02-NLP-01-python正则表达式
Python正则表达式
by 寒小阳(hanxiaoyang.ml@gmail.com)
正则表达式是处理字符串的强大工具,拥有独特的语法和独立的处理引擎。
我们在大文本中匹配字符串时,有些情况用str自带的函数(比如find, in)可能可以完成,有些情况会稍稍复杂一些(比如说找出所有“像邮箱”的字符串,所有和julyedu相关的句子),这个时候我们需要一个某种模式的工具,这个时候正则表达式就派上用场了。
说起来正则表达式效率上可能不如str自带的方法,但匹配功能实在强大太多。对啦,正则表达式不是Python独有的,如果已经在其他语言里使用过正则表达式,这里的说明只需要简单看一看就可以上手啦。
1.语法
废话少说,直接上技能
下面是一张有些同学比较熟的图,我们俗称python正则表达式小抄,把写正则表达式当做一个开卷考试,显然容易得多。
当你要匹配 一个/多个/任意个 数字/字母/非数字/非字母/某几个字符/任意字符,想要 贪婪/非贪婪匹配,想要捕获匹配出来的 第一个/所有 内容的时候,记得这里有个小手册供你参考。
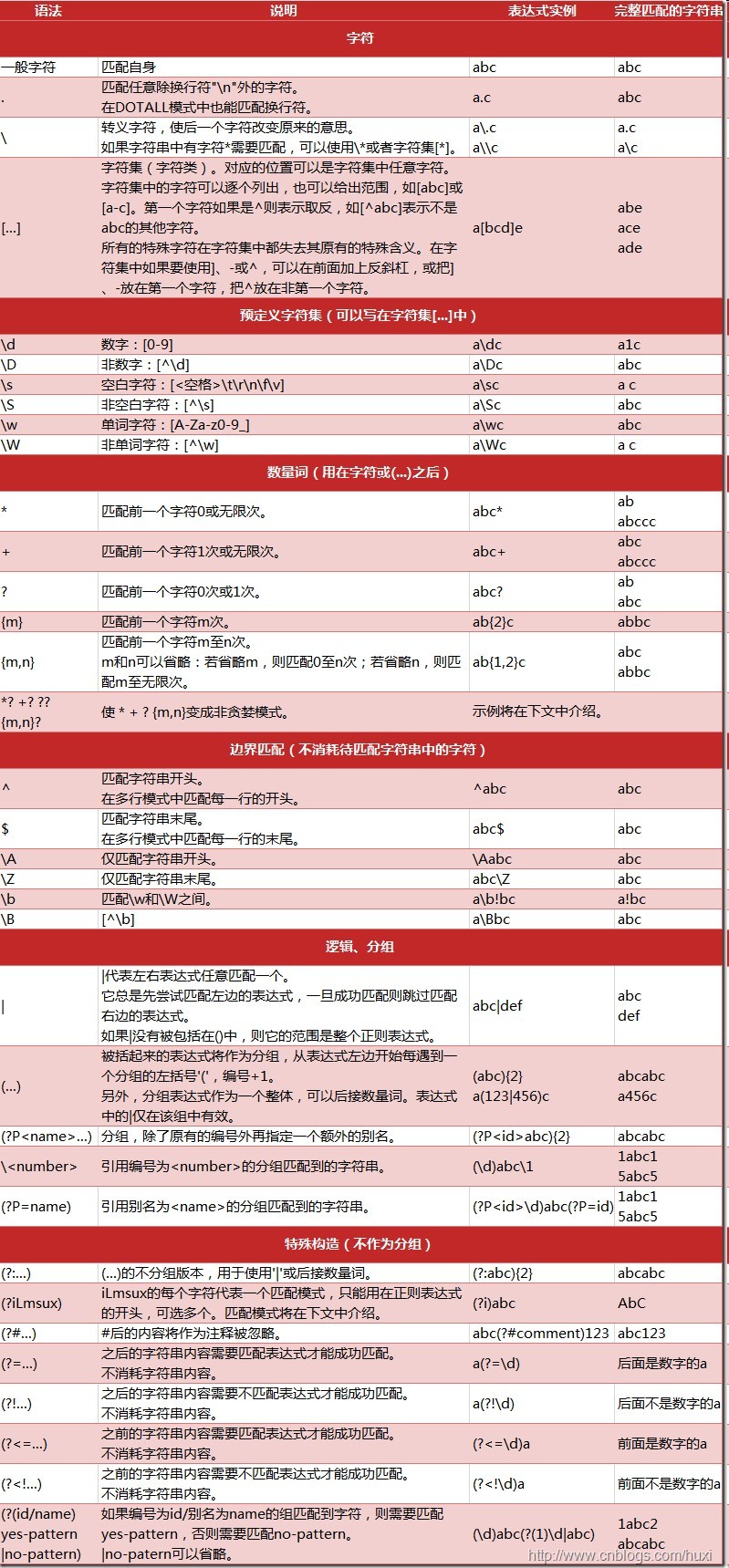
2.验证工具
我们最喜爱的正则表达式在线验证工具之一是http://regexr.com/
谁用谁知道,用过一次以后欲罢不能。

3.挑战与提升
长期做自然语言处理的同学正则表达式都非常熟,曾经有半年写了大量的正则表达式,以至于同事间开玩笑说,只要是符合某种规律或者模式的串,肯定分分钟能匹配出来。
对于想练习正则表达式,或者短期内快速get复杂技能,or想挑战更复杂的正则表达式的同学们。 请戳正则表达式进阶练习
so, 各位宝宝enjoy yourself

4.Python案例
re模块
Python通过re模块提供对正则表达式的支持。
使用re的一般步骤是
- 1.将正则表达式的字符串形式编译为Pattern实例
- 2.使用Pattern实例处理文本并获得匹配结果(一个Match实例)
- 3.使用Match实例获得信息,进行其他的操作。
# encoding: UTF-8
import re# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello.*\!') # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None match = pattern.match('hello, hanxiaoyang! How are you?') if match: # 使用Match获得分组信息 print match.group() hello, hanxiaoyang!
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。
第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。
当然,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)等价于re.compile('(?im)pattern')
flag可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- re.S(DOTALL): 点任意匹配模式,改变'.'的行为
- re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
regex_1 = re.compile(r"""\d + # 数字部分 \. # 小数点部分 \d * # 小数的数字部分""", re.X) regex_2 = re.compile(r"\d+\.\d*")
Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
match属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 - groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 - groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 - end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g引用分组,但不能使用编号0。\id与\g是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
import re m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello hanxiaoyang!')#利用空格分为两组,空格前为一组,空格后为一组 print "m.string:", m.string print "m.re:", m.re #re模块实例化后的一个对象 print "m.pos:", m.pos #从哪里开始匹配,可以自行指定,如果没有指定的话,默认从0开始 print "m.endpos:", m.endpos print "m.lastindex:", m.lastindex print "m.lastgroup:", m.lastgroup print "m.group(1,2):", m.group(1, 2) #匹配结果按照元祖形式返回来,1表示元祖第一项,2表示第二项 print "m.groups():", m.groups() #返回所有的分组 print "m.groupdict():", m.groupdict() # print "m.start(2):", m.start(2) #第二个分组的起始位置 print "m.end(2):", m.end(2) #第二个分组的终止位置 print "m.span(2):", m.span(2) #把开始和结束按照元祖的形式一起返回 print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')
m.string: hello hanxiaoyang!
m.re: <_sre.SRE_Pattern object at 0x10b111be0>
m.pos: 0
m.endpos: 18
m.lastindex: 3
m.lastgroup: sign
m.group(1,2): ('hello', 'hanxiaoyang')
m.groups(): ('hello', 'hanxiaoyang', '!')
m.groupdict(): {'sign': '!'}
m.start(2): 6
m.end(2): 17
m.span(2): (6, 17)
m.expand(r'\2 \1\3'): hanxiaoyang hello!
Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
import re p = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL) print "p.pattern:", p.pattern print "p.flags:", p.flags print "p.groups:", p.groups print "p.groupindex:", p.groupindex
p.pattern: (\w+) (\w+)(?P<sign>.*)
p.flags: 16
p.groups: 3
p.groupindex: {'sign': 3}
使用pattern
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern:- 如果pattern结束时仍可匹配,则返回一个Match对象
- 如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
- pos和endpos的默认值分别为0和len(string)。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
- search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法从string的pos下标处起尝试匹配pattern- 如果pattern结束时仍可匹配,则返回一个Match对象
- 若无法匹配,则将pos加1后重新尝试匹配,直到pos=endpos时仍无法匹配则返回None。
- pos和endpos的默认值分别为0和len(string))
# encoding: UTF-8
import re # 将正则表达式编译成Pattern对象
pattern = re.compile(r'H.*g') # 使用search()查找匹配的子串,不存在能匹配的子串时将返回None # 这个例子中使用match()无法成功匹配 match = pattern.search('hello Hanxiaoyang!') if match: # 使用Match获得分组信息 print match.group() Hanxiaoyang
- split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
- 按照能够匹配的子串将string分割后返回列表。
- maxsplit用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'\d+') #指定分割模式:都以数字来分割(连续有几个出现都进行匹配) print p.split('one1two2232three3four4') ['one', 'two', 'three', 'four', '']
- findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
- 搜索string,以列表形式返回全部能匹配的子串。
- 在原始串上做匹配取得我们想要的信息
import rep = re.compile(r'\d+') print p.findall('one1two2three3four4') ['1', '2', '3', '4']
- finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
- 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
import rep = re.compile(r'\d+') for m in p.finditer('one1two2three3four4'): print m.group()- sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
- 使用repl替换string中每一个匹配的子串后返回替换后的字符串。
- 当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
- 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count用于指定最多替换次数,不指定时全部替换。
- 使用repl替换string中每一个匹配的子串后返回替换后的字符串。
import rep = re.compile(r'(\w+) (\w+)') #只要遇到空格就划分成两个小组 s = 'i say, hello hanxiaoyang!' print p.sub(r'\2 \1', s) #将两个个分组换位置 def func(m): return m.group(1).title() + ' ' + m.group(2).title() #分组的首字母大写 print p.sub(func, s)
say i, hanxiaoyang hello! I Say, Hello Hanxiaoyang!
- subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
- 返回 (sub(repl, string[, count]), 替换次数)。 获取出匹配的次数
import rep = re.compile(r'(\w+) (\w+)') s = 'i say, hello hanxiaoyang!' print p.subn(r'\2 \1', s) def func(m): return m.group(1).title() + ' ' + m.group(2).title() print p.subn(func, s)
('say i, hanxiaoyang hello!', 2)
('I Say, Hello Hanxiaoyang!', 2)转载于:https://www.cnblogs.com/Josie-chen/p/9120765.html
02-NLP-01-python正则表达式相关推荐
- Python正则表达式(正则、regular、re)讲解,及常用正则:匹配邮箱、身份证、手机号、IP地址、URL、HTML等
正则表达式(正则.regular.re)是 Python 中最常见的编程技巧,很多时候,一个好的正则表达式可以抵上几十行代码.比如:匹配(校验)邮箱.身份证.手机号.IP地址.URL.HTML等. 正 ...
- python 结尾回车_理解不了Python正则表达式?我帮你搞定
点击蓝字"python教程"关注我们哟! 在学习Python的过程中,我们难免会遇到比较晦涩.难以理解的内容,比如Python中的正则表达式.面向对象等内容,为了更好地帮助大家理解 ...
- python 逆向生成正则表达式_一篇搞定Python正则表达式
1. 正则表达式语法 1.1 字符与字符类 1 特殊字符:.^$?+*{}[]()| 以上特殊字符要想使用字面值,必须使用进行转义 2 字符类 1. 包含在[]中的一个或者多个字符被称为字符类,字符类 ...
- python正则表达式处理txt,python 正则表达式参数替换实例详解 python使用正则表达式替换txt内容...
Python正则表达式如何进行字符串替换实例 import res = 'adds23dd56'ss = re.sub(r'\d', '*', s)>>> ss'adds**dd** ...
- python正则表达式需要模块_使用Python正则表达式模块,让操作更加简单
处理文本数据的一个主要任务就是创建许多以文本为基础的特性. 人们可能想要在文本中找出特定格式的内容,比如找出存在于文本中的电子邮件,或者大型文本中的电话号码. 虽然想要实现上述功能听起来很繁琐,但是如 ...
- 干货 | 请收下这份2018学习清单:150个最好的机器学习,NLP和Python教程
本文英文出处:Robbie Allen 翻译/雷锋网字幕组 吴楚 校对/ 雷锋网 田晋阳 机器学习的发展可以追溯到1959年,有着丰富的历史.这个领域也正在以前所未有的速度进化.在之前的一篇文章中,我 ...
- Python正则表达式集锦
if 你只有5min: 读Python的正则提取技巧 return else: Python正则表达式指南 Python正则表达式的用法 Python正则表达式操作指南 match和search的区别 ...
- [小小明]Python正则表达式速查表与实操手册
v0.3下载地址:https://download.csdn.net/download/as604049322/14504394 目录 文章目录 文档简介 作者简介 阅读建议 版权声明 Python ...
- Python正则表达式(regular expression)简介-re模块
Python正则表达式(regular expression)简介-re模块 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 就其本质而言,正则表达式(或RE模块)是一种小型的,高度 ...
- python正则表达式面试_python-面试题
1.如何判断一个python对象的类型? print type(2017) print type('junxi') 2.python里面如何生存随机数? import random num = ran ...
最新文章
- 结合项目实例 回顾传统设计模式(二)观察者模式
- Spring的一些资源
- 【MYSQL】常用命令备忘录
- Bit-Z推出去中心化多链钱包CoinU 打造资产价值生态体系
- JavaWeb学习总结(五十三)——Web应用中使用JavaMail发送邮件
- JS之onsubmit事件与组织事件外延
- 神经网络与深度学习——TensorFlow2.0实战(笔记)(三)(python常量、变量和表达式)
- 日志级别_SpringBoot实战(十三):Admin动态修改日志级别
- redux-saga基本用法
- django多语言支持
- 常见Spring异常
- Pytorch:损失函数
- 数据结构与算法之KMP算法中Next数组代码原理分析
- oracle创建只读视图语句,使用语句创建视图(6)——设置视图约束(check option)...
- 机器学习训练数据集图片标注工具推荐
- php对接微信调用不到头像,【微信公众号小程序】微擎获取用户头像失败的问题如何处理— 亲测 可用 持续更新...
- 被老程序员压榨怎么办?我不想辞职
- 深度学习数据增强(data_augmentation):Keras ImageDataGenerator
- 计算机毕业设计Java桌游店会员管理系统(源码+系统+mysql数据库+Lw文档)
- Xcode插件所在的目录:~/Library/Application Support/Developer/Shared/Xcode/Plug-ins