Word2Vec教程(2)- Negative Sampling
原帖地址:http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
在word2vec第二部分教程中(这里是第一部分part1)
我将会讨论一些在原有skip-gram 模型基础上 额外的小trick,使模型训练可行。
当你读到skip-gram model 的时候,你可能会觉得它是一个很大的网络。(译者按:其实对于现在6G/8G/12G的GPU来说,还是挺小的)
在例子中,我给出了 300个神经元,和10,000个词的词典。考虑输入层和输出层,他们各自会产生 300×10,000=3,000,000300\times10,000=3,000,000 个权重。
在神经网络上跑梯度下降 将会很慢。 更不利的是,你需要大量的数据来调整这些权重,防止过拟合。百万数量级的权重,和千万数量级的训练数据,意味着很难训练这个网络。
Word2Vec的作者在他们第二篇paper中解决了这个问题,有3个创新点:
1.把常见的词组作为一个单词。
2.少采样常见的词 (译者按:A the 啥的都滚粗)
3.修改优化目标函数,这个策略成为“Negative Sampling“,使得每个训练样本只去更新模型中一小部分的weights。
值得注意的是 2和3 不仅仅减少了训练的计算量,而且提升了最后word vector的质量。
词组
作者指出像“Boston Globe“(一家报社)这种词对,和两个单词 Boston/Globe有着完全不同语义。所以更合理的是把“Boston Globe“看成一个单词,有他自己的word vector。
你可以从公开的model中看到,GoogleNews 上有100bilion个单词。额外的词组使得词典达到了 3milion 个单词。
如果你对词典有兴趣去你可以看。
词组检测是另外一个问题降采样常用词
在part1中,我展示了如何从句子中产生训练样本,这里我再重复一下。例子为“The quick brown fox jumps over the lazy dog.“
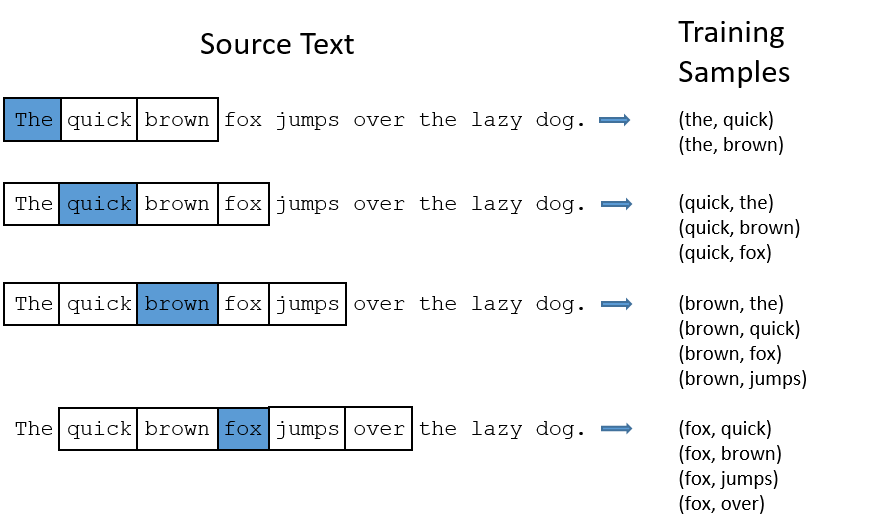
比如像“the“这种常见的词,我们会遇到两个问题:
1. 比如(fox,the)其实没有传递我们关于 fox的信息。‘the‘出现得太多了。
2. 我们有太多 (‘the‘,…)的样本,多于我们真的需要的。
所以word2vec采用了降采样的策略。对于每个我们在训练样本中遇到的词,我们有一个概率去删除它。这个概率与单词出现的频率相关。
如果我们采用window size = 10,同时我们删除“the“:
1. 当我们再去训练剩下的词,我们就不会再遇到‘the‘了;
2. 我们减少了10个包含‘the‘的样本
注意到这两个特点,使得我们可以解决之前提到的两个问题。
采样率
word2vec 的C代码使用了一个等式来计算是否留着这个word。
我们使用 wiw_i 来表示单词,z(wi)z(w_i) 表示它出现在词库中的概率。比如花生在1bilion的词库中出现了1,000词,那么z(花生)=1E−6z(花生)=1E-6。
然后有个叫‘sample‘的参数控制了降采样的程度,一般设置为0.001。这个值越小代表更容易扔掉一些词。
下面这个等式 P(wi)P(w_i) 代表保留这个词的概率
P(wi)=(z(wi)/0.001‾‾‾‾‾‾‾‾‾‾‾√+1)×0.001/z(wi)P(w_i) = (\sqrt{z(w_i)/0.001}+1)\times0.001/z(w_i)
可以看到如果单词出现频率很低,
z(wi)<=0.0026z(w_i) 的情况下,P(wi)=1P(w_i)=1,我们不会把这些词扔掉;
当z(wi)<=0.00746z(w_i) 的情况下,P(wi)=0.5P(w_i)=0.5;
如果出现频率很高,z(wi)==1z(w_i)==1 的情况下,P(wi)=0.033P(w_i)=0.033, 有很低的概率我们keep这个word。当然,如果每个训练样本对都有这个词,这种情况不会出现。
你可能注意到论文中提到的这个函数和C代码中的不同。但是我发现C代码中的函数可能更authoritative。Negative Sampling
训练神经网络 意味着输入一个训练样本调整weight,让它预测这个训练样本更准。换句话说,每个训练样本将会影响网络中所有的weight。
像我们之前讨论的一样,我们词典的大小意味着我们有好多weight,所有都要轻微的调整。
Negative sampling 解决了这个问题,每次我们就修改了其中一小部分weight,而不是全部。
当训练(fox,quick)这个词对的时候,quick这个词的概率是1,其他的都是0。通过negative sample,我们只是随机的选了一部分negative词(假设是5个)来update weight。(这些negative 词就是我们希望是0的。)
论文中说5-20个词适合小数据集, 2-5个词适合大数据集。回忆我们原来模型每次运行都需要 300×10,000300\times10,000 (译者按,其实没有减少数量,但是运行过程中,减少了需要载入的数量。) 现在只要 300×(1+5)300\times (1+5) 减少了好多。
而在输出层始终只要update 输入单词的weight 就好了。(不论有没有采用negative sampling)
译者按:因为输入层就像lookup table,当然其他的都不影响的。
选择 negative samples
问题来了,如何选择5个negative sample呢。
negative sample也是根据他们出现频率来选的。更常出现的词,更容易被选为negative sample。
在word2vec的C实现中,你可以看到一个等式来表达这个概率。每个词给了一个和它频率相关的权重。这个概率公式为
P(wi)=f(wi)0.75∑nj=0(f(wj)0.75)P(w_i) = \frac{f(w_i)^{0.75} }{ \sum_{j=0}^{n}(f(w_j)^{0.75}})
在paper中说0.75这个超参是试出来的,这个函数performance比其他函数好。
而这个实现方式在C代码。采用的就是一个100M的查找表,这个表里,按概率填入每个词,每个词填空的个数为 P(wi)∗tabelsizeP(w_i)*tabelsize 。每次选副样本,只要随机一个整数,然后查找表读就好了。因为高频词出现的更多,所以你更可能选到那些词。
Word2Vec教程(2)- Negative Sampling相关推荐
- [深度学习概念]·word2vec原理讲解Negative Sampling的模型概述
word2vec原理讲解Negative Sampling的模型概述 目录 1. Hierarchical Softmax的缺点与改进 2. 基于Negative Sampling的模型概述 3. 基 ...
- NLP | Word2Vec之基于Negative Sampling的 CBOW 和 skip-gram 模型
前面介绍了基于Hierarchical Softmax的 skip-gram 和 CBOW 模型,虽然我们使用霍夫曼树代替传统的神经网络,可以提高模型训练的效率.但是如果我们的训练样本里的中心词www ...
- 基于pytorch实现Word2Vec(skip-gram+Negative Sampling)
目录 word2vec简介 语料处理 数据预处理 训练模型 近似训练法 参数设定 预测及可视化 word2vec简介 2013 年,Google 团队发表了 word2vec 工具.word2vec ...
- word2vec原理(三): 基于Negative Sampling的模型
目录 1. Hierarchical Softmax的缺点与改进 2. Negative Sampling(负采样) 概述 3. 基于Negative Sampling的模型梯度计算 4. Negat ...
- 【word2vec】篇三:基于Negative Sampling 的 CBOW 模型和 Skip-gram 模型
系列文章: [word2vec]篇一:理解词向量.CBOW与Skip-Gram等知识 [word2vec]篇二:基于Hierarchical Softmax的 CBOW 模型和 Skip-gram 模 ...
- Word2Vec学习笔记(四)——Negative Sampling 模型
前面讲了Hierarchical softmax 模型,现在来说说Negative Sampling 模型的CBOW和Skip-gram的原理.它相对于Hierarchical softmax 模型来 ...
- CS224n 词的向量表示word2vec 之skipgram (Negative sampling )
CS224n 词的向量表示word2vec 之skipgram (Negative sampling ) #!/usr/bin/env pythonimport numpy as np import ...
- Word2Vec学习笔记(五)——Negative Sampling 模型(续)
本来这部分内容不多,是想写在negative sampling 中和cbow一起的,但是写了后不小心按了删除键,浏览器直接回退,找不到了,所以重新写新的,以免出现上述情况 (接上) 三.Negativ ...
- NCE损失(Negative Sampling)
DSSM的损失函数: 先是1个正例和5个负例过softmax: 最后交叉熵损失函数: Word2Vec的损失函数:输入词的词向量和预测词(或负例)的分界面向量点乘,经过sigmoid,再过交叉熵损失函 ...
最新文章
- 中国科大潘建伟团队量子网络研究获重要进展
- Project Management Library项目管理甘特图控件
- WordPress后台的文章、分类,媒体,页面,评论,链接等所有信息中显示ID并将ID设置为第一列...
- Blockquotes,引用,html里面,经常用到的一个!
- python中读取文件编码_[转载]python中使用文件的读取编码问题
- solaris 10 虚拟机下安装双机
- java1.8移除apt,java 1.8上的maven-enunciate-plugin现在从最新的JDK中删除了(即java注释处理工具)...
- MySql-Mysql技术内幕~SQL编程学习笔记(N)
- Install/Remove of the Service Denied
- 3dmax2022序列号 附使用说明
- crispr基因编辑_用CRISPR编程基因组
- Java/Android 进程与线程之 多线程开发(二)
- python如何读取log文件_怎么解决Python读取log文件时报错
- python发邮件附件_python 发送带附件的邮件
- 用计算机弹暖暖数字代码,奇迹暖暖网页版计算器
- node php v2ex,仿V2EX开源二次元论坛程序+安装教程
- 开源权限引擎可能理解了骇客帝国
- python程序怎么运行-Python如何运行程序
- 用excel画像素画,和十字绣一样简单
- 学计算机显卡,计算机显卡与显示器