【BABY夜谈大数据】计算文本相似度
简单讲解
上一章有提到过[基于关键词的空间向量模型]的算法,将用户的喜好以文档描述并转换成向量模型,对商品也是这么处理,然后再通过计算商品文档和用户偏好文档的余弦相似度。
文本相似度计算在信息检索、数据挖掘、机器翻译、文档复制检测等领域有着广泛的应用。
比如舆论控制,我们假设你开发了一个微博网站,并且已经把世界上骂人的句子都已经收录进了数据库,那么当一个用户发微博时会先跟骂人句子的数据库进行比较,如果符合里面的句子就不让用户发出。
通常情况下,很多工程师就会想到用like或者where的sql语法去查找。可是当情况更为复杂呢?
数据库存放了“你是个坏人”,用户要发“小明是个坏人”,这时应该怎么办呢?
最简单的办法就是通过判断文本的相似程度来决定用户发的内容是否是骂人的。
本章节就几种简单的判断文本相似性的算法来讲解,帮助大家更好的理解。
相关算法
1、余弦相似性
余弦(余弦函数),三角函数的一种。在Rt△ABC(直角三角形)中,∠C=90°,角A的余弦是它的邻边比三角形的斜边,即cosA=b/c,也可写为cosA=AC/AB。余弦函数:f(x)=cosx(x∈R)
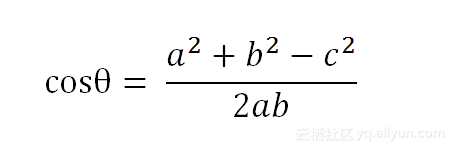
这是一个非常常见的算法,相信大家都应该学过余弦定理了,简单来说这个算法就是通过计算两个向量的夹角余弦值来评估他们的相似度。
对于二维空间,根据向量点积公式,显然可以得知(ps,这个公式不是这个算法的重点,可以不用强记):
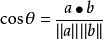
假设向量a、b的坐标分别为(x1,y1)、(x2,y2) 。则:
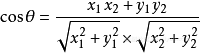
设向量 A = (A1,A2,...,An),B = (B1,B2,...,Bn) 。推广到多维,数学家已经帮我们证明了,所以你只要记住下面的公式:
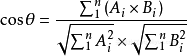
简单来说可以写成下面的式子:
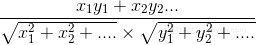
(式子中的x和y是指词频)
比如我们要判断两句话
A=你是个坏人 B=小明是个坏人
① 先进行分词
A=你 / 是 / 个 / 坏人 B=小明 / 是 / 个 / 坏人
② 列出所有的词
{ 你 小明 是 个 坏人 }
③计算词频(出现次数)
A={1 0 1 1} (每个数字对应上面的字) B={0 1 1 1}
然后把词频带入公式
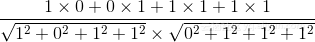
最终=0.667(只余3位),可以百度"2除以(根号3乘以根号3)"看到计算结果。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
简单来说上面计算出的值代表两个句子大概六成相似,越接近1就越相似。
2、简单共有词
通过计算两篇文档共有的词的总字符数除以最长文档字符数来评估他们的相似度。
假设有A、B两句话,先取出这两句话的共同都有的词的字数然后看哪句话更长就除以哪句话的字数。
同样是A、B两句话,共有词的字符长度为4,最长句子长度为6,那么4/6,≈0.667。
3、编辑距离
编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。由俄罗斯科学家Vladimir Levenshtein(找不到他照片233333)在1965年提出这个概念。
例如将“BABAY是个好人”转成“BABY是个帅哥”,编辑举例就是2(好人变帅哥只要2就好...): BABY是个帅人(好→帅) BABY是个帅哥(人→哥)
然后拿编辑距离去除以两者之间的最大长度,2/6≈0.333,意味着只要变动这么多就可以从A变成B,所以不用变动的字符便代表了相似度,1-0.333=0.667。
4、SimHash + 汉明距离
simhash是谷歌发明的算法,据说很nb,可以将一个文档转换成64位的字节,然后我们可以通过判断两个字节的汉明距离就知道是否相似了。
汉明距离是以理查德·卫斯里·汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
1011101 与 1001001 之间的汉明距离是 2。
"toned" 与 "roses" 之间的汉明距离是 3。
首先我们来计算SimHash:
① 提取文档关键词得到[word,weight]这个一个数组。(举例 [美国,4])
② 用hash算法将word转为固定长度的二进制值的字符串[hash(word),weight]。(举例 [100101,4])
③ word的hash从左到右与权重相乘,如果为1则乘以1 ,如果是0则曾以-1。(举例4,-4,-4,4,-4,4)
④ 接着计算下个数,直到将所有分词得出的词计算完,然后将每个词第三步得出的数组中的每一个值相加。(举例美国和51区,[4,-4,-4,4,-4,4]和[5 -5 5 -5 5 5]得到[9 -9 1 -1 1 9])
⑤ 对第四步得到的数组中每一个值进行判断,如果>0记为1,如果<0记为0。(举例[101011])
第四步得出的就是这个文档的SimHash。
这样我们就能将两个不同长度的文档转换为同样长度的SimHash值,so,我们现在可以计算第一个文档的值和第二个文档的汉明距离(一般<3就是相似度高的)。
SimHash本质上是局部敏感性的hash(如果是两个相似的句子,那么只会有部分不同),和md5之类的不一样。 正因为它的局部敏感性,所以我们可以使用海明距离来衡量SimHash值的相似度。
如果想要小数形式的可以这么做:1 - 汉明距离 / 最长关键词数组长度。
5、Jaccard相似性系数
Jaccard 系数,又叫Jaccard相似性系数,用来比较样本集中的相似性和分散性的一个概率。Jaccard系数等于样本集交集与样本集合集的比值,即J = |A∩B| ÷ |A∪B|。
说白了就是交集除以并集,两个文档的共同都有的词除以两个文档所有的词。
*
6、欧几里得距离*
欧几里得距离是用得非常广的公式,设A(x1, y1),B(x2, y2)是平面上任意两点那么两点间的距离距离(A,B)=平方根((x1-x2...)^2+(y1-y2....)^2)
我们可以拿两个文档所有的词(不重复)在A文档的词频作为x,在B文档的作为y进行计算。
同样拿A=你是个坏人、B=小明是个坏人 这两句话作为例子,词频分别为A={1 0 1 1} 、B={0 1 1 1}。
那么距离为根号2,≈ 1.414(余3位)
然后可以通过1 ÷ (1 + 欧几里德距离)得到相似度。
7、曼哈顿距离
曼哈顿距离(Manhattan Distance)是由十九世纪的赫尔曼·闵可夫斯基所创词汇,是种使用在几何度量空间的几何学用语,用以标明两个点上在标准坐标系上的绝对轴距总和。
跟欧几里德距离有点像,简单来说就是d(i,j)=|x1-x2...|+|y1-y2...|,同理xn和yn分别代表两个文档所有的词(不重复)在A和B的词频。
然后可以通过1 ÷ (1 + 曼哈顿距离)得到相似度。
**
其它**
公式生成工具:http://private.codecogs.com/latex/eqneditor.php
计算器:iphone自带
【BABY夜谈大数据】计算文本相似度相关推荐
- 【BABY夜谈大数据】神经网络
前言 如果你喜欢<BABY夜谈大数据>这本书,或者想要及时收到更新,可以到豆瓣上订阅和购买哦! https://read.douban.com/column/3346397/ 神经网络旨在 ...
- 【华为内部狂转的想象力惊人的好文】趣谈大数据
趣谈大数据 一.大数据的初步理解 似乎一夜之间,大数据(Big Data)变成一个IT行业中最时髦的词汇. 首先,大数据不是什么完完全全的新生事物,Google的搜索服务就是一个典型的大数据运用,根据 ...
- 浅谈大数据:如何成为大数据企业?
文章讲的是 浅谈大数据:如何成为大数据企业, 1.什么叫大数据? "大数据"是"数据化"趋势下的必然产物!数据化最核心的理念是:"一切都被记录,一切都 ...
- 数据蒋堂 | 大数据计算语法的SQL化
作者:蒋步星 来源:数据蒋堂 本文共1602字,建议阅读5分钟. 通过本文为大家解读为什么现在SQL变成了当前大数据计算语法的一个发展倾向. 回归SQL是当前大数据计算语法的一个发展倾向.在Hadoo ...
- python计算现场得分_浅谈用 Python 计算文本 BLEU 分数
浅谈用 Python 计算文本 BLEU 分数 BLEU, 全称为 Bilingual Evaluation Understudy(双语评估替换), 是一个比较候选文本翻译与其他一个或多个参考翻译的评 ...
- 大数据计算存储资源池_管家实践:轻松玩转大数据计算服务
以下是直播内容精华整理,主要包括以下四个方面: 1.背景速览: 2.功能介绍: 3.案例讲解: 4.新功能预告. 一.背景速览 MaxCompute(原ODPS)是一项大数据计算服务,它能提供快速.完 ...
- 《大数据》2015年第3期“网络大数据专题”——网络大数据的文本内容分析
网络大数据的文本内容分析 程学旗,兰艳艳 (中国科学院计算技术研究所 北京 100019) 摘要:文本内容分析是实现大数据的理解与价值发现的有效手段.尝试从短文本主题建模.单词表达学习和网页排序学习3 ...
- 大数据计算的四支精干队伍,你造吗
本文首发在我简书的账号上,原文地址:http://www.jianshu.com/p/7a875e09d4e1 <易经·系辞>有云:"形而上者谓之道,形而下者谓之器". ...
- [大数据计算基础] 大数据计算系统
大数据计算系统 大数据计算框架的几个要素 : • 计算场景: 适用于何种任务使用? • 抽象:程序员看到的框架是什么样的? • API:程序员如何使用框架? • 系统架构:系统有哪些模块? • 基本数 ...
最新文章
- 上热搜了!“学了Python6个月,竟然找不到工作!”
- SCLS:巴斯德所崔杰组揭示海洋无脊椎动物RNA病毒的遗传多样
- 【计算机网络】网络安全 : 对称密钥密码体质 ( 数据加密标准 DES | DES 加密过程 | DES 保密性 | 三重 DES 加密 )
- VTK:相互作用之Assembly
- C++/C--C++中substr和Java的substring对比【转载】
- ubuntu之anaconda之编辑器
- Leetcode每日一题:17.letter-combinations-of-a-phone-number(电话号码的字母组合) 0ms通过
- truffle 安装以及基本指令
- 合理设置域名TTL值给网站加速
- ovirt4.4.10安装配置USB重定向
- tbschedule源码学习
- Docker部署应用案例
- pandas 常见写法
- 03 三维地图添加切片图层
- jqwidgets技术分享
- 项目管理:项目开发类型、模型、流程以及案例介绍
- 淘宝代购系统、海外代购系统、代购小程序、APP的开发以及源码PHP前端源码
- java操作excel方法_Java实现操作excel表格的方法
- linux系统克隆后eth0不见了(IP地址没有了)
- PD等多协议快充诱骗触发器SINK(“Power Z 弟弟 Power Low”)DIY
热门文章
- 谁再问我加密算法、签名算法、我上去就是一jio
- 北京大学曹健——Tensorflow笔记 02 Python语法串讲
- 【新手建站教学】如何使用成本更低的虚拟主机实现快速建站?手把手教你搭建一个属于自己的网站。
- 魔众一物一码溯源防伪系统 v1.3.0 产品信息块增强 物流码批量导出
- HTML5期末大作业:HTML+CSS+JavaScript+BootStrap 简约的旅游图文相册博客HTML模板
- pri master hard disk:S.M.A.R.T. status BAD,backup and replace press FX to resume
- 【玩转链表①】单链表动图图解(超详解)
- 怎么把短视频做成gif图?短视频生成gif的步骤
- 淘晶驰串口屏如何修改设备型号
- excle中根据一列数据匹配另一列数据