kafka connect分布式安装
为什么80%的码农都做不了架构师?>>> 
kafka connect分布式部署
Apache Kafka 消息分发组件,数据采集后先入Kafka
Schema Registry Schema管理服务,消息出入kafka、入hdfs时,给数据做序列化/反序列化处理。
Kafka Connect 提供kafka到其他存储的管道服务,此次焦点是从kafka到hdfs,并建立相关HIVE表。
Kafka Rest Proxy 提供kafka的Rest API服务。
Kafka Clients 提供Client编程所需SDK。
说明:以上服务除Apache kafka由Linkedin始创并开源,其他组件皆由Confluent公司开发并开源。上图解决方案由confluent提供。
基本逻辑步骤
- 数据通过Kafka Rest/Kafka Client写入Kafka;
- kafka Connect任务作为consumer从kafka订阅数据;
- kafka Connect任务建立HIVE表和hdfs文件的映射关系;
- kafka connect任务收到数据后,以指定格式,写入指定hdfs目录;
实际操作:
启动kafka服务
- 首先进行集群间ssh免密登陆
- 后期为了测压可控,自己单独搭建了,在所有节点启动
安装zookeeper
具体安装见博文ZOOKEEPER安装及测试
安装kafka
可以采取集成或自己单独搭建
- kafka connect集成:
在路径 */confluent/etc/kafka路径下修改server.properties,进行如下相应的修改
/*
1.修改A、B、C三台服务器上配置
2.配置文件中broker.id值分别修改为0、1、2
*/
broker.id=2
listeners=PLAINTEXT://A:9092
log.dirs=/usr/local/kafka/logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=3
zookeeper.connect=A:2181,B:2181,C:2181
然后启动kafka:
nohup ./bin/kafka-server-start.sh ./config/server.properties > /dev/null 2>&1 &
- 单独安装:
- 下载kafka安装包下载链接,并解压到software目录下:
- 到config目录下修改server.properties,具体修改和上述相同 然后进入kfka目录启动:
./bin/kafka-server-start.sh -daemon ./config/server.properties &
- 服务说明 :kafka服务无Leader概念,服务访问端口为9092
- 进行kafka集群验证
- 新建一个topic:
./kafka-topics.sh -zookeeper A:2181,B:2181,C:2181 -topic connect-test -replication-factor 2 -partitions 3 -create
- 在一个节点中进入bin目录,新建一个consumer:
./kafka-console-consumer.sh -zookeeper A:2015,B:2015,C:2015 -topic connect-test
&
./bin/kafka-console-consumer.sh --zookeeper A:2015,B:2015,C:2015 --topic test_dtc --consumer.config config/consumer1.properties
- 在另一个节点中进入bin目录,新建一个producer:
./kafka-console-producer.sh -broker-list A:9092,B:9092,C:9092 -topic connect-test
之后再生成者终端发送数据,如果在消费者端有消息过来,则说明集群搭建成功: 生产者端:
消费者端:

安装Schema Register并启动该服务
1.所有节点都进入路径*/software/confluent/etc/schema-registry下找到schema-registry.properties文件,并进行如下修改
listeners=http://0.0.0.0:8081
kafkastore.connection.url=A:2015,B:2015,C:2015
kafkastore.topic=_schemas
debug=false
然后启动:
./bin/schema-registry-start ./etc/schema-registry/schema-registry.properties &
- 服务说明 Schema Register服务端口为8081
安装启动Kafka Rest API服务
- 所有节点进入路径*/software/confluent/etc/kafka-rest下找到配置文件kafka-rest.properties,并做如下修改
// 修改schema服务器地址和zookeeper服务器地址
id=kafka-rest-test-server
schema.registry.url=http://localhost:8081
zookeeper.connect=A:2015,B:2015,C:2015
启动:
./bin/kafka-rest-start ./etc/kafka-rest/kafka-rest.properties &
启动Kafka connect服务
- 进入路径*/software/confluent/etc/schema-registry下找到connect-avro-distributed.properties并做如下修改:
/*
修改如下配置项:
1.bootstrap.servers, 所有kafka broker的地址
2.group.id 标志connect集群,集群内配一致
3.key.converter.schema.registry.url,schema服务地址
4.value.converter.schema.registry.url,schema服务地址
*/
bootstrap.servers=A:9092,B:9092,C:9092
# The group ID is a unique identifier for the set of workers that form a single Kafka Connect
# cluster
group.id=connect-cluster
- 启动命令:
./bin/connect-distributed ./etc/kafka/connect-distributed.properties > connect-distribute.log &
传输到hdfs实验
- 在/etc/kafka-connect-hdfs新建connect 这个是在主节点上新建的C,进入路径/software/confluent/etc/kafka-connect-hdfs下新建quickstart-hdfs.properties,并做如下修改
name=hdfs-sink
connector.class=io.confluent.connect.hdfs.HdfsSinkConnector
tasks.max=1
topics=test_hdfs
hdfs.url=hdfs://C:9000
flush.size=3
- 然后在C上启动该connector:
confluent load hdfs-sink -d etc/kafka-connect-hdfs/quickstart-hdfs.properties
- 检查启动的connector:
curl localhost:8083/connectors | jq
- 显示:
["hdfs-sink"
]
即启动成功,接下来即可以进行生产测试了
- 生产测试 然后在C上启动生产者:
./kafka-avro-console-producer --broker-list A:9092,B:9092,C:9092 --topic test-hdfs --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'
#输入以下代码
{"f1":"agastf"}
{"f1":"gaserwsagf"}
最后进入hdfs查看是否生成该文件

继续进入查看都是avro文件: 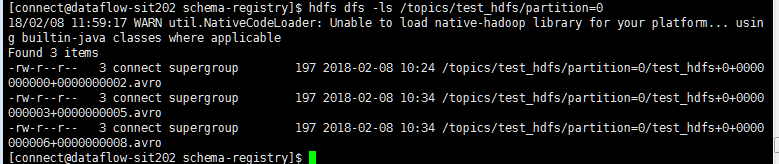
avro文件需要下载解析jarjar下载
然后将hdfs中的avro文件拷贝到本地进行查看
hadoop fs -copyToLocal /topics/test_hdfs/partition=0/test_hdfs+0+0000000000+0000000002.avro /tmp
java -jar avro-tools-1.8.2.jar tojson /tmptest_hdfs+0+0000000000+0000000002.avro //查看数据参考网址
1.kafka connect博客
2.官网
3.参考3
4.参考4
5.参考5
6.参考6
7.Kafka Connector与Debezium
8.kafka connect简介以及部署
9.Kafka 之六 connector
转载于:https://my.oschina.net/112612/blog/1587396
kafka connect分布式安装相关推荐
- Kafka系列之:详细介绍部署Kafka Connect分布式集群
Kafka系列之:详细介绍部署Kafka Connect分布式集群 一.部署分布式Kafka集群详细步骤 二.Kafka Worker节点安装部署Kafka 三.修改connect-distribut ...
- Kafka 伪分布式安装
伪分布式的方式安装kafka 启动3台kafka Brokers 安装过程 上传解压 kafka_2.11-0.8.2.1 版本 百度云 链接:https://pan.baidu.com/s/1y7e ...
- Hadoop完全分布式安装Kafka
应用场景 按照搭建hadoop完全分布式集群博文搭建完hadoop集群后,发现hadoop完全分布式集群自带了HDFS,MapReduce,Yarn等基本的服务,一些其他的服务组件需要自己重新安装,比 ...
- 深入理解Kafka Connect:转换器和序列化
AI前线导读:Kafka Connect是一个简单但功能强大的工具,可用于Kafka和其他系统之间的集成.人们对Kafka Connect最常见的误解之一是它的转换器.这篇文章将告诉我们如何正确地使用 ...
- Kafka: Connect
转自:http://www.cnblogs.com/f1194361820/p/6108025.html Kafka Connect 简介 Kafka Connect 是一个可以在Kafka与其他系统 ...
- Kafka Connect简介
一. Kafka Connect简介 Kafka是一个使用越来越广的消息系统,尤其是在大数据开发中(实时数据处理和分析).为何集成其他系统和解耦应用,经常使用Producer来发送消息到Broker, ...
- kafka安装完整步骤_还在寻找Kafka最新的安装教程吗?精细的安装步骤分享给大家...
Kafka集群部署 概述 之前的大数据集群主要是离线处理的方式对集群的数据进行开发处理.当前的集群数据量已经达到了PB级别了,离线数据获取主要是从数仓侧进行全量或者增量的方式导入大数据平台,部分是通过 ...
- Kafka Connect使用教程
1 kafka connect是什么 根据官方介绍,Kafka Connect是一种用于在Kafka和其他系统之间可扩展的.可靠的流式传输数据的工具.它使得能够快速定义将大量数据集合移入和移出Kafk ...
- Kafka Connect官网说明
文章目录 Kafka Connect Overview 运行Kafka Connect 配置 Connectors Transformations REST API Kafka Connect 原文地 ...
- debezium系列之:Kafka Connect
debezium系列之:Kafka Connect 一.Source和Sink 二.Task和Worker 三.Kafka Connect特性 四.独立模式 1.Source连接器的用法 2.Sink ...
最新文章
- 使用sourceInsight 提高代码编写效率
- eeglab中文教程系列(5)-提取数据epoch
- 设计模式 — 创建型模式 — 建造者模式
- 用Qt开发游戏时一些问题的解决方法(一)
- Java大神推荐,java编程基础必备(必看)
- ks minidriver 开发总结
- 【linux】spinlock 的实现
- onvif_discover虚拟摄像头
- 大型网站系统架构实践(五)深入探讨web应用高可用方案
- python partition by函数_python – 避免Spark窗口函数中单个分区模式的性能影响
- python圆面积函数_python函数题
- .NET Core + JWT令牌认证 + Vue.js 通用动态权限(RBAC)管理系统框架[DncZeus]开源啦!!!...
- 触发器-当表1插入数据时将表1的数据插入表2
- PAT-乙级-1035 插入与归并
- winform前后端框架_ABP开发框架前后端开发系列(1)框架的总体介绍
- 【故障诊断分析】基于matlab小波包能量分析轴承故障诊断【含Matlab源码 1620期】
- Y460蓝牙键盘无法连接问题解决
- java论文word_JAVA课程实践报告 基于web的点餐系统毕业设计word格式
- WIN10下系统缩放比例(DPI)的魔幻设置
- SpingBoot/JAVA实现给图片加水印功能(通过thumbnailator库)
热门文章
- java timer.schedule如何控制执行次数_Java 面试——JIT详解
- Ubiquant LGBM Baseline 九坤量化大赛 版本44
- Plus One @python
- IGMC,Inductive graph-based matrix completion,基于归纳图的矩阵完成
- 324.摆动排序II
- 222.完全二叉树的节点个数
- 决策树C4.5算法对ID3算法的改进
- oracle多边形经纬范围筛选_Oracle数据库之Oracle spatial空间查询的选择度分析
- 多视角子空间学习系列之 MCCA (Multi-view CCA) 多视角CCA Horst算法
- 信息安全收集注意事项