分享下去年底写的mysql分库分表中间件heisenberg
2019独角兽企业重金招聘Python工程师标准>>> 
目前维护在github上了,googlecode稳定性太差
https://github.com/brucexx/heisenberg
之前在组里有做过简单的分享,这段时间稍微轻松了点,先分享出来,看有没有更好的idea在这块有所提升
1.heisenberg总体架构

而heisenberg也是集成了mysql的原生协议,所以对于应用来说,就相当于单库单表的数据源
无论是mysql客户端,c,jdbc驱动等都可以访问heisenberg服务器,由服务器把分库分表的工作给做掉了
访问heisenberg集群可以通过像lvs,F5等负载软件/设备解决,
其实一台heisenberg的性能是相当的赞了,我压力到2320TPS load 都还只有0.1-0.3左右(CPU 8core,16G),由于找不到mysql物理机器了,只得做罢

mysql协议贯穿于应用程序与mysql服务器,最终解析为相关的mysql数据包, 授权包,注册包等
2.heisenberg开发
代码从https://github.com/brucexx/heisenberg
在本地target里会生成一个heisenberg-server-1.0.0.zip 文件
解压之 unzip heisenberg-server-1.0.0.zip
|
<system> <property name="serverPort">8166</property> <property name="managerPort">8266</property> <property name="initExecutor">16</property> <property name="timerExecutor">4</property> <property name="managerExecutor">4</property> <property name="processors">4</property> <property name="processorHandler">8</property> <property name="processorExecutor">8</property> <property name="clusterHeartbeatUser">_HEARTBEAT_USER_</property> <property name="clusterHeartbeatPass">_HEARTBEAT_PASS_</property> </system> |
managerPort为管理端口,即管理的监听端口,用于操作服务器一些配置等
clusterHeartbeatUser和clusterHeartbeatPass 不必改,用于集群的认证方式使用
|
<user name="brucexx"> <property name="password">st0078</property> <property name="schemas">trans_shard</property> </user> |
Brucexx为自定义应用用户名,st0078为自定义应用密码
Schemas为自定义schema,具体见schema.xml中,
|
<quarantine> <host name="1.2.3.4"> <property name="user">test</property> </host> </quarantine> |
mysql数据源
|
<dataSource name="transDS" type="mysql"> <property name="location"> <location>10.58.49.14:8701/db$0-9</location> </property> <property name="user">root</property> <property name="password">st0078</property> <property name="sqlMode">STRICT_TRANS_TABLES</property> </dataSource> |
这里指定的mysql的数据源,后面$0-9是一种自定义的缩略写法
也可以在property里面定义多个location,比如:
|
<property name="location"> <location>10.58.49.14:8701/db0</location> <location>10.58.49.14:8701/db1</location> <location>10.58.49.14:8701/db2</location> </property>
|
Shard结点配置
Shard结点相当于一个逻辑结点,提供给外部相关的schema,对应于数据源有
|
<dataNode name="transDN"> <property name="dataSource"> <!-- 主库 --> <dataSourceRef>transDS$0-9</dataSourceRef> <!-- 备库 --> <dataSourceRef>transSlaveDS$0-9</dataSourceRef> <!-- 灾库 --> <dataSourceRef>transSlaveDS$0-9</dataSourceRef> <!-- slave,暂无 --> <!-- dataSourceRef>ds_shard_slave$0-3</dataSourceRef --> </property> <property name="rwRule"><![CDATA[m:0,s:1]]></property> <property name="poolSize">256</property> <property name="heartbeatSQL">select user()</property> </dataNode> |
属性dataSource 第一个是主库,第二个备库,第三个灾库,需要多少配置多少个
读写分离规则rwRule,m和s代表读取的比例,表示主库读取为0,从库读取1,这样直接读写分离,如果是1:1的话相当读取各1:1的比例
池大小poolSize为到mysqlDB的连接数和心跳sql heartbeatSQL,无特殊需求保持不变
Schema配置
|
<schema name="trans_shard"> <table name="trans_online, trans_content, trans_tb " dataNode="transDN$0-9"rule="rule1" /> </schema> |
trans_shard 提供的schema,对应于server.xml中的名字
<table name="trans_online" dataNode="transDN$0-9" rule="rule1" />
这里必须要把需要分库分表的内容写出来,当然,如果不分库表也是可以的
<table name=”tbxxx" dataNode="transDN0" ruleRequired=”false”/
rule.xml
分库分表规则配置,其中columns,dbRuleList,tbRuleList里面的列名要保持大写
|
<rule> <tableRule name="rule1"> <columns>TRANS_ID</columns> <dbRuleList> <dbRule><![CDATA[#set($start=$TRANS_ID.length() - 2)## #set($end=$TRANS_ID.length() - 1)## $stringUtil.substring($TRANS_ID,$start,$end)]]> </dbRule> </dbRuleList> <tbRuleList> <tbRule><![CDATA[#set($start=$TRANS_ID.length() - 2)## $stringUtil.substring($TRANS_ID,$start)]]></tbRule> </tbRuleList> <!-- 00-99 100个表,每个表属于哪个结点 Map<Integer,Set<String>> --> <tbPrefix> <![CDATA[ def map = [:]; for (int i=0; i<10; i++) { def list = []; for (int j=0; j<10; j++) { list.add(i+""+j); } map.put(i,list); }; return map; ]]> </tbPrefix> </tableRule> </rule> |
|
<dbRuleList> <dbRule><![CDATA[#set($start=$TRANS_ID.length() - 2)## #set($end=$TRANS_ID.length() - 1)## $stringUtil.substring($TRANS_ID,$start,$end)]]> </dbRule> </dbRuleList> |
分库规则dbRuleList可以有多个dbRule,当第一个不满足时,可以用第二个,当然这个效率不好,如果有规则区分,尽量再写一个rule,
比如分库分表 库名为db0-db9,那么这个dbRule渲染时
取到TRANS_ID 这个为后,在脚本里计算出取倒数第2位为库后缀
分表规则配置
|
<tbRuleList> <tbRule><![CDATA[#set($start=$TRANS_ID.length() - 2)## $stringUtil.substring($TRANS_ID,$start)]]></tbRule> </tbRuleList> |

比如db0有个trans_tb00,db1就不能有叫trans_tb00的表
表初始化
|
<!-- 00-99 100个表,每个表属于哪个结点 Map<Integer,Set<String>> --> <tbPrefix> <![CDATA[ def map = [:]; for (int i=0; i<10; i++) { def list = []; for (int j=0; j<10; j++) { list.add(i+""+j); } map.put(i,list); }; return map; ]]> </tbPrefix> |
需要初始化个表,其中key为db的下标索引,比如db0 的下标为0,

这里就不用讲了,wms_shard就是在server.xml里面配置的逻辑分库分表的数据源schema,应用只要访问这个就好了

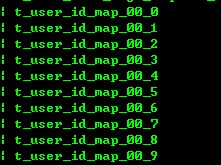
mysql> select * from t_user_id_map;
| F_uid | F_uname | F_enabled | F_user_id | F_create_time | F_modify_time |
| 62000 | | 1 | 533885000 | 2014-03-26 23:02:31 | 2014-03-26 23:02:31 |
| 86000 | | 1 | 237406000 | 2014-03-27 01:04:23 | 2014-03-27 01:04:23 |
| 96000 | | 1 | 767684000 | 2014-03-27 00:30:32 | 2014-03-27 00:30:32 |
| 130000 | | 1 | 506552000 | 2014-03-27 15:57:31 | 2014-03-27 15:57:31 |
| 149000 | | 1 | 868483000 | 2014-03-27 15:50:09 | 2014-03-27 15:50:09 |
| 179000 | | 1 | 245626000 | 2014-03-26 21:33:46 | 2014-03-26 21:33:46 |
当没有指定分库分表规则时,是进行的全表扫描,当然我们可以通过学习
mysql> explain select * from t_user_id_map;
+-----------+-----------------------------------
+-----------+-----------------------------------
| wmsDN[0] | select * from t_user_id_map_00_0
| wmsDN[0] | select * from t_user_id_map_00_1
| wmsDN[0] | select * from t_user_id_map_00_2
| wmsDN[0] | select * from t_user_id_map_00_3
| wmsDN[0] | select * from t_user_id_map_00_4
| wmsDN[0] | select * from t_user_id_map_00_5
| wmsDN[0] | select * from t_user_id_map_00_6
| wmsDN[0] | select * from t_user_id_map_00_7
| wmsDN[0] | select * from t_user_id_map_00_8
| wmsDN[0] | select * from t_user_id_map_00_9
| wmsDN[1] | select * from t_user_id_map_01_0
| wmsDN[1] | select * from t_user_id_map_01_1
| wmsDN[1] | select * from t_user_id_map_01_2
| wmsDN[1] | select * from t_user_id_map_01_3
| wmsDN[1] | select * from t_user_id_map_01_4
| wmsDN[1] | select * from t_user_id_map_01_5
| wmsDN[1] | select * from t_user_id_map_01_6
| wmsDN[1] | select * from t_user_id_map_01_7
| wmsDN[1] | select * from t_user_id_map_01_8
| wmsDN[1] | select * from t_user_id_map_01_9
| wmsDN[2] | select * from t_user_id_map_02_0
mysql> select * from t_user_id_map where f_uid=196606999;
+-----------+---------+-----------+-----------+---------------------+---------------------+
| F_uid | F_uname | F_enabled | F_user_id | F_create_time | F_modify_time |
+-----------+---------+-----------+-----------+---------------------+---------------------+
| 196606999 | | 1 | 749331999 | 2014-04-04 14:46:58 | 2014-04-04 14:46:58 |
+-----------+---------+-----------+-----------+---------------------+---------------------+
这边配置的是按F_uid最后三位分库分表的,dbRuleList配置的是倒数2,3位,
mysql> explain select * from t_user_id_map where f_uid=196606999;
+-----------+---------------------------------------------------------+
+-----------+---------------------------------------------------------+
| wmsDN[99] | select * from t_user_id_map_99_9 where f_uid=196606999 |
+-----------+---------------------------------------------------------+
转载于:https://my.oschina.net/brucexx/blog/221438
分享下去年底写的mysql分库分表中间件heisenberg相关推荐
- heisenberg mysql_分享下去年底写的mysql分库分表中间件heisenberg_MySQL
"tbxxx" dataNode="transDN0" ruleRequired="false"/ rule.xml 分库分表规则配置,其中 ...
- 去年底写的mysql分库分表中间件heisenberg
好久没有写博了,去年年底的时候写了一个分库分表中间件服务器,当时正在看绝命毒师,觉得heisenberg这个名字很叼,然后就以这个命名了,炼毒也要精益求精啊... 公司在java分布式这块的基础设施很 ...
- mysql分库分表中间件Heisenberg
代码地址: https://github.com/brucexx/heisenberg 其优点: 分库分表与应用脱离,分库表如同使用单库表一样 减少db 连接数压力 热重启配置 可水平扩容 遵守My ...
- 分享下去年底写的分库分表中间件heisenberg
好久没有写博了,去年年底的时候写了一个分库分表中间件服务器,当时正在看绝命毒师,觉得heisenberg这个名字很叼,然后就以这个命名了,炼毒也要精益求精啊... 公司在java分布式这块的基础设施很 ...
- 【分布式mysql分库分表中间件sharding】
分布式mysql分库分表中间件,sharding领域的一站式解决方案.具备丰富.灵活的路由算法支持,能够方便DBA实现库的水平扩容和降低数据迁移成本.shark采用应用集成架构,放弃通用性,只为换取更 ...
- mysql 分库分表中间件 mycat_阿里开源的分布式分库分表中间件之MyCat从入门到放弃...
原标题:阿里开源的分布式分库分表中间件之MyCat从入门到放弃 1.非分片字段查询 Mycat中的路由结果是通过分片字段和分片方法来确定的.例如下图中的一个Mycat分库方案: 根据 tt_waybi ...
- mysql分库分表中间件6_当当开源sharding-jdbc,轻量级数据库分库分表中间件
近期,当当开源了数据库分库分表中间件sharding-jdbc. Sharding-JDBC是当当应用框架ddframe中,从关系型数据库模块dd-rdb中分离出来的数据库水平分片框架,实现透明化数据 ...
- mysql分库分表配置命令_mysql分库分表中间件Heisenberg
"trans_shard"> "trans_online, trans_content, trans_tb "dataNode="transDN ...
- 如何彻底解决烦人的 MySQL 分库分表问题?写一个更好的数据库!
作者 | 黄东旭 责编 | 郭 芮 我还清楚记得,五年前的这个时候,当时还在豌豆荚,午后与刘奇和崔秋的闲聊关于未来数据库的想象,就像一粒种子一样,到了今天看起来也竟枝繁叶茂郁郁葱葱,有点感慨.按照 ...
最新文章
- 军哥lnmp一键安装包nginx支持pathinfo配置
- python fetchall方法_Python连接MySQL并使用fetchall()方法过滤特殊字符
- 2015 Multi-University Training Contest 9
- 数据结构入门学习笔记-1
- Python 两个list获取交集,并集,差集的方法(合并、交叉)
- 局域网设备与公网服务之间如何交互数据?
- 2020 存储技术热点与趋势总结
- h5文字垂直居中_PS教程:巧用自由变换,制作折纸文字效果
- mac电脑出现“XXX” is damaged and can’t be opened. You should move it to the Trash
- Udacity 传感器融合笔记 (一)lidar
- excel自动求和_excel工作表的行或列怎么自动求和
- html5内嵌式格式,如何使用内嵌式引入css样式表
- 大众点评网谈成功秘诀:明白用户感兴趣、需要和寻找的是什么
- 51单片机可以用来练手的60个小设计
- python保存的代码在哪里_Python保存程序
- java final f的区别_Java中final、finally、finalize的简单区别,中等区别,详细区别(Lawliet 修改+注释版)...
- 家用计算机防火墙设置,如何设置防火墙 防火墙在哪里设置【详细步骤】
- 原来跨境电商Temu还可以这样快速提升店铺销量!
- python 代码汇总
- ABB.RobotWare数据包 下载分享