深度学习训练,选择P100就对了
1.背景
去年4月,NVIDIA推出了Tesla P100加速卡,速度是NVIDIA之前高端系统的12倍。同年9月的GTC China 2016大会,NVIDIA又发布了Tesla P4、P40两款深度学习芯片。Tesla P100主攻学习和训练任务,而Tesla P4&P40主要负责图像、文字和语音识别。
同为Pascal架构且运算能力接近的P100和P40常常被拿来对比,单看Spec上运算能力,似乎P40比P100的深度学习性能更好,但实际上呢?本文就通过使用NVCaffe、MXNet、TensorFlow三个主流开源深度学习框架对P100和P40做性能实测来揭晓答案吧。
2.初步分析
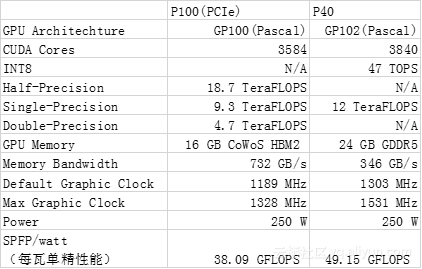
我们先来看下P100和P40的Spec参数指标。从参数来看,的确是P40的单精运算能力强于P100,而深度学习训练普遍使用单精度浮点类型,是衡量深度学习性能的一个重要指标。P40支持IN8类型,所以非常适合精度要求不高的推理场景,24G的显存也非常适合在线处理大数据量的图像等。但是P100搭载的是HBM2高速显存,而P40只搭载了GDDR5的显存,这使得P100的显存带宽达到了P40的2倍多,而这是影响深度学习训练的另一个重要指标,在训练中会有大量的显存操作,对显存带宽要求很高。这一点很可能会制约P40的训练性能。当然这需要实测的数据来验证,下一节是我们的实测数据。
3.实测数据
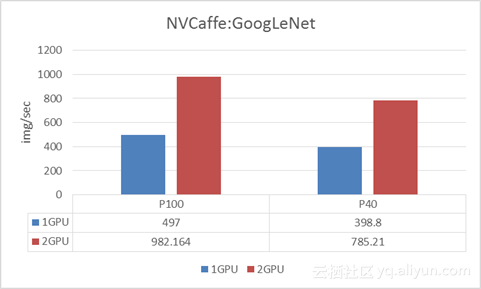
3.1 NVCaffe:GoogLeNet
使用ImageNet ILSVRC2012数据集,其中训练图片1281167张, 验证测试图片 5万张,数据单位是Images/Second(每秒处理的图像张数),OOM表示Batch Size太大导致GPU显存不够。
测试数据如下:
不同Batch Size单卡性能对比:

最大性能对比:
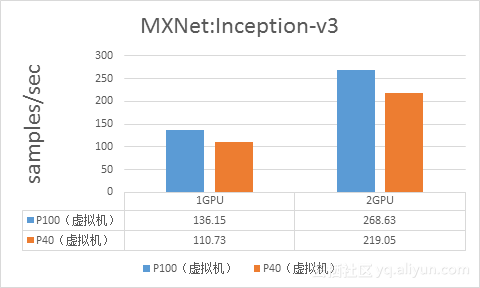
3.2 MXNet:Inception-v3
使用Benchmark模式测试Imagenet训练,数据单位samples/sec,测试数据如下:
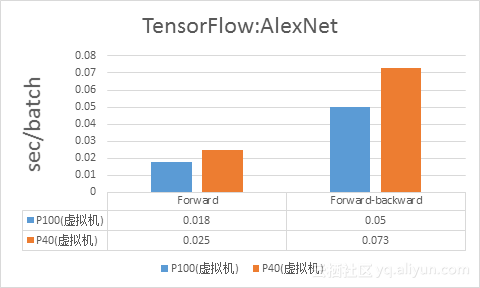
3.3 TensorFlow:AlexNet
TensorFlow使用AlexNet Benchmark模式测试单GPU Forward和Forward-backward作为比较参考,数据单位sec/ batch,越小性能越好。
P100与P40比较的单GPU测试数据如下:
4 测试结论
通过实测NVCaffe、MXNet、TensorFlow三个主流深度学习框架的图像分类训练性能,验证了我们前面的分析,P40虽然计算力优于P100,但是受限于显存带宽,在深度学习训练上性能是不如P100的,通过实测数据,我们可以得出结论:P100比P40训练性能至少高出20%以上。
深度学习训练,选择P100就对了。
阿里云上提供的GN5系列GPU实例,可搭载最多8块P100 GPU,可大大加速深度学习训练,搭载最新V100 GPU的GN6实例近期也已经上线公测,我们后续也会给出GN6实例的性能评测报告。
深度学习训练,选择P100就对了相关推荐
- Tutorial教程:知错就改,错了就罚,论训练深度学习如何选择损失函数
Tutorial教程:训练深度学习如何选择损失函数 xingbod@gmail.com 声明:本文为CSDN首发,谢绝转载,商业转载请联系笔者MrCharles本人获取同意 作为优化算法的一部分,必须 ...
- 深度干货!如何将深度学习训练性能提升数倍?
作者 | 车漾,阿里云高级技术专家 顾荣,南京大学副研究员 责编 | 唐小引 头图 | CSDN 下载自东方 IC 出品 | CSDN(ID:CSDNnews) 近些年,以深度学习为代表的人工智能技术 ...
- 深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化
作者 | 车漾(阿里云高级技术专家).顾荣(南京大学 副研究员) 导读:Alluxio 项目诞生于 UC Berkeley AMP 实验室,自开源以来经过 7 年的不断开发迭代,支撑大数据处理场景的数 ...
- 阿里云原生实践:基于 Alluxio 数据缓存的大规模深度学习训练性能优化
导读:Alluxio 项目诞生于 UC Berkeley AMP 实验室,自开源以来经过 7年的不断开发迭代,支撑大数据处理场景的数据统一管理和高效缓存功能日趋成熟.然而,随着云原生人工智能(Clou ...
- 不止GPU!这些硬件也影响着深度学习训练速度
有志于投身人工智能研究的青年,在关注计算机专业选择时,也不妨先了解一下影响深度学习训练速度的种种因素. 本文实验数据来源:知乎@Justin ho 工程师之于计算机就相当于赛车手对待跑车一样,必须十分 ...
- 深度学习 训练吃显卡_深度学习小钢炮攒机心得:规避一些你看不到的坑
------------------- 已经2017年了,从90年代初的品牌机流行,90年代末的组装机流行,2000-2010桌面级逐渐被移动PC/Mac取代,一直到现在移动终端大行其道,攒机似乎已经 ...
- TensorRT深度学习训练和部署图示
TensorRT深度学习训练和部署 NVIDIA TensorRT是用于生产环境的高性能深度学习推理库.功率效率和响应速度是部署的深度学习应用程序的两个关键指标,因为它们直接影响用户体验和所提供服务的 ...
- MLPerf结果证实至强® 可有效助力深度学习训练
MLPerf结果证实至强® 可有效助力深度学习训练 · 核心与视觉计算事业部副总裁Wei Li通过博客回顾了英特尔这几年为提升深度学习性能所做的努力. · 目前根据英特尔® 至强® 可扩展处理器的ML ...
- 深度学习——训练时碰到的超参数
深度学习--训练时碰到的超参数 文章目录 深度学习--训练时碰到的超参数 一.前言 二.一些常见的超参数 学习率(Learning rate) 迭代次数(iteration) batchsize e ...
最新文章
- php 入口文件引入取别名,php命名空间别名/导入
- Dev 等待提示 WaitDialogForm 升级版
- 项目管理杂感(2)──继续说项目管理的目标
- php常用操作数组函数,PHP常见数组函数用法小结
- 再观手游市场新风口-二次元游戏
- LeetCode 1894. 找到需要补充粉笔的学生编号
- gcc_教程中的命令
- JS原型继承工作原理
- NYOJ--24素数距离问题
- 关于三极管的理解---根据IC符号简易迅速判断三极管导通情况
- 【分布式】psutil cpu_percent如何使用;python如何测试cpu的使用率
- ant pro-table点击表格行高亮显示
- c语言 交通处罚单管理程序 typedef struct,交通罚单.doc
- MacBook下疑难杂症诊断攻略
- 解决VirtualBox虚拟电脑控制台严重错误
- Android 启动“无启动图标的 apk“
- iOS与unity交互、opencv 草稿
- 机器学习笔记(机器学习很难么???那必然难啊!!!)
- 队内基本伺服系统与传感系统
- RedisTemplate写入Redis数据出现无意义乱码前缀\xac\xed\x00\x05