m3u8视频爬虫下载及合并(二)
前言
爬虫获取m3u8视频资源的步骤
目前所要作的流程处理先把m3u8里下载链接批量提取.png把这几百个切片链接先批量下载.png再批量改文件后缀为.ts 再按照m3u8文件提取所有不规则链接文件的【顺序】.png 然后改切片的文件名为0001,0002,0003......顺序.png然后用ffmpeg或者moviepy或者其他工具合并就行.png
看起来也没有那么麻烦…(流汗黄豆)
开始操作
目前已有材料:爬下来的网页源码和从中获取的m3u8文件

把.m3u8改成.txt格式便于操作
批量正则提取和下载
写脚本从原来的m3u8文件中正则表达提取出所有干净的下载链接,将其放到另外一个.txt文件;并且从中下载所有的切片文件
程序代码如下
import requests
import re
from io import BytesIO
import urllib3
import ost = open("b7729bb022ae5d382df1fd28ac61f1178c3f424c.txt", "r", encoding='utf-8')
data = t.readlines()
t.close()for line in data:pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')string = str(line)url = re.findall(pattern,string)f1 = open("url提取.txt", "a+", encoding='utf-8')for urls in url:f1.write(urls+'\n')f1.close()
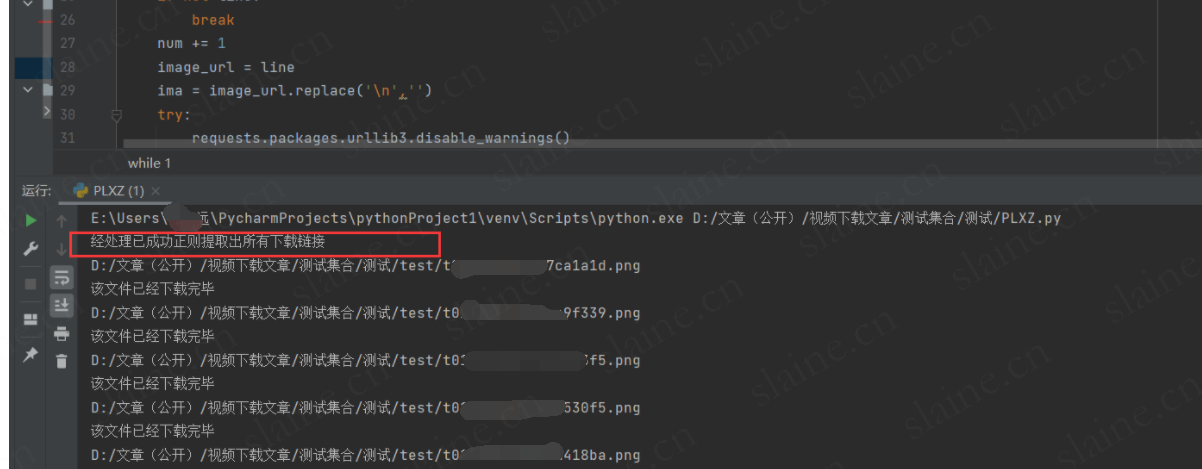
print("经处理已成功正则提取出所有下载链接")
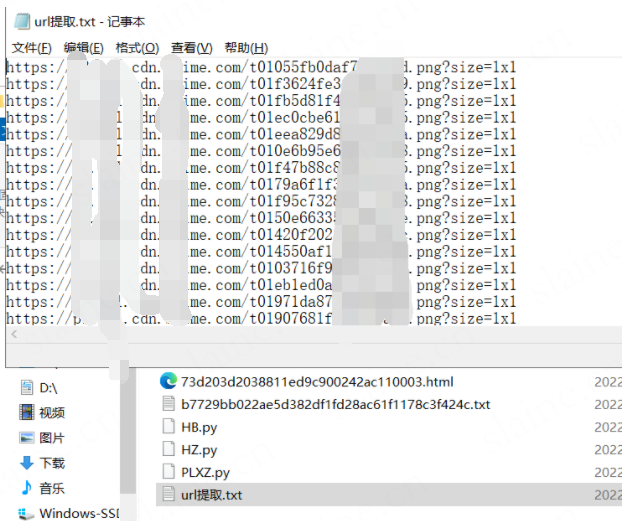
file = open("./url提取.txt") # 打开存放链接的TXT文档
num = 0
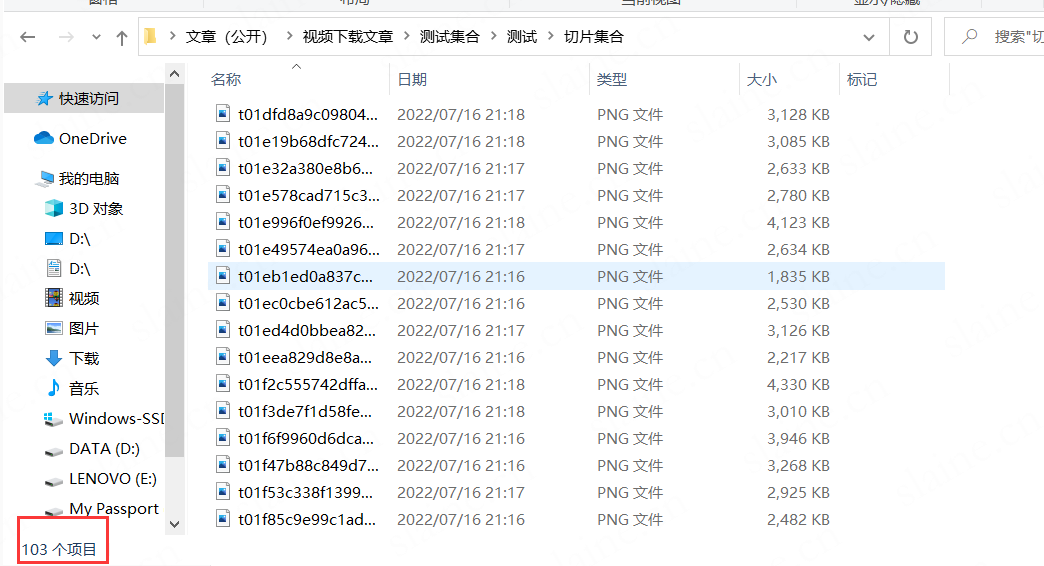
while 1:line = file.readline() if not line:breaknum += 1image_url = lineima = image_url.replace('\n','')try:requests.packages.urllib3.disable_warnings()r = requests.get(ima,verify=False)path = re.sub("https://p0.ssl.cdn.btime.com/|https://p1.ssl.cdn.btime.com/|https://p2.ssl.cdn.btime.com/|https://p3.ssl.cdn.btime.com/|https://p4.ssl.cdn.btime.com/", "D:/文章(公开)/视频下载文章/测试集合/测试/test/", line)path = re.sub('\n', '',path)path = path.replace("?size=1x1", "")print(path)f = open(path, "wb")f.write(r.content) # 将响应对象的内容写下来print("该文件已经下载完毕")f.close()except Exception as e:print('无法下载,%s' % e)continue
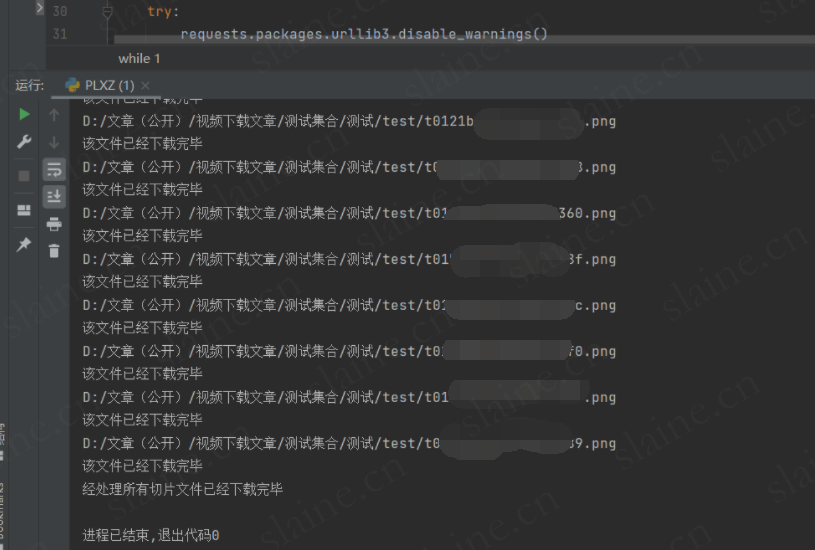
print("经处理所有切片文件已经下载完毕")
file.close()
正常运行
生成提取出的下载链接
并且下载到指定位置
运行结束
批量改后缀
程序代码如下
import os
files = os.listdir('.')
for filename in files:portion = os.path.splitext(filename)if portion[1] == ".png": newname = portion[0] + ".ts" os.rename(filename,newname)
正常运行
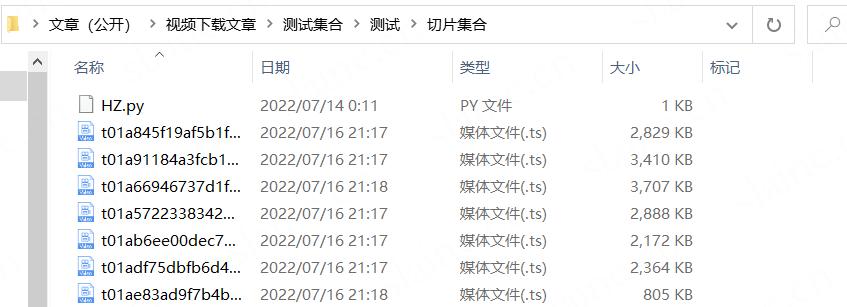
按m3u8指定顺序改文件切片名
接下来就是最关键的根据.m3u8里文件下载链接顺序批量修改文件名的环节
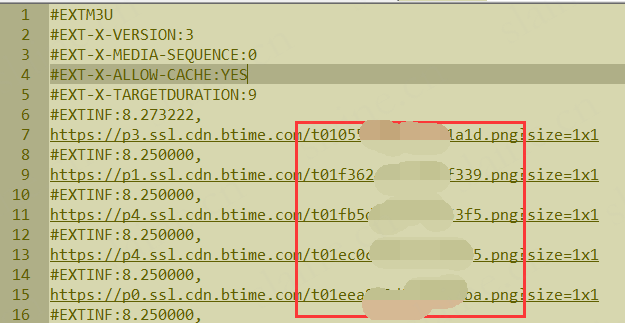
根据已有顺序改文件名为0001,0002,0003…顺序,这对之后的文件合并至关重要
这里就用到刚才提取的url文件
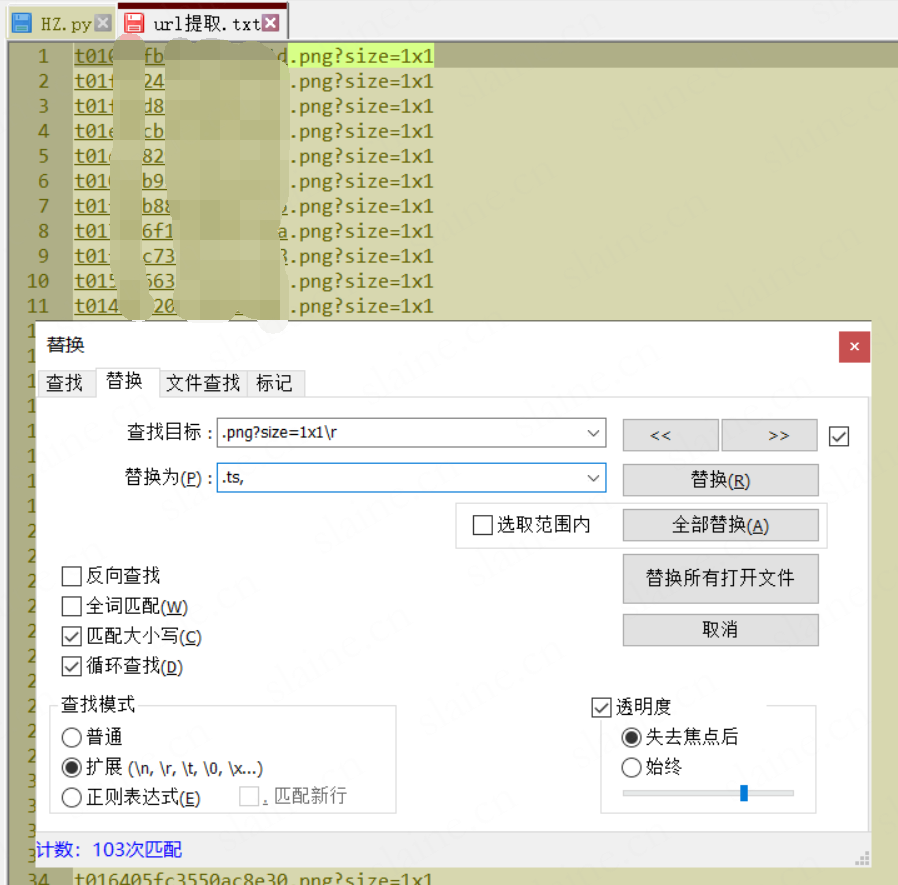
全部替换为.ts结尾且 , 间隔,整理为一行的队列形式

前提需要都准备好了,现在开始批量按照顺序改文件名
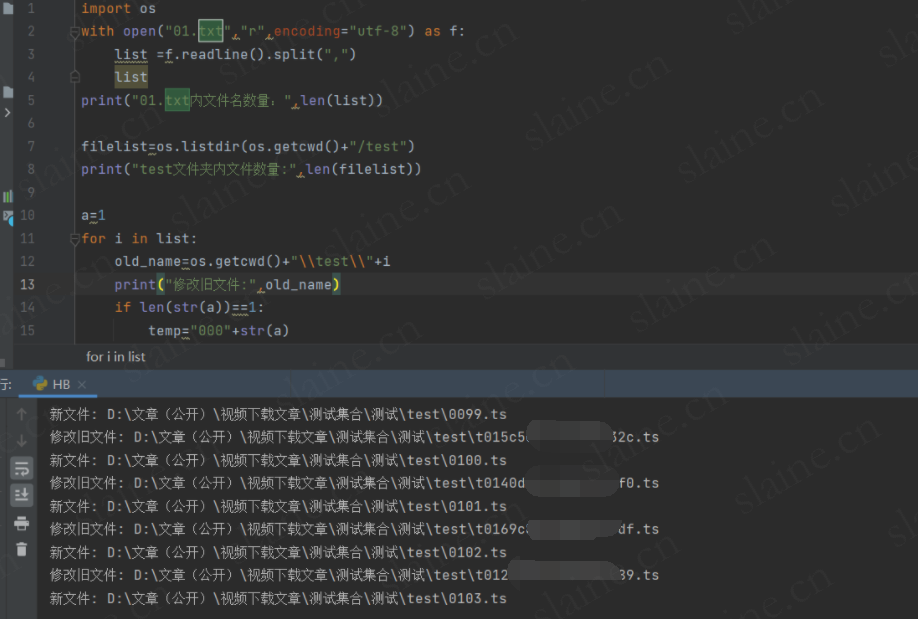
程序代码如下
import os
with open("01.txt","r",encoding="utf-8") as f:list =f.readline().split(",")list
print("01.txt内文件名数量:",len(list))filelist=os.listdir(os.getcwd()+"/test")
print("test文件夹内文件数量:",len(filelist))a=1
for i in list:old_name=os.getcwd()+"\\test\\"+iprint("修改旧文件:",old_name)if len(str(a))==1:temp="000"+str(a)elif len(str(a))==2:temp="00"+str(a)elif len(str(a))==3:temp="0"+str(a)else:temp=str(a)#print(temp)new_name=os.getcwd()+"\\test\\"+temp+".ts"print('新文件:',new_name)a+=1os.rename(old_name, new_name) # 用os模块中的rename方法对文件改名
正常运行完成
所有视频文件按照指定顺序排列完成
文件合并
然后用ffmpeg或者moviepy包或者其他工具合并就行
注意:前提必须是按照m3u8里下载链接的顺序改文件名(上操作)后才能正常合并出成品视频,否则会导致视频片段混乱(作者亲测)
这里网上随便一搜就找到了
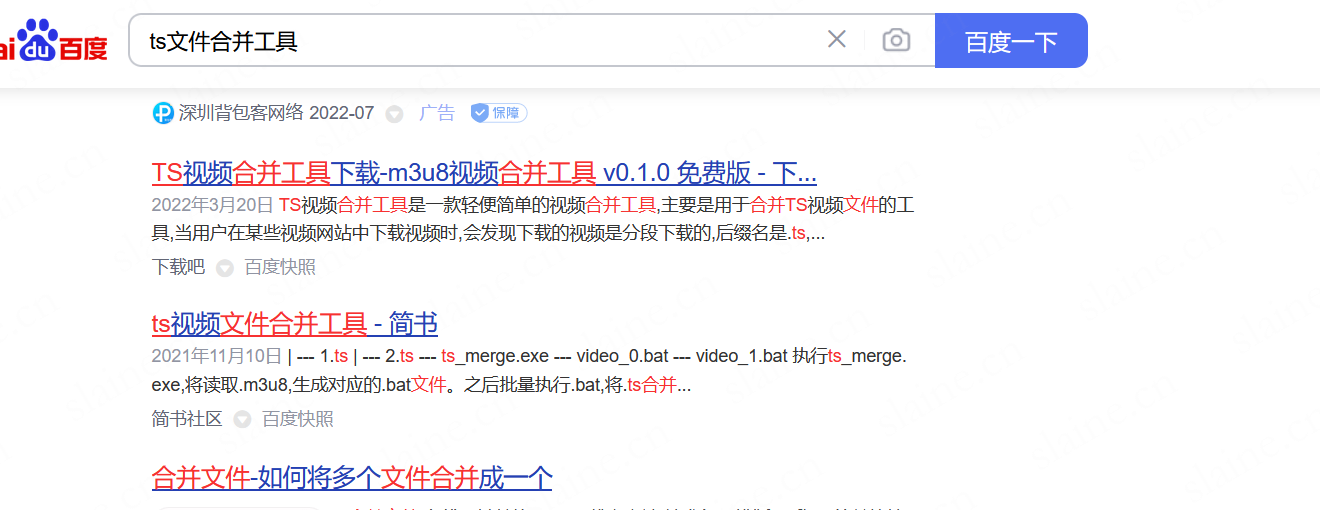
小东西真不错
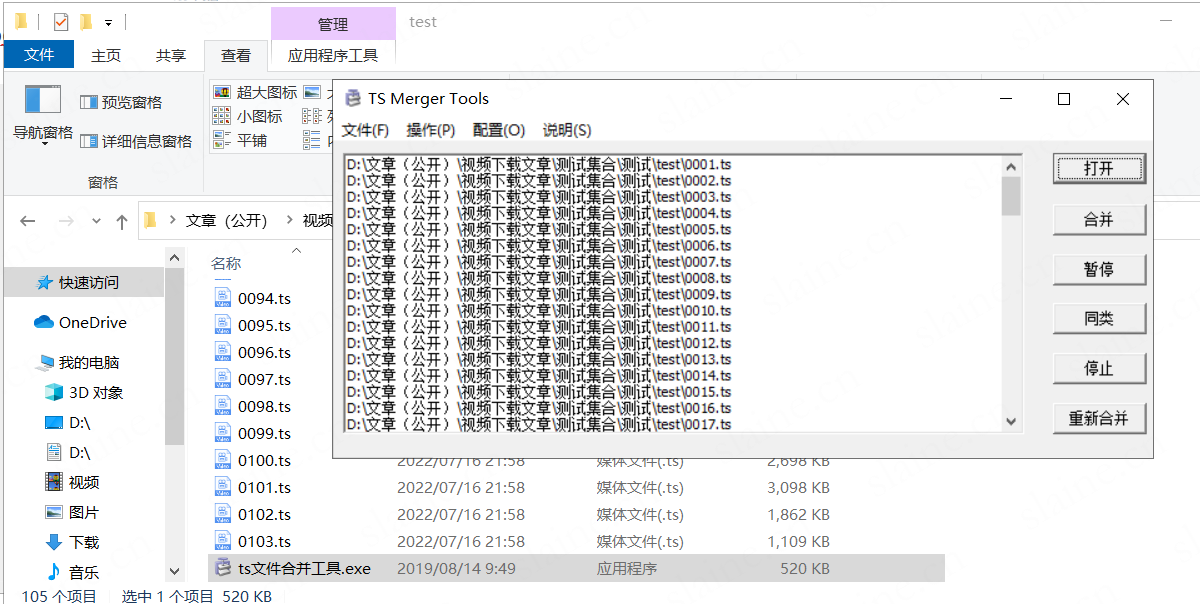
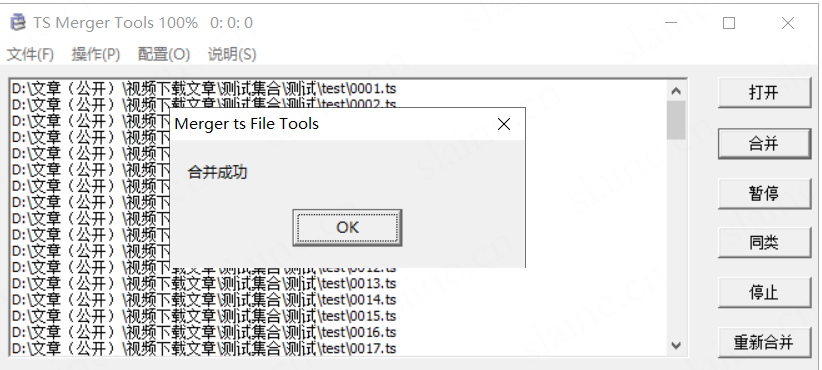
完成
然后就得到成品的文件了
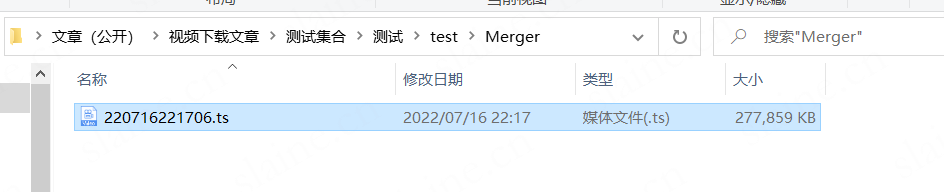
打开看看

内容清晰,完整流畅,达到目的
OVER
老工具人了
m3u8视频爬虫下载及合并(二)相关推荐
- java下载m3u8视频,解密并合并ts(二)
上一篇 java下载m3u8视频,解密并合并ts(一)--m3u8概述 下一篇java下载m3u8视频,解密并合并ts(三)--代码实现 m3u8链接的获取 样例一:两个m3u8无key 首先在浏览器 ...
- java下载m3u8视频,解密并合并ts(三)
上一篇 java下载m3u8视频,解密并合并ts(二)--获取m3u8链接 编写代码 加载jar包 由于java不支持AES/CBC/PKCS7Padding模式解密,所以我们要借助第一篇下载好的ja ...
- Java合并m3u8_m3u8Download java 下载 m3u8 视频,解密并合并 ts java download m3u8 vide @codeKK Android开源站...
java 下载 m3u8 视频,解密并合并 ts m3u8 链接获取方式以及代码分析请参见: https://blog.csdn.net/qq494257084/article/details/103 ...
- python梨视频爬虫下载,反反爬
python梨视频爬虫下载,反反爬 跟着b站视频学习,发现和视频里面讲的不一样 视频URL改成ajax异步请求得到的 拿到视频url之后发现居然是个假链接不是真实的 仔细观察真实的视频url发现,刚才 ...
- m3u8 视频的解密,合并处理 通过java代码
前言 就是一堆废话,可以不看,文末有代码,可以直接down 通过UC下载了一些视频,觉得过于精彩,应该保存下载,不过它是m3u8格式的, 之前为了给手机刷机,资料必须得备份,于是拷贝了出来,把手机上的 ...
- 一键视频爬虫下载神器,广告还没加载就下载完了
欢迎关注微信公众号数云智连. 关注后将收到: 1.各式各样的公开数据.采集程序提供,如广交会.海关数据.股票数据等等,你有需要的数据也请留言,评估后将会在采集后在公号发布: 2.提升个人能力的办公技巧 ...
- python合并ts视频_python爬取视频网站m3u8视频,下载.ts后缀文件,合并成整视频
最近发现一些网站,可以解析各大视频网站的vip.仔细想了想,这也算是爬虫呀,爬的是视频数据. 首先选取一个视频网站,我选的是 影视大全 ,然后选择上映不久的电影 "一出好戏" . ...
- m3u8视频格式下载并转换为mp4(ffmpeg)
通过在网络上查询资料以及博客后发现了下载m3u8转换为mp4得方法,但是在使用后发现转换后的mp4文件信息不完善.如果您使用过网上流传最广的转换方法会发现当你查看mp4文件详细信息时是没有播放时长等数 ...
- Android,播放m3u8视频和下载m3u8的视频
因最近项目需要,研究了一个礼拜的m3u8.格式为m3u8的视频,其实是由多个.ts文件组成在一起播放的.下面有些资料是参考了网上的,总体概括下实现思路: 1.根据后台给出的m3u8的地址,实现播放,核 ...
最新文章
- Spring Cloud Alibaba 基础教程:Nacos 生产级版本 0.8.0
- 香港大学自然语言处理实验室PhD/RA招生(HKU NLP)
- MongoDB(一):简介
- 笔记本卡顿不流畅是什么原因_电脑卡顿不流畅是什么原因
- C# WinForm窗体四周阴影效果
- html表格td的内容修改,点击table中的td,修改td中的内容功能实现
- GitHub 报告:中国755万开发者排全球第二
- 44. Element insertBefore() 方法
- 白话浅谈——组播那点事
- 数学实验基于matlab软件,数学实验:基于MATLAB软件
- gp3688 uhf2扩频_摩托罗拉GP3688_GP3188写频软件
- 前端微信支付代码(公众号支付)
- 基于Lasso回归筛选变量构建Cox模型并绘制Nomogram
- 【VirtualBoxUbuntu】VirtualBox中Ubuntu虚拟机磁盘碎片整理并压缩磁盘空间
- centos ffmpeg 加水印
- 想了解Intel vPro(博锐)技术,就来Intel vPro虚拟展厅
- 非线性混合效应 NLME模型对抗哮喘药物茶碱动力学研究
- 周末imac机重装win7,装得我抓狂
- USBPCAP工具介绍
- 解包酷派CPB包任意机型
热门文章
- AtCoder Beginner Contest 244 B题(超详讲解)
- ufs 固态硬盘_手机机身存储到底有多快?UFS闪存和电脑固态硬盘谁更强?
- 基于RNN(循环神经网络)的北京雾霾天气指数的预测(keras实现RNN,LSTM神经网络算法)
- solrCloud集群的搭建
- 关于举办第三届全国Revit开发实战训练课程的通知
- 一文彻底搞懂I/O多路复用及其技术
- 编写多线程Java应用程序
- 使用MC55实现GPRS通信
- clover引导macos big sur_【黑苹果】手动制作macOS启动U盘及EFI配置指南
- 计算机二级index函数怎么用,Excel函数-match、index(上)-计算机二级Office