数据科学中的陷阱:定性变量的处理
定性变量,也就是表示类别的变量,比如性别、省份等。对于这类变量,不能在模型里直接使用它们,因为定性变量之间的数学计算是毫无意义的。另一方面,定性变量是一类很常见的变量,通常带着很有价值的信息。因此,这篇文章就将讨论如何正确地在模型里使用定性变量。

对于定性变量,常见的处理方法有两种:一种是将定性变量转换为多个虚拟变量,另一种对将有序的定性变量转换为定量变量。
一、虚拟变量
正如前文中讨论的,直接对定性变量数字编码,得到的变量将无法进行有意义的数学运算。那么,相应的解决方法就是使得变换之后的变量不能直接做数学运算。
为了便于理解,我们先来看一个简单的例子:使用身高和性别对体重构建线性回归模型。性别是一个二元定性变量,可能的取值为男或女。用两个新生成的变量来取代性别,记为(x1, x2)。其中,x1 = 1表示性别为男, x1 = 0表示性别不为男; x2类似,表示性别是否为女。在学术上,新生成的变量被称为虚拟变量(dummy variable)。虚拟变量是一种特殊的离散型变量,可能的值只有两个:0或1,因此也被称为0/1变量。
用y表示体重, z表示身高,于是有:

注意到 ,也就是变量和变量成线性关系。这会导致另外一个问题:多重共线性(多重共线性源自线性模型,它是指由于自变量之间存在高度相关关系而使模型参数估计不准确,我们会在后面的文章里详细讨论)这个由虚拟变量引起的多重共线性问题在学术上被称为虚拟变量陷阱(dummy variable trap)。为了规避这个问题,我们对公式(1)做如下的数学变换,得到:
,也就是变量和变量成线性关系。这会导致另外一个问题:多重共线性(多重共线性源自线性模型,它是指由于自变量之间存在高度相关关系而使模型参数估计不准确,我们会在后面的文章里详细讨论)这个由虚拟变量引起的多重共线性问题在学术上被称为虚拟变量陷阱(dummy variable trap)。为了规避这个问题,我们对公式(1)做如下的数学变换,得到:

上面的数学转换可翻译为:首先选择性别男为基准类别,生成一维虚拟变量,变量的含义与之前相同。这个变量前面的系数b - a表示性别女相对于性别男(基准类别)的体重差异。需要注意的是,针对二元定性变量,从表面上来看,直接对变量数字编码同虚拟变量效果一样。但这只是一个巧合而已,两种方法有本质的区别。
将上面的方法推广到n元定性变量(可能取值为n个的定性变量)。选择一个类别作为基准类别,并生成n - 1个虚拟变量,分别表示剩下的n - 1个类别。在搭建模型时,用这n - 1个新生成的虚拟变量代替原来的定性变量。具体过程如图1所示。
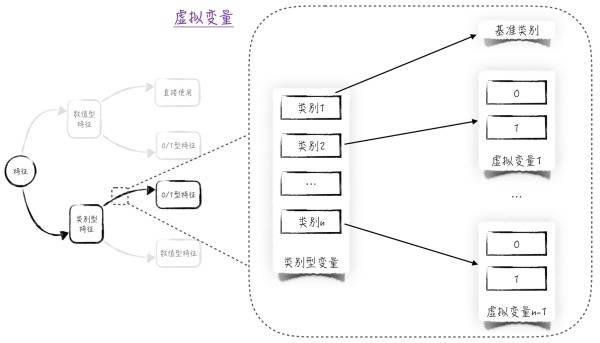
图1二、从定性变量到定量变量
前面讨论的虚拟变量的方法是比较通用的处理方法。但这种方法有一个很明显的缺点:每个虚拟变量都是0或1,无法提供更多的信息。特别是对于多个有序的定性变量,这会损失掉每个定性变量本身的顺序信息和定性变量间的关联信息。为了解决这个问题,常常根据类别的顺序,将定性变量转换为定量变量。具体的转换方法有很多,但限于篇幅,这里只讨论其中的一种:针对二元分类问题的Ridit scoring(此方法在保险业中应用很广),如图2所示。
假设有序的定性变量x有t个可能的取值,记为 。而且对于被预测值,排在后面的类别,y = 1发生的可能性越小。也就是说,对于y = 1这件事,其他变量相同时,类别1的概率最大,类别t的概率最小。用
。而且对于被预测值,排在后面的类别,y = 1发生的可能性越小。也就是说,对于y = 1这件事,其他变量相同时,类别1的概率最大,类别t的概率最小。用 分别表示各个类别所占比例,于是类别的Ridit scoring为:
分别表示各个类别所占比例,于是类别的Ridit scoring为:

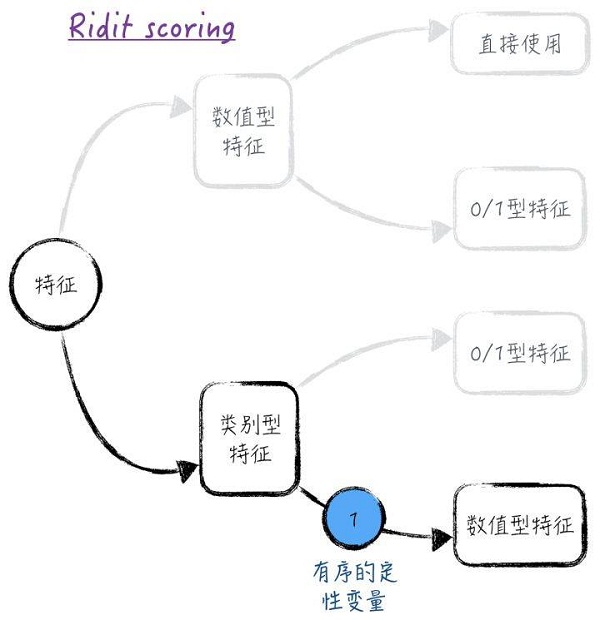
图2对于一般的定性变量,我们也可以使用所谓的WOE(weight of evidence)方法来将其转换为定量变量,这种方法在信贷风控领域十分广泛。具体来说,假设二元分类问题里有两个类别,用B和G表示(这样标记源自金融领域,B表示bad,G表示good)。同样假设,定性变量x有t个可能的取值,记为。那么对于取值i,它的WOE值为:

其中 表示x等于i时,B类别的数量,
表示x等于i时,B类别的数量, 表示B类别的总数量;
表示B类别的总数量; 和
和 表示的意思类似。
表示的意思类似。
注:这篇文章的大部分内容参考《精通数据科学:从线性回归到深度学习》。
数据科学中的陷阱:定性变量的处理相关推荐
- 数据科学中的陷阱II:定性变量的处理
在之前的文章里<数据科学中的陷阱I:变量的数学运算合理吗?>,我们讨论过定性变量,也就是表示类别的变量,比如性别.省份等.对于这类变量,不能在模型里直接使用它们,因为定性变量之间的数学计算 ...
- 独家 | 在数据科学中需要多少数学技能?(附链接)
作者:Benjamin Obi Tayo 翻译:刘思婧 校对:车前子 本文约1600字,建议阅读5分钟 本文为大家介绍了在数据科学和机器学习中所需要的基本数学技能,并且分类给出了相应的主题建议. Je ...
- 数据科学中的6个基本算法,掌握它们要学习哪些知识
晓查 发自 凹非寺 量子位 出品 | 公众号 QbitAI 如果想从事数据科学,但是又没有数学背景,那么有多少数学知识是做数据科学所必须的? 统计学是学习数据科学绕不开的一门数学基础课程,但数据科学也 ...
- 因果关系和相关关系 大数据_数据科学中的相关性与因果关系
因果关系和相关关系 大数据 Let's jump into it right away. 让我们马上进入. 相关性 (Correlation) Correlation means relationsh ...
- 数据科学中的数据可视化
数据可视化简介 (Introduction to Data Visualization) Data visualization is the process of creating interacti ...
- r怎么对两组数据统计检验_数据科学中最常用的统计检验是什么
r怎么对两组数据统计检验 Business analytics and data science is a convergence of many fields of expertise. Profe ...
- 中ridge_10种线性代数在数据科学中的强大应用(内附多种资源)
原文选自 | Analytics Vidhya 作者 | Khyati Mahendru 本文转载自 TalkingData数据学堂 ,未经允许禁止转载 本文摘要 线性代数为各种各样的数据科学算法和应 ...
- 线性代数在计算机视觉的应用,10种线性代数在数据科学中的强大应用(内附多种资源)...
本文摘要线性代数为各种各样的数据科学算法和应用提供支持 在这里,我会向您介绍通过线性代数帮助您成为更好的数据科学家的10种实际应用 我们已将这些应用程序分类到各个领域 - 基本机器学习,降维,自然语言 ...
- 数据科学中的离散型数据的处理策略
点击上方"AI公园",关注公众号,选择加"星标"或"置顶" 作者:Dipanjan (DJ) Sarkar 编译:ronghuaiyang ...
最新文章
- 世界上本没有架构,建设的需求多了便有了架构
- 第四章 .net core做一个简单的登录
- Linux基础命令---添加/删除组
- cas+shiro+spring 单点登录
- 检索数据_14_返回不重复的记录
- 如何使用 Kafka、MongoDB 和 Maxwell’s Daemon 构建 SQL 数据库的审计系统
- Intent各种flag解析。
- oracle+日誌語句,oracle维护常用sql语句
- go语言报错:main redeclared in this block
- 自然数之和(leetcode 167)
- MAC上编译OpenCV
- 微信小程序--几个常用标签
- 大数据定价方法的国内外研究综述及对比分析
- Cloud Native 演进可行性研究
- Uncaught SyntaxError The requested module ‘node_modules.vitevue.jsv=bd1817bb‘ does not provide
- 邮储银行计算机岗位笔试题,中国邮政储蓄银行各类岗位笔试经验汇总
- docker service
- 一梦江湖网页提交问题服务器错误,一梦江湖4月3日更新内容详情一览
- K_A19_002 基于STM32等单片机采集水位检测传感数据 串口与OLED0.96双显示
- kodi树莓派_树莓派如何安装最新版Kodi 18.6 及树莓派4B针对Kodi的优化
热门文章
- 带你学MySQL系列 | 困扰MySQL初学者的分组聚合查询,我终于讲明白了!
- window.localStorage.setItem总结
- 比python更快制作大数据图表展示的平台
- 来自店湾妹的七夕礼物:适合素颜涂的口红,你的女朋友值得拥有!
- 有创意的撩妹句子,句句有创意,拿去撩妹准没错!
- DB2中的NVL和NVL2函数
- C++-向量的点乘、叉乘等操作
- BFU-计算机网络全书笔记 BFU-CS 2021-2022 期末总结
- CC00019.bigdatajava——|JavaMySQL基础.V19|——|MySQL.v19|DML_删除数据|
- 群晖python脚本_群晖、Python、小米摄像头、OneDrive应用案例