如何免费创建云端爬虫集群
在线体验
scrapydweb.herokuapp.com
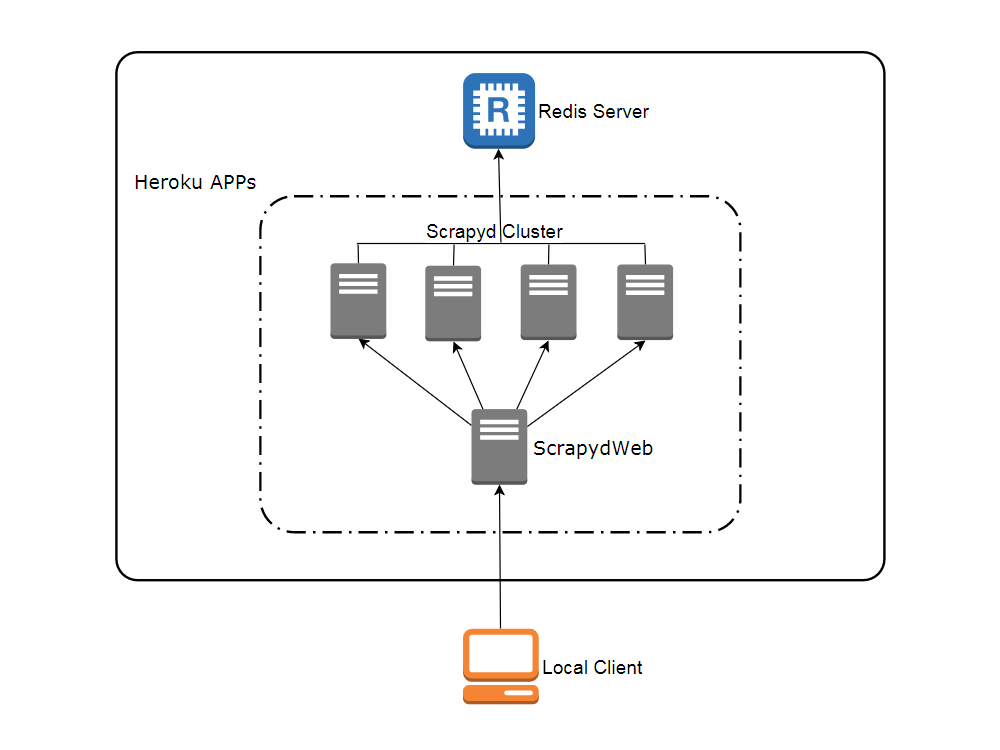
网络拓扑图
注册帐号
- Heroku
访问 heroku.com 注册免费账号(注册页面需要调用 google recaptcha 人机验证,登录页面也需要科学地进行上网,访问 app 运行页面则没有该问题),免费账号最多可以创建和运行5个 app。
- Redis Labs(可选)
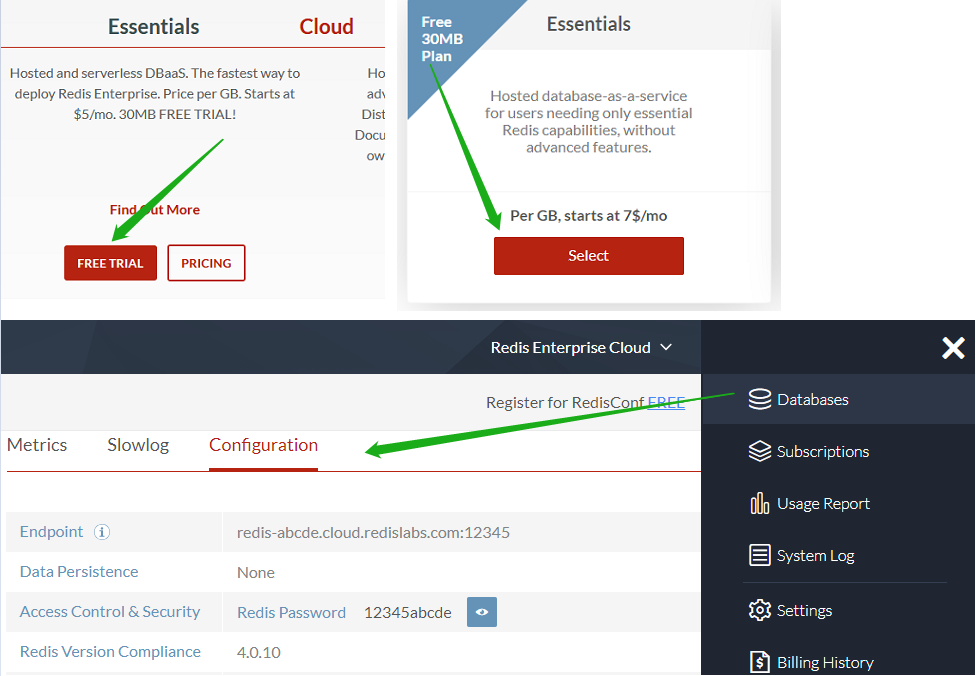
访问 redislabs.com 注册免费账号,提供30MB 存储空间,用于下文通过 scrapy-redis 实现分布式爬虫。
通过浏览器部署 Heroku app
- 访问 my8100/scrapyd-cluster-on-heroku-scrapyd-app 一键部署 Scrapyd app。(注意更新页面表单中 Redis 服务器的主机,端口和密码)
- 重复第1步完成4个 Scrapyd app 的部署,假设应用名称为
svr-1,svr-2,svr-3和svr-4 - 访问 my8100/scrapyd-cluster-on-heroku-scrapydweb-app 一键部署 ScrapydWeb app,取名
myscrapydweb - (可选)点击 dashboard.heroku.com/apps/myscrapydweb/settings 页面中的 Reveal Config Vars 按钮相应添加更多 Scrapyd server,例如 KEY 为
SCRAPYD_SERVER_2, VALUE 为svr-2.herokuapp.com:80#group2 - 访问 myscrapydweb.herokuapp.com
- 跳转 部署和运行分布式爬虫 章节继续阅读。
自定义部署
安装工具
- Git
- Heroku CLI
- Python client for Redis:运行
pip install redis命令即可。
下载配置文件
新开一个命令行提示符:
git clone https://github.com/my8100/scrapyd-cluster-on-heroku
cd scrapyd-cluster-on-heroku登录 Heroku
heroku login
# outputs:
# heroku: Press any key to open up the browser to login or q to exit:
# Opening browser to https://cli-auth.heroku.com/auth/browser/12345-abcde
# Logging in... done
# Logged in as username@gmail.com创建 Scrapyd 集群
新建 Git 仓库
cd scrapyd git init # explore and update the files if needed git status git add . git commit -a -m "first commit" git status部署 Scrapyd app
heroku apps:create svr-1 heroku git:remote -a svr-1 git remote -v git push heroku master heroku logs --tail # Press ctrl+c to stop logs outputting # Visit https://svr-1.herokuapp.com添加环境变量
- 设置时区
# python -c "import tzlocal; print(tzlocal.get_localzone())" heroku config:set TZ=Asia/Shanghai # heroku config:get TZ - 添加 Redis 账号(可选,详见 scrapy_redis_demo_project.zip 中的 settings.py)
heroku config:set REDIS_HOST=your-redis-host heroku config:set REDIS_PORT=your-redis-port heroku config:set REDIS_PASSWORD=your-redis-password
- 设置时区
- 重复上述第2步和第3步完成余下三个 Scrapyd app 的部署和配置:
svr-2,svr-3和svr-4
创建 ScrapydWeb app
新建 Git 仓库
cd .. cd scrapydweb git init # explore and update the files if needed git status git add . git commit -a -m "first commit" git status部署 ScrapydWeb app
heroku apps:create myscrapydweb heroku git:remote -a myscrapydweb git remote -v git push heroku master添加环境变量
- 设置时区
heroku config:set TZ=Asia/Shanghai - 添加 Scrapyd server(详见 scrapydweb 目录下的 scrapydweb_settings_v8.py)
heroku config:set SCRAPYD_SERVER_1=svr-1.herokuapp.com:80 heroku config:set SCRAPYD_SERVER_2=svr-2.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_3=svr-3.herokuapp.com:80#group1 heroku config:set SCRAPYD_SERVER_4=svr-4.herokuapp.com:80#group2
- 设置时区
- 访问 myscrapydweb.herokuapp.com
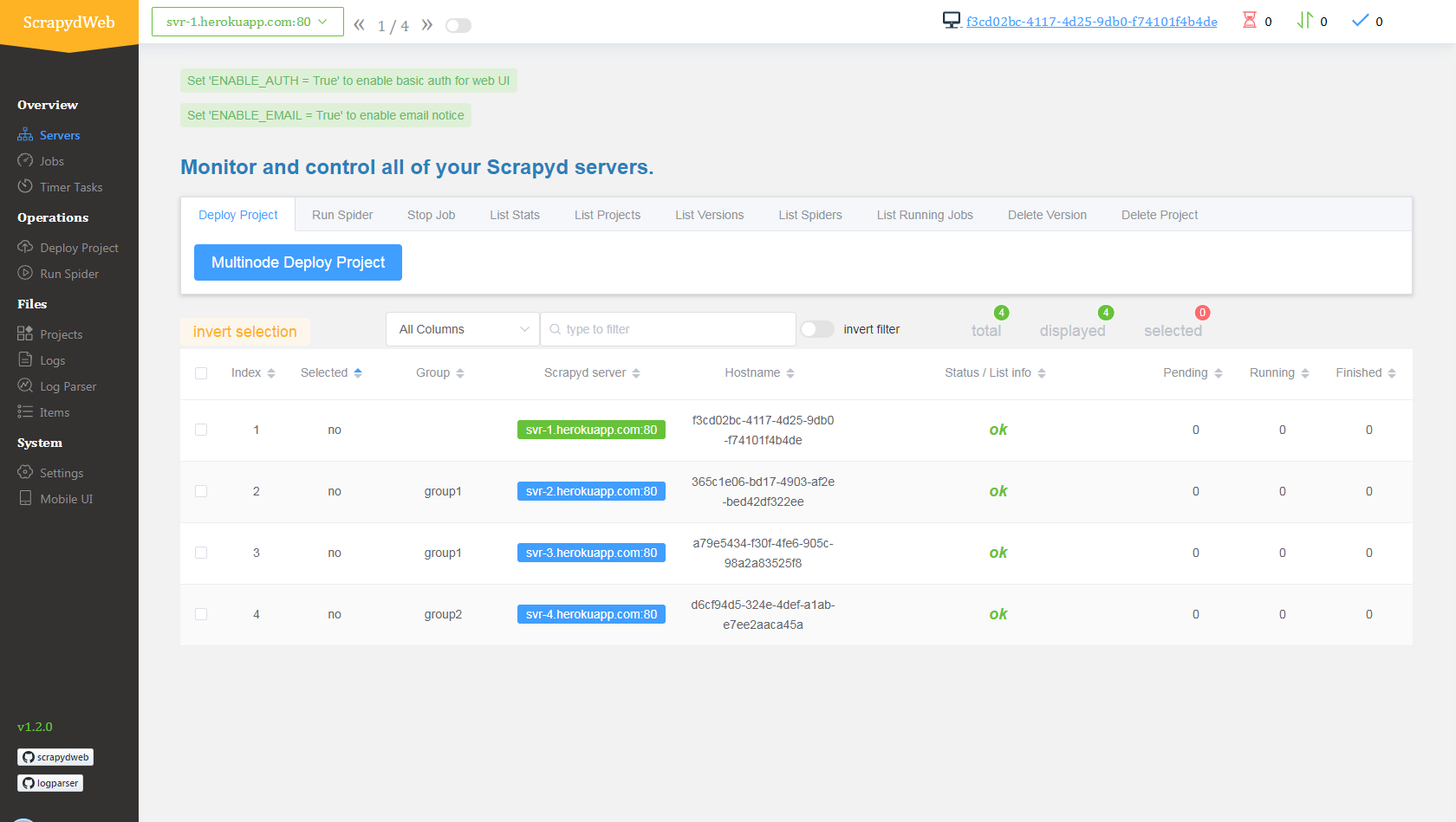
部署和运行分布式爬虫
- 上传 demo 项目,即 scrapyd-cluster-on-heroku 目录下的压缩文档 scrapy_redis_demo_project.zip
- 将种子请求推入
mycrawler:start_urls触发爬虫并查看结果
In [1]: import redis # pip install redisIn [2]: r = redis.Redis(host='your-redis-host', port=your-redis-port, password='your-redis-password')In [3]: r.delete('mycrawler_redis:requests', 'mycrawler_redis:dupefilter', 'mycrawler_redis:items')
Out[3]: 0In [4]: r.lpush('mycrawler:start_urls', 'http://books.toscrape.com', 'http://quotes.toscrape.com')
Out[4]: 2# wait for a minute
In [5]: r.lrange('mycrawler_redis:items', 0, 1)
Out[5]:
[b'{"url": "http://quotes.toscrape.com/", "title": "Quotes to Scrape", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}',b'{"url": "http://books.toscrape.com/index.html", "title": "All products | Books to Scrape - Sandbox", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}']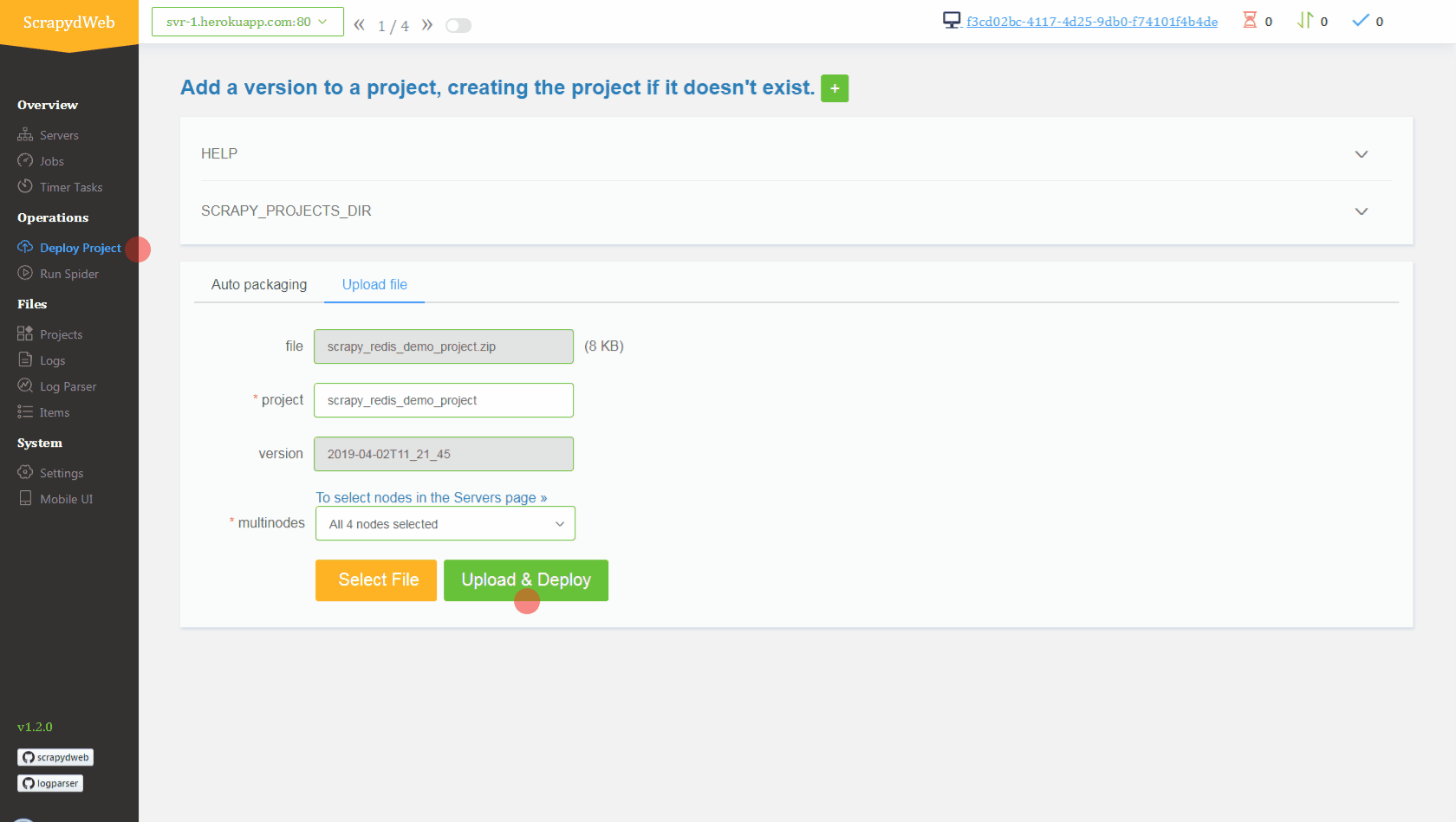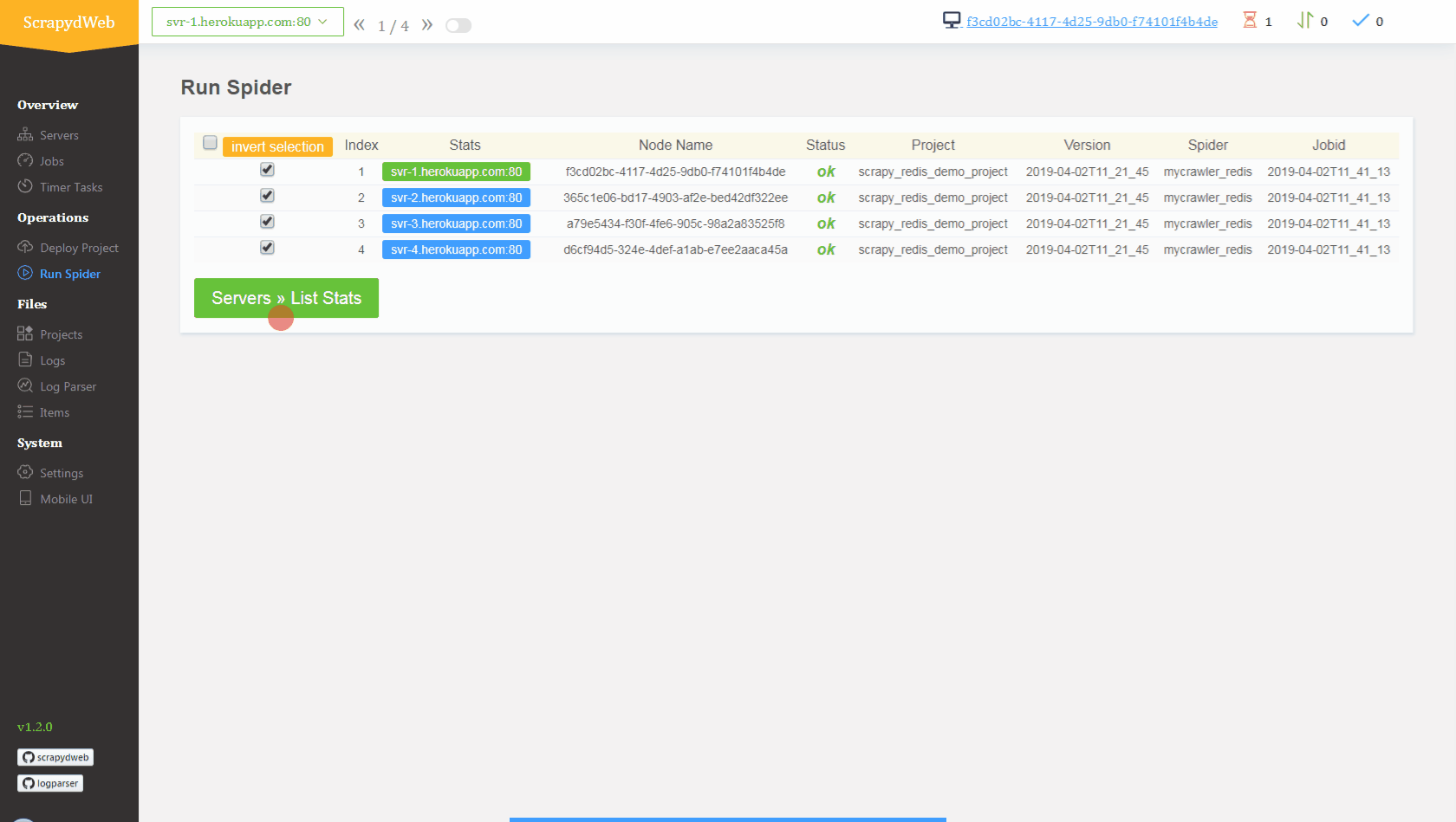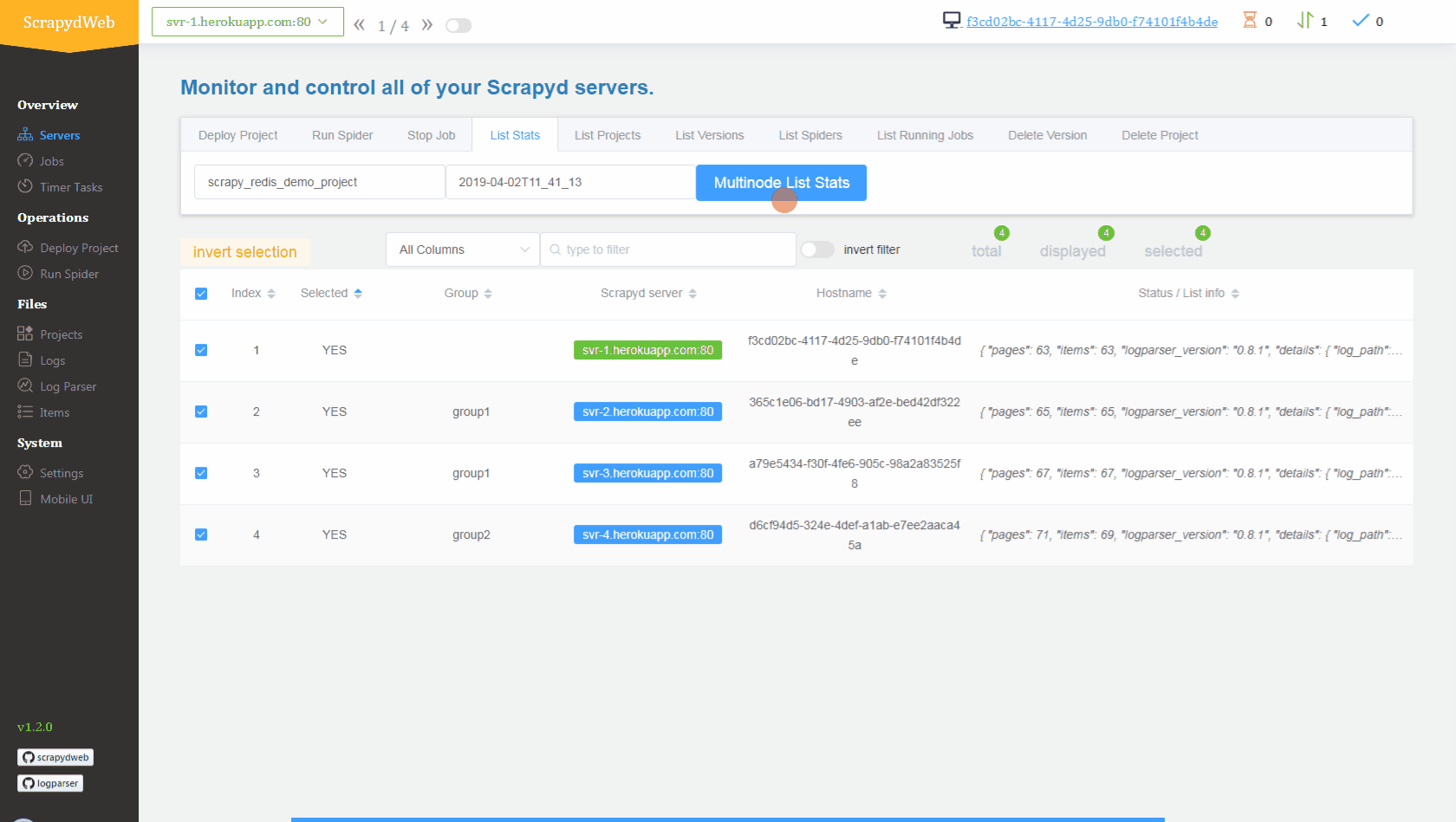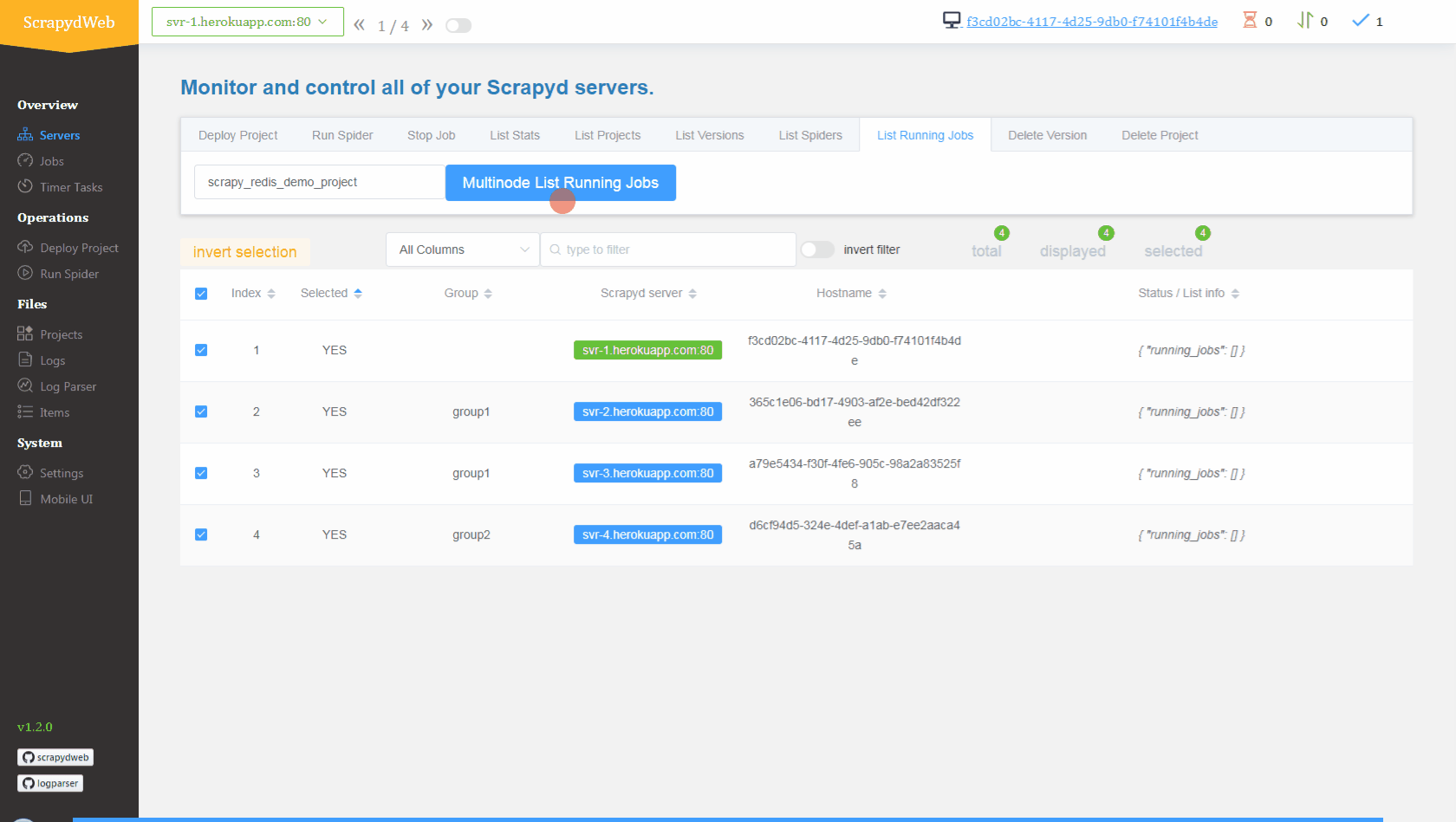
总结
- 优点
- 免费
- 可以爬 Google 等外网
- 可扩展(借助于 ScrapydWeb)
- 缺点
- 注册和登录需要科学地进行上网
- Heroku app 每天至少自动重启一次并且重置所有文件,因此需要外接数据库保存数据,详见 devcenter.heroku.com
GitHub 开源
my8100/scrapyd-cluster-on-heroku
转载于:https://blog.51cto.com/14090467/2374916
如何免费创建云端爬虫集群相关推荐
- 使用Docker Swarm搭建分布式爬虫集群
转载自 使用Docker Swarm搭建分布式爬虫集群 在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况.此时你是怎么操作的呢?逐一SSH登录每个服务器,使用git拉下代码,然后运 ...
- Redis创建高可用集群教程【Windows环境】
模仿的过程中,加入自己的思考和理解,也会有进步和收获. 在这个互联网时代,在高并发和高流量可能随时爆发的情况下,单机版的系统或者单机版的应用已经无法生存,越来越多的应用开始支持集群,支持分布式部署了. ...
- SpringCloud创建Eureka模块集群
1.说明 本文详细介绍Spring Cloud创建Eureka模块集群的方法, 基于已经创建好的Spring Cloud Eureka Server模块, 请参考SpringCloud创建Eureka ...
- 实战weblogic集群之创建节点和集群
一.启动weblogic,访问控制台 weblogic的domain创建完成后,接下来就可以启动它,步骤如下: $ cd /app/sinova/domains/base_domain/bin $ . ...
- api k8s restful 创建pods_Kind:一个容器创建K8S开发集群
什么是 Kind kind:是一种使用Docker容器节点运行本地Kubernetes集群的工具.该类型主要用于测试Kubernetes,但可用于本地开发或CI. 注意:kind仍在开发中 部署 Ma ...
- 基于云服务创建弹性托管集群服务
弹性托管集群服务 使用JMR产品,可在几分钟内创建并启动集群,弹性灵活,可根据业务规模与工作负载等需求实现低成本集群组件最优组合,动态扩容缩容,更专注于业务分析. 使用京东云的JMR,对于其他云平台可 ...
- kubernets(四)创建高可用集群
Kubernetes(一)认识 kubernetes Kubernets(二)部署非高可用Kubernetes集群的环境准备 Kubernets(三)部署非高可用Kubernetes集群-通过阿里云源 ...
- 2021最新版-AWS亚马逊云RDS创建Aurora MySQL集群
AWS亚马逊云RDS创建Aurora MySQL集群 文章目录 AWS亚马逊云RDS创建Aurora MySQL集群 1.进入AWS-RDS控制台创建数据库 2.选择你要创建的数据库 3.Amazon ...
- 如何创建 Azure AKS 集群?
Kubernetes 已经改变了微服务的世界,Azure 通过其 Azure Kubernetes 服务使 Kubernetes 编排变得轻而易举,在本分步教程中,我将向您展示如何在 Azure 上创 ...
最新文章
- arXiv论文如何一键链接解读视频,这个浏览器扩展帮你实现
- MySQL在登陆时出现ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)错误...
- Apache Camel:基于企业集成模式(EIP)的开源集成框架
- 微信终端跨平台组件 Mars 系列(三)连接超时与IPPort排序
- opengl 日地月运动模型_MaskFusion: 多运动目标实时识别、跟踪和重建
- WebBenchmark动态测试Webapi
- 【LeetCode笔记】剑指Offer 41. 数据流中的中位数(Java、堆、优先队列、知识点)
- c# url传参不能包含html标签,c#解析包含HTML特殊字符的字符串XElement
- Redis(三)源source编译
- s5p6818开发板uboot网络开通
- Nexus3 功能介绍
- Thymeleaf 生成静态化模板
- Python turtle库之QQ呲牙表情的绘制
- spring基础内容
- 【JAVA基础】java基础之-泛型详解
- 双臂冗余机器人solidworks转URDF
- javac java编译-g
- Default encoder for format image2 (codec png) is probably disabled. Please choose an encoder manuall
- 七夕总结:2018新型婚恋交友 App 激增!18禁,年轻人有点敢玩
- 6 Processes 下