基于RGB-D的6D目标检测算法
基于RGB-D的6D目标检测算法
本文参考了ITAIC的文章 A Review of 6D Object Pose Estimation
概览
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eQX8ke6j-1683188966051)(https://mezereon-upic.oss-cn-shanghai.aliyuncs.com/uPic/image-20230420165625575.png)]
这里介绍几篇经典的基于RGB-D的6D目标检测算法。
RGB-D,就是RGB + Depth,也就是彩色图像 + 深度信息。
直觉上来说,比单纯的RGB有了更多的信息,精度也会变得更加高了。
这里给出RGB部分方法的性能进行对比,RGB-D的指标是采用的ADD(-S), 所以我们就只看第3,4,5列的指标
![]()
算法REDE在Linemod、Occlusion Linemod、YCB-Video数据集上基本已经超越了所有的RGB算法。
接下来,我们主要介绍三个RGB-D算法G2LNet、PVN3D以及REDE。
G2L-Net
G2L-Net: Global to Local Network for Real-time 6D Pose Estimation with Embedding Vector Features
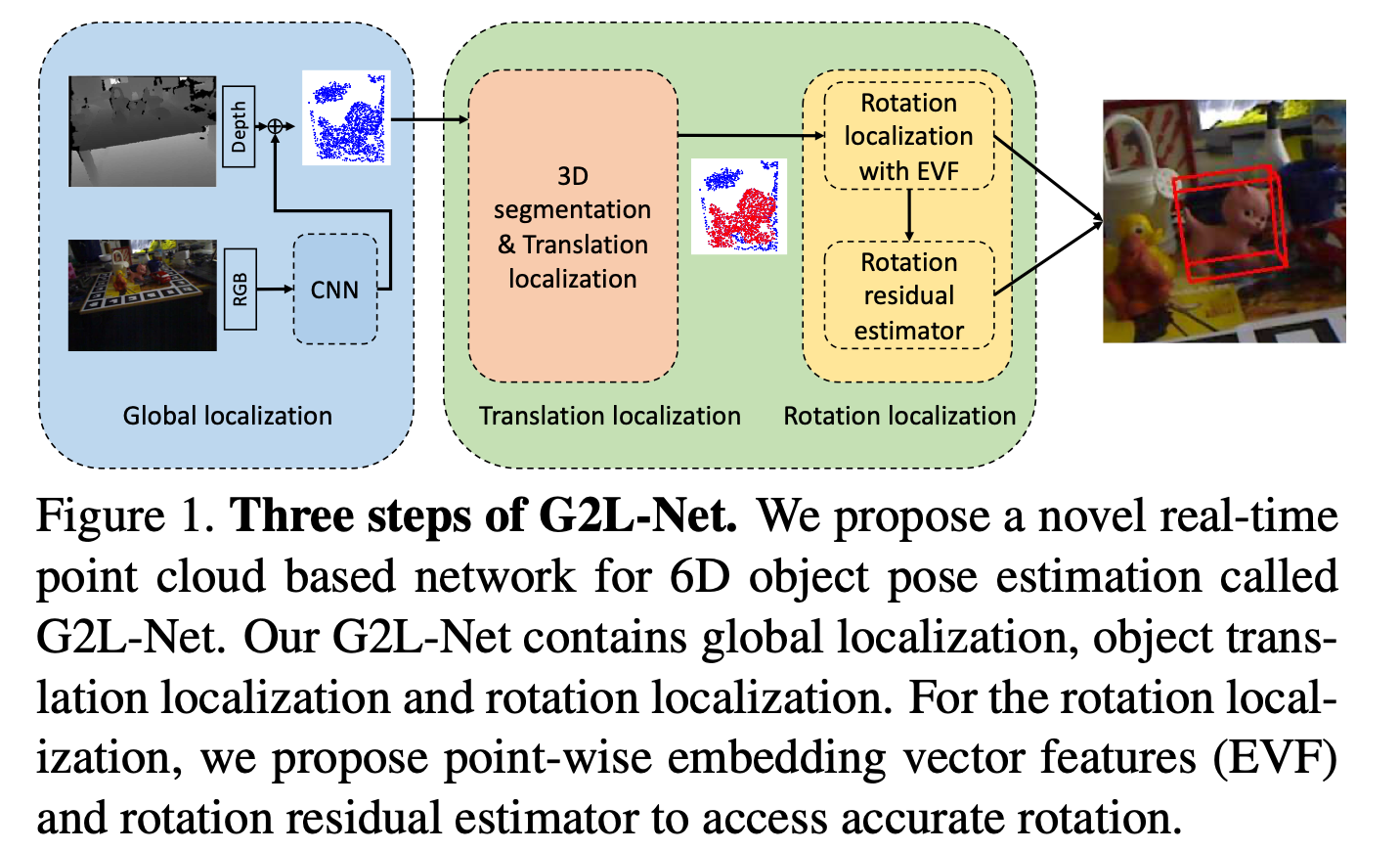
如上图所示,分成三个步骤:
- 全局的定位(Global Localization)
- 平移的定位(Translation Localization)
- 旋转的定位(Rotation Localization)
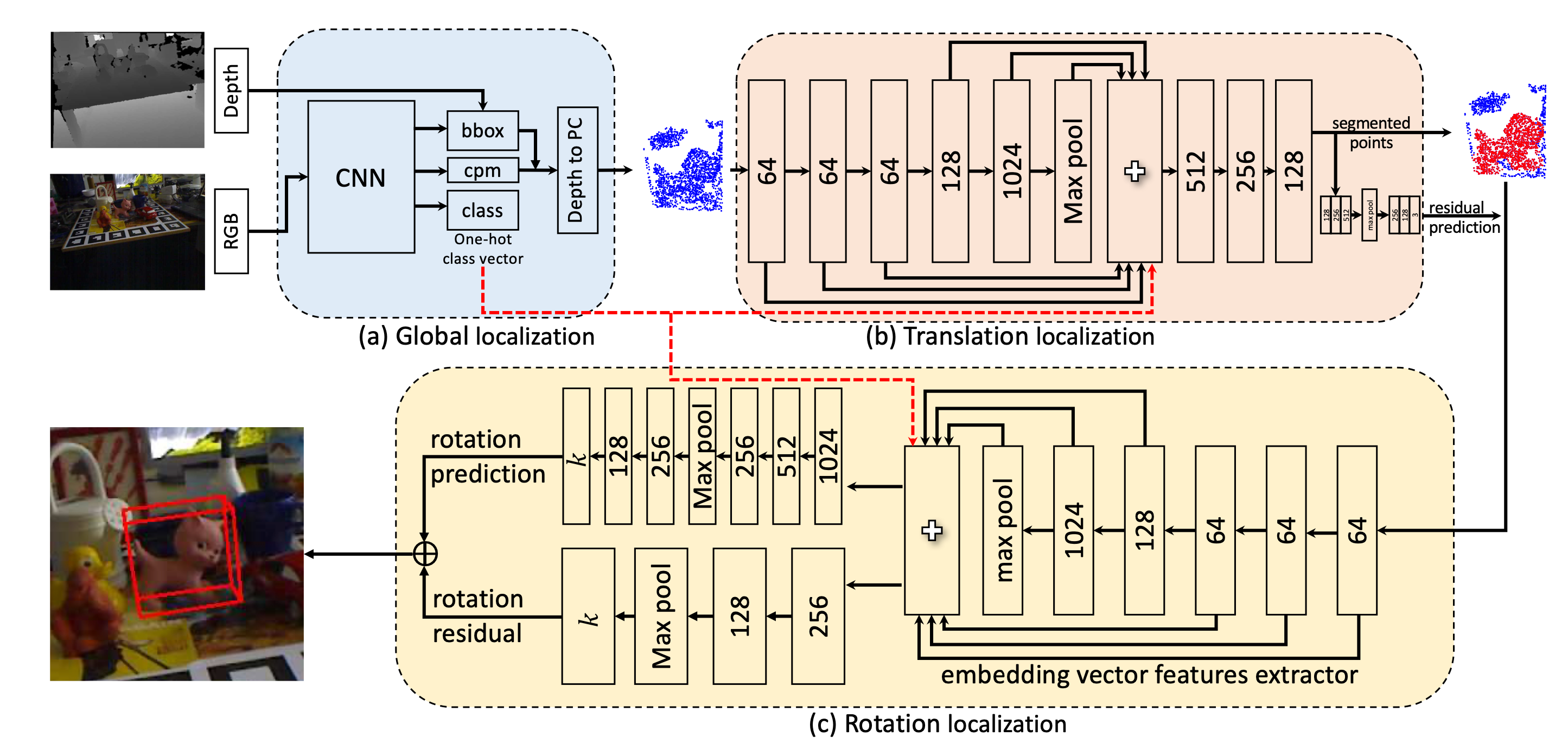
全局的定位
具体而言,首先将RGB图像送到CNN中,得到三个东西:边界框,类别概率图(class probability map),类别向量
文章使用的是一个YOLOv3作为2D的目标检测器
利用2D的边界框架上深度信息,就可以构造出一个个棱台(frustum proposal),只考虑棱台中包含的空间点,便减少了所需要计算的数据规模。
这里文章引入了一种3D球的约束,将点云变得更加紧致
最终输出一系列的点云,对应2D目标检测的结果
平移的定位
利用3D的点云信息,做语义分割,得到分割后的点云,即每一个空间点有自己的类别
旋转的定位
这里将类别向量引入,以点云信息作为输入,直接输出对应的旋转
PVN3D
PVN3D: A Deep Point-Wise 3D Keypoints V oting Network for 6DoF Pose Estimation
![]()
个人认为其主要的贡献在于结合了语义分割的技术
如上图所示,整个PVN3D可以被分成多个部分:
- 特征抽取
- 3D关键点检测
- 语义分割
- 6DoF姿态估计
特征抽取
这里使用一个卷积网络CNN和一个PointNet++分别提取RGB特征以及深度特征,然后进行特征融合。
3D关键点检测、语义分割
使用MLP来分别估计关键点的平移、中心点以及每一个点的语义类别标签
可以看到,其输出的维度分别对应3、22、3,即3个平移的偏移值,22个类别,以及3个中心点偏移值。
然后使用语义标签和中心点,使用投票Vote和聚类Cluster,得到一个实例级别的语义分割
然后将这个结果结合关键点检测,就能给这些关键点分配对应的实体
6DoF姿态估计
使用最小二乘(Least-Square Fitting)实现姿态估计,输出旋转矩阵R以及平移t
REDE
REDE: End-to-End Object 6D Pose Robust Estimation Using Differentiable Outliers Elimination
我们先来看看该方法和其他方法的区别
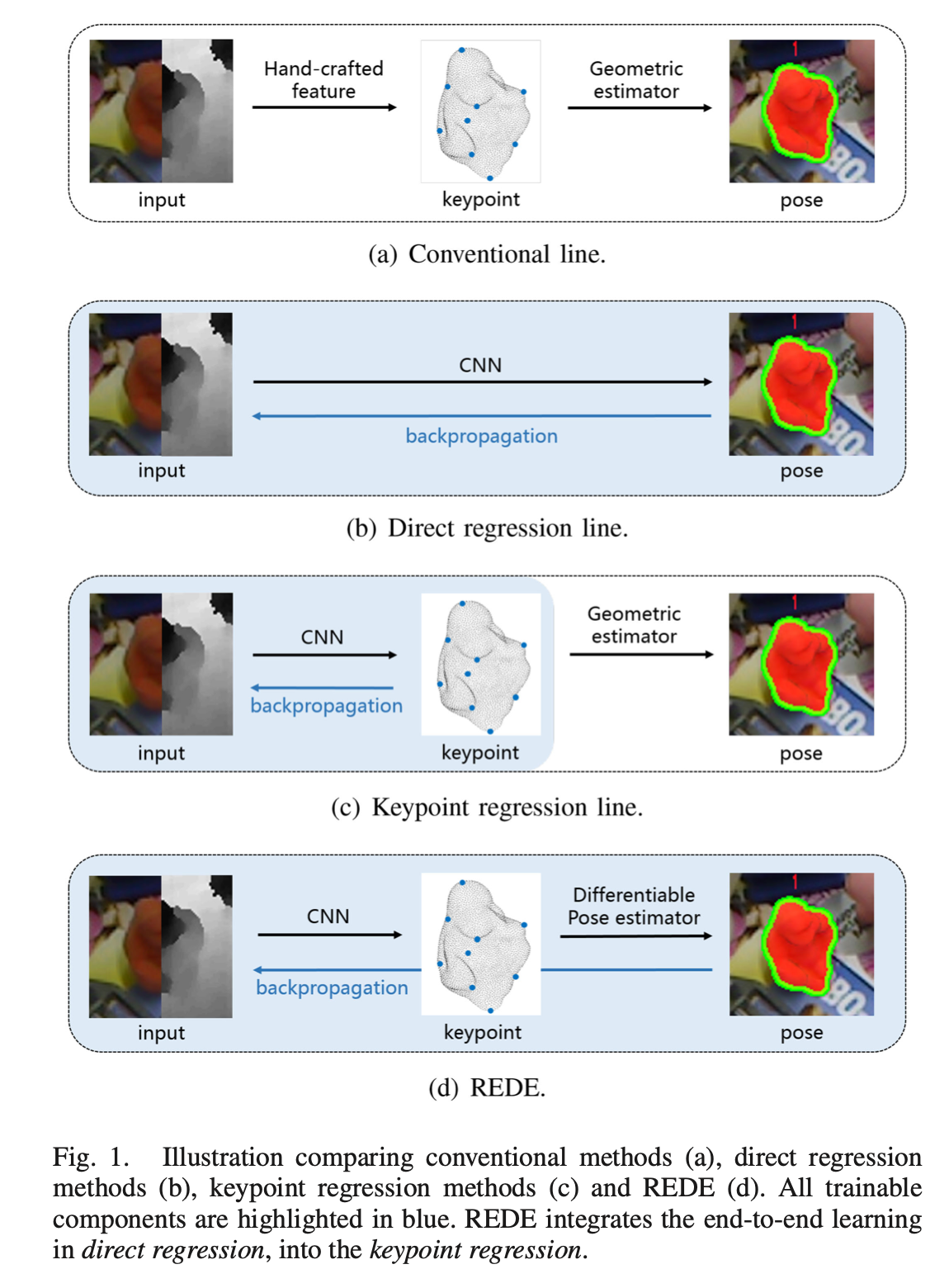
如上图所示,©是基于关键点回归的方法,(d)是REDE方法
可以看到,用CNN去做关键点的检测这一步,大家都是一样的,只不过在后面对姿态进行估计时,REDE是可差分的,能够直接反向传播到前面所有的可学习的参数上。
回想一下上面的PVN3D,在计算关键点之后,便使用最小二乘去估计姿态,估计的偏差并不会影响前面的参数,所以仍然属于©。
下面给出其方法的概览
![]()
从左到右:
- 首先使用点级别的编码
- 类似PVN3D,这里也是分别进行编码,用PSPNet抽取RGB特征,用PointNet抽取深度图信息
- 最后将RGB特征和深度特征融合在一起,具体实现可以参考其仓库中的 lib/network.py
- 然后使用快速点采样 (Fast Point Sample,FPS) 得到K个关键点,用网络估计这些关键点的偏移,计算L1误差
- 这里引入一个异常偏移消除 (Outlier Offsets Elimination) 技术,对于每一个点的偏移估计,多计算一个置信度c,在计算关键点位置的时候,乘以这个置信度
- 使用一个Minimal Solvers Bank,对每三个关键点求姿态估计,这样就可以生成 C K 3 C_K^3 CK3 个姿态,提高整体的鲁棒性
- 最后,对 C K 3 C_K^3 CK3 个姿态,加权平均,通过2范数和F范数计算偏移和旋转的误差,实现可微分的误差计算
基于RGB-D的6D目标检测算法相关推荐
- 目标检测YOLO实战应用案例100讲-基于卷积神经网络的小目标检测算法研究
目录 基于卷积神经网络的小目标检测算法研究 基于卷积神经网络的小目标检测相关理论 2.1 引言
- 目标检测论文解读复现之十六:基于改进YOLOv5的小目标检测算法
前言 此前出了目标改进算法专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读最新目标检测算法论文,帮 ...
- 基于python的HOG+SVM目标检测算法实现
目录 一.场景需求解读 二.HOG算法简介 三.SVM算法简介 四.基于HOG的目标检测算法训练流程 五.目标检测代码实现 六.非极大值抑制(NMS)简介及代码实现 七.NMS效果展示与分析 八.思维 ...
- 目标检测YOLO实战应用案例100讲-基于深度学习的无人机目标检测算法轻量化研究
目录 基于深度学习的无人机图像目标检测算法研究 目标检测相关技术理论 2.1 引言
- 目标检测YOLO实战应用案例100讲-基于改进的YOLOv4柑橘目标检测算法
目录 基于改进的YOLOX目标检测算法研究 目标检测相关理论基础 2.1 深度学习 2.2 目标检测
- 五种基于RGB色彩空间统计的皮肤检测算法
最近一直在研究多脸谱识别以及如何分辨多个皮肤区域是否是人脸的问题 网上找了很多资料,看了很多篇文章,将其中基于RGB色彩空间识别皮肤 的统计算法做了一下总结,统计识别方法主要是简单相比与很多其它基于 ...
- 基于形态学的复杂背景目标检测算法
1.问题描述: 复杂背景下目标检测存在诸多困难,主要为背景对目标检测的干扰,大量噪声存在导致传统导数边缘检测方法的失效等.本文正是针对上述两点,提出了分割区域图像.利用形态学方法检测目标的新算法:即首 ...
- 目标检测YOLO实战应用案例100讲-基于轻量化神经网络的目标检测算法研究与应用
目录 基于轻量化深度神经网络的目标检测方法研究 基于深度学习的目标检测方法
- 目标检测YOLO实战应用案例100讲-基于深度学习的交通场景多尺度目标检测算法研究与应用
目录 基于深度学习的交通目标检测算法研究 传统的目标检测算法 基于深度学习的目标检测算法 </
最新文章
- JavaScript Switch 语句
- AI 算法给手画线稿自动上色指南来了
- 安装虚拟机Ubuntu,搭建lnmp环境碰到的坑(二)
- 金融量化alpha和beta值的意义
- 完美解决tomcat/springboot启动速度相当慢 快死的状态了
- RabbitMQ Network Partitions 服务日志对比
- Java调用虚拟键盘输入法_Android 点击屏幕空白处收起输入法软键盘(手动打开)...
- mysql5.6 with as 用法_python面试专题with 关键字与上下文管理
- 集合框架(Set容器)
- C语言 显示器键盘io
- C#对称加密(3des)和非对称加密(rsa)算法
- oracle闪回scn,Oracle闪回查询及scn_to_timestamp
- 第五版fmea表格_FMEA第五版: 新版 DFMEA六步法解析
- python 对象转json
- win10易升_易升win10失败怎么办
- MRI_Made_Easy 磁共振成像原理-物理基础5
- sCrypt 合约中的椭圆曲线算法:第二部分
- (function(){})() 理解
- ABAP基本数据类型
- 正则表达式的字符串匹配