分布式全局ID生成器设计
项目是分布式的架构,需要设计一款分布式全局ID,参照了多种方案,博主最后基于snowflake的算法设计了一款自用ID生成器。具有以下优势:
- 保证分布式场景下生成的ID是全局唯一的
- 生成的全局ID整体上是呈自增趋势的,也就是说整体是粗略有序的
- 高性能,能快速产生ID,本机(I7-6400HQ)单线程可以达到每秒生成近40万个ID
- 只占64bit位空间,可以根据业务需求扩展在前缀或后缀拼接业务标志位转化为字符串。
UUID方案
- UUID:UUID长度128bit,32个16进制字符,占用存储空间多,且生成的ID是无序的
- 对于InnoDB这种聚集主键类型的引擎来说,数据会按照主键进行排序,由于UUID的无序性,InnoDB会产生巨大的IO压力,此时不适合使用UUID做物理主键,可以把它作为逻辑主键,物理主键依然使用自增ID。
- 组成部分:当前日期和时间、时钟序列、机器识别码
数据库生成全局ID方案
- 结合数据库维护一个Sequence表,每当需要为某个表的新纪录生成ID时就从Sequence表中取出对应的nextid,将其+1后更新到数据库中以备下次使用。
- 由于所有的插入都要访问该表,很容易造成性能瓶颈,且存在单点问题,如果该表所在的数据库失效,全部应用无法工作。
- 在高并发场景下,无法保证高性能。
snowflake方案
是一个优秀的分布式Id生成方案,是Scala实现的,此次项目就是基于snowflake算法基础上设计的Java优化版
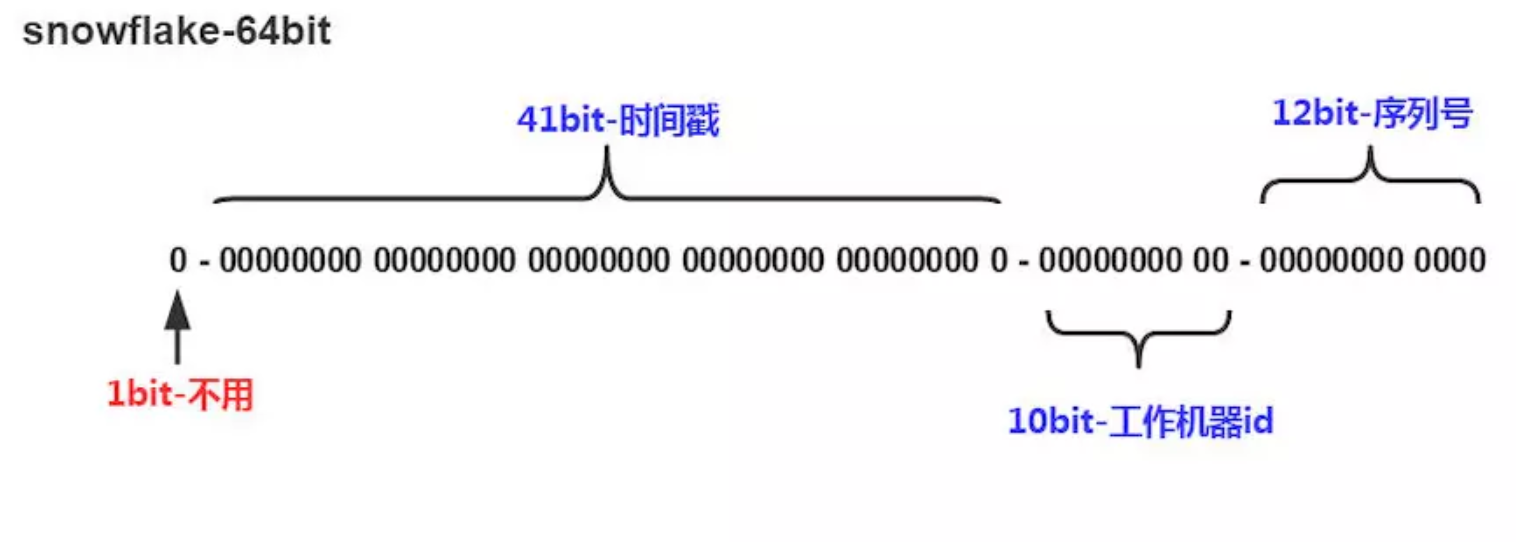
- 1位,不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0
- 41位,用来记录时间戳(毫秒),41位可以表示2^41^−1个数字,也就是说41位可以表示2^41^−1个毫秒的值,转化成单位年则是(2^41−1)/(1000∗60∗60∗24∗365)=69年
- 10位,用来记录工作机器id。可以部署在2^10^=1024个节点,包括5位datacenterId和5位workerId,5位(bit)可以表示的最最大正整数是2^5−1=31,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
- 12位,序列号,用来记录同毫秒内产生的不同id。12位(bit)可以表示的最大正整数是2^12^−1=4095,即可以用0、1、2、3、....4095这4096个数字,来表示同一机器同一时间截(毫秒)内产生的4096个ID序号
改进方案
全局唯一ID生成结构如下(每部分用-分开):
- 0 - 00 - 0000000000 0000000000 0000000000 0000000000 0 - 0000000000 00 - 00000000
- 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
- 2位生成发布方式,0代表嵌入式发布、1代表中心服务器发布模式、2代表rest发布方式、3代表测试方式
- 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
- 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
- 8位的数据机器位,可以部署在256个节点,包括8位workerId
- 加起来刚好64位,为一个Long型
- 优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(机器ID作区分),并且效率较高,经本地测试每秒能够产生40万ID左右。
方案优势
- 保证分布式场景下生成的ID是全局唯一的
- 生成的全局ID整体上是呈自增趋势的,也就是说整体是粗略有序的
- 高性能,能快速产生ID,本机单线程可以达到每秒生成近40万个ID
- 只占64bit位空间,可以根据业务需求在前缀或后缀拼接业务标志位。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public final class IdGenerate {// ==============================Fields===========================================/** 开始时间截 (2018-01-01) */private final long twepoch = 1514736000000L;/** 机器id所占的位数 */private final long workerIdBits = 8L;/** 序列在id中占的位数 */private final long sequenceBits = 12L;/** 毫秒级别时间截占的位数 */private final long timestampBits = 41L;/** 生成发布方式所占的位数 */private final long getMethodBits = 2L;/** 支持的最大机器id,结果是255 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */private final long maxWorkerId = -1L ^ (-1L << workerIdBits);/** 生成序列向左移8位(8) */private final long sequenceShift = workerIdBits;/** 时间截向左移20位(12+8) */private final long timestampShift = sequenceBits + workerIdBits;/** 生成发布方式向左移61位(41+12+8) */private final long getMethodShift = timestampBits + sequenceBits + workerIdBits;/** 工作机器ID(0~255) */private long workerId = 0L;/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */private final long sequenceMask = -1L ^ (-1L << sequenceBits);/** 毫秒内序列(0~4095) */private long sequence = 0L;/** 上次生成ID的时间截 */private long lastTimestamp = -1L;/** 2位生成发布方式,0代表嵌入式发布、1代表中心服务器发布模式、2代表rest发布方式、3代表保留未用 */private long getMethod = 0L;/** 成发布方式的掩码,这里为3 (0b11=0x3=3) */private long maxGetMethod = -1L ^ (-1L << getMethodBits);/** 重入锁*/private Lock lock = new ReentrantLock();//==============================Constructors=====================================/*** 构造函数* @param 发布方式 0代表嵌入式发布、1代表中心服务器发布模式、2代表rest发布方式、3代表保留未用 (0~3)* @param workerId 工作ID (0~255)*/public IdGenerate(long getMethod, long workerId) {if (getMethod > maxGetMethod || getMethod < 0) {throw new IllegalArgumentException(String.format("getMethod can't be greater than %d or less than 0", maxGetMethod));}if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}this.getMethod = getMethod;this.workerId = workerId;}public long[] nextId(int nums) {long[] ids = new long[nums];for (int i = 0; i < nums; i++) {ids[i] = nextId();}return ids;}// ==============================Methods==========================================/*** 获得下一个ID (该方法是线程安全的)* @return SnowflakeId*/public long nextId() {long timestamp = timeGen();//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}//如果是同一时间生成的,则进行毫秒内序列if (lastTimestamp == timestamp) {lock.lock();try {sequence = (sequence + 1) & sequenceMask;//毫秒内序列溢出if (sequence == 0) {//阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}finally {lock.unlock();}}//时间戳改变,毫秒内序列重置else {sequence = 0L;}//上次生成ID的时间截lastTimestamp = timestamp;//移位并通过或运算拼到一起组成64位的IDreturn (getMethod << getMethodShift) // 生成方式占用2位,左移61位| ((timestamp - twepoch) << timestampShift) // 时间差占用41位,最多69年,左移20位| (sequence << sequenceShift) // 毫秒内序列,取值范围0-4095| workerId; // 工作机器,取值范围0-255}public String nextString() {return Long.toString(nextId());}public String[] nextString(int nums) {String[] ids = new String[nums];for (int i = 0; i < nums; i++) {ids[i] = nextString();}return ids;}public String nextCode(String prefix) {StringBuilder sb = new StringBuilder(prefix);long id = nextId();sb.append(id);return sb.toString();}/*** 此方法可以在前缀上增加业务标志* @param prefix* @param nums* @return*/public String[] nextCode(String prefix, int nums) {String[] ids = new String[nums];for (int i = 0; i < nums; i++) {ids[i] = nextCode(prefix);}return ids;}public String nextHexString() {return Long.toHexString(nextId());}/*** 阻塞到下一个毫秒,直到获得新的时间戳* @param lastTimestamp 上次生成ID的时间截* @return 当前时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 返回以毫秒为单位的当前时间* @return 当前时间(毫秒)*/protected long timeGen() {return System.currentTimeMillis();}//==============================Test=============================================/*** 测试***/public static void main(String[] args) {IdGenerate idGenerate = new IdGenerate(0, 0);int count = 100000;//线程数=count*countfinal long[][] times = new long[count][100];Thread[] threads = new Thread[count];for (int i = 0; i < threads.length; i++) {final int ip = i;threads[i] = new Thread() {@Overridepublic void run() {for (int j = 0; j <100; j++) {long t1 = System.nanoTime();//该函数是返回纳秒的。1毫秒=1纳秒*1000000idGenerate.nextId();//测试long t = System.nanoTime() - t1;times[ip][j] = t;//求平均}}};}long lastMilis = System.currentTimeMillis();//逐个启动线程for (int i = 0; i < threads.length; i++) {threads[i].start();}for (int i = 0; i < threads.length; i++) {try {threads[i].join();} catch (InterruptedException e) {e.printStackTrace();}}/*** 1、QPS:系统每秒处理的请求数(query per second)2、RT:系统的响应时间,一个请求的响应时间,也可以是一段时间的平均值3、最佳线程数量:刚好消耗完服务器瓶颈资源的临界线程数对于单线程:QPS=1000/RT对于多线程:QPS=1000*线程数量/RT*/long time = System.currentTimeMillis() - lastMilis;System.out.println("QPS: "+ (1000*count /time));long sum = 0;long max = 0;for (int i = 0; i < times.length; i++) {for (int j = 0; j < times[i].length; j++) {sum += times[i][j];if (times[i][j] > max)max = times[i][j];}}System.out.println("Sum(ms)"+time);System.out.println("AVG(ms): " + sum / 1000000 / (count*100));System.out.println("MAX(ms): " + max / 1000000);}
}测试结果
环境:CPU 双核I7—6400HQ 系统win10
单线程下每秒产生近40万个全局ID
模拟单个服务器并发场景:
1000线程并发下每个线程产生100个ID,共生产10万个ID
- QPS: 2610
- Sum(ms)383
- AVG(ms): 0
- MAX(ms): 9
10000线程并发下每个线程产生100个ID,共生产100万个ID
- QPS: 2701
- Sum(ms)3701
- AVG(ms): 0
- MAX(ms): 9
50000线程并发下每个线程产生100个ID,共生产500万个ID
- QPS: 2720
- Sum(ms)18382
- AVG(ms): 0
- MAX(ms): 11
Ps:个人水平有限,如有错误,还请批评指正。
转载于:https://www.cnblogs.com/keeya/p/9347617.html
分布式全局ID生成器设计相关推荐
- 分布式全局ID生成器
需求背景 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识.如在美团点评的金融.支付.餐饮.酒店.猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息 ...
- 雪花算法id长度_分布式全局ID生成器(雪花算法golang无锁版)
//github地址:https://github.com/chenjie199234/Corelib/tree/master/id var offset uint64 = uint64(time.D ...
- 百度开源的分布式唯一ID生成器UidGenerator,解决了时钟回拨问题
转载自 百度开源的分布式唯一ID生成器UidGenerator,解决了时钟回拨问题 UidGenerator是百度开源的Java语言实现,基于Snowflake算法的唯一ID生成器.而且,它非常适 ...
- 7 种分布式全局 ID 生成策略,你更爱哪种?
上了微服务之后,很多原本很简单的问题现在都变复杂了,例如全局 ID 这事! 最近工作中刚好用到这块内容,于是调研了市面上几种常见的全局 ID 生成策略,稍微做了一下对比,供小伙伴们参考. 当数据库分库 ...
- 七种分布式全局 ID 生成策略,你更爱哪种?
上了微服务之后,很多原本很简单的问题现在都变复杂了,例如全局 ID 这事! 最近工作中刚好用到这块内容,于是调研了市面上几种常见的全局 ID 生成策略,稍微做了一下对比,供小伙伴们参考. 当数据库分库 ...
- php id 生产器,Laravel 分布式唯一 ID 生成器运用_PHP开发框架教程
在运用程序中,常常须要全局唯一的ID作为数据库主键.怎样生成全局唯一ID? 起首,须要肯定全局唯一ID是整型照样字符串?假如是字符串,那末现有的UUID就完整满足需求,不须要分外的事情.瑕玷是字符串作 ...
- 分布式全局唯一id实现-2 springCloud-MyBatis-Plus集成百度分布式全局id(uid-generator)
前言:MyBatis-Plus 集成百度的uid-generator ,实现业务实体在insert 实体时,可以自动获取全局id,完成数据保存: 1 uid-generator 全局id 生成的方式了 ...
- 分布式数据库id生成器的技术选型
分布式数据库id生成器的技术选型 一. 数据库自增主键 二.UUID 三.数据库或者Redis生成ID 五.雪花算法 六.LEAF 七.案例 注:本文部分内容为转载,加入自己的理解及资料 作者:晚歌y ...
- 分布式全局唯一id实现-2.1 springCloud-MyBatis-Plus集成百度分布式全局id(uid-generator)--优化版
前言:在上一篇 springCloud-MyBatis-Plus集成百度分布式全局id, id的生成全部交予程序实现,虽然可以通过集群的方式来提高id 生成服务的高可用性,但是依然需要考虑极端情况,在 ...
最新文章
- 一个普通摄像头就让二次元老婆“活”了过来,网友:求收费
- 设置ORACLE客户端字符集
- 机器学习实战(二)——k-近邻算法
- Python机器学习:梯度下降法008如何确定梯度计算的准确性,调试梯度下降法
- 28 POSIX Threads
- 【SQL Server】CONVERT() 函数
- 请求指纹认证授权秘钥使用
- Linux 痕迹清理
- mysql rollback.pl_binlog-rollback.pl 在线恢复update 和delete不加条件误操作sql
- mysql设置可以存表情_Mysql实例使MySQL能够存储emoji表情字符的设置教程
- Android Studio kotlin编程实现图片滑动浏览 stepbystep
- 看一眼就会马上收藏的宝藏设计网站
- python中plt.legend_matplotlib中plt.legend等的使用方法
- 初学C语言常见的错误
- 2021肇庆各中学高考成绩查询,广东肇庆4所高中,2020高考创佳绩,肇庆中学领跑,其他3所你可知...
- js常用实例:qq。。。
- R16 5G NR Two-Step RACH
- QT编写的学生管理系统
- FIR滤波器设计(Kaiser窗案例)
- Why HTAP Matters