【我的区块链之路】- golang实现主流查找算法
【转载请标明出处】https://blog.csdn.net/qq_25870633/article/details/82705217
查找算法相信各位大佬都不是很陌生吧!很多时候我们需要快速的从某些集合中快速的找到我们想要的内容,或者说我们需要快速的判断某些内容是否存在于某集合中,这就涉及到了查找算法!主要是我最近要去面试了,在复习,所以顺便总结总结查找算法了,免得面试的时候有些吊毛让我手写算法就尴尬了~
查找算法分类:
1)静态查找和动态查找;
注:静态或者动态都是针对查找表而言的。动态表指查找表中有删除和插入操作的表。
2)无序查找和有序查找。
无序查找:被查找数列有序无序均可;
有序查找:被查找数列必须为有序数列。
首先我们先看看查找算法一般都有哪一些,
七大查找算法:顺序查找、二分查找、差值查找、斐波那契查找、 树表查找 (二叉树查找、平衡查找树之2-3查找树、平衡查找树之红黑树、B树和B+树)、分块查找、哈希查找、图查找 (广度优先查找、深度优先查找)
顺序查找:
属于线性查找、无序查找;说白了就是从头找到尾
二分查找:
二分查找,顾名思义是对一段序列不断的做折半对比,最终找出目标值的方式
适用场景:
有序的,非动态的序列
如代码:
func binarySearch(arr []int, k int) int {left, right, mid := 1, len(arr), 0for {// mid向下取整mid = int(math.Floor(float64((left + right) / 2)))if arr[mid] > k {// 如果当前元素大于k,那么把right指针移到mid - 1的位置right = mid - 1} else if arr[mid] < k {// 如果当前元素小于k,那么把left指针移到mid + 1的位置left = mid + 1} else {// 否则就是相等了,退出循环break}// 判断如果left大于right,那么这个元素是不存在的。返回-1并且退出循环if left > right {mid = -1break}}// 输入元素的下标return mid
}func binarySearch2(sortedArray []int, lookingFor int) int {var low int = 0var high int = len(sortedArray) - 1for low <= high {var mid int =low + (high - low)/2var midValue int = sortedArray[mid]if midValue == lookingFor {return mid} else if midValue > lookingFor {high = mid -1} else {low = mid + 1}}return -1
}func binarySearch3(arr []int, k int) int {low := 0high := len(arr) - 1for low <= high {// 这种写法防止两数和导致的内存溢出mid := low + (high-low)>>1 // avg=(a+b)>>1://右移表示除2,左移表示乘2 if k < arr[mid] {high = mid - 1} else if k > arr[mid] {low = mid + 1} else {return mid}}return -1
}func binarySearch4(arr []int, k int) int {low := 0high := len(arr) - 1for low <= high {/**利用位与(&)提取出两个数相同的部分,利用异或(^)拿出两个数不同的部分的和,相同的部分加上不同部分的和除2即得到两个数的平均值异或: 相同得零,不同得1 == 男男等零,女女得零,男女得子avg = (a&b) + (a^b)>>1;或者avg = (a&b) + (a^b)/2;*/mid := low & high + (low ^ high) >> 1if k < arr[mid] {high = mid - 1} else if k > arr[mid] {low = mid + 1} else {return mid}}return -1
}【注】:第三、第四种方法逼格最高,第四种效率最快
差值查找:
折半查找的进化版,自适应中间值 根据 (关键值 - 起始值) / (末位值 - 起始值) 的比例来决定中间值的下标,这样能够快速的缩小查找范围,会比直接折半好很多
适用场景:
有序的,非动态的序列
如代码:
func insertSearch(arr []int, key int) int{low := 0high := len(arr) - 1time := 0for low < high {time += 1// 计算mid值是插值算法的核心代码 实际上就是mid := low + int((high - low) * (key - arr[low])/(arr[high] - arr[low]))if key < arr[mid] {high = mid - 1}else if key > arr[mid] {low = mid + 1}else {return mid}}return -1
}斐波那契查找:
在介绍斐波那契查找算法之前,我们先介绍一下很它紧密相连并且大家都熟知的一个概念:黄金分割。
黄金比例又称黄金分割,是指事物各部分间一定的数学比例关系,即将整体一分为二,较大部分与较小部分之比等于整体与较大部分之比,其比值约为1:0.618或1.618:1。
0.618 被公认为最具有审美意义的比例数字,斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(从第三个数开始,后边每一个数都是前两个数的和)。然后我们会发现,随着斐波那契数列的递增,前后两个数的比值会越来越接近0.618,利用这个特性,我们就可以将黄金比例运用到查找技术中。
![]()
也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
适用场景:
有序的,非动态的序列
如代码:
/**
基本思想:利用黄金分割 0.168 :1 来确定中间值;也是二分查找一种改进版
用文字来说,就是费波那契数列由0和1开始,之后的费波那契系数就是由之前的两数相加而得出。
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233…… 特别指出:0不是第一项,而是第零项数列的值为: F(0)=0,F(1)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*) n为数组下标|--------------- F(K)-1 ---------------|low mid high|______________________|_______________||------- F(K-1)-1 -----|--- F(K-2)-1 --|他要求开始表中记录的个数为某个斐波那契数小1,即n = F(k)-1;开始将key值(要查找的数据)与第F(k-1)位置的记录进行比较(即mid = low + F(k-1) - 1),比较结果也分为三种:(1)相等,mid位置的元素即为所求;(2)大于,low=mid+1,k-=2。说明:low=mid+1 :说明待查找的元素在[mid+1,high]范围内,k-=2 :说明范围[mid+1,high]内的元素个数为n-(F(k-1))= Fk-1-F(k-1)=Fk-F(k-1)-1=F(k-2)-1个,所以可以递归的应用斐波那契查找。(3)小于,high=mid-1,k-=1。说明:low=mid+1说明待查找的元素在[low,mid-1]范围内,k-=1 说明范围[low,mid-1]内的元素个数为F(k-1)-1个,所以可以递归 的应用斐波那契查找*/
func fibonacciSearch (arr []int, key int) int {// 生成裴波那契数列,因为我们要满足 len(arr) = F(k) - 1fibArr := make([]int, 0)// 因为 斐波那契数列的性质我们知道数据递增的特别快,所以我们这里随机选择 生成的数列长度 36 够用了// [0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 6765 10946 17711 28657 46368 75025 121393 196418 317811 514229 832040 1346269 2178309 3524578 5702887 9227465 14930352]for i := 0; i <= 36; i++ {fibArr = append(fibArr, fibonacci(i))}//fmt.Println(fibArr)// 确定待查找数组在裴波那契数列的位置k := 0n := len(arr)// 此处 n > fib[k]-1 也是别有深意的// 若n恰好是裴波那契数列上某一项,且要查找的元素正好在最后一位,此时必须将数组长度填充到数列下一项的数字for n > fibArr[k]-1 {k = k + 1}//fmt.Println(k, fibArr[k])// 将待查找数组填充到指定的长度for i := n; i < fibArr[k]; i++ {arr = append(arr, 0)}low, high := 0, n-1for low <= high {// 获取黄金分割位置元素下标mid := low + fibArr[k-1] - 1if key < arr[mid] {// 若key比这个元素小, 则key值应该在low至mid - 1之间,剩下的范围个数为F(k-1) - 1high = mid - 1k -= 1}else if key > arr[mid] {// 若key比这个元素大, 则key至应该在mid + 1至high之间,剩下的元素个数为F(k) - F(k-1) - 1 = F(k-2) - 1low = mid + 1k -= 2}else {if mid < n {return mid}else {return n - 1}}}return -1
}/**
生成 斐波那契数列*/// 最屌写法
func fibonacci(n int) int {if n < 2 {return n}var fibarry = [3]int{0, 1, 0}for i := 2; i <= n; i++ {fibarry[2] = fibarry[0] + fibarry[1]fibarry[0] = fibarry[1]fibarry[1] = fibarry[2]}return fibarry[2]
}//递归实现
func Fibo1(n int) int {if n == 0 {return 0} else if n == 1 {return 1} else if n > 1 {return Fibo1(n-1) + Fibo1(n-2)} else {return -1}
}//迭代实现
func Fibo2(n int) int {if n < 0 {return -1} else if n == 0 {return 0} else if n <= 2 {return 1} else {a, b := 1, 1result := 0for i := 3; i <= n; i++ {result = a + ba, b = b, result}return result}
}//利用闭包
func Fibo3(n int) int {if n < 0 {return -1} else {f := Fibonacci()result := 0for i := 0; i < n; i++ {result = f()}return result}
}
func Fibonacci() func() int {a, b := 0, 1return func() int {a, b = b, a+breturn a}
}树查找 【二叉树查找】:
二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后再用所查数据和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
适用场景:
前面的几种查找算法因为都是适用于有序集,在插入和删除操作上就需要耗费大量的时间。有没有一种既可以使得插入和删除效率不错,又可以比较高效的实现查找的算法。
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree)或者是一棵空树,或者是具有下列性质的二叉树:
1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2)若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3)任意节点的左、右子树也分别为二叉查找树。
二叉查找树性质:对二叉查找树进行中序遍历,即可得到有序的数列。【注:什么是前序、中序、后序遍历,请参考: http://www.cnblogs.com/turnips/p/5096578.html】
如代码:
/**
基本思路:先把数组构造出一颗二叉树的样纸,然后查找的时候在从root往下对比*/
func BSTsearch(arr []int, key int) int{// 先在内存中构造 二叉树tree := new(Tree)for i, v := range arr {Insert(tree, v, i)}// 开始二叉树查找目标keyreturn searchKey(tree.Root, key)
}// 节点结构
type Node struct {Value, Index int // 元素的值和在数组中的位置Left, Right *Node
}// 树结构
type Tree struct {Root *Node
}// 把数组的的元素插入树中
func Insert(tree *Tree, value, index int){if nil == tree.Root {tree.Root = newNode(value, index)}else {InsertNode(tree.Root, newNode(value, index))}
}// 把新增的节点插入树的对应位置
func InsertNode(root, childNode *Node) {// 否则,先和根的值对比if childNode.Value <= root.Value {// 如果小于等于跟的值,则插入到左子树if nil == root.Left {root.Left = childNode}else {InsertNode(root.Left, childNode)}}else{// 否则,插入到右子树if nil == root.Right {root.Right = childNode}else {InsertNode(root.Right, childNode)}}
}func newNode(value, index int) *Node {return &Node{Value: value,Index: index,}
}
// 在构建好的二叉树中,从root开始往下查找对应的key 返回其在数组中的位置
func searchKey(root *Node, key int) int {if nil == root {return -1}if key == root.Value {return root.Index}else if key < root.Value {// 往左子树查找return searchKey(root.Left, key)}else {// 往右子树查找return searchKey(root.Right, key)}
}【注意】:总的来说就是,需要先构造一个二叉树,然后把数组的元素和索引放置树的对应位置,然后在从输的root逐个换个key做对比,取出key所在数组中的index
其中,2-3树、红黑树、B/B+树,后续有时间再完善了
2-3 树查找:
/**
2-3树 也叫 平衡树
基本思路:
*/
红黑树查找:
我们这里先看看什么是红黑树。
它一种特殊的二叉查找树。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。红黑树是2-3树的一种简单高效的实现。
红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
如图所示:图文均参考自:http://www.cnblogs.com/skywang12345/p/3245399.html
![]()
基本思路:红黑树的基本操作是添加、删除。在对红黑树进行添加或删除之后,都会用到旋转方法。为什么呢?道理很简单,添加或删除红黑树中的节点之后,红黑树就发生了变化,可能不满足红黑树的5条性质,也就不再是一颗红黑树了,而是一颗普通的树。而通过旋转,可以使这颗树重新成为红黑树。简单点说,旋转的目的是让树保持红黑树的特性。
旋转包括两种:左旋 和 右旋。
左旋:
![]()
完整的左旋示意图:
![]()
右旋:
![]()
完整的右旋示意图:
![]()
无论是左旋还是右旋,被旋转的树,在旋转前是二叉查找树,并且旋转之后仍然是一颗二叉查找树。(二叉查找树:左子 < 根 < 右子)
![]()
可见:左旋中的“左”,意味着“被旋转的节点将变成一个左节点”;右旋中的“右”,意味着“被旋转的节点将变成一个右节点”。
节点的插入:
【首先】将红黑树当作一颗二叉查找树,将节点插入;【然后】将节点着色为红色;【最后】通过旋转和重新着色等方法来修正该树,使之重新成为一颗红黑树。
为什么着色成红色,而不是黑色呢?
在回答之前,我们需要重新温习一下红黑树的特性:
(1) 每个节点或者是黑色,或者是红色。
(2) 根节点是黑色。
(3) 每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!]
(4) 如果一个节点是红色的,则它的子节点必须是黑色的。
(5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
将插入的节点着色为红色,不会违背"特性(5)"!少违背一条特性,就意味着我们需要处理的情况越少。接下来,就要努力的让这棵树满足其它性质即可;满足了的话,它就又是一颗红黑树了。
将插入节点着色为"红色"之后,不会违背"特性(5)"。那它到底会违背哪些特性呢?
对于"特性(1)",显然不会违背了。因为我们已经将它涂成红色了。
对于"特性(2)",显然也不会违背。在第一步中,我们是将红黑树当作二叉查找树,然后执行的插入操作。而根据二叉查找数的特点,插入操作不会改变根节点。所以,根节点仍然是黑色。
对于"特性(3)",显然不会违背了。这里的叶子节点是指的空叶子节点,插入非空节点并不会对它们造成影响。
对于"特性(4)",是有可能违背的!
那接下来,想办法使之"满足特性(4)",就可以将树重新构造成红黑树了。
详细请看下面代码自然就明白。
如代码:
const (RED = trueBLACK = false
)// 节点
type RBNode struct {Color bool // true == 红 false == 黑Parent, Left, Right *RBNodeValue, Index int
}type RBTree struct {Root *RBNode
}/*
* 对红黑树的节点(x)进行左旋转
*
* 左旋示意图(对节点 x 进行左旋):
* px px
* / /
* x y
* / \ --(左旋)-. / \ #
* lx y x ry
* / \ / \
* ly ry lx ly
*
*
*/
func (t *RBTree) leftSpin(node *RBNode) {// 先提出自己的 右子y := node.Right// 自己的新右子 是前右子的左子node.Right = y.Leftif nil != y.Left {y.Left.Parent = node}// 你以前的爹,就是我现在的爹y.Parent = node.Parent// 如果被旋转的节点是 之前树的根// 那么,新的跟就是 y 节点if nil == node.Parent {t.Root = y} else { // 被旋转的是普通节点时, 需要结合自身的父亲来确认自己之前是属于 左子还是右子if node.Parent.Left == node { // 被旋转节点之前是 左子时// 用 y 来作为之前 该节点父亲的 新左子node.Parent.Left = y} else { // 否则,是 右子node.Parent.Right = y}}// 将 node 设为 y 的左子y.Left = node// 将 y 设为 node 的新父亲node.Parent = y
}/** 对红黑树的节点(y)进行右旋转** 右旋示意图(对节点 y 进行左旋):* py py* / /* y x* / \ --(右旋)-. / \ #* x ry lx y* / \ / \ #* lx rx rx ry**/
func (t *RBTree) rightSpin(node *RBNode) {// 先提出自己的 左子x := node.Leftnode.Left = x.Rightif nil != x.Left {x.Right.Parent = node}x.Parent = node.Parent// 如果被旋转的节点是 之前树的根// 那么,新的跟就是 x 节点if nil == node.Parent {t.Root = x} else {if node.Parent.Right == node {node.Parent.Right = x} else {node.Parent.Left = x}}x.Right = nodenode.Parent = x
}func insertValue(tree *RBTree, val, index int) {node := &RBNode{Value: val, Index: index, Color: BLACK}if nil == tree.Root {tree.Root = node}else{tree.insert(node)}
}func (t *RBTree) insert(node *RBNode) {//int cmp;var tmpNode *RBNoderoot := t.Root// 1. 将红黑树当作一颗二叉查找树,将节点添加到二叉查找树中。for nil != root {if node.Value < root.Value {root = root.Left} else {root = root.Right}tmpNode = root}node.Parent = tmpNodeif nil != tmpNode {if node.Value < tmpNode.Value {tmpNode.Left = node} else {tmpNode.Right = node}} else {t.Root = node}// 2. 设置节点的颜色为红色node.Color = RED// 3. 将它重新修正为一颗二叉查找树t.adjustRBTree(node)
}// 修正树
func (t *RBTree) adjustRBTree(node *RBNode) {var parent, gparent *RBNode // 父亲 和 祖父// 若“父节点存在,并且父节点的颜色是红色”for nil != node.Parent && RED == node.Parent.Color {parent = node.Parentgparent = parent.Parent//若“父节点”是“祖父节点的左孩子”if parent == gparent.Left {// Case 1条件:叔叔节点是红色uncle := gparent.Rightif nil != uncle && RED == uncle.Color {uncle.Color = BLACKparent.Color = BLACKgparent.Color = REDnode = gparentcontinue}// Case 2条件:叔叔是黑色,且当前节点是右孩子if node == parent.Right {var tmp *RBNodet.leftSpin(parent)tmp = parentparent = nodenode = tmp}// Case 3条件:叔叔是黑色,且当前节点是左孩子。parent.Color = BLACKgparent.Color = REDt.rightSpin(gparent)} else { //若“z的父节点”是“z的祖父节点的右孩子”// Case 1条件:叔叔节点是红色uncle := gparent.Leftif nil != uncle && RED == uncle.Color {uncle.Color = BLACKparent.Color = BLACKgparent.Color = REDnode = gparentcontinue}// Case 2条件:叔叔是黑色,且当前节点是左孩子if node == parent.Left {var tmp *RBNodet.rightSpin(parent)tmp = parentparent = nodenode = tmp}// Case 3条件:叔叔是黑色,且当前节点是右孩子。parent.Color = BLACKgparent.Color = REDt.leftSpin(gparent)}}// 将根节点设为黑色t.Root.Color = BLACK
}/**
红黑树查找*/
func RedBlackTreeSearch(arr []int, key int) int{// 先构造树tree := new(RBTree)for i, v := range arr {insertValue(tree, v, i)}// 开始二叉树查找目标keyreturn tree.serch(key)
}func (t *RBTree) serch(key int) int {return serch(t.Root, key)
}
func serch(node *RBNode, key int) int {if nil == node {return -1}if key < node.Value {return serch(node.Left, key)}else if key > node.Value {return serch(node.Right, key)}else {return node.Index}
}B/B+树查找:
/**
B/B+树是2-3树的另一种拓展,在文件系统和数据库系统中有着广泛的应用
基本思路:
*/
分块查找:
参考:http://www.lishiyu.cn/post/46.html
是顺序查找的一种结合改进;
将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……
算法流程:
step1 :先选取各块中的最大关键字构成一个索引表;
step2 :查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后,在已确定的块中用顺序法进行查找。
如代码:【先省略...我还没写出来...水了】
Hash查找:
说白了就是用一个二维数组来装原数组经过Hash运算后的值,如,第一维是 元素Hash后的值,第二维依次装着该 key在原数组中出现的索引号 <因为原数组中的 元素可能会有相同的,所以Hash值也会一样,所以用了二维数组>。在查找的时候可以先计算Hash然后用顺序查找在第一维中找到对应的Hash,然后在第二维中依次返回里面的内容<也就是该key在原数组中的索引值>;如果没找到对应Hash,则原数组没有包含该key
代码:【先省略...我还没写出来...水了】
在说广度和深度之前我们先来看看一些关于广度和深度的知识:
广度优先:从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远,依次访问和v有路径相通且路径长度为1,2...的顶点。
如图:
【无向图的广度优先搜索】
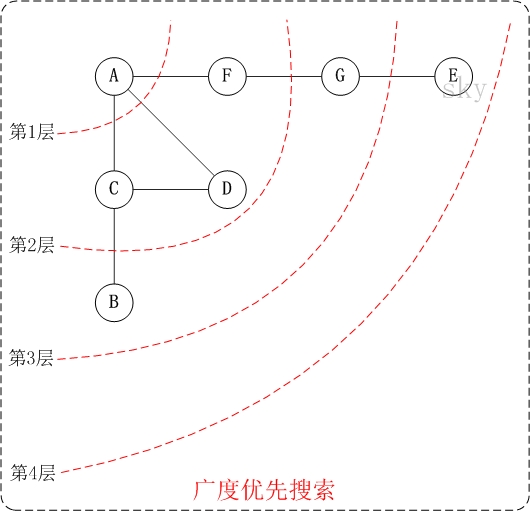
第1步:访问A。
第2步:依次访问C,D,F。
在访问了A之后,接下来访问A的邻接点。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,C在"D和F"的前面,因此,先访问C。再访问完C之后,再依次访问D,F。
第3步:依次访问B,G。
在第2步访问完C,D,F之后,再依次访问它们的邻接点。首先访问C的邻接点B,再访问F的邻接点G。
第4步:访问E。
在第3步访问完B,G之后,再依次访问它们的邻接点。只有G有邻接点E,因此访问G的邻接点E。
因此访问顺序是:A -> C -> D -> F -> B -> G -> E
【有向图的广度优先搜索】
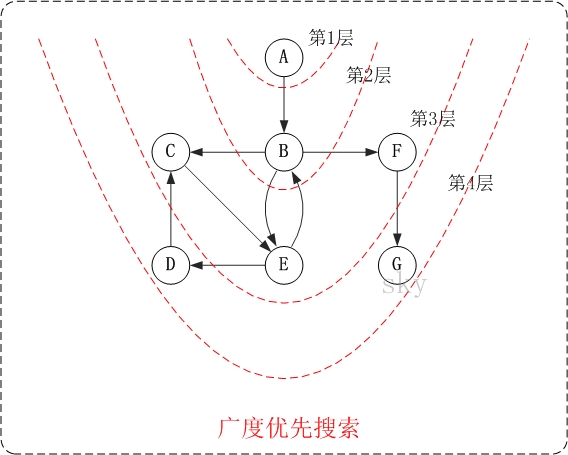
第1步:访问A。
第2步:访问B。
第3步:依次访问C,E,F。
在访问了B之后,接下来访问B的出边的另一个顶点,即C,E,F。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,因此会先访问C,再依次访问E,F。
第4步:依次访问D,G。
在访问完C,E,F之后,再依次访问它们的出边的另一个顶点。还是按照C,E,F的顺序访问,C的已经全部访问过了,那么就只剩下E,F;先访问E的邻接点D,再访问F的邻接点G。
因此访问顺序是:A -> B -> C -> E -> F -> D -> G
深度优先:
假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
显然,深度优先搜索是一个递归的过程。
如图:
【无向图的深度优先搜索】

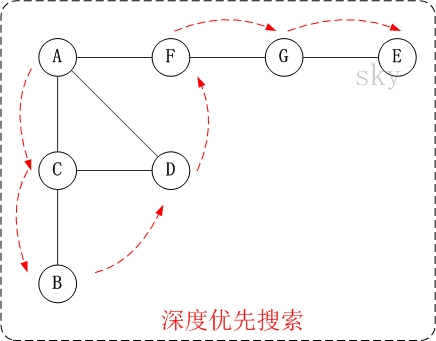
第1步:访问A。
第2步:访问(A的邻接点)C。
在第1步访问A之后,接下来应该访问的是A的邻接点,即"C,D,F"中的一个。但在本文的实现中,顶点ABCDEFG是按照顺序存储,C在"D和F"的前面,因此,先访问C。
第3步:访问(C的邻接点)B。
在第2步访问C之后,接下来应该访问C的邻接点,即"B和D"中一个(A已经被访问过,就不算在内)。而由于B在D之前,先访问B。
第4步:访问(C的邻接点)D。
在第3步访问了C的邻接点B之后,B没有未被访问的邻接点;因此,返回到访问C的另一个邻接点D。
第5步:访问(A的邻接点)F。
前面已经访问了A,并且访问完了"A的邻接点B的所有邻接点(包括递归的邻接点在内)";因此,此时返回到访问A的另一个邻接点F。
第6步:访问(F的邻接点)G。
第7步:访问(G的邻接点)E。
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
【有向图的深度优先搜索】

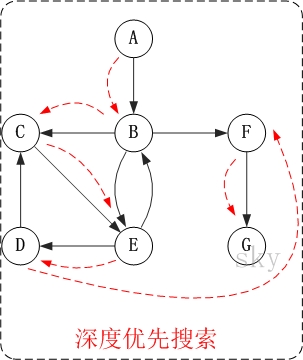
第1步:访问A。
第2步:访问B。
在访问了A之后,接下来应该访问的是A的出边的另一个顶点,即顶点B。
第3步:访问C。
在访问了B之后,接下来应该访问的是B的出边的另一个顶点,即顶点C,E,F。在本文实现的图中,顶点ABCDEFG按照顺序存储,因此先访问C。
第4步:访问E。
接下来访问C的出边的另一个顶点,即顶点E。
第5步:访问D。
接下来访问E的出边的另一个顶点,即顶点B,D。顶点B已经被访问过,因此访问顶点D。
第6步:访问F。
接下应该回溯"访问A的出边的另一个顶点F"。
第7步:访问G。
因此访问顺序是:A -> B -> C -> E -> D -> F -> G
以上几张图和步骤的说明,是抄了 https://www.cnblogs.com/skywang12345/p/3711483.html 的,哼,我怎么可能写的出来呢,天真~
又如代码:
package mainimport "fmt"func main() {/**图的形式:var r = make(map[string][]string)r["A"] = []string{"B", "C", "D"}r["B"] = []string{"A", "E"}r["C"] = []string{"A", "E"}r["D"] = []string{"A"}r["E"] = []string{"B", "C", "F"}r["F"] = []string{"E"}*/// 构造图fillGraph()// 广度遍历g.BFS(func(node *TNode) {fmt.Printf("B-F-S visiting... %v\n", node)})// 深度遍历g.DFS(func(node *TNode) {fmt.Printf("DFS visiting... %v\n", node)})
}/**
图按照不同的特征可以分为以下类别:- 有向图
- 无向图- 有权图
- 无权图- 连通图
- 非连通图*//**
图的两种表示方法邻接矩阵
var s = [][]int{
{0, 1, 1, 1, 0, 0},
{1, 0, 0, 0, 1, 0},
{1, 0, 0, 0, 1, 0},
{1, 0, 0, 0, 0, 0},
{0, 1, 1, 0, 0, 0},
{0, 0, 0, 0, 1, 0},
}邻接表表示
var r = make(map[string][]string)
r["A"] = []string{"B", "C", "D"}
r["B"] = []string{"A", "E"}
r["C"] = []string{"A", "E"}
r["D"] = []string{"A"}
r["E"] = []string{"B", "C", "F"}
r["F"] = []string{"E"}
*/// 组成图的顶点
type TNode struct {Value interface{}
}// 定义一个图的结构, 图有顶点与边组成 V E
type ItemGraph struct {Nodes []*TNode // 顶点 集合/** 采用 邻接表 */Edges map[TNode][]*TNode // 边 集合
}// 添加节点
func (g *ItemGraph) AddNode(n *TNode) {g.Nodes = append(g.Nodes, n)
}// 添加边
func (g *ItemGraph) AddEdge(n1, n2 *TNode) {if g.Edges == nil{g.Edges = make(map[TNode][]*TNode)}// 无向图g.Edges[*n1] = append(g.Edges[*n1], n2) // 设定从节点n1到n2的边g.Edges[*n2] = append(g.Edges[*n2], n1) // 设定从节点n2到n1的边
}// 打印图
func (g *ItemGraph) String() {s := ""for i := 0; i< len(g.Nodes); i++{s += g.Nodes[i].String() + "->"near := g.Edges[*g.Nodes[i]]for j :=0; j<len(near); j++{s += near[j].String() + " "}s += "\n"}fmt.Println(s)
}func (n *TNode) String() string {return fmt.Sprintf("%v", n.Value)
}// 深度用栈,广度用队列
// 深度优先遍历可以通过递归实现,而广度优先遍历要转换成类似于树的层序遍历来实现/// 广度遍历 ////**
首先bfs 广度优先搜索
此处结合队列实现图的广度优先遍历广度优先遍历,这个遍历类似于层序遍历,每遍历一层,需要记住当前层的节点,
然后与遍历当前层相连的节点,如此实现遍历。需要一个队列来记住当前层,先进先出。
还有一个问题,就是需要防止回路,也就是说,一个节点不能遍历两次。这里用了Golang内置的map实现
*/// 定义缓冲队列
type NodeQueue struct {Items []TNode
}func (s *NodeQueue) New() {s.Items = make([]TNode, 0)
}// 从队尾入队
func (s *NodeQueue) Enqueue(t TNode) {s.Items = append(s.Items, t)
}// 从对头出队
func (s *NodeQueue) Dequeue() *TNode {item := s.Items[0]s.Items = s.Items[1:len(s.Items)]return &item
}// 是否空队列
func (s *NodeQueue) IsEmpty() bool {return len(s.Items) == 0
}/**
广度优先 BFS*/
func (g *ItemGraph) BFS(f func(node *TNode)) {// 初始化队列q := new(NodeQueue)q.New()// 获取图的首个节点n := g.Nodes[0]// 首节点入队q.Enqueue(*n)// 缓存是否被某节点是否被遍历过的检查visited := make(map[*TNode]bool)// 初始时, 首节点标识位遍历过visited[n] = truefor {// 如果全部遍历完时,缓冲队列为空if q.IsEmpty(){break}// 节点出队node := q.Dequeue()// 获取当前节点的边,即和该节点相邻的其他节点nearArr := g.Edges[*node]// 先遍历完该节点所有相邻的节点 (也就是这一层的)for i :=0; i < len(nearArr); i++{j := nearArr[i]// 只要是该节点没有被曾经遍历过,即可入队if !visited[j]{q.Enqueue(*j)visited[j] = true}}if f != nil{// 打印当前节点信息f(node)}}
}/**
BFS 广度优先搜索
此处结合队列实现图的广度优先遍历广度优先遍历,这个遍历类似于层序遍历,每遍历一层,需要记住当前层的节点,
然后与遍历当前层相连的节点,如此实现遍历。需要一个队列来记住当前层,先进先出。
还有一个问题,就是需要防止回路,也就是说,一个节点不能遍历两次。这里用了Golang内置的map实现
*/
/**
DFS 深度优先搜索
此处结合栈实现图的深度优先遍历深度优先遍历, 是沿着一个方向先遍历到底,再沿另外的方向一路到底*/// 定义缓冲栈
type NodeStack struct {Items []TNode
}func (n *NodeStack) New() {n.Items = make([]TNode, 0)
}// 压栈
func (n *NodeStack) push(q TNode) {n.Items = append(n.Items, q)
}// 弹栈
func (n *NodeStack) pop() *TNode {item := n.Items[len(n.Items) - 1] //取最后一个n.Items = n.Items[0: len(n.Items) - 1]return &item
}// 判断是否空栈
func (n *NodeStack) IsEmpty() bool {return len(n.Items) == 0
}// 栈宽
func (n *NodeStack) Size() int {return len(n.Items)
}/**
深度优先 DFS*/
func (g *ItemGraph) DFS(f func(node *TNode)) {// 初始化栈stack := new(NodeStack)stack.New()// 取出图的首节点n := g.Nodes[0]// 压栈stack.push(*n)// 缓存是否被某节点是否被遍历过的检查visited := make(map[*TNode] bool)// 初始时, 首节点标识位遍历过visited[n] = truefor {// 如果全部遍历完时,缓冲栈为空if stack.IsEmpty(){break}// 弹栈node := stack.pop()/** 注意:这里和 广度的不一样,因为在深度中,当前这一层的某个节点可能在之前的某次深度中已经被遍历过了 */if !visited[node]{visited[node] = true}// 获取当前节点的边,即和该节点相邻的其他节点nearArr := g.Edges[*node]for i:= 0; i< len(nearArr); i++{j := nearArr[i]if !visited[j]{visited[j] = truestack.push(*j)}}if f != nil{// 打印当前节点信息f(node)}}
}/**
测试*/
var g ItemGraphfunc fillGraph() {// 构造所有游离态的节点nA := TNode{"A"}nB := TNode{"B"}nC := TNode{"C"}nD := TNode{"D"}nE := TNode{"E"}nF := TNode{"F"}// 往图中聚集节点g.AddNode(&nA)g.AddNode(&nB)g.AddNode(&nC)g.AddNode(&nD)g.AddNode(&nE)g.AddNode(&nF)// 添加边;图中的节点通过 链表关联起来g.AddEdge(&nA, &nB)g.AddEdge(&nA, &nC)g.AddEdge(&nB, &nE)g.AddEdge(&nC, &nE)g.AddEdge(&nE, &nF)g.AddEdge(&nD, &nA)
}以上就是,深度和广度的遍历,下面我们来看看,深度和广度的查找,很简单,只要对上面的遍历方法稍加改动就可以是查找方法了。<无论是查找key还是查找 起始节点到目标节点的路径都是可以的 >
topK-- 孤岛算法:
TOP k就是从海量的数据中选取最大的k个元素或记录。
基本思想:就是维护一个具有k个元素的最小堆【小顶堆】。每当有新的元素加入时,判断它是否大于堆顶元素,如果大于,用该元素代替堆顶元素,并重新维护小顶堆,直到所有元素被处理完毕。
时间复杂度为O(N*logk),基本达到线性复杂度。
适用场景:
无序的,海量数据的
如代码:
func HeapSearchK (arr []int, topk int) {// 初始化原始最小堆smallHeapArr := buildSmallHeap(arr, topk)for i := topk; i < len(arr); i ++ {// 如果当前原始比最小堆的根元素大,那么替换根,且重新调整最小堆if arr[i] > smallHeapArr[0] {swapRoot(smallHeapArr, arr[i])}}// 最大的K个数fmt.Println(smallHeapArr)
}//建立小顶堆
func buildSmallHeap(arr []int,topk int) []int{smallHeapArr := arr[:topk]for i := topk>>1 - 1; i >= 0; i-- {adjustSmallHeap(smallHeapArr, i, topk)}return smallHeapArr
}
// 调整最小堆
func adjustSmallHeap(arr []int, parent, length int) {i := parentfor {lchild := 2*parent + 1rchild := 2 *parent + 2if lchild < length && arr[lchild] < arr[i] {i = lchild}// 右节点和根if rchild < length && arr[rchild] < arr[i]{i = rchild}// 互换位置if parent != i {arr[i], arr[parent] = arr[parent], arr[i]parent = i}else {break}}
}// 替换根部,且重新构造最小堆
func swapRoot(arr []int, root int) {arr[0] = root // 新的根// 重新调整堆adjustSmallHeap(arr, 0, len(arr))
}好了,今天就写这么多了,累死我了!
【我的区块链之路】- golang实现主流查找算法相关推荐
- 【我的区块链之路】- Hyperledger fabric的简单入门(四)链码的编写及调试
[我的区块链之路]- Hyperledger fabric的简单入门(四)链码的编写及调试 之前的文章中我们有讲过了fabric的一些核心的配置文件的选项说明,讲过fabric 的网络启动 ...
- 揭秘大公司区块链之路:迅雷是如何成为区块链领军者的?
点击上方"蓝色字"可关注我们! 编辑:铅笔盒 有人说,区块链是21世纪最伟大的发明:也有人说,区块链是最有争议的科技之一.无论技术未来会走向何方,显而易见的是,在机会面前,谁都不甘 ...
- 大厂的区块链之路 | 百度开启富场景模式直达宇宙
大厂的区块链之路 | 百度开启富场景模式直达宇宙 2015-2017年,是比特币等数字货币以及ICO爆红的时期,各大巨头对于区块链布局一直保持低调.2018年,随着数字货币的低迷和ICO被监管部门明确 ...
- 【我的区块链之路】- 去中心化的神级大作Hashgraph的讲解
[转载请标明出处]: https://blog.csdn.net/qq_25870633/article/details/82057232 本文章参考自: https://blog.csdn.net/ ...
- 【我的区块链之路】- 谈一谈IPFS原理及玩法
[转载请标明出处]https://blog.csdn.net/qq_25870633/article/details/82027510 文章参考自: https://www.zybuluo.com/z ...
- 从零开始的java区块链之路(一) 什么是区块链?
说起区块链最被人所熟知的还是 比特币.比特币是一种去中心化的P2P(Point to Point)形式的数字货币. 货币的起源 在公元前3000年,两河流域的苏美尔人,在波斯湾沿岸有着很广阔的贸易,当 ...
- 【我的区块链之路】- SPV 的特点及使用场景
[转载请标明出处]:https://blog.csdn.net/qq_25870633/article/details/81980376 我们很多人都知道在比特币中有一种节点叫做 spv (简易支付验 ...
- BC之CM:区块链之共识机制——深入浅出以及国内外当下主流区块链平台共识机制纵向、横向比较相关配图
BC之CM:区块链之共识机制--深入浅出以及国内外当下主流区块链平台共识机制纵向.横向比较相关配图 目录 区块链共识机制的深入浅出 国内外当下主流区块链平台共识机制纵向.横向比较 区块链共识机制的深入 ...
- 深度解读波卡智能合约平台Gear:通往并行架构公链之路
本篇节选自:深度解读波卡智能合约平台Gear:通往并行架构公链之路 摘要 2021 年 11 月,随着波卡主网正式开启平行链插槽拍卖,波卡生态顿时成为一股耀眼的新势力.其创始人 Gavin Wood ...
最新文章
- 安卓(android)建立项目时失败,出现Android Manifest.xml file missing几种解决方法?...
- socket编程中常见的概念问题!
- wps文档提取关键词_Cisdem Document Reader5实用文档阅读器
- 华为计算机充电指示灯,数码产品:华为p40充电指示灯不亮在哪里设置 有指示灯吗...
- 百度智能云人脸库的创建与使用
- 清风数学建模学习笔记——层次分析法(AHP)
- pptswot分析图怎么做_SWOT分析图-PPT模板.pptx
- Java 计量单位换算 工具类
- 高等数学几何图形凸优化
- 敏捷 | 【万字长文】 说透 如何学习敏捷开发流程和运用
- 综合素质计算机考点,教师资格综合素质考前必背知识点:基本能力
- 金蝶K3总账期初数据录入案例教程
- 正则表达式[^\\.]
- 分时调度和抢占式调度
- 文献阅读 | Deep learning enables reference-free isotropic super-resolution for v fluorescence microscopy
- 如何下载浙江省卫星地图高清版大图
- Node.js 的安装与配置
- 【Rust日报】 2019-05-31:rust.cc社区提供了国内crates镜像
- 《MongoDB入门教程》第21篇 CRUD之删除文档
- 调整光电避障传感器测距的距离
热门文章
- 计算机实验室里计算机显示屏黑屏怎么处理,电脑进入系统后黑屏怎么处理?电脑进入系统黑屏的原因及解决方法...
- 主要的七种排序(快排、希尔排序、堆排序、归并排序、选择排序、插入排序、冒泡排序)
- 论文笔记-YOLOv4: Optimal Speed and Accuracy of Object Detection
- 天涯明月刀开发_腾讯或为天涯明月刀打造国际研发团队
- 2118: 墨墨的等式
- ContextMenu菜单详解
- ST-LINK接口定义
- android 清理内存图标掉进垃圾桶的动画,Android Magnet:桌面删除APP自动弹出垃圾桶接受图标删除动作...
- 给家里的垃圾桶做个分类标贴
- 仿天猫App可打开列表