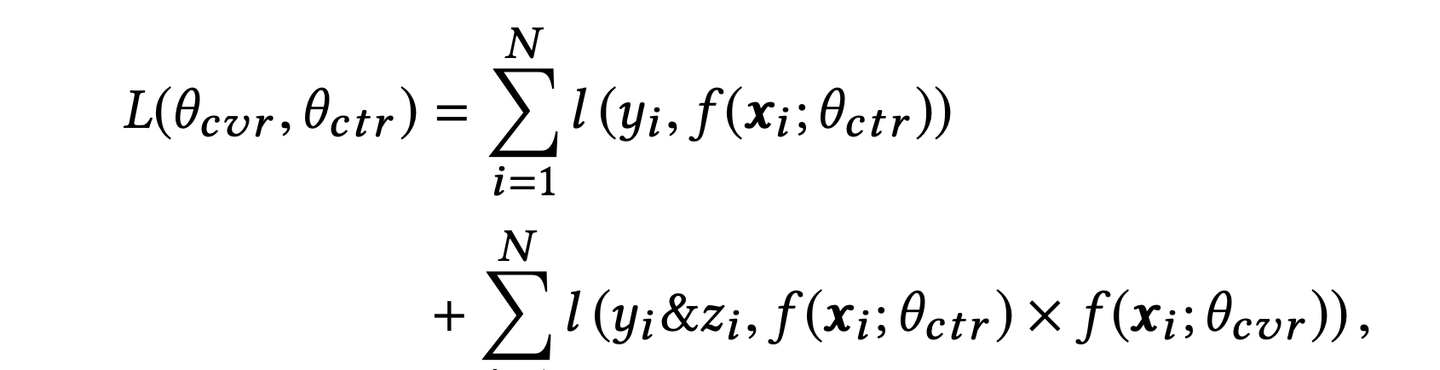
该架构具有两大特点,分别给出上述两个问题的解决方案:
帮助CVR模型在完整样本空间建模(即曝光空间X)。
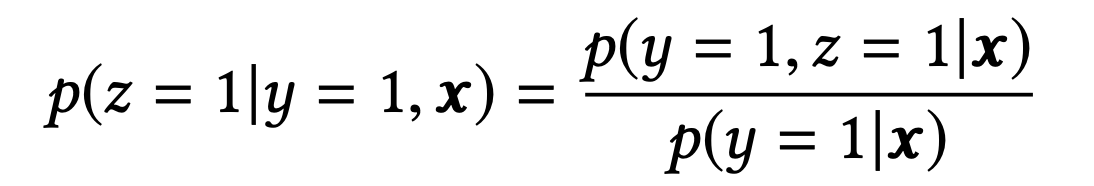
从公式中可以看出,pCVR 可以由pCTR 和pCTCVR推导出。从原理上来说,相当于分别单独训练两个模型拟合出pCTR 和pCTCVR,再通过pCTCVR 除以pCTR 得到最终的拟合目标pCVR 。在训练过程中,模型只需要预测pCTCVR和pCTR,利用两种相加组成的联合loss更新参数。pCVR 只是一个中间变量。而pCTCVR和pCTR的数据是在完整样本空间中提取的,从而相当于pCVR也是在整个曝光样本空间中建模。
- 提供特征表达的迁移学习(embedding层共享)。CVR和CTR任务的两个子网络共享embedding层,网络的embedding层把大规模稀疏的输入数据映射到低维的表示向量,该层的参数占了整个网络参数的绝大部分,需要大量的训练样本才能充分学习得到。由于CTR任务的训练样本量要大大超过CVR任务的训练样本量,ESMM模型中特征表示共享的机制能够使得CVR子任务也能够从只有展现没有点击的样本中学习,从而能够极大地有利于缓解训练数据稀疏性问题。
模型训练完成后,可以同时预测cvr、ctr、ctcvr三个指标,线上根据实际需求进行融合或者只采用此模型得到的cvr预估值。
总结:
ESMM首创了利用用户行为序列数据在完整样本空间建模,并提出利用学习CTR和CTCVR的辅助任务,迂回学习CVR,避免了传统CVR模型经常遭遇的样本选择偏差和训练数据稀疏的问题,取得了显著的效果。
ESSM代码(torch-rechub)
import torch
import torch.nn.functional as F
from torch_rechub.basic.layers import MLP, EmbeddingLayer
from tqdm import tqdmCopy to clipboardErrorCopied
class ESMM(torch.nn.Module):def __init__(self, user_features, item_features, cvr_params, ctr_params):super().__init__()self.user_features = user_featuresself.item_features = item_featuresself.embedding = EmbeddingLayer(user_features + item_features)self.tower_dims = user_features[0].embed_dim + item_features[0].embed_dim# 构建CVR和CTR的双塔self.tower_cvr = MLP(self.tower_dims, **cvr_params)self.tower_ctr = MLP(self.tower_dims, **ctr_params)def forward(self, x):embed_user_features = self.embedding(x, self.user_features, squeeze_dim=False).sum(dim=1) embed_item_features = self.embedding(x, self.item_features, squeeze_dim=False).sum(dim=1)input_tower = torch.cat((embed_user_features, embed_item_features), dim=1)cvr_logit = self.tower_cvr(input_tower)ctr_logit = self.tower_ctr(input_tower)cvr_pred = torch.sigmoid(cvr_logit)ctr_pred = torch.sigmoid(ctr_logit)# 计算pCTCVR = pCTR * pCVRctcvr_pred = torch.mul(cvr_pred, cvr_pred)ys = [cvr_pred, ctr_pred, ctcvr_pred]return torch.cat(ys, dim=1)
3.MMOE
MMOE是2018年谷歌提出的,全称是Multi-gate Mixture-of-Experts, 对于多个优化任务,引入了多个专家进行不同的决策和组合,最终完成多目标的预测。解决的是硬共享里面如果多个任务相似性不是很强,底层的embedding学习反而相互影响,最终都学不好的痛点。
背景与动机
推荐系统中,即使同一个场景,常常也不只有一个业务目标。 在Youtube的视频推荐中,推荐排序任务不仅需要考虑到用户点击率,完播率,也需要考虑到一些满意度指标,例如,对视频是否喜欢,用户观看后对视频的评分;在淘宝的信息流商品推荐中,需要考虑到点击率,也需要考虑转化率;而在一些内容场景中,需要考虑到点击和互动、关注、停留时长等指标。
模型中,如果采用一个网络同时完成多个任务,就可以把这样的网络模型称为多任务模型, 这种模型能在不同任务之间学习共性以及差异性,能够提高建模的质量以及效率。 常见的多任务模型的设计范式大致可以分为三大类:
hard parameter sharing 方法: 这是非常经典的一种方式,底层是共享的隐藏层,学习各个任务的共同模式,上层用一些特定的全连接层学习特定任务模式。

这种方法目前用的也有,比如美团的猜你喜欢,知乎推荐的Ranking等, 这种方法最大的优势是Task越多, 单任务更加不可能过拟合,即可以减少任务之间过拟合的风险。 但是劣势也非常明显,就是底层强制的shared layers难以学习到适用于所有任务的有效表达。 尤其是任务之间存在冲突的时候。MMOE中给出了实验结论,当两个任务相关性没那么好(比如排序中的点击率与互动,点击与停留时长),此时这种结果会遭受训练困境,毕竟所有任务底层用的是同一组参数。
soft parameter sharing: 硬的不行,那就来软的,这个范式对应的结果从
MOE->MMOE->PLE等。 即底层不是使用共享的一个shared bottom,而是有多个tower, 称为多个专家,然后往往再有一个gating networks在多任务学习时,给不同的tower分配不同的权重,那么这样对于不同的任务,可以允许使用底层不同的专家组合去进行预测,相较于上面所有任务共享底层,这个方式显得更加灵活任务序列依赖关系建模:这种适合于不同任务之间有一定的序列依赖关系。比如电商场景里面的ctr和cvr,其中cvr这个行为只有在点击之后才会发生。所以这种依赖关系如果能加以利用,可以解决任务预估中的样本选择偏差(SSB)和数据稀疏性(DS)问题
样本选择偏差: 后一阶段的模型基于上一阶段采样后的样本子集训练,但最终在全样本空间进行推理,带来严重泛化性问题样本稀疏: 后一阶段的模型训练样本远小于前一阶段任务
ESSM是一种较为通用的任务序列依赖关系建模的方法,除此之外,阿里的DBMTL,ESSM2等工作都属于这一个范式。
通过上面的描述,能大体上对多任务模型方面的几种常用建模范式有了解,然后也知道了hard parameter sharing存在的一些问题,即不能很好的权衡特定任务的目标与任务之间的冲突关系。而这也就是MMOE模型提出的一个动机所在了, 那么下面的关键就是MMOE模型是怎么建模任务之间的关系的,又是怎么能使得特定任务与任务关系保持平衡的?
带着这两个问题,下面看下MMOE的细节。
MMOE模型的理论及论文细节
MMOE模型结构图如下。
这其实是一个演进的过程,首先hard parameter sharing这个就不用过多描述了, 下面主要是看MOE模型以及MMOE模型。
混合专家模型
我们知道共享的这种模型结构,会遭受任务之间冲突而导致可能无法很好的收敛,从而无法学习到任务之间的共同模式。这个结构也可以看成是多个任务共用了一个专家。
先抛开任务关系, 我们发现一个专家在多任务学习上的表达能力很有限,于是乎,尝试引入多个专家,这就慢慢的演化出了混合专家模型。 公式表达如下:
y=∑i=1ng(x)ifi(x)y=\sum_{i=1}^{n} g(x)_{i} f_{i}(x) y=i=1∑ng(x)ifi(x)
∑i=1ng(x)i=1\sum_{i=1}^{n} g(x)_{i}=1∑i=1ng(x)i=1。fi(x)f_i(x)fi(x)就是每个专家的输出, 而g(x)ig(x)_ig(x)i就是每个专家对应的权重。改进:
- 模型集成思想: 这个东西很像bagging的思路,即训练多个模型进行决策,这个决策的有效性显然要比单独一个模型来的靠谱一点,不管是从泛化能力,表达能力,学习能力上,应该都强于一个模型
- 注意力思想: 为了增加灵活性, 为不同的模型还学习了重要性权重,这可能考虑到了在学习任务的共性模式上, 不同的模型学习的模式不同,那么聚合的时候,显然不能按照相同的重要度聚合,所以为各个专家学习权重,默认了不同专家的决策地位不一样。这个思想目前不过也非常普遍了。
- multi-head机制: 从另一个角度看, 多个专家其实代表了多个不同head, 而不同的head代表了不同的非线性空间,之所以说表达能力增强了,是因为把输入特征映射到了不同的空间中去学习任务之间的共性模式。可以理解成从多个角度去捕捉任务之间的共性特征模式。
MOE使用了多个混合专家增加了各种表达能力,但是, 一个门控并不是很灵活,因为这所有的任务,最终只能选定一组专家组合,即这个专家组合是在多个任务上综合衡量的结果,并没有针对性了。 如果这些任务都比较相似,那就相当于用这一组专家组合确实可以应对这多个任务,学习到多个相似任务的共性。 但如果任务之间差的很大,这种单门控控制的方式就不行了,因为此时底层的多个专家学习到的特征模式相差可能会很大,毕竟任务不同,而单门控机制选择专家组合的时候,肯定是选择出那些有利于大多数任务的专家, 而对于某些特殊任务,可能学习的一塌糊涂。
所以,这种方式的缺口很明显,这样,也更能理解为啥提出多门控控制的专家混合模型了。
MMOE结构
Multi-gate Mixture-of-Experts(MMOE)的魅力就在于在OMOE的基础上,对于每个任务都会涉及一个门控网络,这样,对于每个特定的任务,都能有一组对应的专家组合去进行预测。更关键的时候,参数量还不会增加太多。公式如下:
yk=hk(fk(x)),y_{k}=h^{k}\left(f^{k}(x)\right), yk=hk(fk(x)),
- 首先,就刚才分析的OMOE的问题,在专家组合选取上单门控会产生限制,此时如果多个任务产生了冲突,这种结构就无法进行很好的权衡。 而MMOE就不一样了。MMOE是针对每个任务都单独有个门控选择专家组合,那么即使任务冲突了,也能根据不同的门控进行调整,选择出对当前任务有帮助的专家组合。
- 多门控机制能够建模任务之间的关系了。如果各个任务都冲突, 那么此时有多门控的帮助, 此时让每个任务独享一个专家,如果任务之间能聚成几个相似的类,那么这几类之间应该对应的不同的专家组合,那么门控机制也可以选择出来。如果所有任务都相似,那这几个门控网络学习到的权重也会相似,所以这种机制把任务的无关,部分相关和全相关进行了一种统一。
- 灵活的参数共享, 这个我们可以和hard模式或者是针对每个任务单独建模的模型对比,对于hard模式,所有任务共享底层参数,而每个任务单独建模,是所有任务单独有一套参数,算是共享和不共享的两个极端,对于都共享的极端,害怕任务冲突,而对于一点都不共享的极端,无法利用迁移学习的优势,模型之间没法互享信息,互为补充,容易遭受过拟合的困境,另外还会增加计算量和参数量。 而MMOE处于两者的中间,既兼顾了如果有相似任务,那就参数共享,模式共享,互为补充,如果没有相似任务,那就独立学习,互不影响。 又把这两种极端给进行了统一。
- 训练时能快速收敛,这是因为相似的任务对于特定的专家组合训练都会产生贡献,这样进行一轮epoch,相当于单独任务训练时的多轮epoch。
- 虽然模型的复杂度提升了,但是计算量不会大幅增加。MoE是条件计算(conditional computation)的一种实现,而条件计算可以提升模型容量而不会大幅增加计算力需求。
那么, 为什么多任务学习为什么是有效的呢? 这里整理一个看到比较不错的答案:
多任务学习有效的原因是引入了归纳偏置,两个效果:
- 互相促进: 可以把多任务模型之间的关系看作是互相先验知识,也称为归纳迁移,有了对模型的先验假设,可以更好提升模型的效果。解决数据稀疏性其实本身也是迁移学习的一个特性,多任务学习中也同样会体现
- 泛化作用:不同模型学到的表征不同,可能A模型学到的是B模型所没有学好的,B模型也有其自身的特点,而这一点很可能A学不好,这样一来模型健壮性更强
代码
import torch
import torch.nn as nnfrom torch_rechub.basic.layers import MLP, EmbeddingLayer, PredictionLayerCopy to clipboardErrorCopied
class MMOE(torch.nn.Module):def __init__(self, features, task_types, n_expert, expert_params, tower_params_list):super().__init__()self.features = featuresself.task_types = task_types# 任务数量self.n_task = len(task_types)self.n_expert = n_expertself.embedding = EmbeddingLayer(features)self.input_dims = sum([fea.embed_dim for fea in features])# 每个Expert对应一个门控self.experts = nn.ModuleList(MLP(self.input_dims, output_layer=False, **expert_params) for i in range(self.n_expert))self.gates = nn.ModuleList(MLP(self.input_dims, output_layer=False, **{"dims": [self.n_expert],"activation": "softmax"}) for i in range(self.n_task))# 双塔self.towers = nn.ModuleList(MLP(expert_params["dims"][-1], **tower_params_list[i]) for i in range(self.n_task))self.predict_layers = nn.ModuleList(PredictionLayer(task_type) for task_type in task_types)def forward(self, x):embed_x = self.embedding(x, self.features, squeeze_dim=True)expert_outs = [expert(embed_x).unsqueeze(1) for expert in self.experts] expert_outs = torch.cat(expert_outs, dim=1) gate_outs = [gate(embed_x).unsqueeze(-1) for gate in self.gates]ys = []for gate_out, tower, predict_layer in zip(gate_outs, self.towers, self.predict_layers):expert_weight = torch.mul(gate_out, expert_outs) expert_pooling = torch.sum(expert_weight, dim=1) # 计算双塔tower_out = tower(expert_pooling)# logit -> probay = predict_layer(tower_out)ys.append(y)return torch.cat(ys, dim=1)
论文阅读
• ESMM https://arxiv.org/abs/1804.07931
• MMOE https://dl.acm.org/doi/pdf/10.1145/3219819.3220007
ESMM、MMOE-推荐系统小结相关推荐
- 自己动手写一个推荐系统,推荐系统小结,推荐系统:总体介绍、推荐算法、性能比较, 漫谈“推荐系统”, 浅谈矩阵分解在推荐系统中的应用...
自己动手写一个推荐系统 废话: 最近朋友在学习推荐系统相关,说是实现完整的推荐系统,于是我们三不之一会有一些讨论和推导,想想索性整理出来. 在文中主要以工程中做推荐系统的流程着手,穿插一些经验之谈,并 ...
- 深度学习在阿里B2B电商推荐系统中的实践
作者:卡本,来自:DataFunTalk 导读:推荐导购场景在电商中是重要的满足用户"逛"和"买"的场景,本次分享我们聚焦深度学习在阿里B2B电商 ( 1688 ...
- 【推荐实践】深度学习在阿里B2B电商推荐系统中的实践
分享嘉宾:卡本 阿里 高级算法专家 文章整理:刘金鑫 内容来源:DataFunTalk 导读:推荐导购场景在电商中是重要的满足用户"逛"和"买"的场景,本次分享 ...
- 5大经典排序算法在淘宝“有好货”场景的实践
本文将介绍有好货推荐场景下的排序算法.有好货作为淘宝典型的内容导购场景,产品的定位是帮助消费升级人群发现口碑好货.排序作为推荐场景链路中重要环节,很大程度决定了推荐效率.过去一年,我们在排序算法的超长 ...
- 下拉推荐在 Shopee Chatbot 中的探索和实践
首发于微信公众号"Shopee技术团队". 摘要 在主流的搜索引擎.购物 App 和 Chatbot 等应用中,下拉推荐可以有效地帮助用户快速检索所需要的内容,已经成为一项必需且标 ...
- 全链路总结!推荐算法召回-粗排-精排
作者 | Salon sai 整理 | NewBeeNLP https://zhuanlan.zhihu.com/p/463021052 大家好,这里是NewBeeNLP.现在的推荐系统都是一个很大 ...
- 多任务学习MTL-基本介绍(一)
多任务模型 单任务模型 一个模型学习一个目标,不同模型享用独立的模型空间,不同模型之间没有连接,相互独立 多任务模型 一个模型学习多个目标,共享同一个模型空间 优势:相比于单任务模型,同时学习多个相关 ...
- 饿了么为啥给你推荐这个?本地生活搜索算法解密
作者:玄东.王喆.采英.格鸣 搜索是本地业务的重要入口,切实影响着用户体验和业务效果.本文将围绕算法优化来介绍本地生活搜索该如何有效适配本地业务. 搜索是本地业务的重要入口,也是C端流量/B端供给/D ...
- 多目标学习(MMOE/ESMM/PLE)在推荐系统的实战经验分享
作者 | 绝密伏击 知乎 | https://zhuanlan.zhihu.com/p/291406172 整理 | 深度传送门 一.前言 最近搞了一个月的视频多目标优化,同时优化点击率和衍生率(ys ...
最新文章
- R语言psych包的fa函数对指定数据集进行因子分析(输入数据为相关性矩阵)、指定进行正交旋转、斜交旋转提取因子、比较正交旋转和斜交旋转之间的差异、因子结构矩阵、因子模式矩阵和因子相关矩阵之间的关系
- 你不曾见过的酷炫地图可视化作品(一)
- pandas.DataFrame.multiply()含义解释
- redis操作帮助类
- wxWidgets:wxSizer类用法
- docker $PWD路径_使用docker炼丹
- 【安卓开发】Android初级开发(okhttp3发送带header与带参数的GET请求)
- 云上救命APP!——e代驾手机客户端!
- 教师节快乐:删了库之后,不要着急跑路
- python列表数据类型一致_python自学——数据类型之列表
- 小学计算机信息论文题目,小学计算机论文
- Python骚操作—自动刷抖音
- 抗击疫情,在家自学编程
- 天宝水准仪DINI数据传输遇到问题
- 互联网与移动互联网仍是本世纪最大创业机会
- Metrics 使用
- 2022年保研经验贴建议个人经历:计算机软件工程
- [基础论文阅读]QMIX: Monotonic Value Function Factorization for Deep Multi-agent Reinforcement Learning
- 微信小程序实例:创建下发模板消息实例
- 计算机动画_3dsmax的使用(二)
热门文章
- 《高绩效教练》读后感_20180114
- 安兔兔android手机性能排行榜,安兔兔发布:2018年10月国内Android手机性能排行榜...
- 想放酒店鸽子?酒店:尽管放,预测不到算我输
- JS中的按位运算符们
- UE4实现丁达尔光线效果
- flexcell绑定MySQL数据_利用FlexCell实现的一些报表统计应用
- 【mybatis】mybatis if 标签判断字符串相等
- BNU All Your Base (Regionals 2011, North America - South Central USA) - from lanshui_Yang
- Bert系列:如何用bert模型输出文本的embedding
- QT程序打包配置手册