深度学习机器学习面试问题准备
转自:http://blog.csdn.net/woaidapaopao/article/details/77806273
第一部分:深度学习
1、神经网络基础问题
(1)Backpropagation(要能推倒)
后向传播是在求解损失函数L对参数w求导时候用到的方法,目的是通过链式法则对参数进行一层一层的求导。这里重点强调:要将参数进行随机初始化而不是全部置0,否则所有隐层的数值都会与输入相关,这称为对称失效。
大致过程是:
首先前向传导计算出所有节点的激活值和输出值,
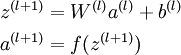
计算整体损失函数:
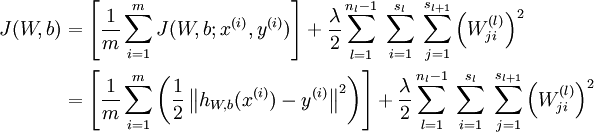
- 然后针对第L层的每个节点计算出残差(这里是因为UFLDL中说的是残差,本质就是整体损失函数对每一层激活值Z的导数),所以要对W求导只要再乘上激活函数对W的导数即可
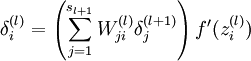
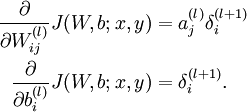
(2)梯度消失、梯度爆炸
梯度消失:这本质上是由于激活函数的选择导致的, 最简单的sigmoid函数为例,在函数的两端梯度求导结果非常小(饱和区),导致后向传播过程中由于多次用到激活函数的导数值使得整体的乘积梯度结果变得越来越小,也就出现了梯度消失的现象。
梯度爆炸:同理,出现在激活函数处在激活区,而且权重W过大的情况下。但是梯度爆炸不如梯度消失出现的机会多。
(3)常用的激活函数
| 激活函数 | 公式 | 缺点 | 优点 |
|---|---|---|---|
| Sigmoid |
σ(x)=1/(1+e−x)σ(x)=1/(1+e−x)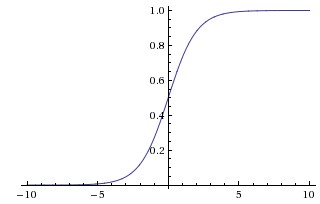
|
1、会有梯度弥散 2、不是关于原点对称 3、计算exp比较耗时 |
- |
| Tanh |
tanh(x)=2σ(2x)−1tanh(x)=2σ(2x)−1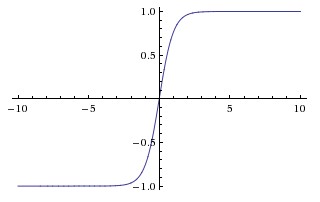
|
梯度弥散没解决 |
1、解决了原点对称问题 2、比sigmoid更快 |
| ReLU |
f(x)=max(0,x)f(x)=max(0,x)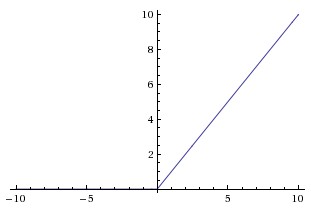
|
梯度弥散没完全解决,在(-)部分相当于神经元死亡而且不会复活 |
1、解决了部分梯度弥散问题 2、收敛速度更快 |
| Leaky ReLU | f(x)=1(x<0)(αx)+1(x>=0)(x)f(x)=1(x<0)(αx)+1(x>=0)(x) | - | 解决了神经死亡问题 |
| Maxout |
max(wT1x+b1,wT2x+b2)max(w1Tx+b1,w2Tx+b2) |
参数比较多,本质上是在输出结果上又增加了一层 | 克服了ReLU的缺点,比较提倡使用 |
(4)参数更新方法
| 方法名称 | 公式 | |
|---|---|---|
| Vanilla update | x += - learning_rate * dx | |
| Momentum update动量更新 |
v = mu * v - learning_rate * dx # integrate velocity x += v # integrate position |
|
| Nesterov Momentum |
x_ahead = x + mu * v v = mu * v - learning_rate * dx_ahead x += v |
|
|
Adagrad (自适应的方法,梯度大的方向学习率越来越小,由快到慢) |
cache += dx**2 x += - learning_rate * dx / (np.sqrt(cache) + eps) |
|
| Adam |
m = beta1*m + (1-beta1)dx v = beta2*v + (1-beta2)(dx**2) x += - learning_rate * m / (np.sqrt(v) + eps) |
(5)解决overfitting的方法
dropout, regularization, batch normalizatin,但是要注意dropout只在训练的时候用,让一部分神经元随机失活。
Batch normalization是为了让输出都是单位高斯激活,方法是在连接和激活函数之间加入BatchNorm层,计算每个特征的均值和方差进行规则化。
2、CNN问题
(1) 思想
改变全连接为局部连接,这是由于图片的特殊性造成的(图像的一部分的统计特性与其他部分是一样的),通过局部连接和参数共享大范围的减少参数值。可以通过使用多个filter来提取图片的不同特征(多卷积核)。
(2)filter尺寸的选择
通常尺寸多为奇数(1,3,5,7)
(3)输出尺寸计算公式
输出尺寸=(N - F +padding*2)/stride + 1
步长可以自由选择通过补零的方式来实现连接。
(4)pooling池化的作用
虽然通过.卷积的方式可以大范围的减少输出尺寸(特征数),但是依然很难计算而且很容易过拟合,所以依然利用图片的静态特性通过池化的方式进一步减少尺寸。
(5)常用的几个模型,这个最好能记住模型大致的尺寸参数。
| 名称 | 特点 |
|---|---|
| LeNet5 | –没啥特点-不过是第一个CNN应该要知道 |
| AlexNet | 引入了ReLU和dropout,引入数据增强、池化相互之间有覆盖,三个卷积一个最大池化+三个全连接层 |
| VGGNet | 采用1*1和3*3的卷积核以及2*2的最大池化使得层数变得更深。常用VGGNet-16和VGGNet19 |
|
Google Inception Net 我称为盗梦空间网络 |
这个在控制了计算量和参数量的同时,获得了比较好的分类性能,和上面相比有几个大的改进: 1、去除了最后的全连接层,而是用一个全局的平均池化来取代它; 2、引入Inception Module,这是一个4个分支结合的结构。所有的分支都用到了1*1的卷积,这是因为1*1性价比很高,可以用很少的参数达到非线性和特征变换。 3、Inception V2第二版将所有的5*5变成2个3*3,而且提出来著名的Batch Normalization; 4、Inception V3第三版就更变态了,把较大的二维卷积拆成了两个较小的一维卷积,加速运算、减少过拟合,同时还更改了Inception Module的结构。 |
| 微软ResNet残差神经网络(Residual Neural Network) |
1、引入高速公路结构,可以让神经网络变得非常深 2、ResNet第二个版本将ReLU激活函数变成y=x的线性函数 |
2、RNN
1、RNN原理:
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward+Neural+Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出。所以叫循环神经网络
2、RNN、LSTM、GRU区别
- RNN引入了循环的概念,但是在实际过程中却出现了初始信息随时间消失的问题,即长期依赖(Long-Term Dependencies)问题,所以引入了LSTM。
- LSTM:因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。推导forget gate,input gate,cell state, hidden information等因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸的变化是关键,下图非常明确适合记忆:

- GRU是LSTM的变体,将忘记门和输入们合成了一个单一的更新门。



3、LSTM防止梯度弥散和爆炸
LSTM用加和的方式取代了乘积,使得很难出现梯度弥散。但是相应的更大的几率会出现梯度爆炸,但是可以通过给梯度加门限解决这一问题。
4、引出word2vec
这个也就是Word Embedding,是一种高效的从原始语料中学习字词空间向量的预测模型。分为CBOW(Continous Bag of Words)和Skip-Gram两种形式。其中CBOW是从原始语句推测目标词汇,而Skip-Gram相反。CBOW可以用于小语料库,Skip-Gram用于大语料库。具体的就不是很会了。
3、GAN
1、GAN的思想
GAN结合了生成模型和判别模型,相当于矛与盾的撞击。生成模型负责生成最好的数据骗过判别模型,而判别模型负责识别出哪些是真的哪些是生成模型生成的。但是这些只是在了解了GAN之后才体会到的,但是为什么这样会有效呢?
假设我们有分布Pdata(x),我们希望能建立一个生成模型来模拟真实的数据分布,假设生成模型为Pg(x;θθ),我们的目的是求解θθ的值,通常我们都是用最大似然估计。但是现在的问题是由于我们相用NN来模拟Pdata(x),但是我们很难求解似然函数,因为我们没办法写出生成模型的具体表达形式,于是才有了GAN,也就是用判别模型来代替求解最大似然的过程。
在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
2、GAN的表达式

通过分析GAN的表达可以看出本质上就是一个minmax问题。其中V(D, G)可以看成是生成模型和判别模型的差异,而minmaxD说的是最大的差异越小越好。这种度量差异的方式实际上叫做Jensen-Shannon divergence。
3、GAN的实际计算方法
因为我们不可能有Pdata(x)的分布,所以我们实际中都是用采样的方式来计算差异(也就是积分变求和)。具体实现过程如下:

有几个关键点:判别方程训练K次,而生成模型只需要每次迭代训练一次,先最大化(梯度上升)再最小化(梯度下降)。
但是实际计算时V的后面一项在D(x)很小的情况下由于log函数的原因会导致更新很慢,所以实际中通常将后一项的log(1-D(x))变为-logD(x)。
实际计算的时候还发现不论生成器设计的多好,判别器总是能判断出真假,也就是loss几乎都是0,这可能是因为抽样造成的,生成数据与真实数据的交集过小,无论生成模型多好,判别模型也能分辨出来。解决方法有两个:1、用WGAN 2、引入随时间减少的噪声
4、对GAN有一些改进有引入f-divergence,取代Jensen-Shannon divergence,还有很多,这里主要介绍WGAN
5、WGAN
上面说过了用f-divergence来衡量两个分布的差异,而WGAN的思路是使用Earth Mover distance (挖掘机距离 Wasserstein distance)。
第二部分、机器学习准备
1、决策树树相关问题
(1)各种熵的计算
熵、联合熵、条件熵、交叉熵、KL散度(相对熵)
- 熵用于衡量不确定性,所以均分的时候熵最大
- KL散度用于度量两个分布的不相似性,KL(p||q)等于交叉熵H(p,q)-熵H(p)。交叉熵可以看成是用q编码P所需的bit数,减去p本身需要的bit数,KL散度相当于用q编码p需要的额外bits。
- 交互信息Mutual information :I(x,y) = H(x)-H(x|y) = H(y)-H(y|x) 表示观察到x后,y的熵会减少多少。
(2)常用的树搭建方法:ID3、C4.5、CART
上述几种树分别利用信息增益、信息增益率、Gini指数作为数据分割标准。
- 其中信息增益衡量按照某个特征分割前后熵的减少程度,其实就是上面说的交互信息。

- 用上述信息增益会出现优先选择具有较多属性的特征,毕竟分的越细的属性确定性越高。所以提出了信息增益率的概念,让含有较多属性的特征的作用降低。
- CART树在分类过程中使用的基尼指数Gini,只能用于切分二叉树,而且和ID3、C4.5树不同,Cart树不会在每一个步骤删除所用特征。
(3)防止过拟合:剪枝
剪枝分为前剪枝和后剪枝,前剪枝本质就是早停止,后剪枝通常是通过衡量剪枝后损失函数变化来决定是否剪枝。后剪枝有:错误率降低剪枝、悲观剪枝、代价复杂度剪枝
(4)前剪枝的几种停止条件
- 节点中样本为同一类
- 特征不足返回多类
- 如果某个分支没有值则返回父节点中的多类
- 样本个数小于阈值返回多类
2、逻辑回归相关问题
(1)公式推导一定要会
(2)逻辑回归的基本概念
这个最好从广义线性模型的角度分析,逻辑回归是假设y服从Bernoulli分布。
(3)L1-norm和L2-norm
其实稀疏的根本还是在于L0-norm也就是直接统计参数不为0的个数作为规则项,但实际上却不好执行于是引入了L1-norm;而L1norm本质上是假设参数先验是服从Laplace分布的,而L2-norm是假设参数先验为Gaussian分布,我们在网上看到的通常用图像来解答这个问题的原理就在这。
但是L1-norm的求解比较困难,可以用坐标轴下降法或是最小角回归法求解。
(4)LR和SVM对比
首先,LR和SVM最大的区别在于损失函数的选择,LR的损失函数为Log损失(或者说是逻辑损失都可以)、而SVM的损失函数为hinge loss。
其次,两者都是线性模型。
最后,SVM只考虑支持向量(也就是和分类相关的少数点)
(5)LR和随机森林区别
随机森林等树算法都是非线性的,而LR是线性的。LR更侧重全局优化,而树模型主要是局部的优化。
(6)常用的优化方法
逻辑回归本身是可以用公式求解的,但是因为需要求逆的复杂度太高,所以才引入了梯度下降算法。
一阶方法:梯度下降、随机梯度下降、mini 随机梯度下降降法。随机梯度下降不但速度上比原始梯度下降要快,局部最优化问题时可以一定程度上抑制局部最优解的发生。
二阶方法:牛顿法、拟牛顿法:
这里详细说一下牛顿法的基本原理和牛顿法的应用方式。牛顿法其实就是通过切线与x轴的交点不断更新切线的位置,直到达到曲线与x轴的交点得到方程解。在实际应用中我们因为常常要求解凸优化问题,也就是要求解函数一阶导数为0的位置,而牛顿法恰好可以给这种问题提供解决方法。实际应用中牛顿法首先选择一个点作为起始点,并进行一次二阶泰勒展开得到导数为0的点进行一个更新,直到达到要求,这时牛顿法也就成了二阶求解问题,比一阶方法更快。我们常常看到的x通常为一个多维向量,这也就引出了Hessian矩阵的概念(就是x的二阶导数矩阵)。缺点:牛顿法是定长迭代,没有步长因子,所以不能保证函数值稳定的下降,严重时甚至会失败。还有就是牛顿法要求函数一定是二阶可导的。而且计算Hessian矩阵的逆复杂度很大。
拟牛顿法: 不用二阶偏导而是构造出Hessian矩阵的近似正定对称矩阵的方法称为拟牛顿法。拟牛顿法的思路就是用一个特别的表达形式来模拟Hessian矩阵或者是他的逆使得表达式满足拟牛顿条件。主要有DFP法(逼近Hession的逆)、BFGS(直接逼近Hession矩阵)、 L-BFGS(可以减少BFGS所需的存储空间)。
3、SVM相关问题
(1)带核的SVM为什么能分类非线性问题?
核函数的本质是两个函数的內积,而这个函数在SVM中可以表示成对于输入值的高维映射。注意核并不是直接对应映射,核只不过是一个內积
(2)RBF核一定是线性可分的吗
不一定,RBF核比较难调参而且容易出现维度灾难,要知道无穷维的概念是从泰勒展开得出的。
(3)常用核函数及核函数的条件:
核函数选择的时候应该从线性核开始,而且在特征很多的情况下没有必要选择高斯核,应该从简单到难的选择模型。我们通常说的核函数指的是正定和函数,其充要条件是对于任意的x属于X,要求K对应的Gram矩阵要是半正定矩阵。
- RBF核径向基,这类函数取值依赖于特定点间的距离,所以拉普拉斯核其实也是径向基核。
- 线性核:主要用于线性可分的情况
- 多项式核
(4)SVM的基本思想:
间隔最大化来得到最优分离超平面。方法是将这个问题形式化为一个凸二次规划问题,还可以等价位一个正则化的合页损失最小化问题。SVM又有硬间隔最大化和软间隔SVM两种。这时首先要考虑的是如何定义间隔,这就引出了函数间隔和几何间隔的概念(这里只说思路),我们选择了几何间隔作为距离评定标准(为什么要这样,怎么求出来的要知道),我们希望能够最大化与超平面之间的几何间隔x,同时要求所有点都大于这个值,通过一些变化就得到了我们常见的SVM表达式。接着我们发现定义出的x只是由个别几个支持向量决定的。对于原始问题(primal problem)而言,可以利用凸函数的函数包来进行求解,但是发现如果用对偶问题(dual )求解会变得更简单,而且可以引入核函数。而原始问题转为对偶问题需要满足KKT条件(这个条件应该细细思考一下)到这里还都是比较好求解的。因为我们前面说过可以变成软间隔问题,引入了惩罚系数,这样还可以引出hinge损失的等价形式(这样可以用梯度下降的思想求解SVM了)。我个人认为难的地方在于求解参数的SMO算法。
(5)是否所有的优化问题都可以转化为对偶问题:
这个问题我感觉非常好,有了强对偶和弱对偶的概念。用知乎大神的解释吧
(6)处理数据偏斜:
可以对数量多的类使得惩罚系数C越小表示越不重视,相反另数量少的类惩罚系数变大。
4、Boosting和Bagging
(1)随机森林
随机森林改变了决策树容易过拟合的问题,这主要是由两个操作所优化的:1、Boostrap从袋内有放回的抽取样本值2、每次随机抽取一定数量的特征(通常为sqr(n))。
分类问题:采用Bagging投票的方式选择类别频次最高的
回归问题:直接取每颗树结果的平均值。
| 常见参数 | 误差分析 | 优点 | 缺点 |
|---|---|---|---|
|
1、树最大深度 2、树的个数 3、节点上的最小样本数 4、特征数(sqr(n)) |
oob(out-of-bag) 将各个树的未采样样本作为预测样本统计误差作为误分率 |
可以并行计算 不需要特征选择 可以总结出特征重要性 可以处理缺失数据 不需要额外设计测试集 |
在回归上不能输出连续结果 |
(2)Boosting之AdaBoost
Boosting的本质实际上是一个加法模型,通过改变训练样本权重学习多个分类器并进行一些线性组合。而Adaboost就是加法模型+指数损失函数+前项分布算法。Adaboost就是从弱分类器出发反复训练,在其中不断调整数据权重或者是概率分布,同时提高前一轮被弱分类器误分的样本的权值。最后用分类器进行投票表决(但是分类器的重要性不同)。
(3)Boosting之GBDT
将基分类器变成二叉树,回归用二叉回归树,分类用二叉分类树。和上面的Adaboost相比,回归树的损失函数为平方损失,同样可以用指数损失函数定义分类问题。但是对于一般损失函数怎么计算呢?GBDT(梯度提升决策树)是为了解决一般损失函数的优化问题,方法是用损失函数的负梯度在当前模型的值来模拟回归问题中残差的近似值。
注:由于GBDT很容易出现过拟合的问题,所以推荐的GBDT深度不要超过6,而随机森林可以在15以上。
(4)GBDT和Random Forest区别
这个就和上面说的差不多。
(5)Xgboost
这个工具主要有以下几个特点:
- 支持线性分类器
- 可以自定义损失函数,并且可以用二阶偏导
- 加入了正则化项:叶节点数、每个叶节点输出score的L2-norm
- 支持特征抽样
- 在一定情况下支持并行,只有在建树的阶段才会用到,每个节点可以并行的寻找分裂特征。
5、KNN和Kmean
(1)KNN 和Kmean缺点
都属于惰性学习机制,需要大量的计算距离过程,速度慢的可以(但是都有相应的优化方法)。
(2)KNN
KNN不需要进行训练,只要对于一个陌生的点利用离其最近的K个点的标签判断其结果。KNN相当于多数表决,也就等价于经验最小化。而KNN的优化方式就是用Kd树来实现。
(3)Kmean
要求自定义K个聚类中心,然后人为的初始化聚类中心,通过不断增加新点变换中心位置得到最终结果。Kmean的缺点可以用Kmean++方法进行一些解决(思想是使得初始聚类中心之间的距离最大化)
6、EM算法、HMM、CRF
这三个放在一起不是很恰当,但是有互相有关联,所以就放在这里一起说了。注意重点关注算法的思想。
(1)EM算法
EM算法是用于含有隐变量模型的极大似然估计或者极大后验估计,有两步组成:E步,求期望(expectation);M步,求极大(maxmization)。本质上EM算法还是一个迭代算法,通过不断用上一代参数对隐变量的估计来对当前变量进行计算,直到收敛。
注意:EM算法是对初值敏感的,而且EM是不断求解下界的极大化逼近求解对数似然函数的极大化的算法,也就是说EM算法不能保证找到全局最优值。对于EM的导出方法也应该掌握。
(2)HMM算法
隐马尔可夫模型是用于标注问题的生成模型。有几个参数(ππ,A,B):初始状态概率向量ππ,状态转移矩阵A,观测概率矩阵B。称为马尔科夫模型的三要素。
马尔科夫三个基本问题:
- 概率计算问题:给定模型和观测序列,计算模型下观测序列输出的概率。–》前向后向算法
- 学习问题:已知观测序列,估计模型参数,即用极大似然估计来估计参数。–》Baum-Welch(也就是EM算法)和极大似然估计。
- 预测问题:已知模型和观测序列,求解对应的状态序列。–》近似算法(贪心算法)和维比特算法(动态规划求最优路径)
(3)条件随机场CRF
给定一组输入随机变量的条件下另一组输出随机变量的条件概率分布密度。条件随机场假设输出变量构成马尔科夫随机场,而我们平时看到的大多是线性链条随机场,也就是由输入对输出进行预测的判别模型。求解方法为极大似然估计或正则化的极大似然估计。
之所以总把HMM和CRF进行比较,主要是因为CRF和HMM都利用了图的知识,但是CRF利用的是马尔科夫随机场(无向图),而HMM的基础是贝叶斯网络(有向图)。而且CRF也有:概率计算问题、学习问题和预测问题。大致计算方法和HMM类似,只不过不需要EM算法进行学习问题。
(4)HMM和CRF对比
其根本还是在于基本的理念不同,一个是生成模型,一个是判别模型,这也就导致了求解方式的不同。
7、常见基础问题
(1)数据归一化(或者标准化,注意归一化和标准化不同)的原因
要强调:能不归一化最好不归一化,之所以进行数据归一化是因为各维度的量纲不相同。而且需要看情况进行归一化。
- 有些模型在各维度进行了不均匀的伸缩后,最优解与原来不等价(如SVM)需要归一化。
- 有些模型伸缩有与原来等价,如:LR则不用归一化,但是实际中往往通过迭代求解模型参数,如果目标函数太扁(想象一下很扁的高斯模型)迭代算法会发生不收敛的情况,所以最坏进行数据归一化。
补充:其实本质是由于loss函数不同造成的,SVM用了欧拉距离,如果一个特征很大就会把其他的维度dominated。而LR可以通过权重调整使得损失函数不变。
(2)衡量分类器的好坏:
这里首先要知道TP、FN(真的判成假的)、FP(假的判成真)、TN四种(可以画一个表格)。
几种常用的指标:
- 精度precision = TP/(TP+FP) = TP/~P (~p为预测为真的数量)
- 召回率 recall = TP/(TP+FN) = TP/ P
- F1值: 2/F1 = 1/recall + 1/precision
- ROC曲线:ROC空间是一个以伪阳性率(FPR,false positive rate)为X轴,真阳性率(TPR, true positive rate)为Y轴的二维坐标系所代表的平面。其中真阳率TPR = TP / P = recall, 伪阳率FPR = FP / N
(3)SVD和PCA
PCA的理念是使得数据投影后的方差最大,找到这样一个投影向量,满足方差最大的条件即可。而经过了去除均值的操作之后,就可以用SVD分解来求解这样一个投影向量,选择特征值最大的方向。
(4)防止过拟合的方法
过拟合的原因是算法的学习能力过强;一些假设条件(如样本独立同分布)可能是不成立的;训练样本过少不能对整个空间进行分布估计。
处理方法:
- 早停止:如在训练中多次迭代后发现模型性能没有显著提高就停止训练
- 数据集扩增:原有数据增加、原有数据加随机噪声、重采样
- 正则化
- 交叉验证
- 特征选择/特征降维
(5)数据不平衡问题
这主要是由于数据分布不平衡造成的。解决方法如下:
- 采样,对小样本加噪声采样,对大样本进行下采样
- 进行特殊的加权,如在Adaboost中或者SVM中
- 采用对不平衡数据集不敏感的算法
- 改变评价标准:用AUC/ROC来进行评价
- 采用Bagging/Boosting/ensemble等方法
- 考虑数据的先验分布
转载于:https://www.cnblogs.com/houjun/p/8535471.html
深度学习机器学习面试问题准备相关推荐
- 深度学习机器学习面试问题准备(必会)
深度学习机器学习面试问题准备(必会) 第一部分:深度学习 1.神经网络基础问题 (1)Backpropagation(要能推倒) 后向传播是在求解损失函数L对参数w求导时候用到的方法,目的是通过链式 ...
- [面试笔试整理1]:深度学习机器学习面试问题准备(必会)
此系列三篇文章的原文链接 面试笔试整理1:深度学习机器学习面试问题准备(必会) 1.神经网络基础问题 (1)Backpropagation(要能推倒) 后向传播是在求解损失函数L对参数w求导时候用到的 ...
- 面试笔试整理3:深度学习机器学习面试问题准备(必会)
第一部分:深度学习 原文:https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 1.神 ...
- 计算机视觉面试宝典--深度学习机器学习基础篇(四)
计算机视觉面试宝典–深度学习机器学习基础篇(四) 本篇主要包含SVM支持向量机.K-Means均值以及机器学习相关常考内容等相关面试经验. SVM-支持向量机 支持向量机(support vector ...
- 深度学习机器学习面试题——GAN
深度学习机器学习笔试面试题--GAN 提示:互联网大厂可能会考的笔试面试题 GAN是用来干什么的,怎么用的,介绍一下 GANs的优缺点是什么? GAN为什么不好收敛 为什么GAN中的优化器不常用SGD ...
- 深度学习机器学习面试题——损失函数
深度学习机器学习面试题--损失函数 提示:重要的深度学习机器学习面试题,大厂可能会在笔试面试中考 说一下你了解的损失函数? 说说你平时都用过什么损失函数,各自什么特点? 交叉熵函数与最大似然函数的联系 ...
- 深度学习机器学习面试题——自然语言处理NLP,transformer,BERT,RNN,LSTM
深度学习机器学习面试题--自然语言处理NLP,transformer,BERT,RNN,LSTM 提示:互联网大厂常考的深度学习基础知识 LSTM与Transformer的区别 讲一下Bert原理,B ...
- 深度学习机器学习面试题汇——模型优化,轻量化,模型压缩
深度学习机器学习面试题汇--模型优化,轻量化,模型压缩 提示:互联网大厂可能考的面试题 若CNN网络很庞大,在手机上运行效率不高,对应模型压缩方法有了解吗 介绍一下模型压缩常用的方法?为什么用知识蒸馏 ...
- 信号处理深度学习机器学习_机器学习和信号处理如何融合?
信号处理深度学习机器学习 As a design engineer, I am increasingly exposed to more complex engineering challenges ...
最新文章
- 完美避坑!记一次Elasticsearch集群迁移架构实战
- support library目录解释说明内容
- SharePoint 2013 Search REST API 使用示例
- mysql修改存储引擎报错,MySQL改变表的存储引擎
- 关于SOCKET中send和recv函数工作原理总结
- JAVA解析纯真IP地址库
- JQuery树插件——ztree
- 【报告分享】2019互联网大会大佬演讲实录 (附11个演讲文档下载链接)
- StreamInsight查询系列汇总
- 【20211228】【信号处理】从 Matlab 仿真角度理解频谱泄露
- #import 指令 (C++)
- python对excel操作简书_python Excel 写
- Mybatis 多层嵌套查询(高级结果映射)
- 卸载包时不要简单的用 uninstall !!
- 三栏布局的七种实现方式
- mysql数据库j电子课件,MYSQL数据库技术分享PPT演示课件
- Python 3.10来了,switch语法终于出现
- java中word导入数据库
- 首个5G智慧机场落地广州 速度是4G的50倍
- php顺序结构例题,php顺序结构就象一条直线,按照语句出现的先后顺序依次执行...