发现印度尼西亚提克多克州的病毒性食物食谱
In the past 5 months quarantine from the Covid-19 pandemic, I’ve seen changes in my friend’s and relatives’ Instagram posts and story updates. From posts on outdoor communal activities — travel, hangouts, parties — , now it’s shifting to home activities on gardening, Netflix binge-watching, and cooking!
在过去五个月的Covid-19大流行隔离中,我看到我的朋友和亲戚的Instagram帖子和故事更新发生了变化。 从户外公共活动的帖子(旅行,视频群聊,聚会),现在已经转移到园艺,Netflix狂欢观看和烹饪等家庭活动!
I’m seeing there are similar dishes that people are trying out and posts on social media. It started with dalgona coffee on March-April, to Korean garlic cheese bun in the recent days. Interestingly enough, I also see people are now sharing their recipes on TikTok, with demo videos for the recipes.
我看到人们正在尝试类似的菜肴并在社交媒体上发帖。 从3月至4月的dalgona咖啡到最近几天的韩国大蒜奶酪面包 。 有趣的是,我还看到人们现在在TikTok上分享他们的食谱,以及有关食谱的演示视频。
Now using my curiosity to play around with data, I decided to look around and explore the TikTok posts on some hashtags that people use to explore recipes to try at home. My goal is pretty simple :
现在,出于好奇,我开始研究数据,然后决定环顾四周,并探索一些人们在用来在家中尝试食谱的标签上的TikTok帖子。 我的目标很简单:
- Scrape some top TikTok posts with these hashtags使用这些标签刮掉一些TikTok的重要帖子
Extract the captions, likes/views, and check for any interesting trends — literally playing around with data :D
提取字幕,喜欢/观看次数,并检查是否有任何有趣的趋势- 实际上就是在玩数据 :D
TikTok数据收集 (TikTok Data Collection)
Disclaimer: I’m using TikTokApi from David Teather, which is available on RapidAPI.
免责声明 :我使用 TikTokApi 从 大卫Teather ,这是可以的RapidAPI。
For this case, I’m using the endpoints of this API from RapidAPI. Whilst web-scraping has its ethical debate, in this exploration I’m using it responsibly for only retrieving publicly available data and within a limited amount.
对于这种情况,我正在使用RapidAPI中该API的端点。 尽管网络爬虫在道德上存在争议 ,但在本次探索中,我以负责任的态度将其用于仅检索有限数量的公共可用数据。
The full code of the TikTok scraping code can be found here.
TikTok抓取代码的完整代码可以在这里找到。
1.从RapidApi端点获取原始数据 (1. Get Raw Data from RapidApi endpoints)
Here I’m using Python HTTP request comment, calling to RapidApi endpoints with the hashtag query that I need. I have pre-defined the count of posts to be captured as 1000 posts(out of maximum 2000 posts/request)
在这里,我使用的是Python HTTP请求注释,并通过所需的主题标签查询调用RapidApi端点。 我已经预定义了要捕获的帖子数为1000个帖子(每个请求最多2000个帖子)
import requestsurl = "https://tiktok2.p.rapidapi.com/hashtag"querystring = {"hashtag":"masakdirumah","count":"1000"}headers = { 'x-rapidapi-host': "tiktok2.p.rapidapi.com", 'x-rapidapi-key': "yourkeyhere" }response = requests.request("GET", url, headers=headers, params=querystring)print(response.text)2.解析响应数据 (2. Parse the response data)
From the above script, we will get a response to JSON data.
从上面的脚本中,我们将获得对JSON数据的响应。
import jsonimport pandas as pddata = response.texty = json.loads(data)raw_df = pd.json_normalize(y['data'])raw_dfNext, I’m parsing this data to data frame format, and only for the columns that I need: video URL, user_name, caption, count of likes, comments, plays, and shares.
接下来,我将这些数据解析为数据帧格式,并且仅用于我需要的列:视频URL,用户名,标题,顶数,评论,播放和共享。
df_summary = raw_df[['itemInfos.createTime','itemInfos.video.urls','itemInfos.text','authorInfos.uniqueId','authorStats.followerCount','itemInfos.commentCount','itemInfos.playCount','itemInfos.shareCount','itemInfos.diggCount','itemInfos.video.videoMeta.duration']]df_summary.rename(columns={ "itemInfos.createTime" : "created_time", "itemInfos.video.urls" : "video_url", 'authorInfos.uniqueId' : 'user_name', 'itemInfos.text' : 'video_desc', 'authorStats.followerCount':'user_follower_cnt', 'itemInfos.commentCount':'cnt_comments', 'itemInfos.playCount':'cnt_plays', 'itemInfos.shareCount':'cnt_shares', 'itemInfos.diggCount':'cnt_likes', 'itemInfos.video.videoMeta.duration':'video_length'})3.从字幕中提取提及和主题标签 (3. Extract mentions and hashtags from the captions)
Here is where I thank John Naujoks for his functions to extract hashtags and mentions from a string. I did some modification, but without his example script, I won’t be able to figure out what to do to get this.
在这里,我感谢John Naujoks的功能,它从字符串中提取标签和提及内容。 我做了一些修改,但是没有他的示例脚本,我将无法弄清楚该怎么做。
def find_hashtags(comment):"""Find hastags used in comment and return them""" hashtags = re.findall('#[A-Za-z]+', comment)if (len(hashtags) > 1) & (len(hashtags) != 1):return hashtagselif len(hashtags) == 1:return hashtags[0]else:return ""def find_mentions(comment):"""Find mentions used in comment and return them""" mentions = re.findall('@[A-Za-z]+', comment)if (len(mentions) > 1) & (len(mentions) != 1):return mentionselif len(mentions) == 1:return mentions[0]else:return ""df_summary['hashtags'] = [find_hashtags(video_desc) for video_desc in df_summary['video_desc']]df_summary['mentions'] = [find_mentions(video_desc) for video_desc in df_summary['video_desc']]df_summaryThere you go, some dataset to play around with!
到这里,您可以玩一些数据集!
数据整理时间! (Data Wrangling Time!)
Now onto the fun part — data exploration. With the data above, here’s what I have in mind for the exploration part :
现在进入有趣的部分-数据探索。 有了上面的数据,这就是我要探索的部分:
- Timeseries trends of the posts帖子的时间序列趋势
- Plays/likes/shares distribution across accounts帐户之间的播放/喜欢/分享分配
- Content of popular recipes热门食谱的内容
Starting with some time-series analysis, here is the trend of post over time. Looking at the below timeseries charts we get some interesting insights:
从一些时间序列分析开始,这是帖子随时间变化的趋势。 查看下面的时间序列图,我们可以获得一些有趣的见解:
Video posts have uptrends from March 2020, peaking in May 2020 (Ramadhan season in Indonesia). Within the past 2 months, the total videos being posted are quite stable of ~10 posts/day.
视频帖子从2020年3月开始呈上升趋势,到2020年5月 (印度尼西亚的斋月季节) 达到顶峰 。 在过去2个月内,发布的视频总数非常稳定,每天大约有10个帖子。
The length of videos posted also have an uptrend. It used to be ~40 seconds in April 2020, but now reaching ~60 seconds in August 2020.
发布的视频的长度也有上升的趋势 。 过去在2020年4月约为40秒,但现在在2020年8月约为60秒。
Afternoon hours — 3 pm to 7 pm seems to be the peak hours where people are posting their cooking tutorials. Prepping for afternoon snack or dinner, perhaps?
下午时间-下午3点至7点似乎是人们发布烹饪教程的高峰时间。 也许准备下午点心或晚餐?

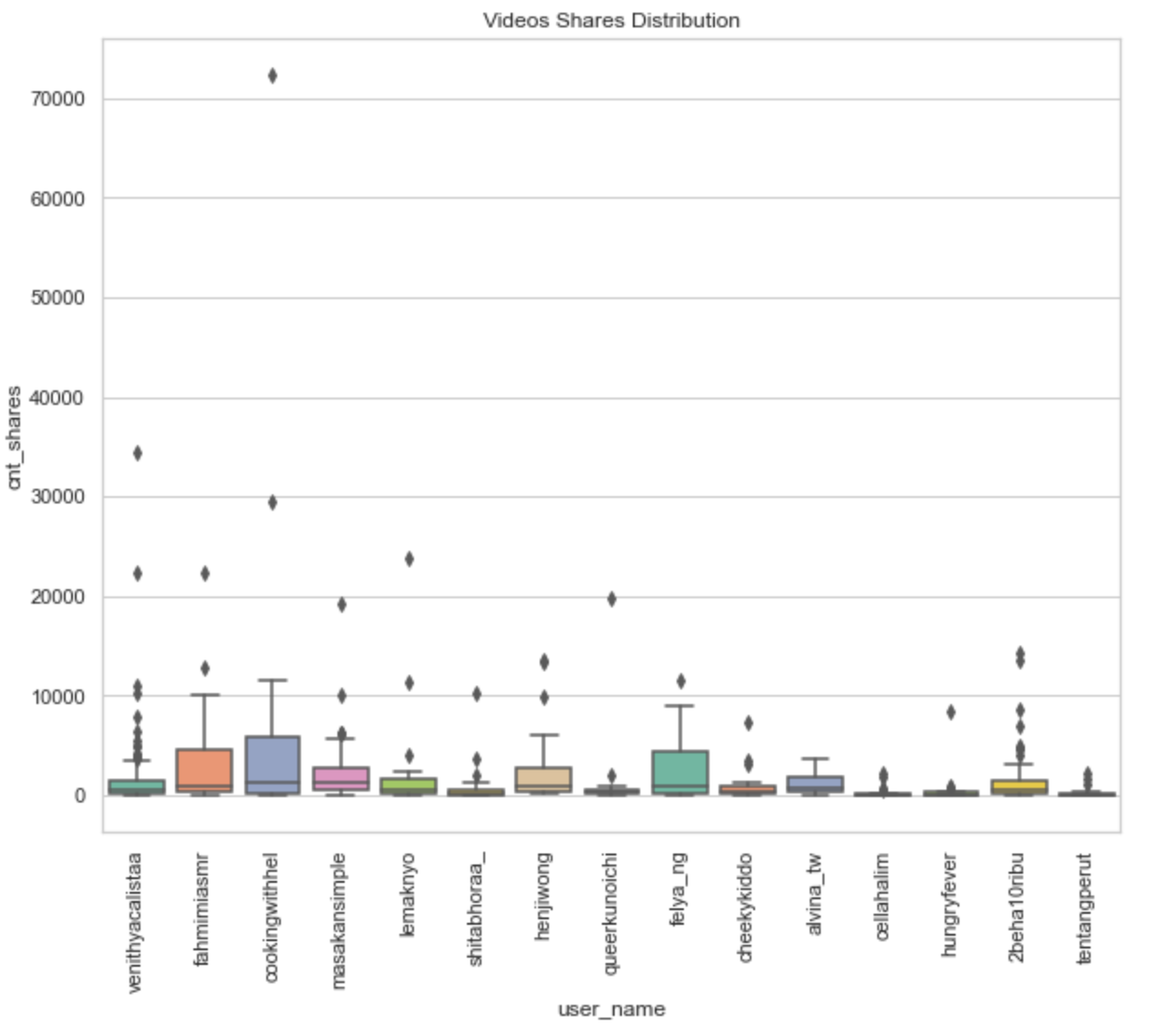
How about post trends across accounts? Interestingly, for the top 15 users with the highest posts, we see a quite different distribution of likes and shares. Accounts like ‘2beha10ribu’, ‘fahmimiasmr’, and ‘venithyacalistaa’ have high likes distribution, reaching above 1mio likes. On the other hand, ‘cookingwithhel’ is the winner in terms of the distribution of the shares. One of their posts even reaching 70k shares.
各个帐户的发布趋势如何? 有趣的是,对于帖子数最高的前15位用户,我们发现喜欢和分享的分布情况大不相同。 诸如“ 2beha10ribu ”,“ fahmimiasmr ”和“ venithyacalistaa ”这样的帐户具有很高的喜欢分布,达到了1mio以上的喜欢。 另一方面,就股份分配而言,“ cookingwithhel ”是赢家。 他们的职位之一甚至达到7万股。

Now on to the highlight of the post, let’s find out the food recipes with the highest shares, likes, and plays (indicating their popularity).
现在到帖子的重点,让我们找出分享,喜欢和玩耍最多的食物食谱 (表明它们的受欢迎程度)。
The biggest challenge of this is extracting the dish names from the posts’ captions. The reason being is in a TikTok post you can type anything you want — without any structured fields. Also, the videos itself can be edited to show the dish names — instead of using captions. In this case, I did several data cleansing methods: remove numbers and special characters, filter out word noise (stopwords and common words on the posts), and then extract dish names from popular bigrams and trigrams in the dataset.
最大的挑战是从帖子标题中提取菜名 。 原因是在TikTok帖子中,您可以键入任何想要的内容-无需任何结构化字段。 另外,可以编辑视频本身以显示菜名-而不是使用字幕。 在这种情况下,我做了几种数据清理方法: 删除数字和特殊字符 , 过滤掉单词杂音 (职位上的停用词和常用单词),然后从数据集中的流行双字母组和三字母组中提取菜名。
Some word clouds of the food, in unigram, bigrams, and trigrams. You might want to translate it since it’s in Bahasa Indonesia, but the components here are mostly related to desserts and snacks — oreo, chocolate, martabak, cake, milo, pie, pudding, cheese stick, etc. No wonder the peak hour of the posts is in the afternoon — these are prefect afternoon snacks!
食物中的某些词云,用会标,二字组和三字组表示。 你可能会想翻译它,因为它是在印尼语,但这里的部件大多与甜点和小吃 -奥利奥,巧克力,martabak,饼,高粱,馅饼,布丁,奶酪棒等难怪的高峰小时帖子是在下午- 这些都是下午的点心 !
And the popular dishes are
最受欢迎的菜是

There are various recipes of dishes here and even a few posts referring to the same dishes. Summarizing quickly, here are the viral food recipes of Indonesia TikTok:
这里有各种菜谱,甚至有几篇文章都提到了同一道菜。 总结一下,这是印度尼西亚TikTok的病毒性食品食谱:
- Desserts: brownies, dessert box, cake, smoothies bowl, milk pie甜点:布朗尼蛋糕,甜点盒,蛋糕,冰沙碗,牛奶派
- Snacks: rolled egg, coffee bread, fried tofu, potato hotdog, mochi小吃:鸡蛋卷,面包,炸豆腐,土豆热狗,麻chi
- Savory dishes: meatballs, Korean fried rice, grilled chicken, chicken katsu美味佳肴:丸子,韩国炒饭,烤鸡,炸鸡
Quite a number of it seems to be desserts and snacks as opposed to side dishes to be eaten with rice.
与米饭一起食用的小菜相比,似乎有很多是甜点和小吃。
Some extra viz to make a more fancy wordcloud — I’m using PIL and pylab for getting an image color as the background of the word cloud.
一些额外的方法来制作更精美的 wordcloud —我正在使用PIL和pylab获取图像颜色作为单词云的背景。

The full code of data exploration and visualization can be found here.
完整的数据探索和可视化代码可在此处找到。
结束语 (Closing Remarks)
That sums up my discovery for viral food recipes of TikTok Indonesia. Try out your version of the top recipes: brownies pudding, milk pie, martabak, and dessert box and see for yourself if they’re worthy of the virality :D
总结我对印尼TikTok病毒性食品食谱的发现。 试试你的食谱顶级版本: 巧克力布丁 , 奶饼 , martabak和点心盒 ,看看自己,如果他们是当之无愧的传播性的:d
Again, although there are limitless possibilities to scrape data all over the web, we still need to be mindful of the ethical stands of it. Just keep in mind that you retrieve only the publicly available data and not in a destructive manner to the server account (i.e hitting the API to the server limit).
同样,尽管在网络上刮刮数据的可能性无限大,但我们仍然需要注意其道德立场。 请记住,您只能检索公开可用的数据,而不会以破坏性的方式检索服务器帐户(即,使API达到服务器限制)。
Happy exploring (and cooking)!
愉快的探索(和烹饪)!
翻译自: https://medium.com/swlh/discovering-viral-food-recipes-of-tiktok-indonesia-7f7e353c52ef
http://www.taodudu.cc/news/show-5233505.html
相关文章:
- javamail 发送内容为图片的邮件
- 云原生计算动态周报8.9-8.15
- 云原生行业应用崛起,从“可用”到“好用”有多远?
- Service Mesh Summit | 无侵入增强 Istio,网易数帆践行这三条原则
- Hango Rider:网易数帆开源 Envoy 企业级自定义扩展框架
- Hango 开源解读:云原生网关实践,为何要选择 Envoy ?
- python抢券代码_京东python抢券脚本Python内置函数——str
- php京东秒杀,php,高并发_关于抢京东券高并发的问题?,php,高并发,秒杀 - phpStudy...
- 京东商品获取优惠券API接口-京东优惠券如何获取-京东联盟API接口
- 京东神券:新年满500-40、1000-80、3000-240神券,每满200-30京贴 新年补贴 可叠万券
- MATLAB--simulink工具箱的使用(2)
- 设备驱动的艺术之旅 - Watch Dog 的 NMI 应用场景
- JZ2440系统时钟和定时器
- 定时器基本原理及常见问题
- 论文学习与复现记录
- QTextToSpeech类语音播报
- (TTS)QT编写文字转语音(wav)PC小工具
- QT播放语音的一系列问题
- Qt —— 英汉互译+语音翻译(Qt接口,附源码)
- 基于Qt的智能语音机器人
- QT的语音识别
- QT实现文字转语音
- Qt功能优化:Qt语音助手
- 关于qt上实现基于百度的语音识别
- QT实现文本转语音
- 基于QT的语音识别 超简单 最详细
- qt调节linux系统音量,QT语音声音小怎么办?QT语音各种声音调节教程
- Qt跨平台文字转语音
- qt linux 文字转语音,QT文本转语音模块(TTS)QTextToSpeech
- linux qt语音播放库,QT语音如何上传视频?QT语音上传视频的方法
发现印度尼西亚提克多克州的病毒性食物食谱相关推荐
- 最新研究发现:天然海绵含有抑制Omicron变体感染的天然化合物
本文原文首发于2023年1月9日E-LIFESTYLE (阅读时间4分钟) 附标题:通过研究370多种来自植物.真菌和海绵等天然来源的化合物,寻找可用于治疗新冠肺炎的新抗病毒药物,用这些天然化合物制成 ...
- 文献翻译和笔记--CHEF:CHEF: Cross-Modal Hierarchical Embeddings for Food Domain Retrieval(用于食物域检索的跨模态分层嵌入)
文献下载地址:CHEF: Cross-modal Hierarchical Embeddings for Food Domain Retrieval| Proceedings of the AAAI ...
- 如何在html中加入食品,Foodie怎么给食物加滤镜
Foodie appV1.5.1 安卓手机版 类型:图形图像大小:21M语言:中文 评分:10.0 标签: 立即下载 Foodie是一款傻瓜式的相机应用,主要功能就是为食物加一个合适的滤镜来提高食物颜 ...
- AI设计“超级食物”:可能有助于预防癌症!
全文共3613字,预计学习时长10分钟 图源:unsplash 随着现代医学的发展,如今的我们比任何时代都更长寿,但却并不一定更健康:人口老龄化加速,癌症.代谢病.神经系统疾病和心脏病等慢性疾病持续增 ...
- 被妖魔化的碳水化合物食物能否卷土重来?
新浪科技讯 北京时间3月1日消息,一段时间以来,许多追求健康的人都着迷于低碳水化合物饮食.包括生酮(Keto).Dukan.Paleo和Atkins等饮食方法在减肥人群中仍然相当流行,并且使健康脂肪和 ...
- 2019年国考行测错题集(省级)
6.有关经济学常识,下列说法错误的是( ) A.国民收入统计中包括退休金 B.货币发行是中央银行的负债业务 C.公共物品无法通过市场机制来调节供求 D.春节前后的物价上涨不属于通货膨胀 答错选项:B ...
- 喝凉水都长胖?吸收比别人好?肠道菌群真是个任性的小妖精
本文转载自"态昌基因",已获授权 BBC曾经出了一部拉仇恨的科教纪录片:为什么有的人长不胖. 英国某大学招募了10名自认为不容易发胖的志愿者,进行了为期4周的实验.在4周的时间里, ...
- 拍下首张黑洞照片的团队获300万美元奖金:2020年科学突破奖揭晓
来源:科学突破奖科学突破奖 2019 年 9 月 5 日,2020 年度突破奖(Breakthrough Prize)揭晓.突破奖,又被誉为"科学界的奥斯卡",现已经入第八个年头. ...
- 全球奖金最高的科学奖项颁发:黑洞拍摄团队、肥胖症治疗等获奖;2位清华北大校友入围...
允中 发自 凹非寺 量子位 报道 | 公众号 QbitAI 2019年9月5日,2020年度突破奖(Breakthrough Prize)揭晓. 该奖项又被誉为"科学界的奥斯卡" ...
最新文章
- Python中的map()函数和reduce()函数的用法
- IBM 340 亿美元收购 RedHat(红帽)
- ftpClient的连接超时设置(setConnectTimeout,setSoTimeout)
- vuex 实现vue中多个组件之间数据同步以及数据共享。
- UITableView加载几种不同的cell
- 使用jMeter的regular expression extract提取SSO form的XSRF protection token
- 分享25个新鲜出炉的 Photoshop 高级教程
- 会计电算化常考题目二
- 数据结构上机实践第三周项目3- 求集合并集
- OpenCV每日函数 对象追踪模块 Meanshift算法
- Iframe的allow属性生效时机
- windows删除文件夹时提示:你需要权限来执行此操作
- Mac安装gensim报错:No extention 巴拉巴拉
- 遗传算法入门(连载之十) 神经网络入门(连载预告)
- 珠海实验室通风系统建设安装说明
- JAVA程序设计:买卖股票的最佳时机含手续费(LeetCode:714)
- 包青天 - 乞丐王孙(4) 片段 - 堂审河南荥县县令马松友
- expected `;' before ‘iter’
- 两所澳门顶尖高校基金与芯耀辉合作,共同促进产业和技术发展
- Unity在OpenGL模式下Shader编译报错