AI独角兽商汤科技的内部服务容器化历程 1
2019独角兽企业重金招聘Python工程师标准>>> 
本文由阿尔曼,商汤科技运维工程师于4月26日晚在Rancher微信群所做的技术分享整理而成。商汤科技是专注于计算机视觉领域的AI公司。本次分享结合了容器平台团队帮助公司业务/内部服务容器化历程,介绍商汤科技在容器化历程中使用的工具、拥有的最佳实践及值得分享的经验教训。
搜索微信号RancherLabsChina,或文末扫码,添加Rancher小助手为好友,可加入官方技术交流群,实时参加下一次分享~
内容目录
● 背景
● 需求分析与技术选型
● 容器镜像
● 监控报警
● 可靠性保障
● 总结
背 景
商汤科技是一家计算机视觉领域的AI创业公司,公司内会有一些业务需要云端API支持,一些客户也会通过公网调用这些所谓SaaS服务。总体来讲,云API的架构比较简单,另外由于公司成立不久,历史包袱要轻许多,很多业务在设计之初就有类似微服务的架构,比较适合通过容器化来适配其部署较繁复的问题。
公司各个业务线相对独立,在组织上,体现在人员,绩效及汇报关系的差异;在技术上体现在编程语言,框架及技术架构的独自演进,而服务的部署上线和后续维护的工作,则划归于运维部门。这种独立性、差异性所加大的运维复杂度需要得到收敛。
我们遇到的问题不是新问题,业界也是有不少应对的工具和方法论,但在早期,我们对运维工具的复杂性增长还是保持了一定的克制:ssh + bash script扛过了早期的一段时光,ansible也得到过数月的应用,但现实所迫,我们最终还是投向了Docker的怀抱。
Docker是革命性的,干净利落的UX俘获了技术人员的芳心,我们当时所处的时期,容器编排的大战则正处于Docker Swarm mode发布的阶段,而我们需要寻找那种工具,要既能应对日益增长的运维复杂度,也能把运维工程师从单调、重复、压力大的发布中解放出来。
Rancher是我们在HackerNews上的评论上看到的,其简单易用性让我们看到了生产环境部署容器化应用的曙光,但是要真正能放心地在生产环境使用容器,不“翻车”,还是有不少工作要做。由于篇幅的原因,事无巨细的描述是不现实的。我接下来首先介绍我们当时的需求分析和技术选型,再谈谈几个重要的组成部分如容器镜像、监控报警和可靠性保障。

需求分析与技术选型
暂时抛开容器/容器编排/微服务这些时髦的词在一边,对于我们当时的情况,这套新的运维工具需要三个特性才能算成功:开发友好、操作可控及易运维。
开发友好
能把应用打包的工作推给开发来做,来消灭自己打包/编译如java/ruby/python代码的工作,但又要保证开发打出的包在生产环境至少要能运行,所以怎么能让开发人员方便正确地打出发布包,后者又能自动流转到生产环境是关键。长话短说,我们采取的是Docker + Harbor的方式,由开发人员构建容器镜像,通过LDAP认证推送到公司内部基于Harbor的容器镜像站,再通过Harbor的replication机制,自动将内部镜像同步到生产环境的镜像站,具体实现可参考接下来的容器镜像一节。
操作可控
能让开发人员参与到服务发布的工作中来,由于业务线迥异的业务场景/技术栈/架构,使得只靠运维人员来解决发布时出现的代码相关问题是勉为其难的,所以需要能够让开发人员在受控的情境下,参与到服务日常的发布工作中来,而这就需要像其提供一些受限可审计且易用的接口,WebUI+Webhook就是比较灵活的方案。这方面,Rancher提供的功能符合需求。
易运维
运维复杂度实话说是我们关注的核心,毕竟容器化是运维部门为适应复杂度与日俱增而发起的,屁股决定脑袋。考虑到本身容器的黑盒性和稳定性欠佳的问题,再加上真正把容器技术搞明白的人寥寥无几,能平稳落地的容器化运维在我们这里体现为三个需求:多租户支持,稳定且出了事能知道,故障切换成本低。多租户是支持多个并行业务线的必要项;容器出问题的情况太多,线上环境以操作系统镜像的方式限定每台机器Docker和内核版本;由于传统监控报警工具在容器化环境捉襟见肘,需要一整套新的监控报警解决方案;没人有把握能现场调试所有容器问题(如跨主机容器网络不通/挂载点泄漏/dockerd卡死/基础组件容器起不来),需要蓝绿部署的出故障后能立刻切换,维护可靠与可控感对于一个新系统至关重要。
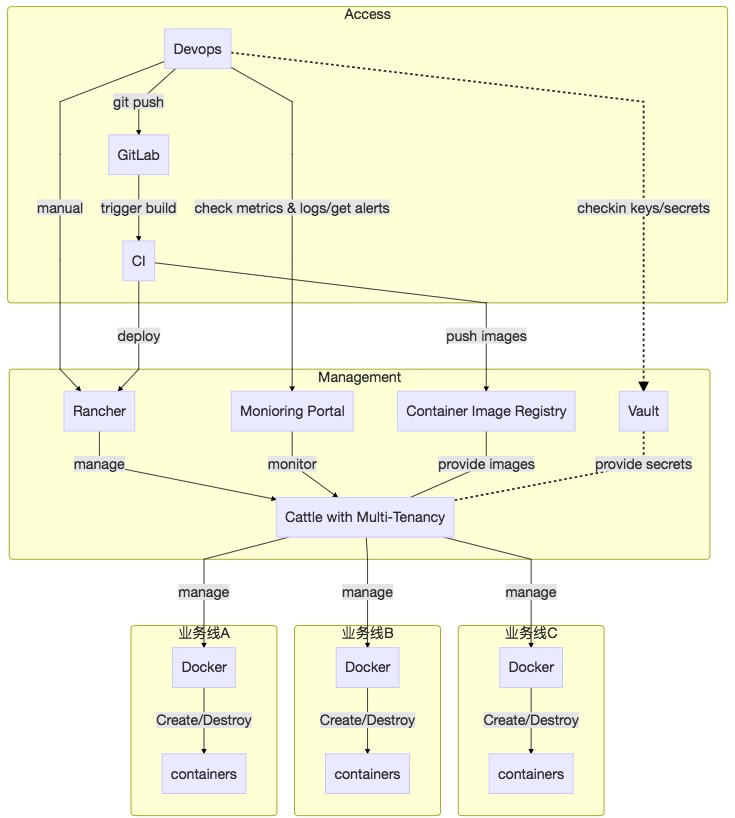
技术架构图
总结一下,Rancher, Harbor, Prometheus/Alertmanager为主的开源系统组合可以基本满足容器管理的大部分需求,总体架构如下图
容器镜像
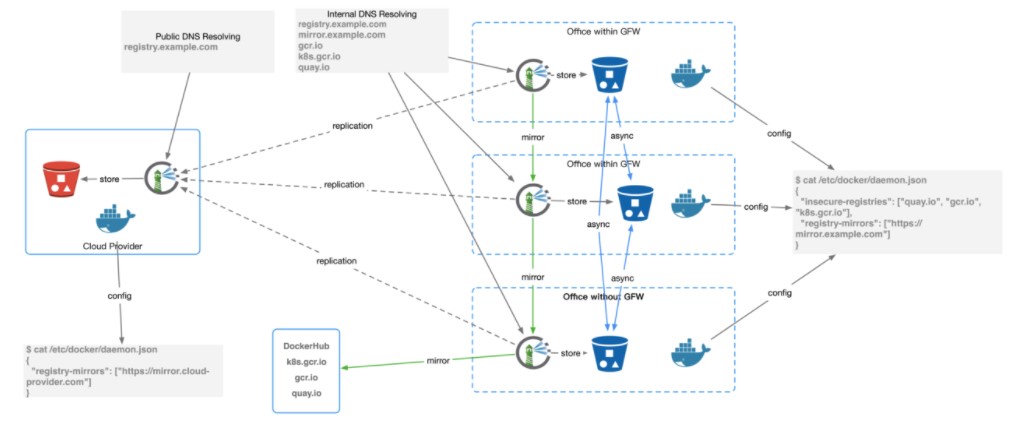
容器镜像服务是公司级别的IT基础设施,在各个办公区互联带宽有限的物理限制下,需要给分散在多个地理位置的用户以一致、方便、快速的使用体验。我们主要使用了Vmware开源的Harbor工具来搭建容器镜像服务,虽然Harbor解决了如认证、同步等问题,但Harbor不是这个问题的银色子弹,还是需要做一些工作来使镜像服务有比较好的用户体验。这种体验我们以Google Container Registry为例来展现。
作为Google的开放容器镜像服务,全球各地的用户都会以同一个域名gcr.io推拉镜像docker push gcr.io/my_repo/my_image:my_tag,但其实用户推拉镜像的请求,由于来源地理位置不同,可能会被GeoDNS分发在不同的Google数据中心上,这些数据中心之间有高速网络连接,各种应用包括GCR会通过网络同步数据。这样的方法既给用户一致的使用体验,即所有人都是通过gcr.io的域名推拉镜像,又因为每个人都是同自己地理位置近的数据中心交互而不会太“卡”,并且由于Google Container Registry底层存储的跨数据中心在不断高速同步镜像(得益于Google优异的IT基础设施),异国他乡的别人也能感觉很快地拉取我们推送的镜像(镜像“推”和“拉”的异步性是前提条件)。
花篇幅介绍Google Container Registry的目的是,用户体验对用户接受度至关重要,而后者往往是一个新服务存活的关键,即在公司内部提供类似GCR一般的体验,是我们容器镜像服务为了成功落地而想接近的产品观感。为了达到这种观感,需要介绍两个核心的功能,开发/生产镜像自动同步,镜像跨办公区同步。另外,虽然有点超出镜像服务本身,但由于特殊的国情和使用关联性,国外镜像(DockerHub, GCR, Quay)拉取慢也是影响容器镜像服务使用体验的关键一环,镜像加速服务也是需要的。
开发/生产镜像自动同步
由于开发环境(公司私网),生产环境(公网)的安全性和使用场景的差异,我们部署了两套镜像服务,内网的为了方便开发人员使用是基于LDAP认证,而公网的则做了多种安全措施来限制访问。但这带来的问题是如何方便地向生产环境传递镜像,即开发人员在内网打出的镜像需要能自动地同步到生产环境。
我们利用了Harbor的replication功能,只对生产环境需要的项目才手动启用了replication,通过这种方式只需初次上线时候的配置,后续开发的镜像推送就会有内网Harbor自动同步到公网的Harbor上,不需要人工操作。
镜像跨办公区同步
由于公司在多地有办公区,同一个team的成员也会有地理位置的分布。为了使他们能方便地协作开发,镜像需要跨地同步,这我们就依靠了公司已有的swift存储,这一块儿没有太多可说的,带宽越大,同步的速度就越快。值得一提的是,由于Harbor的UI需要从MySQL提取数据,所以如果需要各地看到一样的界面,是需要同步Harbor MySQL数据的。
镜像加速
很多开源镜像都托管在DockerHub、Google Container Registry和Quay上,由于受制于GFW及公司网络带宽,直接pull这些镜像,速度如龟爬,极大影响工作心情和效率。
一种可行方案是将这些镜像通过代理下载下来,docker tag后上传到公司镜像站,再更改相应manifest yaml,但这种方案的用户体验就是像最终幻想里的踩雷式遇敌,普通用户不知道为什么应用起不了,即使知道了是因为镜像拉取慢,镜像有时能拉有时又不能拉,他的机器能拉,我的机器不能拉,得搞明白哪里去配默认镜像地址,而且还得想办法把镜像从国外拉回来,上传到公司,整个过程繁琐耗时低智,把时间浪费在这种事情上,实在是浪费生命。
我们采取的方案是,用mirror.example.com的域名来mirror DockerHub,同时公司nameserver劫持quay,gcr,这样用户只需要配置一次docker daemon就可以无痛拉取所有常用镜像,也不用担心是否哪里需要override拉取镜像的位置,而且每个办公区都做类似的部署,这样用户都是在办公区本地拉取镜像,速度快并且节约宝贵的办公区间带宽。
值得一提的是,由于对gcr.io等域名在办公区内网做了劫持,但我们手里肯定没有这些域名的key,所以必须用http来拉取镜像,于是需要配置docker daemon的--insecure-registry这个项
用户体验
配置docker daemon(以Ubuntu 16.04为例)
sudo -s
cat << EOF > /etc/docker/daemon.json
{"insecure-registries": ["quay.io", "gcr.io","k8s.gcr.io],"registry-mirrors": ["https://mirror.example.com"]
}
EOF
systemctl restart docker.service
测试
# 测试解析,应解析到一个内网IP地址(private IP address)
# 拉取dockerhub镜像
docker pull ubuntu:xenial
# 拉取google镜像
docker pull gcr.io/google_containers/kube-apiserver:v1.10.0
# 拉取quay镜像
docker pull quay.io/coreos/etcd:v3.2
# minikube
minikube start --insecure-registry gcr.io,quay.io,k8s.gcr.io --registry-mirror https://mirror.example.com
技术架构图
监控报警
由于zabbix等传统监控报警工具容器化环境中捉襟见肘,我们需要重新建立一套监控报警系统,幸亏prometheus/alertmanager使用还算比较方便,并且已有的zabbix由于使用不善,导致已有监控系统的用户体验很差(误报/漏报/报警风暴/命名不规范/操作复杂等等),不然在有限的时间和人员条件下,只是为了kick start而什么都得另起炉灶,还是很麻烦的。
其实分布式系统的监控报警系统,不论在是否用容器,都需要解决这些问题:能感知机器/容器(进程)/应用/三个层面的指标,分散在各个机器的日志要能尽快收集起来供查询检索及报警低信噪比、不误报不漏报、能“望文生义”等。
而这些问题就像之前提到的,prometheus/alertmanager已经解决得比较好了:通过exporter pattern,插件化的解决灵活适配不同监控目标(node-exporter, cAdvisor, mysql-exporter, elasticsearch-exporter等等);利用prometheus和rancher dns服务配合,可以动态发现新加入的exporter/agent;alertmanager则是一款很优秀的报警工具,能实现alerts的路由/聚合/正则匹配,配合已有的邮件和我们自己添加的微信(现已官方支持)/电话(集成阿里云语音服务),每天报警数量和频次达到了oncall人员能接受的状态。
至于日志收集,我们还是遵从了社区的推荐,使用了Elasticsearch + fluentd + Kibana的组合,fluentd作为Rancher的Global Serivce(对应于Kubernetes的daemon set),收集每台机器的系统日志,dockerd日志,通过docker_metadata这个插件来收集容器标准输出(log_driver: json_file)的日志,rancher基础服务日志,既本地文件系统压缩存档也及时地发往相应的elasticsearch服务(并未用容器方式启动),通过Kibana可视化供产品售后使用。基于的日志报警使用的是Yelp开源的elastalert工具。
为每个环境手动创建监控报警stack还是蛮繁琐的,于是我们也自定义了一个Rancher Catalog来方便部署。
监控报警系统涉及的方面太多,而至于什么是一个“好”的监控报警系统,不是我在这里能阐述的话题,Google的Site Reliability Engineering的这本书有我认为比较好的诠释,但一个抛砖引玉的观点可以分享,即把监控报警系统也当成一个严肃的产品来设计和改进,需要有一个人(最好是核心oncall人员)承担产品经理般的角色,来从人性地角度来衡量这个产品是否真的好用,是否有观感上的问题,特别是要避免破窗效应,这样对于建立oncall人员对监控报警系统的信赖和认可至关重要。
技术架构图 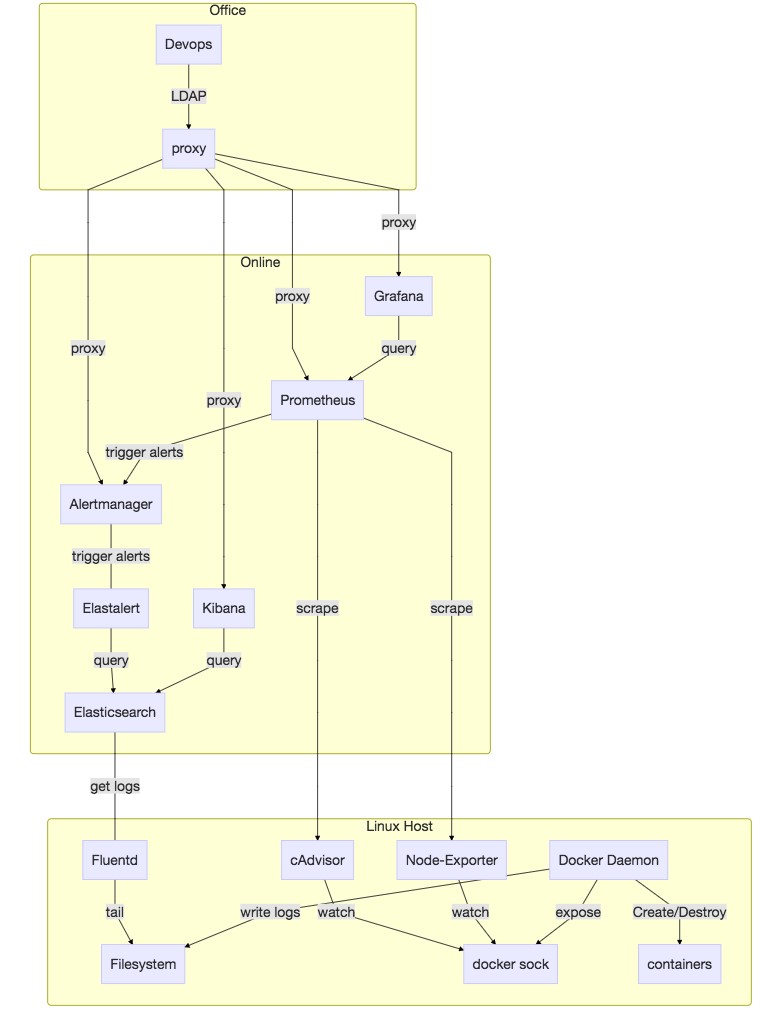
可靠性保障
分布式系统在提升了并发性能的同时,也增大了局部故障的概率。健壮的程序设计和部署方案能够提高系统的容错性,提高系统的可用性。可靠性保障是运维部门发起的一系列目的在于保障业务稳定/可靠/鲁棒的措施和方法,具体包括:
● 生产就绪性检查
● 备份管理体系
● 故障分析与总结
● chaos monkey
主要谈谈chaos monkey,总体思路就是流水不腐,户枢不蠹。通过模拟各种可能存在的故障,发现系统存在的可用性问题,提醒开发/运维人员进行各种层面的改进。
预期
大多数故障无需人立刻干预
业务异常(如HTTP 502/503)窗口在两分钟以内
报警系统应该保证
不漏报没有报警风暴报警分级别(邮件/微信/电话)发到该接收报警的人
测试样例
我们需要进行测试的case有:
service升级
业务容器随机销毁
主机遣散
网络抖动模拟
Rancher基础服务升级
主机级别网络故障
单主机机器宕机
若干个主机机器宕机
可用区宕机
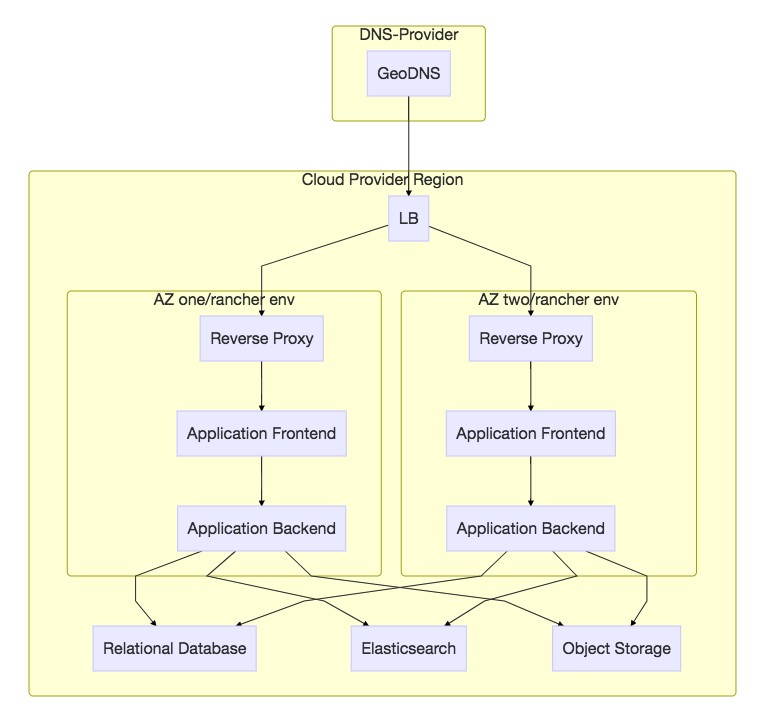
部署示例(单个租户 & 单个地域)
总 结
1、体量较小公司也可以搭建相对可用的容器平台。
2、公司发展早期投入一些精力在基础设施的建设上,从长远来看还是有价值的,这种价值体现在很早就可以积累一批有能力有经验有干劲儿的团队,来不断对抗规模扩大后的复杂性猛增的问题。一个“让人直观感觉”,“看起来”混乱的基础技术架构,会很大程度上影响开发人员编码效率。甚至可以根据破窗原理揣测,开发人员可能会觉得将会运行在“脏”,“乱”,”差”平台的项目没必要把质量看得太重。对于一个大的组织来讲,秩序是一种可贵的资产,是有无法估量的价值的。
3、镜像拉取慢问题也可以比较优雅地缓解。
4、国内访问国外网络资源总体来讲还是不方便的,即使没有GFW,带宽也是很大的问题。而我们的解决方案也很朴素,就是缓存加本地访问,这样用比较优雅高效地方法解决一个“苍蝇”问题,改善了很多人的工作体验,作为工程人员,心里是很满足的。
5、容器化也可以看作是一种对传统运维体系的重构。
6、容器化本质上是当容器成为技术架构的所谓building blocks之后,对已有开发运维解决方案重新审视,设计与重构。微服务、云原生催生了容器技术产生,而后者,特别是Docker工具本身美妙的UX,极大地鼓舞了技术人员与企业奔向运维“应许之地”的热情。虽然大家都心知肚明银色子弹并不存在,但Kubernetes ecosystem越来越看起来前途不可限量,给人以无限希望。而贩卖希望本身被历史不断证明,倒真是稳赚不亏的商业模式。
致 谢
1、感谢Richard Stallman为代表的自由软件运动的参与者、贡献者们,让小人物、小公司也能有大作为。
2、感谢Google Search让搜索信息变得如此便利。
3、感谢Docker公司及Docker软件的贡献者们,催生了一个巨大的行业也改善了众多开发/运维人员的生活。
4、感谢Rancher这个优秀的开源项目,提供了如Docker般的容器运维UX。
5、感谢GitHub让软件协作和代码共享如此便利和普及。
6、感谢mermaid插件的作者们,可以方便地用markdown定义编辑好看的流程图。
转载于:https://my.oschina.net/u/3330830/blog/1803012
AI独角兽商汤科技的内部服务容器化历程 1相关推荐
- AI独角兽商汤科技的内部服务容器化历程
本文由阿尔曼,商汤科技运维工程师于4月26日晚在Rancher微信群所做的技术分享整理而成.商汤科技是专注于计算机视觉领域的AI公司.本次分享结合了容器平台团队帮助公司业务/内部服务容器化历程,介绍商 ...
- AI龙头商汤科技跌进元宇宙的运行轨迹
撰文|DcMdia发起人宋清华 AI龙头商汤科技跌进元宇宙之后并没有什么动静.最近引起市场一点点波澜的是几天前的一场"徐悲鸿数字文创"营销,商汤科技通过AI算法模拟马匹瞬间动势并以 ...
- 智引万物论剑AI,商汤科技欲打造颠覆式创新引擎
9月18日,由2018世界人工智能大会(WAIC)战略合作伙伴商汤科技SenseTime承办的"智引万物"人工智能平台主题论坛在上海举行.科技部创新发展司副司长余健及上海市经济和信 ...
- 专访商汤科技联合创始人林达华丨一名AI人才,需要多少栽培?
原创:谭婧 林达华,现任MMLab掌门.MMLab是香港中文大学多媒体实验室,也是港中文-商汤联合实验室.掌门的大部分时间花在全球多个实验室里,所以北京的记者想面对面采访,未必是件容易的事. 最终,我 ...
- 独家|AI独角兽的终极猜想:旷视科技会跟商汤科技合并吗?阿里爸爸请回答
作者|震霆 出品|遇见人工智能 公众号|GOwithAI 是时候抛出这个话题了吧! 昨天晚上旷视科技官方微信发布消息,宣布旷视科技Face++全资收购艾瑞思机器人 ...
- 商汤科技43篇论文横扫2017全球顶级视觉学术会议 实习生摘得五项世界冠军
华人学者7月在夏威夷CVPR 掀起的中国风尚未完全褪去,近日又在水城威尼斯ICCV 引爆中国学术研究风暴.中国最大新锐AI企业商汤科技与香港中大-商汤科技联合实验室,继以23篇论文横扫CVPR后,又以 ...
- 商汤科技积极复工,将大力投入数字哨兵的产能和部署
总部位于上海的AI企业商汤科技开始有序推进复工.首批商汤复工人员将涵盖智慧城市.智算中心.智慧诊疗.智能汽车.产研创新.运营管理.IT.行政以及人力资源等相关岗位成员,在已有抗疫项目及技术能力基础上, ...
- AI一分钟 | 马斯克:我不是中本聪,我自己的比特币都丢了;商汤科技再获阿里巴巴15亿元投资,内部消息称C轮还有更大巨头入股
一分钟AI 马斯克:我不是中本聪 我自己的比特币都弄丢了 传苹果租试验场测试自动驾驶汽车,并招募技术人员,看似低调但野心不小 商汤科技再获阿里巴巴15亿元投资,刷新AI领域单笔融资金额最高纪录 麒麟9 ...
- 北大AI公开课2019 | 商汤科技沈徽:AI创新与落地
3月13日,备受瞩目的北大AI公开课第四讲如期开讲,商汤科技集团副总裁.商业与数据洞察事业群总裁.工程院院长沈徽带来了<AI创新与落地>的分享,结合商汤科技在技术创新以及产业落地上的经验和 ...
最新文章
- php 伪协议 lfi,php://伪协议(I/O)总能给你惊喜——Bugku CTF-welcome to bugkuctf
- 新版本,ggplot2 v3.3.0 新特性来袭
- 2021年春季学期-信号与系统-第六次作业参考答案-第七小题
- Hadoop学习之Hadoop集群的定制配置(一)
- Cortex - M3 中断和异常的区别
- python教程从入门到实践第八章_python:从入门到实践--第八章:函数
- mysql常用的备份命令有哪些_MySQL常用备份还原命令
- windows计算机考试题,全国计算机等级考试一级Windows试题及解答.pdf
- data2vec!统一模态的新里程碑
- python自带sqlite_python内置的sqlite3模块,使用其内置数据库
- ExtAspNet应用技巧(七) - ViewState优化
- 使用IntelliJ IDEA和Maven构建Java web项目并打包部署
- Flash Programer 给CC2530下载Hex文件 error解决办法 汇总
- 以下是一段歌词,请从这段歌词中统计出朋友出现的次数。 这些年一个人,风也过,雨也走,有过泪,有过错, 还记得坚持甚么,真爱过才会懂,会寂寞会回首,终有梦终有你在心中。 朋友一生一起走,那些日子不再
- 孤独星球android app,《孤独星球》终于出了全套免费的旅行指南APP!
- 挑选电脑免费加密软件特别注意哪些?
- 3DSMAX渲染器哪个好以及建模方法大盘点?你学会了吗
- 8.6 空间曲面及方程
- 字符集、ASCII、Unicode
- NoSQL之 Redis配置与优化