教您使用java爬虫gecco抓取JD全部商品信息(一)
教您使用java爬虫gecco抓取JD全部商品信息(一)
gecco爬虫
如果对gecco还没有了解可以参看一下gecco的github首页。gecco爬虫十分的简单易用,JD全部商品信息的抓取9个类就能搞定。
JD网站的分析
要抓取JD网站的全部商品信息,我们要先分析一下网站,京东网站可以大体分为三级,首页上通过分类跳转到商品列表页,商品列表页对每个商品有详情页。那么我们通过找到所有分类就能逐个分类抓取商品信息。
入口地址
http://www.jd.com/allSort.aspx,这个地址是JD全部商品的分类列表,我们以该页面作为开始页面,抓取JD的全部商品信息
新建开始页面的HtmlBean类AllSort
@Gecco(matchUrl="http://www.jd.com/allSort.aspx", pipelines={"consolePipeline", "allSortPipeline"})
public class AllSort implements HtmlBean {private static final long serialVersionUID = 665662335318691818L;@Requestprivate HttpRequest request;//手机@HtmlField(cssPath=".category-items > div:nth-child(1) > div:nth-child(2) > div.mc > div.items > dl")private List<Category> mobile;//家用电器@HtmlField(cssPath=".category-items > div:nth-child(1) > div:nth-child(3) > div.mc > div.items > dl")private List<Category> domestic;public List<Category> getMobile() {return mobile;}public void setMobile(List<Category> mobile) {this.mobile = mobile;}public List<Category> getDomestic() {return domestic;}public void setDomestic(List<Category> domestic) {this.domestic = domestic;}public HttpRequest getRequest() {return request;}public void setRequest(HttpRequest request) {this.request = request;}
}
可以看到,这里以抓取手机和家用电器两个大类的商品信息为例,可以看到每个大类都包含若干个子分类,用List<Category>表示。gecco支持Bean的嵌套,可以很好的表达html页面结构。Category表示子分类信息内容,HrefBean是共用的链接Bean。
public class Category implements HtmlBean {private static final long serialVersionUID = 3018760488621382659L;@Text@HtmlField(cssPath="dt a")private String parentName;@HtmlField(cssPath="dd a")private List<HrefBean> categorys;public String getParentName() {return parentName;}public void setParentName(String parentName) {this.parentName = parentName;}public List<HrefBean> getCategorys() {return categorys;}public void setCategorys(List<HrefBean> categorys) {this.categorys = categorys;}}
获取页面元素cssPath的小技巧
上面两个类难点就在cssPath的获取上,这里介绍一些cssPath获取的小技巧。用Chrome浏览器打开需要抓取的网页,按F12进入发者模式。选择你要获取的元素,如图:
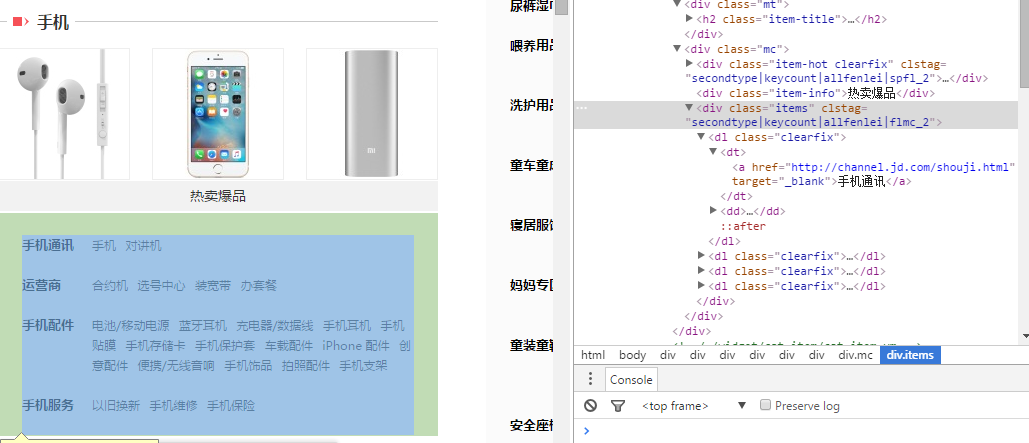 在浏览器右侧选中该元素,鼠标右键选择Copy--Copy selector,即可获得该元素的cssPath
在浏览器右侧选中该元素,鼠标右键选择Copy--Copy selector,即可获得该元素的cssPath
body > div:nth-child(5) > div.main-classify > div.list > div.category-items.clearfix > div:nth-child(1) > div:nth-child(2) > div.mc > div.items
如果你对jquery的selector有了解,另外我们只希望获得dl元素,因此即可简化为:
.category-items > div:nth-child(1) > div:nth-child(2) > div.mc > div.items > dl
编写AllSort的业务处理类
完成对AllSort的注入后,我们需要对AllSort进行业务处理,这里我们不做分类信息持久化等处理,只对分类链接进行提取,进一步抓取商品列表信息。看代码:
@PipelineName("allSortPipeline")
public class AllSortPipeline implements Pipeline<AllSort> {@Overridepublic void process(AllSort allSort) {List<Category> categorys = allSort.getMobile();for(Category category : categorys) {List<HrefBean> hrefs = category.getCategorys();for(HrefBean href : hrefs) {String url = href.getUrl()+"&delivery=1&page=1&JL=4_10_0&go=0";HttpRequest currRequest = allSort.getRequest();SchedulerContext.into(currRequest.subRequest(url));}}}}
@PipelinName定义该pipeline的名称,在AllSort的@Gecco注解里进行关联,这样,gecco在抓取完并注入Bean后就会逐个调用@Gecco定义的pipeline了。为每个子链接增加"&delivery=1&page=1&JL=4_10_0&go=0"的目的是只抓取京东自营并且有货的商品。SchedulerContext.into()方法是将待抓取的链接放入队列中等待进一步抓取。
转:https://my.oschina.net/u/2336761/blog/620158
教您使用java爬虫gecco抓取JD全部商品信息(一)相关推荐
- java爬虫 京东_教您使用java爬虫gecco抓取JD全部商品信息(一)
#教您使用java爬虫gecco抓取JD全部商品信息(一) ##gecco爬虫 如果对gecco还没有了解可以参看一下gecco的github首页.gecco爬虫十分的简单易用,JD全部商品信息的抓取 ...
- 教您使用java爬虫gecco抓取JD全部商品信息
转自:http://www.geccocrawler.com/demo-jd/ gecco爬虫 如果对gecco还没有了解可以参看一下gecco的github首页.gecco爬虫十分的简单易用,JD全 ...
- java爬虫异步取数据_教您使用java爬虫gecco抓取JD全部商品信息(三)
##详情页抓取 商品的基本信息抓取完成后,就要针对每个商品的详情页进行抓取,可以看到详情页的地址格式一般如下:http://item.jd.com/1861098.html.我们建立商品详情页的Bea ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- python简单爬虫代码-python爬虫超简单攻略,带你写入门级的爬虫,抓取上万条信息...
原标题:python爬虫超简单攻略,带你写入门级的爬虫,抓取上万条信息 最近经常有人问我,明明看着教程写个爬虫很简单,但是自己上手的时候就麻爪了...那么今天就给刚开始学习爬虫的同学,分享一下怎么一步 ...
- python爬取网店数据_Python爬虫实现抓取京东店铺信息及下载图片功能示例
本文实例讲述了Python爬虫实现抓取京东店铺信息及下载图片功能.分享给大家供大家参考,具体如下: 这个是抓取信息的 from bs4 import BeautifulSoup import requ ...
- Scrapy 爬虫实例 抓取豆瓣小组信息并保存到mongodb中
这个框架关注了很久,但是直到最近空了才仔细的看了下 这里我用的是scrapy0.24版本 先来个成品好感受这个框架带来的便捷性,等这段时间慢慢整理下思绪再把最近学到的关于此框架的知识一一更新到博客来. ...
- Python爬虫之抓取京东店铺信息及下载图片
这个是抓取信息的 from bs4 import BeautifulSoup import requestsurl = 'https://list.tmall.com/search_product.h ...
- JAVA爬虫Jsoup,抓取房价
里面的命名很烂,但能跑出来效果. 依赖: <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependenc ...
最新文章
- UITableView的cell向左滑出有删除,修改等选项
- smarty foreach函数
- BRCM5.02编译一 : 缺少工具链路
- Acwing291. 蒙德里安的梦想:状态压缩dp
- PyTorch深度学习实践03
- MySql数据库出现 1396错误
- php成品网站安装,PHPweb成品网站安装环境要求和安装方法
- 知识图谱在招聘推荐匹配的应用
- win10装系统--笔记
- input和raw_input的区别
- 单片机c语言案例教程,单片机C语言案例教程
- 百度文库文档免下载券免费下载方法
- 浅谈程序脱壳后的优化
- Shell脚本实现判断一个数是否为质数
- docker镜像编译与docker-compose部署与编排
- 北京龙庆峡自助游及攻略
- 几行代码解决京东购物界面
- IOI 2005 Riv 河流 题解
- iVX无代码挑战五秒游戏制作
- Angular4 第三章(中) 重定向路由,子路由,辅助路由