ODPS到ODPS数据迁移指南
1. 工具选择与方案确定
目前,有两种方式可用于专有云环境下的从MaxCompute到MaxCompute整体数据迁移。
(1)使用DataX工具进行迁移,迁移所需的作业配置文件及运行脚本,可用DataX批量配置工具来生成;
(2)通过大数据开发套件(DataIDE)- 数据开发进行迁移,这种方式可选择界面向导模式逐步配置,操作简单容易上手;
2. 具体实施
2.1 使用DataX工具
这种场景需要先从源MaxCompute中导出元数据DDL,在目标MaxCompute中初始化表,然后借助DataX工具完成数据迁移,步骤如下:
2.1.1 DataX工具简介
· Apache Maven 3.x (Compile DataX)
2.1.2 工具下载及环境部署
因为专有域的ODPS处于专有域经典网络中,即IP为阿里云的私有IP,与专有云的网络不通,所以需要在专有域的ECS部署datax。
下载DataX工具包,下载后解压至本地某个目录,修改权限为755,进入bin目录,即可运行样例同步作业:
$ sudo chmod -R 755 {YOUR_DATAX_HOME}
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py ../job/job.json
(2)安装配置ODPS客户端
客户端下载解压后,其配置文件位于config/odps_config.ini,配置项如下:
project_name=
access_id=<accessid>
access_key=<accesskey>
end_point=http://service.odps.aliyun.com/api
2.1.3 表结构迁移
本部分操作,可通过调用ODPS的SQL来完成。具体可编写程序,调用ODPS SDK或ODPS cmd工具来进⾏。
对预迁移的表,在源ODPS中获取表结构,根据表结构,在目标ODPS中批量运行组装好的建表语句,即可完成。
2.1.3.1Â Â Â Â Â 要迁移的表名梳理
1.根据1.2中调研结果,梳理出表名列表;
2.此步骤,也可使用show tables语句获取表名,然后将临时表等不需要迁移的表名去除;
2.1.3.2Â Â Â Â Â 生成DDL建表(分区)语句
此步骤操作,在ODPS源端进行,可使用ODPS CMD工具。其配置文件位于config/odps_config.ini,配置项如下:
project_name=
access_id=<accessid>
access_key=<accesskey>
end_point=http://service.odps.aliyun.com/api
*这里注意,专有云环境下的end_point需要联系专有云管理人员获取。
在专有云环境下,可以在Bash环境中,执行如下示例语句,批量导出建表语句。请根据实际情况改写shell语句,例如读取表名列表文件等。这里的odps_config.ini.src是源端ODPS的配置文件。
for table in tab1 tab2 tab3
do
odpscmd --config=odps_config.ini.src -e "export table $table "|awk -F ':' '{print $2}' >>tab.ddl
done
2.1.3.1Â Â Â Â Â 建立对应表(分区)
在目标端的DataIDE界面依次执行建表语句,生成迁移所需要的表。
2.1.4 数据迁移
2.1.4.1Â 作业配置示例
(1)创建作业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER},并根据json样例填空完成配置即可。
以odps2odps.json样例:python datax.py -r odpsreader -w odpswriter,(填写相关参数,odpsServer/ tunnelServer要改成源/目标ODPS配置):
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessId": "${srcAccessId}",
"accessKey": "${srcAccessKey}",
"project": "${srcProject}",
"table": "${srcTable}",
"partition": ["pt=${srcPartition}"],
"column": [
"*"
],
"odpsServer": " http://service.odps.aliyun.com/api ",
"tunnelServer": "http://tunnel.odps.aliyun-inc.com"
}
},
"writer": {
"name": "odpswriter",
"parameter": {
"accessId": "${dstAccessId}",
"accessKey": "${dstAccessKey}",
"project": "${dstProject}",
"table": "${dstTable}",
"partition": "pt",
"column": [
"*"
],
"odpsServer": " http://service.odps.aliyun.com/api ",
"tunnelServer": "http://tunnel.odps.aliyun-inc.com"
}
}
}
]
}
}
(2)运行DataX任务
$ cd {YOUR_DATAX_DIR_BIN}
$ python datax.py ./odps2odps.json
同步结束,显示日志如下:
...
2017-05-10 11:20:09.871 [job-0] INFO JobContainer -
任务启动时刻 : 2017-05-10 11:19:35
任务结束时刻 : 2017-05-10 11:20:09
任务总计耗时 : 34s
任务平均流量 : 571.50KB/s
记录写入速度 : 18287rec/s
读出记录总数 : 548639
读写失败总数 : 0
运行后,可在终端查看运行信息。建议真正跑任务时,可使用DataX批量工具的方式运行。具体如下:
该工具可以自动获取源表和目标表的属性及分区信息,自动生成源表所有分区的json文件,并生成批量串行脚本和批量检测脚本。方便大家的数据迁移。
注:具体脚本详见附件datax_tools内。
(2)操作过程
l mkdir ./json ./log ./temp
l 在config.ini中配置好源ODPS和目标ODPS相关的accessID、accessKEY、project、ODPS server等相关信息;
l 在config.ini中配置好datax.py与odmscmd的路径;
l 在tables.ini中配置好需要迁移的表名;
l 运行python datax_tools.py,生成运行脚本;
l 运行run_datax.sh,批量顺序执行迁移任务;
l 运行check_datax.sh,进行源表和目标表的条数校验;
(3)详细说明
ÃÂ 工具配置
l 源ODPS配置与目标ODPS配置
在配置文件config.ini的reader_common和writer_common区域,reader表示源ODPS,writer表示目标ODPS。主要配置accessID、accessKey和project名。这些均可从base的用户信息获取。
l datax的相关配置
在配置文件config.ini的datax_settings区域。
datax_speed: 控制datax实际运行时的速度上限;
reader_project_auth: datax的验证机制,可为空。如果验证失败,可以输入一个源ODPS ID具备owner权限的项目名;
reader_odps_server: 源ODPS的api url,可从cmdb查询,或找云管理员获取;
writer_odps_server: 目标ODPS的api url,可从cmdb查询,或找云管理员获取;
writer_odps_tunnel: 目标ODPS的tunnel,可从cmdb查询,或找云管理员获取;
writer_truncate: 覆盖式导入开关;
writer_accoutType: 一般默认为aliyun;
l 工具的相关配置
本批量工具的相关配置,需要注意datax.py和odpscmd的路径,其余一般不用修改。
ÃÂ 源表和目标表添加在配置文件tables.ini中
l 若源表和目标表的表名相同,则直接输入源表的表名即可,每行一个表名;
l 若源表和目标表的表名不同,则每行输入一个源表名和一个目标表名,两者之间用空格分隔;
ÃÂ 生成脚本直接运行python datax_tools.py即可
l 运行过程中会打印运行的odpscmd语句及相关运行信息,该语句可能会有延迟或失败;
l 运行的所有过程会记录在./log/info.log中;
l 脚本运行完毕会打印所有获取信息失败的表名;
l 所有获取信息成功的表,会生成相关的json文件,存储在./json中;
l 生成run_datax.sh脚本,用于实际进行datax任务;
l 生成check_datax.sh脚本,用于运行完任务后进行校验;
ÃÂ 批量运行datax任务运行run_datax.sh的脚本,批量顺序执行datax任务
l 相关日志存储在./log/表名.log中;
l 若想并行运行程序,可修改run_datax.sh中的语句,改为后台运行;
l 批量检测;
l 当data_x的所有任务完成后,运行check_datax.sh的脚本,会生成所有源表和目标表所有的条数;
l 为减少对ODPS的请求次数,脚本会一次请求该ODPS(源表,目标表)所有迁移表的条数;
l 结果会存储在./log/check_src.log, ./log/check_dst.log两个日志中;
l 可用vimdiff来比较两个日志,查看具体哪个表条数不同。
2.2 通过Base中的CDP同步数据
2.2.1 CDP简介
CDP是阿里集团对外提供的稳定高效、弹性伸缩的数据同步平台,为阿里云大数据计算引擎(包括 MaxCompute、AnalyticDB 等)提供离线(批量)的数据进出通道 。
2.2.2 数据源配置
在目的云账号的MaxCompute项目空间的数据集成中添加数据源,该数据源为另一个云账号的MaxCompute项目空间。
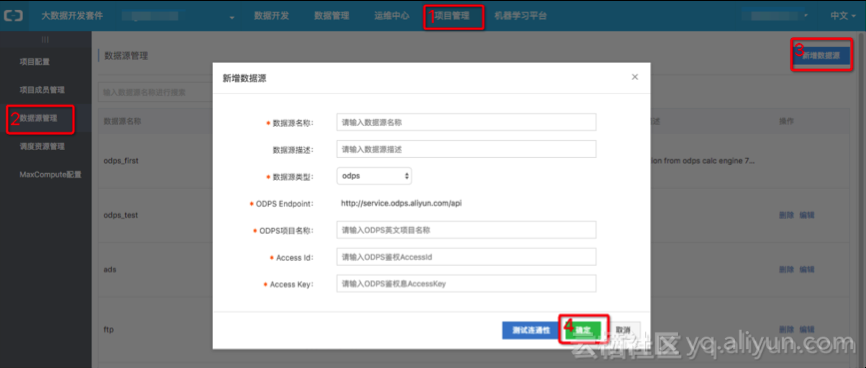
在新增数据源弹出框中填写相关配置项,并测试连通性。若测试连通性成功,则点击保存按钮完成配置信息保存。
2.2.3 作业配置示例

同步任务节点包括“选择来源”、“选择目标”、“字段映射”、“通道控制”四大配置项 。
选择数据源(数据源为“新建数据源”中已经建立好的数据源)后并且选择数据表。
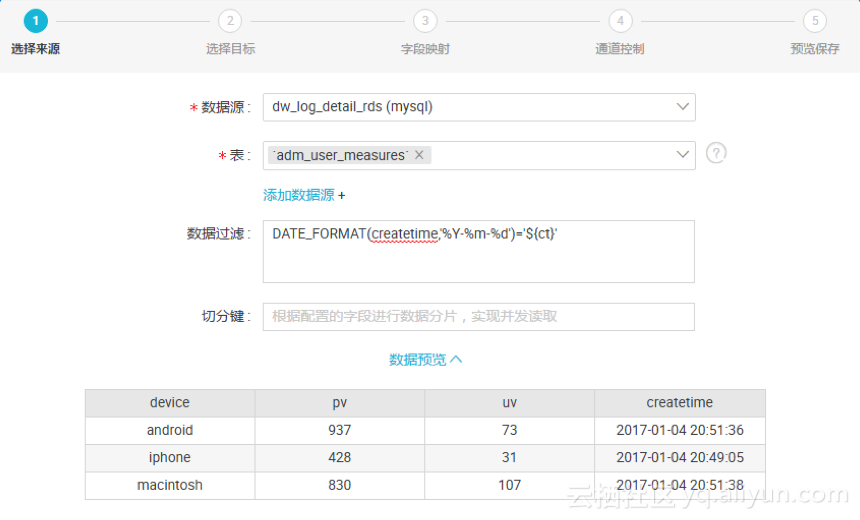
点击“快速建表”可将源头表的建表语句转化为符合 MaxCompute SQL 语法规范的 DDL 语句新建目标表 。选择后点击“下一步”。
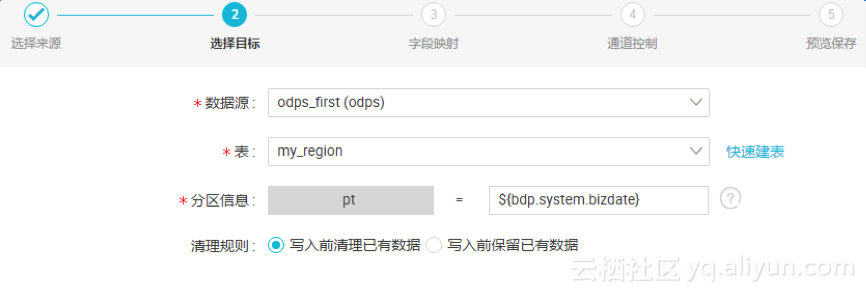
l 分区信息:分区是为了便于查询部分数据引入的特殊列,指定分区便于快速定位到需要的数据。支持常量和变量 。
1)写入前清理已有数据:导数据之前,清空表或者分区的所有数据,相当于 insert overwrite 。
2)写入前保留已有数据:导数据之前不清理任何数据,每次运行数据都是追加进去的,相当于 insert into 。
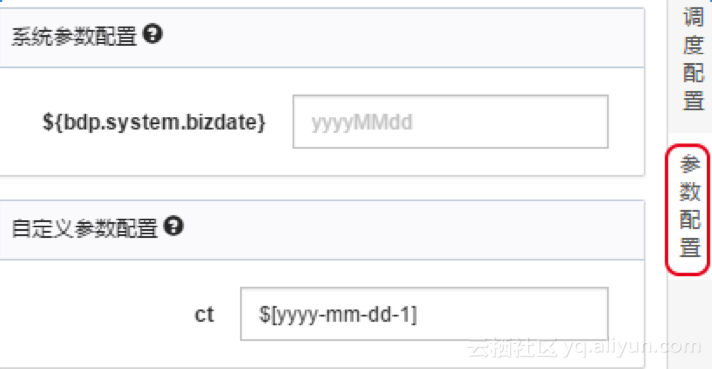
需对字段映射关系进行配置,左侧“源头表字段”和右侧“目标表字段”为一一对应的关系。
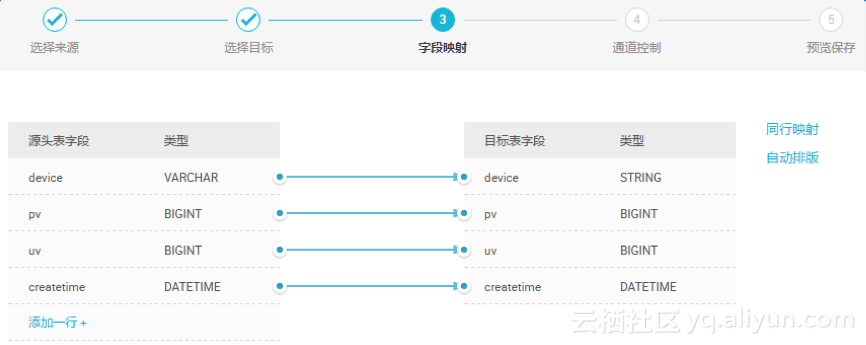
增加/删除,点击”添加一行”可单个增加字段。鼠标 Hover 上每一行,点击删除图标可以删除当前字段。
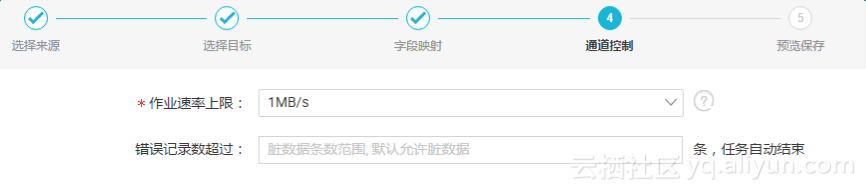
l 当错误记录数(即脏数据数量)超过所配置的个数时,该数据同步任务结束 。
完成以上配置后,点击“下一步”即可预览,如若无误,点击“保存”,如下图所示:
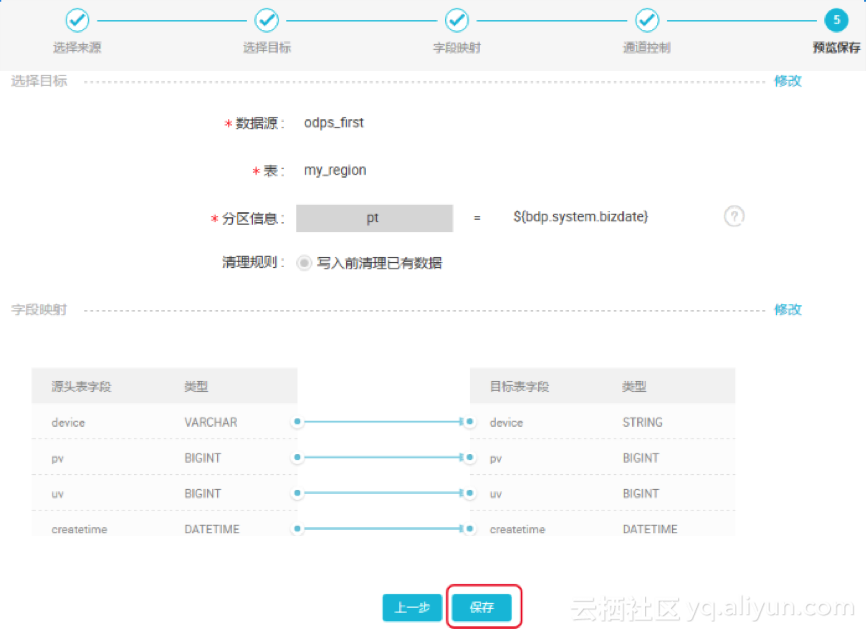
备注:如果您想切换为脚本模式,点击工具栏中的“转换脚本”即可 。
2.2.4 配置批量数据同步任务
通过创建工作流的方式,将多个数据同步任务放入同一工作流执行,即可实现数据表的批量迁移。具体操作步骤如下:
步骤1:以开发者身份进入阿里云数加平台>大数据开发套件>管理控制台,点击对应项目操作栏中的进入工作区。
步骤3:目录文件夹上点击右键新建任务>工作流任务,或右边工作区点击新建任务>工作流任务。
步骤1:在上一步创建的工作流设计器的节点组件中向画布拖拽一个虚节点组件,作为开始节点;
步骤2:在工作流设计器的节点组件中向画布拖拽一个数据同步节点组件,进行创建;
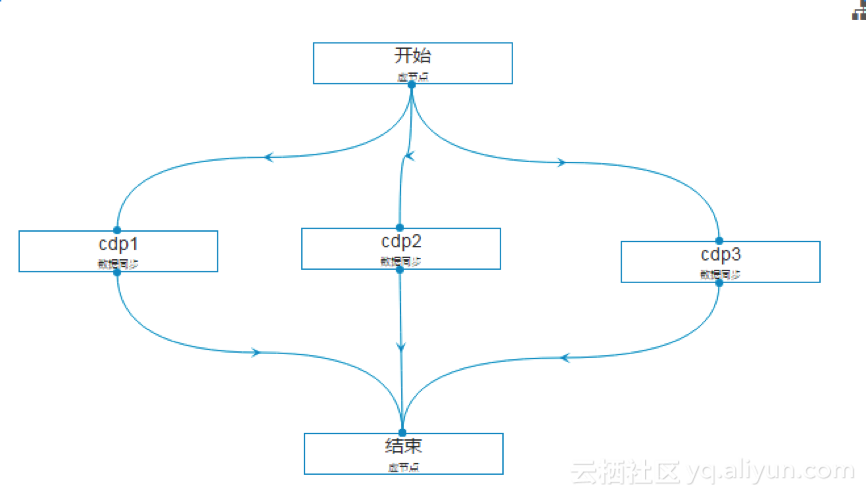
步骤3:双击该节点或右键查看节点内容进入任务配置界面。具体操作同2.2.3作业配置示例;
步骤5:点击“保存”、“提交”,然后就可以进行测试运行,可以通过执行日志监控执行成功与否。
2.3优势与限制
2.3.1优势与特点
ï¼1ï¼Â DataX通过配置文件做源和目标的映射非常灵活;
ï¼2ï¼Â 可以通过DataX批量配置工具生成批量迁移所需要的脚本和作业配置文件。
ÃÂ 通过大数据开发套件(DataIDE)-数据开发做数据同步
ï¼1ï¼Â 这种方式可以通过选择界面向导逐步配置,操作简单容易上手,学习成本低;
ï¼2ï¼Â 对于目标端不存在的表可以使用向导模式提供的“快速建表”功能新建目标表;
ï¼3ï¼Â 脚本模式可以提供更丰富灵活的能力,做精细化的配置管理,适合高级用户,学习成本较高。
2.3.2 约束与限制
(1)新建专有云环境中不支持odpscmd客户端访问,无法进行批量建表,需通过大数据开发套件手动创建;
ODPS到ODPS数据迁移指南相关推荐
- ODPS到ADS数据迁移指南
数据同步节点任务是阿里云大数据平台对外提供的稳定高效.弹性伸缩的数据同步云服务.ODPS到ADS数据迁移采用CDP的方式同步数据. 1.    创建源和目标库表结构 初次在同步数据前需要在源 ...
- iOS Core Data 数据迁移 指南 144 作者 一缕殇流化隐半边冰霜 关注 2016.05.09 00:35* 字数 4718 阅读 2931评论 17喜欢 327 前言 Core
iOS Core Data 数据迁移 指南 作者 一缕殇流化隐半边冰霜 关注 2016.05.09 00:35* 字数 4718 阅读 2931评论 17喜欢 327 前言 Core Data是iOS ...
- ODPS数据迁移指南
1. 背景调研 1.1 ODPS源与目的集群 调研项 内容 ODPS源集群版本 ODPS目的集群版本 ODPS源与目的是否在一个集群/可使用相同账号 ODPS源集群AccessKeyId ODPS源集 ...
- sql oltp_内存中的OLTP系列– SQL Server 2014上的数据迁移指南过程
sql oltp In this article we will review migration from disk-based tables to in-memory optimized tabl ...
- Gogs生产环境搭建和数据迁移指南
说明 说明下gogs的搭建和迁移,搭建过程比较简单,资料也很多,不作为本文的重点.重点是说明一下如何迁移gogs,可以解决一下几个业务场景的迁移工作 相同系统间的迁移 linux-liunx wind ...
- DataX使用指南——ODPS to ODPS
1. DataX是什么 DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlServer.Postgre.HDFS.Hive.ADS.HBase. ...
- 阿里ODPS降低大数据应用门槛
阿里云计算的ODPS从内部使用的工具变成了面向社会开放的大数据平台,开创了国内大数据公共服务的先河,降低了大数据在资金.人才和应用方面的门槛. 小型企业只要花费几百元就能进行海量数据分析,这是真的吗? ...
- java 迁移数据_Java 9迁移指南:七个最常见的挑战
java 迁移数据 我敢肯定,您已经听说过更新到Java 9并不是一件容易的事,甚至可能是不兼容的更新,而且对于大型代码库而言,迁移毫无意义. 这样做之后,我迁移了一个相当大的旧代码库,我可以告诉你, ...
- DataX在数据迁移中的应用
简介:DataX在数据迁移中的应用 1. DataX定义 首先简单介绍下datax是什么. DataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
最新文章
- nginx0.8 + php-5.3.4 + memcached
- Python基础03 序列
- 反射就是获取该类的.class文件里面的方法,属性
- swiper轮播图插件
- Learn Python the Hard Way: 字典
- 操作系统中的一些基本概念
- openSSH离线升级(6.6->7.9),解决Linux安全漏洞(CVE-2018-15473)
- 全球首例无人车撞人致死事故判决:Uber无罪,安全员要进一步调查
- pandas 保存csv 不要序号
- c语言指针++_C和C ++中的指针
- 朋友圈营销:如何做好个人IP打造吸金朋友圈?(内附思维导图)
- 合并m3u8(ts)文件的工具
- Word文档人民币符号怎么打出来
- Android 腾讯优图开发问题总结
- android 极光推送解绑,app集成极光推送笔记(angular js)
- Linux —— wget -qO- 命令详解
- TI-RTOS之初体验(1)
- STM32cubeMX:双通道ADC(DMA)
- 无法启动此程序因为计算机中丢失vcruntime140_1.dll
- 数字图像处理第三章<一>、灰度变换