Doris 最佳实践-Compaction调优(3)

本文是 Compaction 调优系列文章的第三篇。在前两篇文章中我们介绍了Compaction的一些基本概念,以及Compaction选择策略和执行过程。本篇我们将从实际使用场景的角度出发,介绍 Compaction 的调优思路和策略。通过本文读者将了解到 Compaction 相关的日志分析、参数调整和 API 的使用。
Doris 最佳实践-Compaction调优(1)
Doris 最佳实践-Compaction调优(2)
## 什么情况下需要调整 Compaction 参数
Compaction 的目的是合并多个数据版本,一是避免在读取时大量的 Merge 操作,二是避免大量的数据版本导致的随机IO。并且在这个过程中,Compaction 操作不能占用太多的系统资源。所以我们可以以结果为导向,从以下两个方面反推是否需要调整 Compaction 策略。
检查数据版本是否有堆积。
检查 IO 和内存资源是否被 Compaction 任务过多的占用。
查看数据版本数量变化趋势
Doris 提供数据版本数量的监控数据。如果你部署了 Prometheus + Grafana 的监控,则可以通过 Grafana 仪表盘的 BE Base Compaction Score 和 BE Cumu Compaction Score 图表查看到这个监控数据的趋势图:
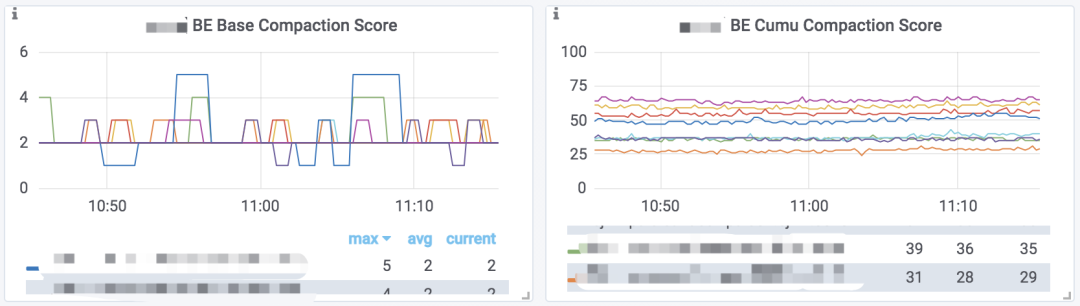
> 这个图表展示的是每个 BE 节点,所有 Tablet 中数据版本最多的那个 Tablet 的版本数量,可以反映出当前版本堆积情况。
> 部署方式参阅:http://doris.incubator.apache.org/master/zh-CN/administrator-guide/operation/monitor-alert.html
如果没有安装这个监控,如果你是用的 Palo 0.14.7 版本以上,也可以通过以下命令在命令行查看这个监控数据的趋势图:
mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_BASE_COMPACTION_SCORE", "time" = "last 4 hours");mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_CUMU_COMPACTION_SCORE", "time" = "last 4 hours");

> 该命令具体帮助可执行 HELP ADMIN SHOW METRIC 查看
注意这里有两个指标,分别表示 Base Compaction 和 Cumulative Compaction 所对应的版本数量。在大部分情况下,我们只需要查看 Cumulative Compaction 的指标,即可大致了解集群的数据版本堆积情况。
版本是否堆积没有一个明确的界限,而是根据使用场景和查询延迟进行判断的一个经验值。我们可以按照以下步骤进行简单的推断:
1. 观察数据版本数量的趋势,如果趋势平稳,则说明 Compaction 和导入速度基本持平。如果呈上升态势,则说明 Compaction 速度跟不上导入速度了。如果呈下降态势,说明 Compaction 速度超过了导入速度。如果呈上升态势,或在平稳状态但数值较高,则需要考虑调整 Compaction 参数以加快 Compaction 的进度。
2. 通常版本数量维持在 100 以内可以视为正常。而在大部分批量导入或低频导入场景下,版本数量通常为10-20甚至更低。
查看Compaction资源占用
Compaction 资源占用主要是 IO 和 内存。
对于 Compaction 占用的内存,可以在浏览器打开以下链接:
http://be_host:webserver_port/mem_tracker
在搜索框中输入 AutoCompaction:

则可以查看当前Compaction的内存开销和历史峰值开销。
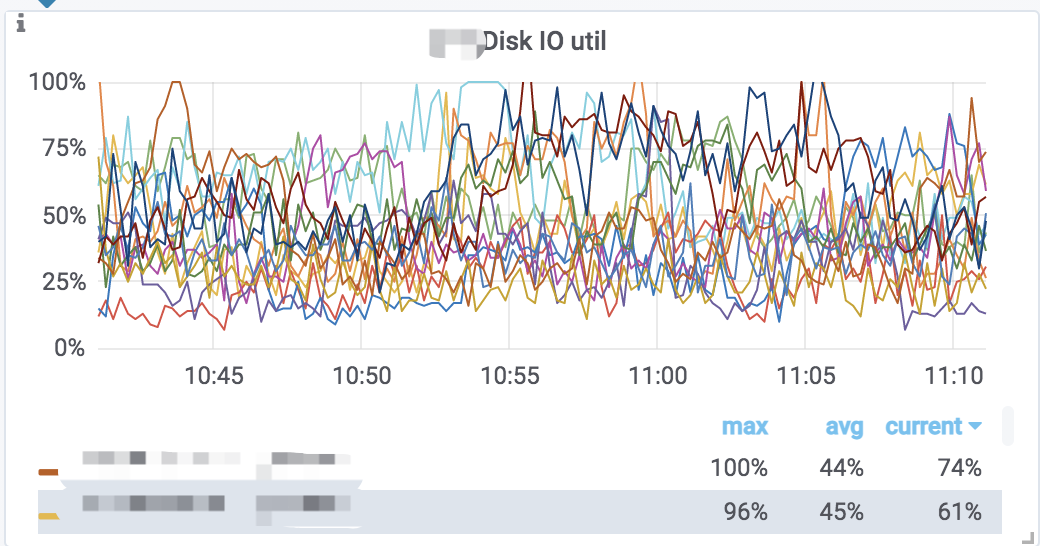
而对于 IO 操作,目前还没有提供单独的 Compaction 操作的 IO 监控,我们只能根据集群整体的 IO 利用率情况来做判断。我们可以查看监控图 Disk IO util:
或者通过命令在命令行查看(Palo 0.14.7 以上版本):
mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_DISK_IO", "time" = "last 4 hours");这个监控展示的是每个 BE 节点上磁盘的 IO util 指标。数值越高表示IO越繁忙。当然大部分情况下 IO 资源都是查询请求消耗的,这个监控主要用于指导我们是否需要增加或减少 Compaction 任务数。
## Compaction 调优策略
如果版本数量有上升趋势或者数值较高,则可以从以下两方面优化 Compaction:
1. 修改 Compaction 线程数,使得同时能够执行更多的 Compaction 任务。
2. 优化单个 Compaction 的执行逻辑,使数据版本数量维持在一个合理范围。
优化前的准备工作
在优化 Compaction 执行逻辑之前,我们需要使用一些命令来进一步查看一些Compaction的细节信息。
首先,我们通过监控图找到一个版本数量最高的 BE 节点。然后执行以下命令分析日志:
$> grep "succeed to do base" log/be.INFO.log.20210505-142010 |tail -n 100$> grep "succeed to do cumu" log/be.INFO.log.20210505-142010 |tail -n 100
以上两个命令可以查看最近100个执行完成的 compaction 任务:
I0505 17:06:56.143455 675 compaction.cpp:135] succeed to do cumulative compaction. tablet=106827682.505347040.d040c1cdf71e5c95-3a002a06127ccd86, output_version=2-2631, current_max_version=2633, disk=/home/disk6/palo.HDD, segments=57. elapsed time=2.29371s. cumulative_compaction_policy=SIZE_BASED.I0505 17:06:56.520058 666 compaction.cpp:135] succeed to do cumulative compaction. tablet=106822189.1661856168.654562832a620ea6-46fe84c73ea84795, output_version=2-3247, current_max_version=3250, disk=/home/disk2/palo.HDD, segments=22. elapsed time=2.66858s. cumulative_compaction_policy=SIZE_BASED.
通过日志时间可以判断 Compaction 是否在持续正确的执行,通过 elapsed time 可以观察每个任务的执行时间。
我们还可以执行以下命令展示最近100个 compaction 任务的配额(permits):
$> grep "permits" log/be.INFO |tail -n 100I0505 17:04:07.120920 667 compaction.cpp:83] start cumulative compaction. tablet=106827970.777011641.9c474de1b8ba9199-4addeb135d6834ac, output_version=2-2623, permits: 39I0505 17:04:13.898777 672 compaction.cpp:83] start cumulative compaction. tablet=106822777.1948936074.a44ac9462e79b76d-4a33ee39559bb0bf, output_version=2-3238, permits: 22
配额和版本数量成正比。
我们可以找到 permits 较大的一个任务对应的 tablet id,如上图permit 为 39 的任务的 tablet id 为 106827970,然后继续分析这个 tablet 的 compaction 情况。
通过 MySQL 客户端连接 Doris 集群后,执行:
mysql> show tablet 106827970;+--------------------------+-----------+---------------+-----------+---------+----------+-------------+----------+--------+----------------------------------------------------------------------------+| DbName | TableName | PartitionName | IndexName | DbId | TableId | PartitionId | IndexId | IsSync | DetailCmd |+--------------------------+-----------+---------------+-----------+---------+----------+-------------+----------+--------+----------------------------------------------------------------------------+| default_cluster:test | tbl1 | p20210505 | tbl1 | 3828954 | 63708800 | 106826829 | 63709761 | true | SHOW PROC '/dbs/3828954/63708800/partitions/106826829/63709761/106827970'; |+--------------------------+-----------+---------------+-----------+---------+----------+-------------+----------+--------+----------------------------------------------------------------------------+
然后执行后面的 SHOW PROC 语句,我们可以获得这个 tablet 所有副本的详细信息。其中 VersionCount 列表示对应副本的数据版本数量。我们可以选取一个 VersionCount 较大的副本,在浏览器打开 CompactionStatus 列显示的 URL,得到如下Json结果:
{"cumulative policy type": "SIZE_BASED","cumulative point": 18438,"last cumulative failure time": "1970-01-01 08:00:00.000","last base failure time": "1970-01-01 08:00:00.000","last cumulative success time": "2021-05-05 17:18:48.904","last base success time": "2021-05-05 16:14:49.786","rowsets": ["[0-17444] 13 DATA NONOVERLAPPING 0200000000b1fb8d344f83103113563dd81740036795499d 2.86 GB","[17445-17751] 1 DATA NONOVERLAPPING 0200000000b25183344f83103113563dd81740036795499d 68.61 MB","[17752-18089] 1 DATA NONOVERLAPPING 0200000000b2b9a2344f83103113563dd81740036795499d 74.52 MB","[18090-18437] 1 DATA NONOVERLAPPING 0200000000b32686344f83103113563dd81740036795499d 76.41 MB","[18438-18678] 1 DATA NONOVERLAPPING 0200000000b37084344f83103113563dd81740036795499d 53.07 MB","[18679-18679] 1 DATA NONOVERLAPPING 0200000000b36d87344f83103113563dd81740036795499d 3.11 KB","[18680-18680] 1 DATA NONOVERLAPPING 0200000000b36d70344f83103113563dd81740036795499d 258.40 KB","[18681-18681] 1 DATA NONOVERLAPPING 0200000000b36da0344f83103113563dd81740036795499d 266.98 KB",],"stale_rowsets": [],"stale version path": []}
这里我们可以看到一个 tablet 的 Cumulative Point,最近一次成功、失败的 BC/CC 任务时间,以及每个 rowset 的版本信息。如上面这个示例,我们可以得出以下结论:
1. 基线数据量大约在2-3GB,增量rowset增长到几十MB后就会晋升到BC任务区。
2. 新增rowset数据量很小,且版本增长较快,说明这是一个高频小批量的导入场景。
我们还可以进一步的通过以下命令分析指定 tablet id 的日志:
# 查看 tablet 48062815 最近十个任务的配额情况$> grep permits log/be.INFO |grep 48062815 |tail -n 10# 查看 tablet 48062815 最近十个执行完成的 compaction 任务$> grep "succeed to do" log/be.INFO |grep 48062815 |tail -n 10
另外,我们还可以在浏览器打开以下 URL,查看一个 BE 节点当前正在执行的 compaction 任务:
be_host:webserver_port/api/compaction/run_status
{"CumulativeCompaction": {"/home/disk2/palo": [],"/home/disk1/palo": ["48061239"]},"BaseCompaction": {"/home/disk2/palo": [],"/home/disk1/palo": ["48062815","48061276"]}}
这个接口可以看到每个磁盘上当前正在执行的 compaction 任务。
通过以上一系列的分析,我们应该可以对系统的 Compaction 情况有以下判断:
1. Compaction 任务的执行频率、每个任务大致的执行耗时。
2. 指定节点数据版本数量的变化情况。
2. 指定 tablet 数据版本的变化情况,以及 compaction 的频率。
这些结论将指导我们对 Compaction 进行调优。
修改 Compaction 线程数
增加 Compaction 线程数是一个非常直接的加速 Compaction 的方法。但是更多的任务意味着更大的 IO 和 内存开销。尤其在机械磁盘上,因为随机读写问题,有时可能单线程串行执行的效率会高于多线程并行执行。Doris 默认配置为每块盘两个 Compaction 任务(这也是最小的合法配置),最多 10 个任务。如果磁盘数量多于 5,在内存允许的情况下,可以修改 max_compaction_threads 参数增加总任务数,以保证每块盘可以执行两个 Compaction 任务。
对于机械磁盘,不建议增加每块盘的任务数。对于固态硬盘,可以考虑修改 compaction_task_num_per_disk 参数适当增加每块盘的任务数,如修改为 4。注意修改这个参数的同时可能还需同步修改 max_compaction_threads,使得 max_compaction_threads 大于等于 compaction_task_num_per_disk * 磁盘数量。
优化单个 Compaction 任务逻辑
这个优化方式比较复杂,我们尝试从几个场景出发来说明:
场景一:基线数据量大,Base Compaction 任务执行时间长。
BC 任务执行时间长,意味着一个任务会长时间占用 Compaction 工作线程,从而导致其他 tablet 的 compaction 任务时间被挤占。如果是因为 0 号版本的基线数据量较大导致,则我们可以考虑尽量推迟增量rowset 晋升到 BC 任务区的时间。以下两个参数将影响这个逻辑:
cumulative_size_based_promotion_ratio :默认 0.05,基线数据量乘以这个系数,即晋升阈值。可以调大这个系数来提高晋升阈值。
cumulative_size_based_promotion_size_mbytes :默认 1024MB。如果增量rowset的数据量大于这个值,则会忽略第一个参数的阈值直接晋升。因此需要同时调整这个参数来提升晋升阈值。
当然,提升晋升阈值,会导致单个 BC 任务需要处理更大的数据量,耗时更长,但是总体的数据量会减少。举个例子。基线数据大小为 1024GB,假设晋升阈值分别为 100MB 和 200MB。数据导入速度为 100MB/分钟。每5个版本执行一次 BC。那么理论上在10分钟内,阈值为 100MB 时,BC 任务处理的总数据量为 (1024 + 100 * 5)* 2 = 3048MB。阈值为 200MB 是,BC 任务处理的总数据量为 (1024 + 200 * 5) = 2024 MB。
场景二:增量数据版本数量增长较快,Cumulative Compaction 处理过多版本,耗时较长。
max_cumulative_compaction_num_singleton_deltas 参数控制一个 CC 任务最多合并多少个数据版本,默认值为 1000。我们考虑这样一种场景:针对某一个 tablet,其数据版本的增长速度为 1个/秒。而其 CC 任务的执行时间 + 调度时间是 1000秒(即单个 CC 任务的执行时间加上Compaction再一次调度到这个 tablet 的时间总和)。那么我们可能会看到这个 tablet 的版本数量在 1-1000之间浮动(这里我们忽略基线版本数量)。因为在下一次 CC 任务执行前的 1000 秒内,又会累积 1000 个版本。
这种情况可能导致这个 tablet 的读取效率很不稳定。这时我们可以尝试调小 max_cumulative_compaction_num_singleton_deltas 这个参数,这样一个 CC 所要合并的版本数更少,执行时间更短,执行频率会更高。还是刚才这个场景,假设参数调整到500,而对应的 CC 任务的执行时间 + 调度时间也降低到 500,则理论上这个 tablet 的版本数量将会在 1-500 之间浮动,相比于之前,版本数量更稳定。
当然这个只是理论数值,实际情况还要考虑任务的具体执行时间、调度情况等等。
## 手动 Compaction
某些情况下,自动 Compaction 策略可能无法选取到某些 tablet,这时我们可能需要通过 Compaction 接口来主动触发指定 tablet 的 Compaction。我们以 curl 命令举例:
curl -X POST http://192.168.1.1:8040/api/compaction/run?tablet_id=106818600\&schema_hash=6979334\&compact_type=cumulative这里我们指定 id 为 106818600,schema hash 为 6979334 的 tablet 进行 Cumulative Compaction(compact_type参数为 base 则触发 Base Compaction)。其中 schema hash 可以通过 SHOW TABLET tablet_id 命令得到的 SHOW PROC 命令获取。
如果提交成功,则会返回:
{"status": "Success", "msg": "compaction task is successfully triggered."}这是一个异步操作,命令只是提交compaction 任务,之后我们可以通过以下 API 来查看任务是否在运行:
curl -X GET http://192.168.1.1:8040/api/compaction/run_status?tablet_id=106818600\&schema_hash=6979334返回结果:
{"status" : "Success","run_status" : false,"msg" : "compaction task for this tablet is running","tablet_id" : 106818600,"schema_hash" : 6979334,"compact_type" : "cumulative"}
当然也可以直接查看 tablet 的版本情况:
curl -X GET http://192.168.1.1:8040/api/compaction/show?tablet_id=106818600\&schema_hash=6979334End
我们通过三篇文章系统的阐述了 Compaction 的原理和调优过程,希望能够帮助用户更好的维护 Doris 集群。Compaction 策略是 Doris 比较复杂的一个数据处理逻辑,需要考虑的状态和情况非常多,因此也在不断完善中,最终希望能够自动的适配各种负载场景,减轻用户的运维压力。
【往期回顾】
【Doris Weekly】2020.05.25~2021.06. 08
【Doris Weekly】2021.05.10~2021.05. 24
【Doris Weekly】2021.04.26~2021.05. 09
【精彩文章】
活动报名|Apache Doris x Apache Pulsar 联合Meetup - 北京站
Apache Doris Roadmap 2021
【Doris全面解析】 Doris Compaction 机制解析
欢迎关注:
Apache Doris(incubating)官方公众号
相关链接:
Apache Doris官方网站:
http://doris.incubator.apache.org
Apache Doris Githu b:
https://github.com/apache/incubator-doris
Apache Doris 开发者邮件组:
dev@doris.apache.org

本文分享自微信公众号 - ApacheDoris(gh_80d448709a68)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。
Doris 最佳实践-Compaction调优(3)相关推荐
- Doris 实践-Compaction调优 3
Apache Doris 代码仓库地址:apache/incubator-doris 欢迎大家关注加星 本文是 Compaction 调优系列文章的第三篇.在前两篇文章中我们介绍了Compaction ...
- DB2 最佳实践: 性能调优和问题诊断最佳实践
最佳实践的相关文章可见:http://www.ibm.com/developerworks/cn/data/bestpractices/ DB2 最佳实践: 性能调优和问题诊断最佳实践,第 1 部分 ...
- 【clickhouse】ClickHouse基础、实践、调优全视角解析
1.概述 ClickHouse基础.实践.调优全视角解析(part1-配置篇) ClickHouse基础.实践.调优全视角解析(part2-表引擎介绍) ClickHouse基础.实践.调优全视角解析 ...
- DB2 Workload Management 工作负载管理最佳实践
转自:http://www.ibm.com/developerworks/cn/data/library/techarticles/dm-0912db2workloadm/index.html 概要介 ...
- 基于ITIL的SCOM监控最佳实践
1. 按照系统类别进行监控 很多朋友在使用SCOM进行监控的时候,往往只是导入管理包,推送代理,并不会思考很多,那么在这种情况下,SCOM在进行监控的时候都是基于缺省的类对象进行监控,比如说Wind ...
- MindSpore模型精度调优实践
MindSpore模型精度调优实践 引论:在模型的开发过程中,精度达不到预期常常让人头疼.为了帮助用户解决模型调试调优的问题,为MindSpore量身定做了可视化调试调优组件:MindInsight. ...
- 【TUG 话题探讨003】TUG 专家们如何做 TiDB 性能调优
作者:luzizhuo 原文来源: https://tidb.net/blog/e25c02b8 9 月 16 日晚上 8 点,第三期技术话题探讨会在 TUG 群里如期而至,本次探讨会主要围绕 系统经 ...
- 数据与广告系列十五:商业兴趣标签建模XGboost调优实战
作者·黄崇远 『数据虫巢』 全文共8210字 题图ssyer.com " 聊聊商业兴趣标签建模,顺带学习下kaggle竞赛神器,快哉." 01 前言 我们来回想下,早在第是一篇&l ...
- 机器学习模型调优总结!
↑↑↑关注后"星标"Datawhale 每日干货 & 每月组队学习,不错过 Datawhale干货 作者:Xiaoyou Wang,编译:机器之心 无论是 Kaggle 竞 ...
最新文章
- 分享Hadoop处理大数据工具及优势
- mac云显卡服务器_重磅!NVIDIA GeForce NOW登陆Mac:云显卡玩吃鸡逆天
- 关于CSS属性display:none和visible:hidden的区别
- NumberOf1Bits(leetcode191)
- 爆款不是运气:网易产品布局背后的6大标准框架
- 在MATLAB function中可变的变量数据类型
- 首批拟科创板IPO名单今日揭晓!
- html里content标签作用,HTML content 标签
- Android开发笔记(四十五)手势事件
- loadrunner 服务器性能监控,Loadrunner 性能测试服务器监控指标
- 小爱同学app安卓版_小爱同学3.0版本下载-小爱同学3.0安装包下载v5.0.62 安卓最新版-2265安卓网...
- java练习题,个人所得税计算
- Halo2学习笔记——设计之Proof和Field实现(3)
- 怎么去除视频字幕清理视频字幕或水印的四种方法
- 2.中继镜(增距镜)详解
- 国产ETL etl-engine 星光不问赶路人 时我不待
- 第一次通过服务器远程跑代码
- lower_bound和upper_bound详解
- UE4中使用第三方库Ⅱ
- Mybatis中foreach的三种用法