Android面试题解(全)
Android
(一)RecyclerView 与 ListView 的主要区别:
- 使用
- 布局效果
- 局部刷新
- 嵌套滚动机制
- 布局效果对比
- 常用功能和API对比
- RecyclerView 和 ListView 在 Android L 引入嵌套滚动机制之后的对比
(1)简单使用
ListView:
- 继承重写BaseAdapter类
- 自定义 ViewHolder 和 convertView 一起完成复用优化工作(在自定义的ADP、adapter中完成)
RecyclerView:
- 继承重写RecyclerView.Adapter与RecyclerView.ViewHolder
- 在ViewHolder中传入View参数,获取布局实例findViewById()
- onCreateViewHolder()--------加载布局,创建ViewHolder实例
- onBindViewHolder()--------子项数据赋值
- getItemCount()-------子项数
- 设置LayoutManager,以及layout的布局效果
- LayoutManager-------LinearLayoutManager,GridLayoutManager,staggeredGridLayoutManager
(2)布局效果
**ListView:**布局单一,只有纵向效果
**RecyclerView:**布局效果丰富(3种);LayoutManager的API中自定义Layout:
(3)实现嵌套滚动机制
在事件分发机制中,Touch事件在进行分发的时候,由父View向子View传递,一旦子View消费这个事件的话,那么接下来的事件分发的时候,父View将不接受,由子View进行处理;但是与Android的事件分发机制不同,嵌套滚动机制(Nested Scrolling)可以弥补这个不足,能让子View与父View同时处理这个Touch事件,主要实现在于NestedScrollingChild与NestedScrollingParent这两个接口;而在RecyclerView中,实现的是NestedScrollingChild,所以能实现嵌套滚动机制;
ListView就没有实现嵌套滚动机制;
(4)局部刷新
**RecyclerView:**notifyItemChanged(),局部刷新
ListView:
notifyDataSetChanged() ,全局刷新(每个item的数据都会重新加载一遍),非常消耗资源;
如何实现局部刷新?
在adapter里定义一个方法notifyDataSetChangedAt(View view,int position),然后在该方法处理逻辑(自定义局部刷新方法)
public void notifyDataSetChangedAt(View view,int position) {if(view != null){int data = datas.get(position);data = data+1;datas.set(position,data);TextView textView = (TextView) view.findViewById(R.id.textview);textView.setText(String.valueOf(data));}} ———————————————— //在外部调用,实现调用 mListView.setOnItemClickListener(new AdapterView.OnItemClickListener() {@Overridepublic void onItemClick(AdapterView<?> parent, View view, int position, long id) {/*int data = datas.get(position);data = data+1;datas.set(position,data);adapter.notifyDataSetChanged();*/----->刷新全部数据adapter.notifyDataSetChangedAt(view,position);----》刷新局部数据} });
【扩展】:View的重新绘制过程(尝试引导话题)
onMeasure()–>onLayout()–>onDraw()
(二)View的工作流程
measure:
- View
- ViewGroup
layout:
- layout()
- onLayout()
draw:
draw()中调用的4个方法
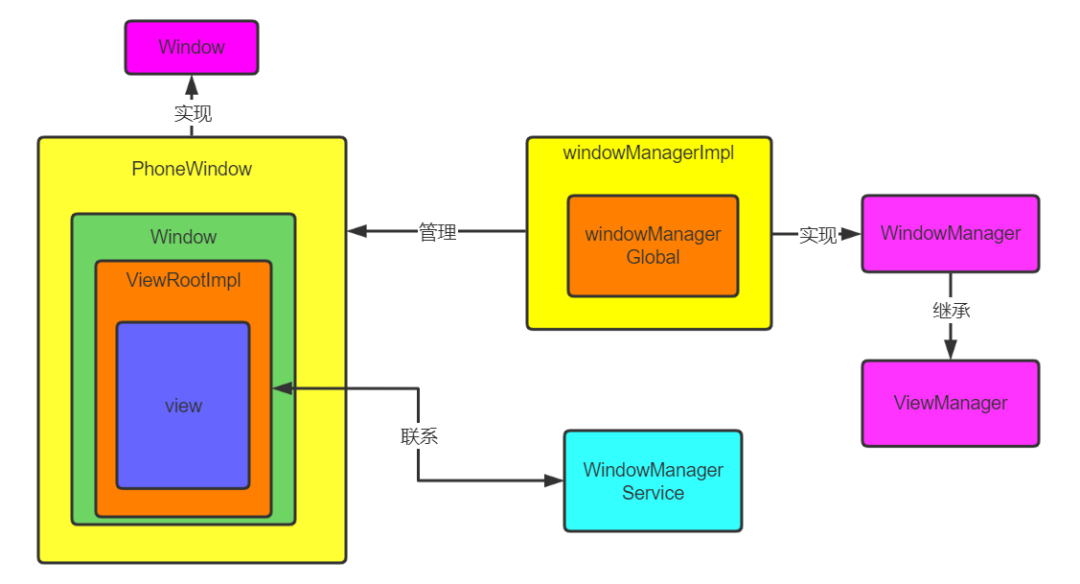
PhoneWindow是窗口类,继承自抽象类Window,也是唯一子类。WindowManager是Window管理接口,继承自ViewManager,他的唯一实现类是WindowManagerImpl。WindowManagerImpl并没有真正实现windowManager接口逻辑,而是把逻辑转给了WindowManagerGlobal,WindowManagerGlobal是全局单例。Window和View的联系通过ViewRootImpl桥梁,同时ViewRootImpl还负责管理view树、绘制view树、和WMS通信。WMS即WindowManagerService,是Window的真正管理类。
measure------->layout-------->draw
测量-------布局-------绘制
确定View的测量宽高
确定View的最终宽高和四个顶点的位置
将View绘制到屏幕上
measure:完成测量过程。由**(final型,不能重写)**measure()方法来完成
- View的measure()方法中会调用View的onMeasure()方法
- 如果是ViewGroup则会遍历调用所有的子元素的measure方法-----measureChildren()
- 对于ViewGroup来说,除了完成自己的measure过程,还会遍历去调用所有子元素的measure方法,各个子元素在递归去执行这个过程。和View不同的是,ViewGroup是一个抽象类,因此它没有重写View的onMeasure方法,但是他提供了一个叫measureChildren的方法。
Layout:作用:ViewGroup用来确定子元素的位置
- layout()方法确定View本身的位置
- 通过setFrame()方法设定View的四个顶点的位置
- 调用onLayout()方法:父容器确定子元素的位置
- onLayout()方法确定所有子元素的位置。(onLayout()是在layout()中被调用个)
- 在onLayout()方法中调用子元素的layout()方法
- 层层传递,则可完成整个View树的layout过程
- layout()方法确定View本身的位置
draw:将View绘制到屏幕上。
这4个方法全包括在draw()方法里面调用
- 绘制背景 drawBackground(canvas)
- 绘制自己( onDraw(canvas) )
- 绘制children(dispatchDraw(canvas) )
- dispatchDraw会层层遍历所有子元素的draw方法
- 绘制装饰(onDrawScrollerBars(canvas) )
View绘制的过程的传递通过dispatchDraw()来实现的,它会调用所有子元素的draw方法
那么发起绘制的入口在哪里呢?
在介绍发起绘制的入口之前,我们需要先了解Window,ViewRootImpl,DecorView之间的联系。
一个 Activity 包含一个Window,Window是一个抽象基类,是 Activity 和整个 View 系统交互的接口,只有一个子类实现类PhoneWindow,提供了一系列窗口的方法,比如设置背景,标题等。一个PhoneWindow 对应一个 DecorView 跟 一个 ViewRootImpl,DecorView 是ViewTree 里面的顶层布局,是继承于FrameLayout,包含两个子View,一个id=statusBarBackground 的 View 和 LineaLayout,LineaLayout 里面包含 title 跟 content,title就是平时用的TitleBar或者ActionBar,contenty也是 FrameLayout,activity通过 setContent()加载布局的时候加载到这个View上。ViewRootImpl 就是建立 DecorView 和 Window 之间的联系。
这三个阶段的核心入口是在 ViewRootImpl 类的 performTraversals() 方法中。绘制的入口是由ViewRootImpl的performTraversals方法来发起Measure,Layout,Draw等流程的。
private void performTraversals() {......int childWidthMeasureSpec = getRootMeasureSpec(mWidth, lp.width);int childHeightMeasureSpec = getRootMeasureSpec(mHeight, lp.height);......mView.measure(childWidthMeasureSpec, childHeightMeasureSpec);......mView.layout(0, 0, mView.getMeasuredWidth(), mView.getMeasuredHeight());......mView.draw(canvas);......}1. Measure
MeasureSpec的值由specSize和specMode共同组成的,其中specSize记录的是大小,specMode记录的是规格。
- 对于View默认是测量很简单,大部分情况就是拿计算出来的MeasureSpec的size 当做最终测量的大小
一个MeasureSpec封装了从父容器传递给子容器的布局要求,这个MeasureSpec 封装的是父容器传递给子容器的布局要求,而不是父容器对子容器的布局要求,“传递” 两个字很重要,更精确的说法应该这个MeasureSpec是由父View的MeasureSpec和子View的LayoutParams通过简单的计算得出一个针对子View的测量要求,这个测量要求就是MeasureSpec。
- 子View的LayoutParams其实就是我们在xml写的时候设置的layout_width和layout_height 转化而来的
父View的measure的过程会先测量子View,等子View测量结果出来后,再来测量自己,上面的measureChildWithMargins就是用来测量某个子View的
子View的LayoutParams:
- 具体大小(childDimension)
- match_parent
- wrap_content
MeasureSpec一共有三种模式 :
UPSPECIFIED : 父容器对于子容器没有任何限制,子容器想要多大就多大(说明父View大小是确定的)
EXACTLY: 父容器已经为子容器设置了尺寸,子容器应当服从这些边界,不论子容器想要多大的空间。
AT_MOST:子容器可以是声明大小内的任意大小(说明父View大小是不确定的)
(三)事件分发机制
- 三种方法的解析
- 具体流程分析(点击事件为例):图
- View处理事件优先级:3种的对比
- dispatchTouchEvent()-------分发事件
- onInterceptTouchEvent()--------判断是否拦截某个事件,如果当前View拦截了某个事件,那么在同一个事件序列中,此方法不会被再次调用,返回结果表示是否拦截当前事件。(只存在于ViewGroup中,为什么?)------->解释原因:结合传递顺序
- 如果拦截事件,则调用onTouchEvent()来处理点击事件。
- 不拦截-----> child.dispatchTouchEvent()
- 在 ViewGroup 的dispatchTouchEvent()内部调用
- onTouchEvent()-------处理点击事件,在dispatchTouchEvent()中调用,返回结果表示是否消耗当前事件。
//这个是伪代码表示,并不是实际的代码!!!!!
public boolean dispatchTouchEvent(MotionEvent ev) {boolean consume = false;if(onInterceptTouchEvent(ev)){ //拦截事件consume = onTouchEvent(ev);} else { //不拦截事件consume = child.dispatchTouchEvent(ev);}return consume;
}
![]()
点击事件的传递过程:
Activity ----> ViewGroup----> View
顶级View接收到事件后,就会按照事件分发机制区分发事件。
![]()
对比上面的例子,Activity对应的就是项目经理,viewGroup就是你的老大,而你就相当于view了;
**Activity和View是没有onInterceptTouchEvent()**事件拦截这个方法的?
Activity是处于分发机制的最顶端,如果一开始就把事件拦截了,那么会导致整个屏幕都无法响应用户的操作
而view处于事件分发的最末端,它不需要拦截,事件分发到View的时候,view能处理就处理,不处理就返回给他的父控件;
流程分析,以点击事件为例:
当用户点击了屏幕,首先Activity先监测到,事件先传递到Activity中,Activity通过它的dispatchTouchEvent将事件分发到phoneWindow,phonewindow则会调用superdispatchTouchEvent方法(抽象方法)的内部是调用了其内部类DecorView,而DecorView又会调用dispatchTouchEvent去进行事件分发,如果不拦截事件,那么就会继续下传到rootview**(ViewGroup),rootview中的操作是一样的,同样在dispatchTouchEvent内部调用onInterceptTouchEvent去判断是否拦截**(讨论),不拦截就会把事件分发给下一个viewgroupA,拦截就直接在onTouchEvent返回true,viewgroupA中做的判断也是一样,最后事件传递到view1,view1是最底层控件,不会有onInterceptTouchEvent,它的选择就只有处理或不处理(讨论),处理就在onTouchEvent进行处理并返回true,不处理的话事件也不会被销毁,view1这时会把事件回传,经过上述流程后回传给activity,如果Activity还不处理,那么这个事件才会被销毁。
![]()
**【补充】**回答后面加粗的2,3,4
View处理事件优先级
OnTouchListener 【onTouch()】 > onTouchEvent()方法 > OnClickListener【onClick()】
OnTouchListener中有onTouch()方法
OnClickListener中有onClick()方法
先说onTouchEvent与setOnTouchListener中onTouch的区别
其逻辑可参看下面伪代码
public boolean dispatchTouchEvent(MotionEvent event){if(mOnTouchListener != null && mOnTouchListener.onTouch(this,event)){return true;}return onTouchEvent(event);
}
结合上面代码的含义与事件分发机制得出以下结论
(1)dispatchTouchEvent(MotionEvent event)返回true,表示本次事件被消耗,然后会有新事件传入。若返回false则不会有新事件传入。
(2)mOnTouchListener.onTouch方法返回的是true,onTouchEvent将不被执行。只有前者返回false,后者才会执行.
(3)只要onTouchEvent方法中的DOWN与UP事件都执行了,就会执行setOnClickListener中的onClick或者回调View.onClick,只是后者优先执行。
(4)总体优先级 setTouchListener > onTouchEvent > onClick > setClickListener
注意:DOWN或UP就是一个事件,不是DOWM+MOVE+UP才是一个事件,加起来是我们称作一系列事件
重写onTouchEvent时千万别删了super.onTouchEvent(event)——本人手贱,为此付出过惨痛代价。
可见是首先执行OnTouchListener,之后为onTouchEvent,最后才执行onClickListener内的方法
至于为什么OnTouchListener和onTouchEvent执行了两次,onClick()执行力一次
- 是因为在DOWN和UP时两个方法都被调用
- 至于onClickListener则只在UP的时候调用
(四)Android的Handler机制
看字节一面复盘
- 使用Handler的原因
- Handler4个组成部分解析
- Handler流程:
- 主线程创建Handler实例MHandler
- 子线程中保存创送的消息到message
- 子线程调用MHandler 的sendMessage()
- message添加到MessageQueue
- Looper循环获取message送至Handler的handlerMessage()中处理
1.使用Handler机制的原因
Handler------异步消息处理机制
Android的UI控件是非线程安全的,更新UI必须在主线程中,否则会有异常。但我们需要在子线程中执行一些耗时任务,然后根据任务结果来更新UI。Android中提供了一套消息异步处理机制,完美解决在子线程中进行UI操作的问题。
Handler创建时会采用当前线程的Looper来构建内部的消息循环系统,如果当前线程无Looper,则会报错
- 解决方法:在当前线程创建Looper
- 或者在一个有Looper的线程中创建Looper
4个组成部分:
- Message:线程间传递的消息
- Handler(处理者)
- sendMessage()-----------发送消息
- 消息经过辗转处理,最终会传递给Handler 的 handleMessage(到达主线程)---------处理消息
- MessageQueue:存放Message队列
- Handler的send方法被调用后,它会调用MessageQueue的enqueueMessage方法将这个消息放入消息队列
- 每个线程只有一个MessageQueue
- Looper (消息队列管家):Looper发现有新消息到来时,就会处理这个消息
- loop()
- 每个线程只有一个looper
- 最终消息中的Runnable或者Handler的handleMessage方法就会被调用
- 从而实现线程之间的通信
流程
主线程创建一个Handler对象,重写handleMessage()方法
(当子线程需要进行UI操作时)
- 创建一个Message对象----保存要传递的消息
- 通过Handler的sendMessage()方法发出消息---------在子线程中获取Handler实例来发送消息
- Handler的post方法将一个Runnable投递到Handler内部的Looper中处理
- 或者通过Handler的send方法发送一个消息,这个消息同样会在Looper中去处理
- post方法最终也是通过send方法发送一个消息
这条message被添加到MessageQueue中等待处理
- Looper一直尝试从MessageQueue中取出Message
- 并分发会Handler的handleMessage()方法中**(主线程)**----->从而实现线程间通信
消息的延时处理
https://www.jianshu.com/p/edf4f5ee0057/
MessageQueue是按照Message触发时间的先后顺序排列的,队头的消息是将要最早触发的消息。排在越前面的越早触发,那我们现在应该了解到了,这个所谓的延时呢,不是延时发送消息,而是延时去处理消息,我们在发消息都是马上插入到消息队列当中。
可以看到,在这个方法内,如果头部的这个Message是有延迟而且延迟时间没到的(now < msg.when),会计算一下时间(保存为变量nextPollTimeoutMillis),然后在循环开始的时候判断如果这个Message有延迟,就调用nativePollOnce(ptr, nextPollTimeoutMillis)进行阻塞。nativePollOnce()的作用类似与object.wait(),只不过是使用了Native的方法对这个线程精确时间的唤醒。
1、postDelay()一个10秒钟的Runnable A、消息进队,MessageQueue调用nativePollOnce()阻塞,Looper阻塞;
2、紧接着post()一个Runnable B、消息进队,判断现在A时间还没到、正在阻塞,把B插入消息队列的头部(A的前面),然后调用nativeWake()方法唤醒线程;
3、MessageQueue.next()方法被唤醒后,重新开始读取消息链表,第一个消息B无延时,直接返回给Looper;
4、Looper处理完这个消息再次调用next()方法,MessageQueue继续读取消息链表,第二个消息A还没到时间,计算一下剩余时间(假如还剩9秒)继续调用nativePollOnce()阻塞;直到阻塞时间到或者下一次有Message进队;
(五)滑动冲突场景:用一个实际场景让我分析如何解决滑动问题
多看外部拦截法
了解内部拦截法
场景1:外部滑动方向和内部滑动方向不一致
场景2:外部滑动方向和内部滑动方向一致
场景3:上面两种情况的嵌套
ViewPager内部处理了这和机制【引申到ViewPager的介绍问题,TODO 看一下源码】
【重写FrameLayout(父View或子View)的onInterceptTouchEvent,来处理什么时候需要拦截什么时候不需要拦截】
修改需要拦截事件的条件
场景1:外部滑动方向和内部滑动方向不一致
处理原则:根据滑动是水平还是竖直的来判断有谁拦截事件
- 当用户左右滑动时,需要让外部的View拦截点击事件
- 当用户上下滑动时,需要让内部的View拦截点击事件
- 滑动方向:根据水平方向和竖直方向上的距离差来判断(或者夹角,速度差)
外部拦截法
点击事件都先经过父容器的拦截处理,如果父容器需要此事件就拦截,如果不需要此事件就不拦截。(比较符合点击事件的分发机制)
- 重写父容器的OnInterceptTouchEvent(),在内部做出相应的拦截即可
- ACTION_DOWN----------这个事件必须返回false,不拦截(父容器一旦开始拦截,那么后续的时间都会交给它处理),如果拦截,就会导致子元素无法收到ACTION_UP事件,????
- ACTION_MOVE-----------这个事件根据具体情况决定是否拦截
- ACTION_UP ---------------必须返回false,因为ACTION_UP事件本身没有多大意义。如果父容器返回true,就会导致子元素无法接收到ACTION_UP事件,这个时候onClick事件就无法触发。
内部拦截法
父容器不拦截任何事件,所有事件都传递给子元素,如果子元素需要此事件就直接消耗掉,否则就交给父容器处理。(与Android事件分发机制不一样)
- 重写子元素的dispatchTouchEvent()
- 父元素不能拦截ACTION_DOWN----------这个事件必须返回false,不拦截(父容器一旦开始拦截,那么后续的时间都会交给它处理),如果拦截,就会导致子元素无法收到ACTION_UP事件
- 父容器默认拦截ACTION_MOVE和ACTION_UP事件,这样只有当子元素调用了parent.requestDisallowTouchEvent(),父元素才能拦截所需的事件。
场景
一个类似于ViewPager的自定义控件,有一个可以水平滑动的类似于LinearLayout的东西,内部有一个ListView
外部拦截法:(推荐使用,比较简单)
重写onInterceptTouchEvent():
- 在滑动过程中,水平距离更大时判断为水平滑动,父容器拦截事件
- 竖直距离更大时父容器不拦截事件,将事件传递给ListView
内部拦截法:
(六)Android进程间通信的几种方式
- Intent—Bundle
- 文件共享
- Messenger
- AIDL
- ContenProvider
- Socket套接字
定义多进程
Android中多进程是指一个应用中存在多个进程的情况。
在AndroidMenifest.xml中给四大组件指定 android:process = “”;属性(或通过JNI在native层fork一个新的进程)
默认进程名是包名。
私有进程。进程名以 “:”开头的
全局进程。进程名不以 “:”开头的。
其他应用通过ShareUID方式和它跑在同一个进程中(相同ShareUID,相同签名)
进程间通信—IPC
Inter-Process Communication 进程间通信或跨进程通信
- 使用Bundle传递数据:Intent
可传递基本类型,实现了Serializable或Parcellable接口的数据结构等。Serializable是Java的序列化方法,Parcellable是Android的序列化方法,前者代码量少(仅一句),但I/O开销较大,一般用于输出到磁盘或网卡;后者实现代码多,效率高,一般用户内存间序列化和反序列化传输。
文件共享:
对同一个文件先后写读,从而实现传输,Linux机制下,可以对文件并发写,所以要注意同步。顺便一提,Windows下不支持并发读或写。
Messenger:
Messenger是基于AIDL实现的,服务端(被动方)提供一个Service来处理客户端(主动方)连接,维护一个Handler来创建Messenger,在onBind时返回Messenger的binder。
双方用Messenger来发送数据,用Handler来处理数据。Messenger处理数据依靠Handler,所以是串行的,也就是说,Handler接到多个message时,就要排队依次处理。
AIDL:
AIDL通过定义服务端暴露的接口,以提供给客户端来调用,AIDL使服务器可以并行处理,而Messenger封装了AIDL之后只能串行运行,所以Messenger一般用作消息传递。
通过编写aidl文件来设计想要暴露的接口,编译后会自动生成相应的java文件,服务器将接口的具体实现写在Stub中,用iBinder对象传递给客户端,客户端bindService的时候,用asInterface的形式将iBinder还原成接口,再调用其中的方法。
ContentProvider:
系统四大组件之一,底层也是Binder实现,主要用来为其他APP提供数据,可以说天生就是为进程通信而生的。自己实现一个ContentProvider需要实现6个方法,其中onCreate是主线程中回调的,其他方法是运行在Binder之中的。自定义的ContentProvider注册时要提供authorities属性,应用需要访问的时候将属性包装成Uri.parse(“content://authorities”)。还可以设置permission,readPermission,writePermission来设置权限。 ContentProvider有query,delete,insert等方法,看起来貌似是一个数据库管理类,但其实可以用文件,内存数据等等一切来充当数据源,query返回的是一个Cursor,可以自定义继承AbstractCursor的类来实现。
Socket:
学过计算机网络的对Socket不陌生,所以不需要详细讲述。只需要注意,Android不允许在主线程中请求网络,而且请求网络必须要注意声明相应的permission。然后,在服务器中定义ServerSocket来监听端口,客户端使用Socket来请求端口,连通后就可以进行通信。
![]()
【Messenger扩展】
对AIDL做了封装,一次处理一个请求,因此在服务端不需要考虑线程同步的问题,这是因为服务端中不存在并发执行情况
服务端进程
在服务端创建一个Service来处理客户端的请求
创建一个Handler并通过它来创建一个Messenger对象
public static class MessageHandler entends Service{...private static class MessengerHandler entends Handler {重写HandlerMessage方法} }
Service在onBind中返回这个Messenger对象底层的Binder即可
客户端进程
- 绑定服务端Service**【服务端会返回一个Binder对象】**
- 绑定成功后用服务端返回的IBinder对象创建一个Messenger,通过这个Messenger就可以向服务端发送消息了(消息类型为Message对象)
- 如果需要服务端能回复客户端:
- 在客户端创建一个Handler并通过它来创建一个Messenger对象
- 把这个Messenger对象通过Message的replyTo参数传递给服务端
- 服务端通过这个replyTo参数就可以回应客户端
在Messenger中进行数据传递必须将数据放入Message中,而Messenger和Message都实现了Parcelable接口,因此可以跨进程传输
Message能使用的载体只有5个:
what,arg1,arg2,Bundle以及replyTo
【服务端自动回复客户端】类似于邮箱的自动服务功能
- 服务端修改MessengerHandler对象(extends Handler)—自动回复
- 客户端准备一个接收消息的Messenger与Handler
- 在客户端发送消息的时候,需要把【接收服务端回复消息的】Messenger通过Message的replyTo参数传给服务端
(七)【AIDL扩展】

如要使用 AIDL 创建绑定服务,请执行以下步骤:
创建 .aidl 文件
此文件定义带有方法签名的编程接口。
实现接口
Android SDK 工具会基于您的
.aidl文件,使用 Java 编程语言自动生成接口。此接口拥有一个名为Stub的内部抽象类,用于扩展Binder类并实现 AIDL 接口中的方法。您必须扩展Stub类并实现这些方法。向客户端公开接口
实现
Service并重写onBind(),从而返回Stub类的实现。
- AIDL接口的创建
创建后缀为.AIDL的文件,在里面声明一个接口和两个方法
(AIDL只支持方法,不支持声明静态变量)
远程服务端Service的实现
- 实现接口(参考上面)
- 向客户端公开接口:实现
Service并重写onBind(),从而返回Stub类的实现。
public class BookManager extends Service {...private Binder mBinder = new IBookManager.Stub(){//2.实现接口这里是那两个接口里面方法的实现}@Overridepublic IBinder onBind(Intent intent) { //3.向客户端公开接口return mBinder;} }客户端的实现
- 绑定远程服务
- 绑定成功后将服务端返回的Binder对象转换成AIDL接口
- 用bookManager调用接口的方法
public class BookManagerActivity extends Activity {private ServiceConnection mConnection = new ServiceConnection() {@Overridepublic void onServiceConnected(ComponentName className,IBinder service) {IbookManager bookManager = IBookManager.Stub.asInterface(service);List<Book> list = bookManager.getBookList();}@Overridepublic void onServiceDisconnected(ComponentName arg0) {...}};@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.main);Intent intent = new Intent(this,BookManagerService.class);bindService(intent,mConnection,Context.BIND_AUTO_CREATE);}@Overrideprotected void onDestory() {unbindService(mConnection);super.onDestory();}}
(八)Binder 粘合剂
Binder主要用在Service中包括AIDL与Messager
**AIDL:**Android Interface Definition Language
![]()
TODO:今天不想写 待补充
(九)ANR
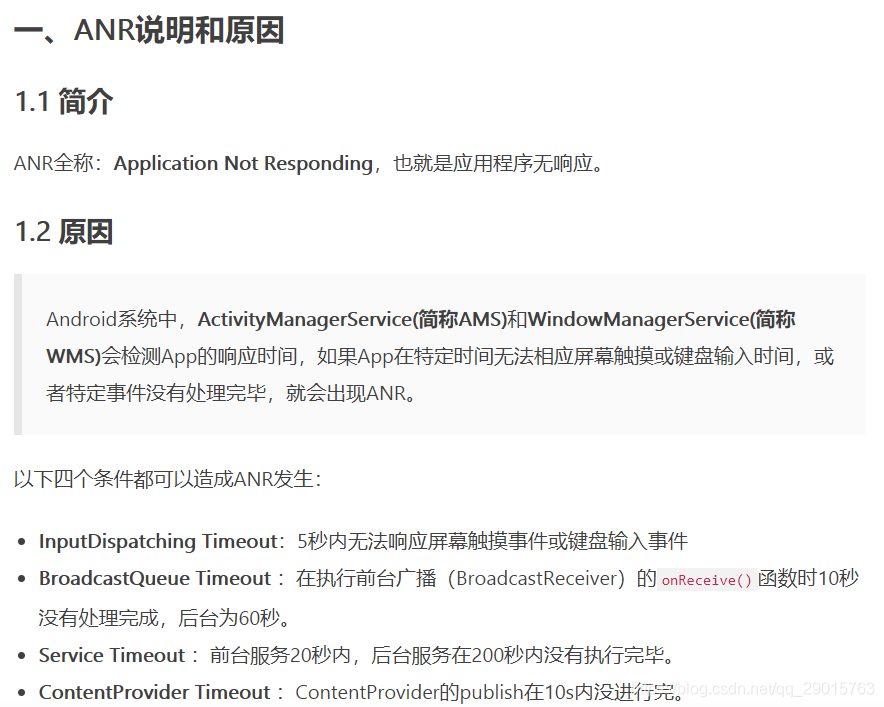

如何避免ANR
UI线程尽量只做跟UI相关的工作;
耗时的工作(比如数据库操作,I/O,连接网络或者别的有可能阻碍UI线程的操作)把它放入单独的线程处理;
尽量用Handler来处理UI thread和别的thread之间的交互;
实在绕不开主线程,可以尝试通过Handler延迟加载;
广播中如果有耗时操作,建议放在IntentService中去执行,或者通过goAsync() + HandlerThread分发执行。
分析ANR的重点
cpu占用率方面:
可以通过分析各进程的CPU时间占用率,来判断是否为某些进程长期占用CPU导致该进程无法获取到足够的CPU处理时间,而导致ANR重点关注下CPU的负载,各个进程总的CPU时间占用率,用户CPU时间占用率,核心态CPU时间占用率,以及iowait CPU时间占用率。内存方面
主要看当前应用native和dalvik层内存使用情况,结合系统给每个应用分配的最大内存来分析。
(十)OOM----OutOfMemoryError
https://www.runoob.com/w3cnote/android-oom.html
1.为什么会有OOM?
因为android系统的app的每个进程或者每个虚拟机有个最大内存限制,如果申请的内存资源超过这个限制,系统就会抛出OOM错误。跟整个设备的剩余内存没太大关系。
2.1 Android的APP内存组成:
APP内存由 dalvik内存 和 native内存 2部分组成,dalvik也就是java堆,创建的对象就是就是在这里分配的,而native是通过c/c++方式申请的内存,Bitmap就是以这种方式分配的。(android3.0以后,系统都默认通过dalvik分配的,native作为堆来管理)。这2部分加起来不能超过android对单个进程,虚拟机的内存限制。
每个手机的内存限制大小是多少?-------虚拟机的最大内存资源。
ActivityManager activityManager = (ActivityManager)context.getSystemService(Context.ACTIVITY_SERVICE)
activityManager.getMemoryClass();
2.2 为什么android系统设定APP的内存限制?
1 要使开发者内存使用更为合理。 限制每个应用的可用内存上限,可以放置某些应用程序恶意或者无意的使用过多的内存。而导致其它应用无法正常运行。Android是有多进程的,如果一个进程(就是一个应用)耗费过多的内存,其他应用就无法运行了。因为有了限制,使得开发者必须好好利用有限资源,优化资源的使用。
2 屏幕显示内容有限,内存足够即可。 即使有万千图片千万数据需要使用到,但在特定时刻需要展示给用户看的总是有限的,因为屏幕显示就那么大,上面可以放的信息就是很有限的。大部分信息都是处于准备显示状态,所以没必要给予太多heap内存。也就是说出现 OOM现象,绝大部分原因是我们的程序设计上有问题,需要优化 。优化方法很多,比如通过时间换空间,不停的加载要用的的图片,不停的回收不用的图片,把大图片解析成适合手机屏幕大小的图片等。
3 多APP多个虚拟机davlik的限制需要。 android上的app使用独立虚拟机,每开一个应用就会打开至少一个独立的虚拟机。这样可以避免虚拟机崩溃导致整个系统崩溃,同时代价就是需要浪费更多的内存。这样设计保证了android的稳定性。
2.3 不是GC自动回收资源么,为什么还会OOM?
Android不是用GC会自动回收资源么,为什么app的那些不用的资源不回收呢?
Android的gc会按照特定的算法回收程序不用的内存资源,避免app的内存申请约积越多,但是gc一般回收的资源是那些无主的对象内存或者软引用的资源,或者更软引用的引用资源。比如:
Bitmap bt = BitmapFactory.decodeResource( this .getResources(), R.drawable.splash); //此时的图片资源是强引用,是有主的资源。
bt = null ; //此时这个图片资源就是无主的了。gc心情号的时候就会去回收它。
SoftReference<Bitmap> softRef = new SoftReference<Bitmap>(bt);
bt = null ;
其他代码...
当程序申请很多内存资源时,gc有可能会释放softref引用的这个图片内存。bt=softRef.get(),此时可能得到的是null,需要重新加载图片。
当然这也说明了用软引用图片资源的好处,就是gc会自动根据需要释放资源,一定程度上避免OOM。
TIPS:编程要养成习惯,不用的对象设置为null。其实更好的是**,不用的图片直接recycle**。因为通过设置null让gc来回收,有时候还是会来不及。
(11)Android几种进程
前台进程: 即与用户正在交互的Activity或者Activity用到的Service等,如果系统内存不足时前台进程是最后被杀死的
**可见线程:**可以是处于暂停状态(onPause)的Activity或者绑定在其上的Service,即被用户可见,但由于失去了焦点而不能与用户交互
**服务进程:**其中运行着使用startService方法启动的Service,虽然不被用户可见,但是却是用户关系的,例如用户正在非音乐界面听的音乐或者正在非下载页面自己下载的文件等,当系统要用空间运行前两者进程时才会被终止
**后台进程:**其中运行着执行onStop方法而停止的程序,但是却不是用户当前关心的,例如后台挂着的QQ,这样的进程系统一旦没有内存就首先被杀死。
**空进程:**不包含任何应用程序的程序组件的进程,这样的进程系统是一般不会让他存在的。
如何避免后台进程被杀死?
调用startForegound,让你的Service所在的进程成为前台进程
Service的onStartCommand返回START_STICKY或START_REDELIVER_INTENT
Service的onDestroy里面重新启动自己
(12)单例模式
Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在
1、将该类的构造方法定义为私有方法,这样其他处的代码就无法通过调用该类的构造方法来实例化该类的对象,只有通过该类提供的静态方法来得到该类的唯一实例;
2、在该类内提供一个静态方法,当我们调用这个方法时,如果类持有的引用不为空就返回这个引用,如果类保持的引用为空就创建该类的实例并将实例的引用赋予该类保持的引用。在类初始化时实例话,通过一个public static的getInstance方法获取对它的引用,继而调用其中的方法。
3、它有一个static的private的该类变量
定义一个类,它的构造函数为private的,所有方法为static的。
//懒汉式线程安全:
public class Single {private static Single instance;private Single(){};//构造方法为私有方法public static synchronized Single getInstance(){if(instance == null) {instance = new Single();}return instance;}
}//饥汉模式:* 优点:当类被加载的时候,已经创建好了一个静态的对象,因此,是线程安全的; * 缺点:这个对象还没有被使用就被创建出来了。
public class HungrySingleton {// 私有化静态成员变量,已初始化private static HungrySingleton test = new HungrySingleton();// 私有化构造方法private HungrySingleton() {}// 提供一个公共的接口供外界获得单例对象// 不需要同步(类加载时已经初始化,不存在多线程的问题)// 始终只有一个对象public static HungrySingleton getInstance() {return test;}
}
【问题】synchronize的底层实现
Synchronized使用场景:
//修饰实例方法,对当前实例对象this加锁
public class Synchronized {public synchronized void husband(){}
}//修饰静态方法,对当前类的Class对象加锁
public class Synchronized {public void husband(){synchronized(Synchronized.class){}}
}//修饰代码块,指定一个加锁的对象,给对象加锁
public class Synchronized {public void husband(){synchronized(new test()){}}
}
其实就是锁方法、锁代码块和锁对象,那他们是怎么实现加锁的呢?
- 修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁
- 修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁
- 修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
![]()
Synchronized 原理
实现原理: JVM 是通过进入、退出 对象监视器(Monitor) 来实现对方法、同步块的同步的,而对象监视器的本质依赖于底层操作系统的 互斥锁(Mutex Lock) 实现。
具体实现是在编译之后在同步方法调用前加入一个monitor.enter指令,在退出方法和异常处插入monitor.exit的指令。
其本质就是对一个对象监视器( Monitor )进行获取,而这个获取过程具有排他性从而达到了同一时刻只能一个线程访问的目的。
对于没有获取到锁的线程将会阻塞到方法入口处,直到获取锁的线程monitor.exit之后才能尝试继续获取锁。
![]()
![]()
Synchronized 优化(底层还是不太懂!!!)----->直接看《深入理解Java虚拟机》
3.1 偏向锁
引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗)。
3.2 轻量锁
轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用产生的性能消耗。
3.3 其他优化
适应性自旋:在使用CAS时,如果操作失败,CAS会自旋再次尝试。由于自旋是需要消耗CPU资源的,所以如果长期自旋就白白浪费了CPU。JDK1.6 加入了适应性自旋,即如果某个锁自旋很少成功获得,那么下一次就会减少自旋。
4.2 Synchronized 与 ThreadLocal 的对比
Synchronized 与 ThreadLocal(有关ThreadLocal的知识会在之后的博客中介绍)的比较:
- Synchronized关键字主要解决多线程共享数据同步问题;ThreadLocal主要解决多线程中数据因并发产生不一致问题。
- Synchronized是利用锁的机制,使变量或代码块只能被一个线程访问。而ThreadLocal为每一个线程都提供变量的副本,使得每个线程访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。
(13)启动模式
standard。标准模式-----每次启动都会重新创建新的实例,不管这个实例是否存在。
- 谁启动了这个activity,那么这个activity就运行在启动它的那个activity所在的栈中。eg:Activity_A启动了Activity_B(B是Standard模式),那么B就会进入A所在的栈中。(oncreate, onStart, onResume都会被调用)
singleTop。栈顶复用模式-----如果新Activity已经位于任务栈的栈顶(若不在栈顶则重新创建),那么此Activity不会被重新创建,同时它的onNewIntent()方法会被重调。(onCreate()和onStart()不会被调用)
singleTask。栈内复用模式–----一种单例模式,【程序主界面一般用SingleTask模式】
- 只要Activity在栈中存在,那么多次启动此Activity都不会重新创建实例。
- 默认有clearTop功能,会导致栈内所有在D之上的Activity全部出栈
singleInstance。单实例模式
加强的singleTask模式
此种模式的activity只能单独位于一个任务栈中。
eg:如果Activity A是singleInstance模式,当A启动后,系统会为它创建一个新的任务栈,然后A独自在这个新的任务栈中,由于栈内复用的特性,后续请求均不会创建新的Activity,除非这个独特的任务栈被系统销毁
如何设置启动模式
- AndroidMainfest.xml中指定android:launchModel = “singleTask”;
- 在Intent中设置标志位来位Activity指定启动模式。优先级更高
【问题1】 Activity A 启动模式为 singleTask
Activity B 启动模式为常规模式
问A 启动 B,B 又启动 A 的生命周期调用顺序?
**要结合任务栈来分析:**先调用onPause(),新activity创建,调用就activity的onStop()
(图错误,A的最后一个Create不需要,直接从start()开始)
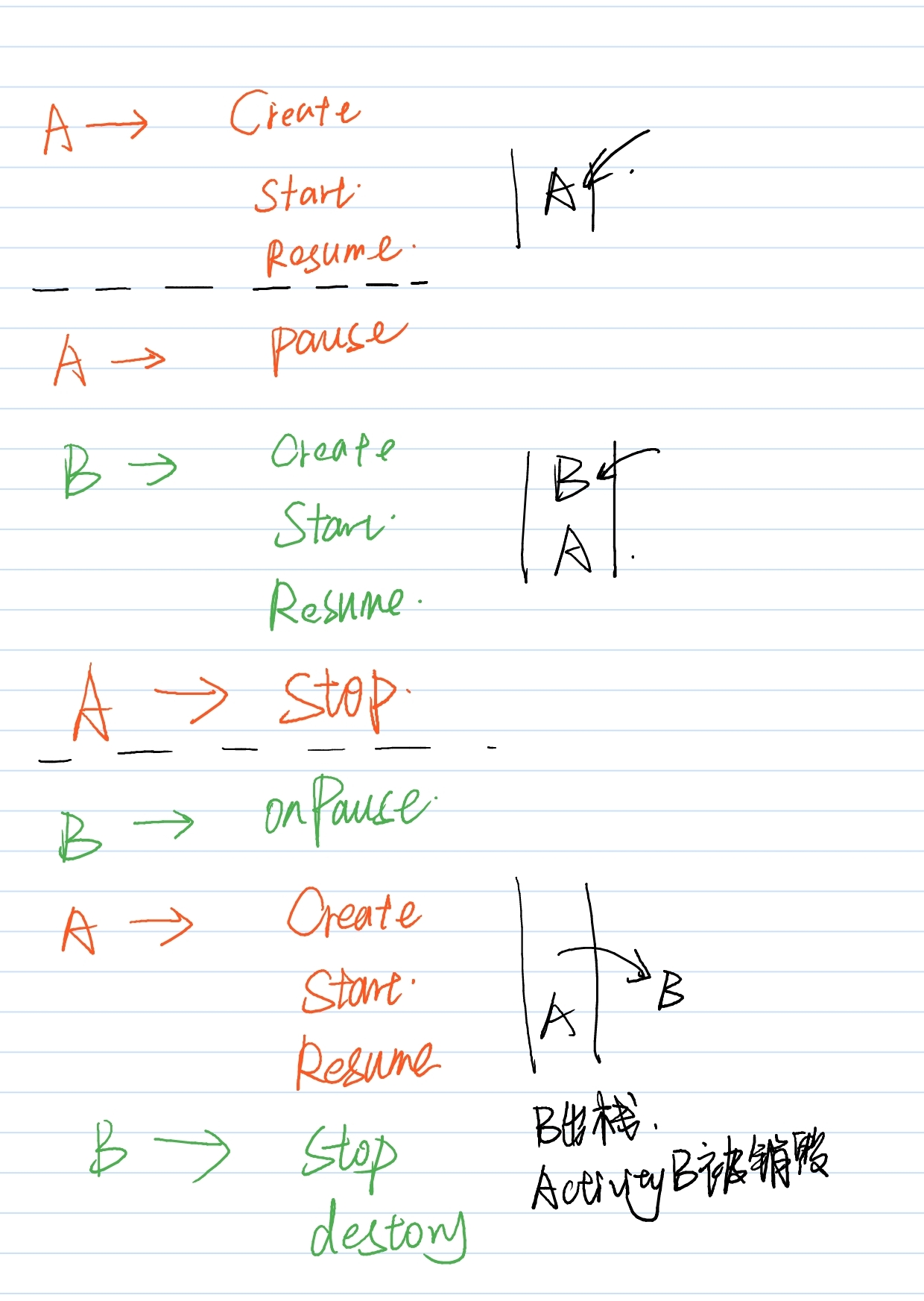
https://blog.csdn.net/zy_jibai/article/details/80587083 (启动模式)
(14)生命周期
- onCreate:Activity正在被创建
- onRestart:Activity正在重新启动,当前Activity由不可见变为可见状态是调用(eg:按home键或打开一个新的activity会让当前Activity暂停,onPause,onStop;接着用户又回到这个activity,就会出现这种情况)【第一次创建不会调用调用这个方法】
- onStart:Activity正在被启动。可见,但没出现在前台(在后台),无法交互。
- onResume:可见,且出现在前台并开始活动。
- onPause:Activity正在停止,正常情况下onStop就会被调用。(特殊情况下,如果再快速回到Activity,则onResume会被调用)
- onPause必须先要执行完,新Activ ity的onResume才会执行。
- onStop:Activity即将停止
- onDestroy:Activity即将被销毁
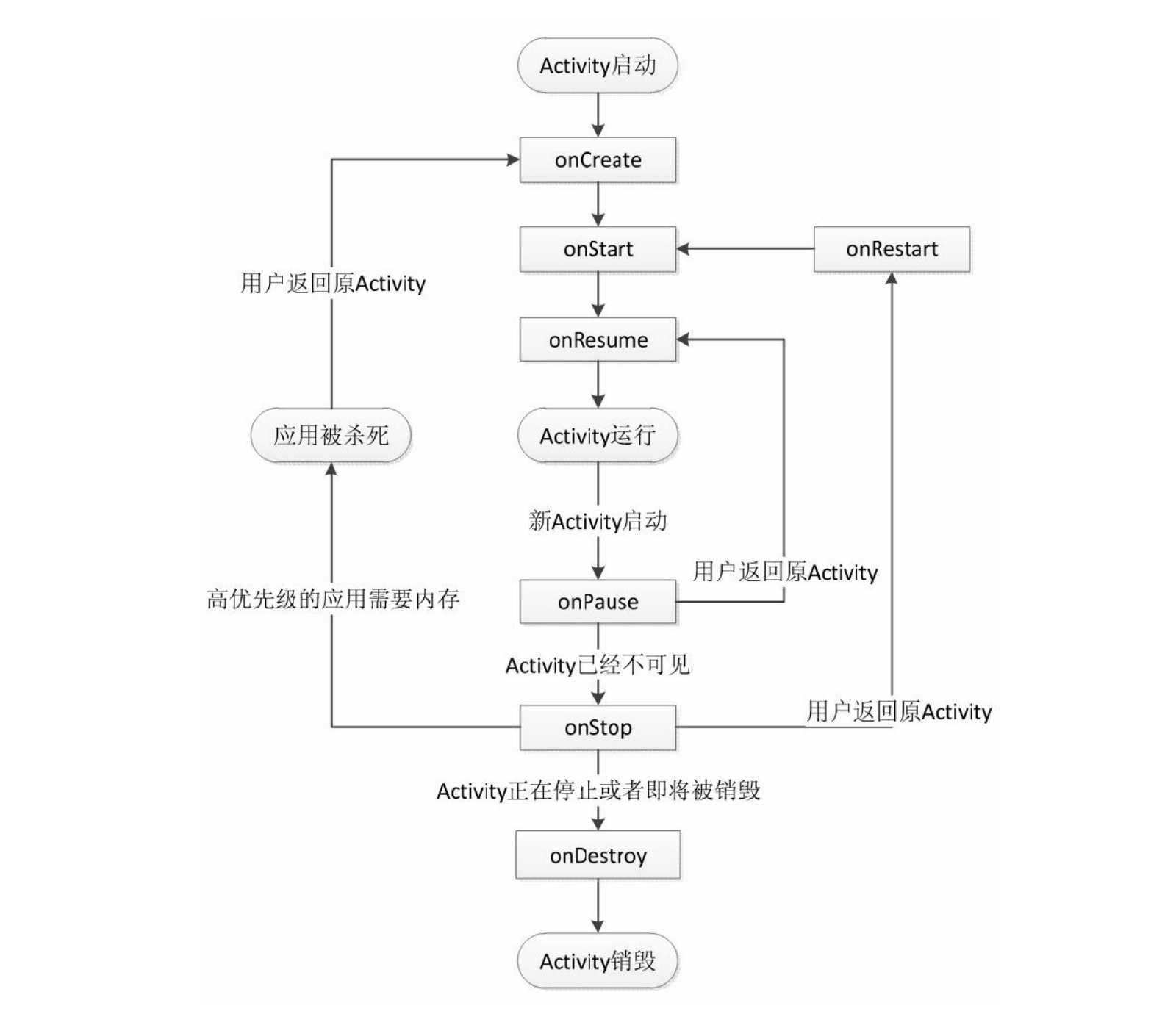
| onCreate | onRestart | onStart | onResume | onPause | onStop | onDestory |
|---|---|---|---|---|---|---|
| 正在被创建 | 正在重新启动 | 正在被启动 | 正在停止 | 即将停止 | 即将被销毁 | |
| 初始化布局资源,初始化activity所需数据 | activity可见 | activity可见 | 不可见 | 回收工作,资源释放 | ||
| activity出现在后台 | 出现在前台 | 后台 | 稍微重量级回收工作 | |||
| (栈顶activity)onPause必须执行完,新activity的才能启动 |
- 当新启动一个activity时,就activity的onPause会先执行,新的activity才会启动。

新创建Activity会被压入栈顶。点击back会将栈顶Activity弹出,并产生新的栈顶元素作为显示界面(onResume状态)
【问题1】 onSaveInstancestate() 说一下调用时机
异常情况下
- 资源相关的系统配置文件发生变化导致activity被杀死并重新创建
- 资源内存不足导致优先级低的activity被杀死
- 意外情况(如屏幕旋转)
- 当前activity会被销毁。onPause—>onStop ----> onDestory都会被调用
- onSaveInstanceState调用时机是在onStop之前(和onPause无既定时序关系)-----正常情况下不会调用此方法
- onStop–>onDestory
- activity被重新创建之后------->把旧Activity销毁时通过onSaveInstanceState所保存的Bundle对象传给onCreate()和onRestoreInstanceState()(onRestoreInstanceState()调用时机在onStop()之后)
- 委托思想保存数据
- 正常销毁不会调用onSaveInstanceState和onRestoreInstanceState,异常销毁且有机会重现它时调用onSaveInstanceState和onRestoreInstanceState
activity优先级
- 前台activity。正在和用户交互的
- 可见但非前台的activity。弹出一个对话框导致activity可见但是位于后台无法和用户直接交互
- 后台activity。已经被暂停的activity,必去执行了onStop的,优先级最低
资源内存不足导致优先级低的activity被杀死,会调用onSaveInstanceState和onRestoreInstanceState保存和回复数据
如果没有在android:configChanges中指定对应选项的话,当配置发生改变时就会导致activity重新创建
在AndroidMenifest.xml文件中加入Activity的声明即可
- locale:设备的本地位置
- orientation:屏幕方向
- keyboardHidden:键盘的可访问性发生改变,比如用户调出键盘
- screenSize和smallestScreenSize比较特殊。minSdkVersion和targetSdkVersion 大于 13时必须添加上,否则旋转屏幕后会activity会被重建
【问题2】onsaveInstancestate() 保存的参数是?Bundle 里面都放一些什么东西?
Bundle对象用于不同Activity之间的数据传递。对于不同Actvity而言,Bundle对象就相当于一个数据包,Intent对象就充当搬运工。
使用Bundle传递对象
1.让实体类对象实现序列化接口(Serializable接口和Parcelable接口)
2.数据封装
3.取出数据
(15)序列化
序列化:指的是把对象转换成字节序列的过程,也可以称之为对象流,可以保存到文件中,也可以用来网络传输数据。
反序列化:既是相反的过程,可以从我们的文件中把对象流(字节序列)读出来,转换为对象供我们使用。
【问题0】对象为什么需要序列化?
1.永久性保存对象,保存对象的字节序列到本地文件。
2.通过序列化对象在网络中传递对象。
3.通过序列化对象在进程间传递对象。
【问题1】Parcelable 和 Serializable有什么区别?
- 是有Java提供还是Android自带?
- 实现是否简单?效率如何?
- Serializable是Java中的序列化接口,使用简单但是开销很大,序列化和反序列化过程需要大量 I / O 操作
- Parcelable是Android中的序列化方式,因此更适合于Android平台。缺点是使用起来稍微麻烦点,但效率很高,是Android推荐的序列化方式,首选Parcelable。
- Parcelable主要用在内存序列化上,通过parcel将对象序列化到存储设备中或者将对象序列化后通过网络传输也是可以的,但是这个过程会稍显复杂,因此这两种情况下建议使用Serializable。
- Parcelable不能使用在将对象存储在磁盘上这种情况,因为在外界的变化下Parcelable不能很好的保证数据的持续性
注:Android中Intent传递对象有两种方法:一是Bundle.putSerializable(Key,Object),另一种是Bundle.putParcelable(Key,Object)。当然这些Object是有一定的条件的,前者是实现了Serializable接口,而后者是实现了Parcelable接口。
- Serializable:Java提供的序列化接口,是一个空接口(标记简单)
- 在类中声明一个标识:serialVersionUID(辅助序列化和反序列化,原则上序列化后的数据中的SerialVersionUID只有和当前类的serialVersionUID相同才能正常被反序列化)
- 序列化(将当前类的serialVersionUID写入序列化文件)—-ObjectOutputStream
- 反序列化(系统检测文件中的serialVersionUID,看是否与当前类的serialVersionUID相同。相同,可以成功翻序列化;不同,无法正常序列化)------—ObjectIutputStream
- Parcelable:Android特有的接口,一个类的对象通过该接口实例化,并可以通过Intent和Binder传递
- 效率比Serializable接口高------体检使用提高性能
【问题2】serialVersionUID的作用
如果没有手动指定该值,一开始序列化了classA,得到文件A,接着对classA的内部结构更改,比如添加了一个新的变量,那么此时反序列化则会失败。因为实际上系统在序列化的时候,会自动计算出一个serialVersionUID值,并保存在已经序列化好的数据中,此时修改了classA,那么反序列化的时候系统就会重新计算一个新的serialVersionUID值,那么两个值就会不相等,就会反序列化失败。所以,手动指定一个值,能很大程度上保存数据,防止数据丢失。
如果类有毁灭性改变(如类名发生改变),序列化会失败,无法从老版本数据中还原处一个新的类结构对象。
不会参与序列化过程的对象:
- 静态成员属于类不属于对象,所以不会参与序列化过程(序列化对象)
- transient关键字标记的成员变量不参与序列化过程。transient:adj.短暂的,临时的
【问题3】Serializable序列化和反序列化的具体步骤
(1)实例化一个对象输出流:ObjectOutputStream,该对象输出流可以包装一个输出流,比如文件输出流。
(2)使用ObjectOutputStream.writeObject(obj)进行写对象(obj类要实现序列化接口)。
(3)实例化一个对象输入流:ObjectInputStream,该对象输入流可以包装一个输入流,比如文件输入流。
(4)使用ObjectInputStream.readObject(obj)进行读对象。
public class UserTest {public static void main(String[] args) throws IOException, ClassNotFoundException {//实例化User类 该类已经实现SerializableUser user =new User(18,"zhouguizhi");//序列化过程ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("test.txt"));objectOutputStream.writeObject(user);objectOutputStream.close();System.out.println("序列化成功!");//反序列化过程ObjectInputStream objectInputStream =new ObjectInputStream(new FileInputStream("test.txt"));User newUser = (User) objectInputStream.readObject();objectInputStream.close();System.out.println("反序列化成功!");System.out.println("age:"+newUser.getAge()+" name:"+newUser.getName());}
}
序列化成功!
反序列化成功!
age:1 name:zhouguizhi
【问题4】Parcelable接口
需要实现的功能:
- 序列化。writeToParcel():将当前对象写入序列化结构中,最终通过Parcel中的一系列write方法来完成
- 反序列化。由CREATOR来完成:内部标明如何创建序列化对象和数组,并通过Parcel的一系列read方法来完成反序列化过程
- 从序列化后的对象中创建原始对象
- 创建指定长度的原始对象数组
- 内容描述。describeContents()方法来完成。一般返回0,仅当当前对象中存在文件描述符是,此方法返回1.
public class MyParcelable implements Parcelable {private int age;protected MyParcelable(Parcel in) {//从序列化后的对象中创建原始对象age = in.readInt();}@Overridepublic void writeToParcel(Parcel out, int flags) {//将当前对象写入序列化结构之中out.writeInt(age);}@Overridepublic int describeContents() {//内容描述return 0;}public static final Creator<MyParcelable> CREATOR = new Creator<MyParcelable>() {@Overridepublic MyParcelable createFromParcel(Parcel in) {//从序列化后的对象中创建原始对象return new MyParcelable(in);}@Overridepublic MyParcelable[] newArray(int size) {//创建指定长度的原始对象数组 return new MyParcelable[size];}};
}
实现了Parcelable接口的类:它们是可以直接序列化的,eg:Intent, Bundle, Bitmap,同时List和Map也可以实现序列化,前提是它李阿敏的每一个元素都是可序列化的。
(16)MVP架构 (应用框架模式)
Model-View-Presenter。在MVP中,M代表Model,V代表View,P代表Presenter。
MVP架构由MVC发展而来。
Model:数据层,负责获取数据,数据的来源可以是网络或本地数据库等。
**View:**视图层,负责界面数据的展示,与用户进行交互。在Android中,可以是Activity、fragment类或者是某个View控件。
Presenter:作为View和Model之间沟通的桥梁,它从Model层检索数据后返回给View层,使得View和Model之间没有耦合。
在MVP里,Presenter将Model和View进行了分离,主要程序逻辑在Presenter里面实现。Presenter与具体View是没有直接关联的,而是通过定义好的接口进行交互,从而使得在变更View时可以保持Presenter的不变,符合面向接口编程的特点。决不允许View直接访问Model。
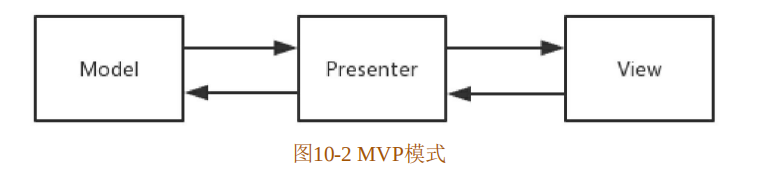
MVP的架构有如下好处:
1)降低了View和Model的耦合,通过Presenter层来通信;
2)把视图层抽象到View接口,逻辑层抽象到Presenter接口,提高了代码的可读性、可维护性;
3)Activity和Fragment功能变得更加单一,只需要处理View相关的逻辑;
4)Presenter抽象成接口,就可以有多种实现,方便单元测试。
具体实现(参考MVP.markdown)
(16)泛型
泛型,即**“参数化类型**”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?
顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),
然后在使用/调用时传入具体的类型(类型实参)。
List<String> list = new ArrayList<>(); //这里的List是一个String类型的List
List<Integer> list2 = new ArrayList<>();
List<int> list3 = new ArrayList<>();//不能为基本类型,编译时出错
//可以将ArrayList<String> 类当成ArrayList的子类
//list.getClass() 得到的是ArrayList类;list2.getClass() 得到的也是ArrayList类
//对于Java来说,它们仍然被当做同一个类来处理,在内存中只是占用一块内存空间
//**泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。**
可以称List是一个带类型参数的泛型接口,类型参数是String。允许程序在创建集合时指定集合元素的类型
所谓泛型,就是允许在定义类、接口、方法时使用类型参形,这个类型形参将在声明变量、创建对象、调用方法时动态地指定(即传入实际的类型参数,也可称为类型实参)。
- 定义泛型接口、类
- 允许在定义接口、类时声明类型形参,类型形参在整个接口、类体内可当成类型使用
- 当创建了带泛型的接口、父类之后,可以为该接口创建实现类,或从该父类派生子类,但是,当使用这些接口、父类时不能再包含类型形参(必须要传一个类型实参进去!!!!)

在静态方法、静态初始化块或者静态变量的声明和初始化中不允许使用类型形参
public class Persion<T> {// 编译时报错public static T name;//编译时报错,不能在静态方法声明中使用泛型形参public static <T> void test(T t) {}
}
泛型在对象创建时才知道是什么类型,但是静态方法属于类,调用test方法实际调用的Persion类的方法,而类在编译阶段就存在了,所以虚拟机根本不知道方法中引用的泛型是什么类型
初始化时:对象创建的代码执行先后顺序是static的部分,然后才是构造函数等等,所以在对象初始化之前static的部分已经执行了,如果你在静态部分引用的泛型,那么毫无疑问虚拟机根本不知道是什么东西
特性
通过上面的例子可以证明,在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。
泛型的使用
泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法

类型通配符 ?
我们可以将上面的方法改一下:
public void showKeyValue1(Generic<?> obj){Log.d("泛型测试","key value is " + obj.getKey());
}
类型通配符一般是使用 **?**代替具体的类型实参,注意了,此处’?’是类型实参,而不是类型形参 。重要说三遍!此处’?’是类型实参,而不是类型形参 ! 此处’?’是类型实参,而不是类型形参 !再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
![]()
![]()
https://segmentfault.com/a/1190000014824002
类型擦除
Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
Java编译器是通过先检查代码中泛型的类型,然后在进行类型擦除,再进行编译。所以无法在运行时得知其类型参数的类型
因为类型检查就是编译时完成的,new ArrayList()只是在内存中开辟了一个存储空间,可以存储任何类型对象,而真正涉及类型检查的是它的引用,因为我们是使用它的引用list1来调用它的方法,比如说调用add方法,所以list1引用能完成泛型类型的检查。而引用list2没有使用泛型,所以不行。
public class Test { public static void main(String[] args) { ArrayList<String> list1 = new ArrayList(); list1.add("1"); //编译通过 list1.add(1); //编译错误 String str1 = list1.get(0); //返回类型就是String ArrayList list2 = new ArrayList<String>(); list2.add("1"); //编译通过 list2.add(1); //编译通过 Object object = list2.get(0); //返回类型就是Object new ArrayList<String>().add("11"); //编译通过 ,//使用引用来调用方法的//有引用才能调用方法,所以这里new ArrayList<String>().add("11")相当于一个引用调用了一个方法,会进行类型检查new ArrayList<String>().add(22); //编译错误 String str2 = new ArrayList<String>().get(0); //返回类型就是String } } public class Test {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<String>();list1.add("abc");ArrayList<Integer> list2 = new ArrayList<Integer>();list2.add(123);System.out.println(list1.getClass() == list2.getClass());//true 都是ArrayList}}
https://www.cnblogs.com/wuqinglong/p/9456193.html
(17)OkHttp
使用步骤
配置gradle,添加网络权限
异步请求POST
创建OkHttpClient
Request:通过Request.Builder来创建Request的实例
Call:通过OkHttpClient的实例的newCall(Request request)方法来创建
Call call = mOkHttpClient.newCall(request);调用Call的enqueue()方法-----异步
- 同步:execute
异步POST请求
- 多路FormBody(RequestBody)来封装参数,并传递给Request
![]()
源码
- OkHttpClient.newCall(request)实际调用的是RealCall类的enqueue(),最终请求由dispatcher完成
- 它会调用client的dispatcher()方法去执行网络请求,这里的dispatcher其实在它的官方文档上写的是执行异步操作的策略
- 在dispatcher里,其实我们能看见三个非常重要的集合类:
- Dispatcher任务调度
- Dispatcher主要用于控制并发的请求
- **getResponseWithInterceptorChain()**这个方法可以说把okhttp最精髓的地方体现出来了,也就是----拦截器,最后,它会返回请求到的数据,然后把这次的请求关闭;
- 在这个方法里面有很多拦截器。okhttp最大的亮点就是这个interceptor,网络请求要很多步骤,比如需要去请求网络,缓存,透明压缩,等等一系列的操作,okhttp这个网络框架就把这些操作分割成一个个的interceptor,然后把这些interceptor连成一个链也就是Interceptor.Chain,然后去完成一次完整的网络请求,这是典型的分层思想的提现,把一次复杂的工作分步骤去做,更加合理,也更加高效安全;

(18)RecyclerView的补充
ListView的缓存机制
在ListView里面有一个内部类RecycleBin,RecycleBin有两个对象ActiveView和ScrapView来管理缓存
**两级 缓存:**缓存对象是itemView
- **ActiveView:**缓存在屏幕内的ItemView,当列表数据发生变化时,屏幕内的数据可以直接拿来复用,无需进行数据绑定。(屏幕内ItemView快速复用)
- ScrapView:缓存在屏幕外的ItemView,这里所有的缓存的数据都是脏的,也就是数据需要重新绑定,也就是说屏幕外的所有数据在进入屏幕的时候都要走一遍getView()方法。
- 当ActiveView和ScrapView中都没有缓存的时候就会直接createView()
![]()

RecyclerView的缓存机制

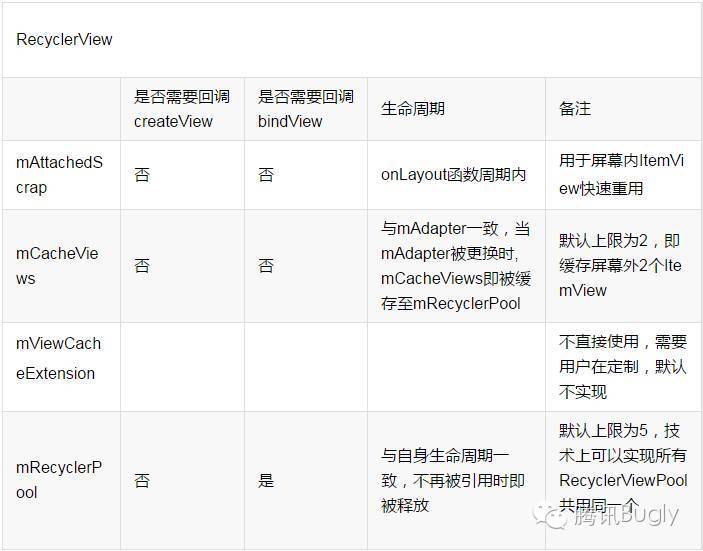
四级缓存:缓存对象是ViewHolder
**Scrap:**对应ListView的ActiveView,即屏幕内的缓存数据
- 根据position拿到缓存(ViewHolder)
- ViewHolder可以直接拿出来复用

Cache:刚刚移出屏幕的缓存数据,默认大小是2。数据可以直接拿出来复用
- 根据position获取ViewHolder
- ViewHolder可以直接拿出来复用(不需要bindViewHolder)

**ViewCacheExtension:**留给开发者自定义缓存的,建议慎用
- 支持开发者自定义缓存处理逻辑
RecycledViewPool:
根据itemType获取ViewHolder
ViewHolder不能直接复用,要走一遍onBindViewHolder()方法
当Cache满了之后根据先进先出的原则把cache先缓存进去的ViewHolder移出并缓存到RecyclerViewPool中,RecyclerViewPool默认缓存大小是5个。从cache中移出的ViewHolder再存入RecyclerViewPool之前ViewHolder的数据会被全部重置(reset),相当于一个新的ViewHolder。Cache根据position来获取ViewHolder,RecyclerViewPool通过itemType获取ViewHoler,如果没有重写getItemType()方法,itemType就是默认的。因为RecyclerViewPool缓存的ViewHolder是全新的,所以取出来的时候需要走一遍onBindViewHolder()方法
支持所有RecyclerView共用同一个RecyclerViewPool(缓存池)

缓存策略:
RecyclerView在获取ViewHolder时按照四级缓存的顺序进行查找,如果没找到就创建。其中只有RecycleViewPool找到是才会调用bindViewHolder,其他缓存不会重新bindViewHolder
![]()

(19)ViewPager的使用
1. 总体设计思路
- TabLayout:点击切换选项卡
- Fragment:存放不同选项的页面内容
- ViewPager:实现页面的左右滑动效果
2. 实现步骤
利用(TabLayout+ViewPager+Fragment)实现顶部&底部Tab导航栏的步骤一共有6个:
- 步骤1:添加依赖
- 步骤2:创建需要的Fragment布局文件(需要多少个Tab选项,就建多少个Fragment)
- 步骤3:创建Fragment对应的Activity类
- 步骤4:定义适配器Adapter
- 步骤5:定义主布局activity_main.xml文件
- 步骤6:定义MainActivity类
创建n个具体的Fragment及其布局文件
**定义适配器Adapter类 ** myFragmentPagerAdapter
用一个String[] 存放tabTitle
用一个List存放 fragment:初始化碎片集合,并将它们加到list中去
重写3个方法:
public Fragment getItem(int position) //获取某个具体的fragment public int getCount() //fragment的数量 public CharSequence getPageTitle(int position)//ViewPager与TabLayout绑定后,这里获取到PageTitle就是Tab的Text,标题
- MainActivity,并定义主布局activity_main.xml
- 初始化ViewPager,并将ViewPager与myFragmentPagerAdapter(extends FragmentPagerAdapter )绑定**(ViewPager与Fragment绑定)**
- 将TabLayout与ViewPager绑定在一起
【问题1】ViewPager是什么?
ViewPager是android扩展包v4包中的类,这个类可以让用户左右切换当前的view。
- 1)ViewPager类直接继承了ViewGroup类,所有它是一个容器类,可以在其中添加其他的view类。
- 2)ViewPager类需要一个PagerAdapter适配器类给它提供数据。
- 3)ViewPager经常和Fragment一起使用,并且提供了专门的FragmentPagerAdapter和FragmentStatePagerAdapter类供Fragment中的ViewPager使用。
【问题2】ViewPager的适配器
用过ListView或者RecyclerView都知道,凡是类似这种显示多个Item的控件,Android系统都设置成适配器模式了,因此ViewPager也需要适配器才能去显示数据,ViewPager的适配器就是PagerAdapter。
【问题3】
viewpager显示fragment的时候不会仅仅显示展现的那个fragment,而是将前一个,后一个,和正在显示的fragment的生命周期都跑一遍。
(20)Window
window机制的关键类
![]()
PhoneWindow是窗口类,继承自抽象类Window,也是唯一子类。
WindowManager是Window管理接口,继承自ViewManager,他的唯一实现类是WindowManagerImpl。
WindowManagerImpl并没有真正实现windowManager接口逻辑,而是把逻辑转给了WindowManagerGlobal,
WindowManagerGlobal是全局单例。
Window和View的联系通过ViewRootImpl桥梁,同时ViewRootImpl还负责管理view树、绘制view树、和WMS通信。
WMS即WindowManagerService,是Window的真正管理类。
中去
重写3个方法:
public Fragment getItem(int position) //获取某个具体的fragment public int getCount() //fragment的数量 public CharSequence getPageTitle(int position)//ViewPager与TabLayout绑定后,这里获取到PageTitle就是Tab的Text,标题
- MainActivity,并定义主布局activity_main.xml
- 初始化ViewPager,并将ViewPager与myFragmentPagerAdapter(extends FragmentPagerAdapter )绑定**(ViewPager与Fragment绑定)**
- 将TabLayout与ViewPager绑定在一起
【问题1】ViewPager是什么?
ViewPager是android扩展包v4包中的类,这个类可以让用户左右切换当前的view。
- 1)ViewPager类直接继承了ViewGroup类,所有它是一个容器类,可以在其中添加其他的view类。
- 2)ViewPager类需要一个PagerAdapter适配器类给它提供数据。
- 3)ViewPager经常和Fragment一起使用,并且提供了专门的FragmentPagerAdapter和FragmentStatePagerAdapter类供Fragment中的ViewPager使用。
【问题2】ViewPager的适配器
用过ListView或者RecyclerView都知道,凡是类似这种显示多个Item的控件,Android系统都设置成适配器模式了,因此ViewPager也需要适配器才能去显示数据,ViewPager的适配器就是PagerAdapter。
【问题3】
viewpager显示fragment的时候不会仅仅显示展现的那个fragment,而是将前一个,后一个,和正在显示的fragment的生命周期都跑一遍。
(20)Window
window机制的关键类
[外链图片转存中…(img-yUsHU49r-1628430571116)]
PhoneWindow是窗口类,继承自抽象类Window,也是唯一子类。
WindowManager是Window管理接口,继承自ViewManager,他的唯一实现类是WindowManagerImpl。
WindowManagerImpl并没有真正实现windowManager接口逻辑,而是把逻辑转给了WindowManagerGlobal,
WindowManagerGlobal是全局单例。
Window和View的联系通过ViewRootImpl桥梁,同时ViewRootImpl还负责管理view树、绘制view树、和WMS通信。
WMS即WindowManagerService,是Window的真正管理类。
Android面试题解(全)相关推荐
- 终于有阿里p8进行了大汇总(Redis+JVM+MySQL+Spring)还有面试题解全在这里了!
Redis特性 Redis是一直基于键值对的NoSQL数据库: Redis支持5种主要数据结构:string.hash.list.set.zset以及bitmaps.hyperLoglog.GEO等特 ...
- 史上最全Android面试真题+解析,全网阅读量7w+
前言 对于程序员而言,无论是想加快个人技能成长速度,或是想要升职涨薪,都需要不断进阶,进入到规模与业务较大,并且有成熟的技术成长体系的公司当中去. 因此,跳槽逐渐成为了这个行业里一个常见的词汇. 而想 ...
- 从投递到拿到offer,这份Android面试秘籍一文全解,kotlin开源项目
"emm-" (老哥!你真的是来面试的吗?!) 如果你是面试官,你会用一个都不知道公司和岗位职责是什么的人吗?这至少说明了2个问题: 1.他对这次面试是不重视的!(那他怎么会对他的 ...
- 应该是史上最全最新Java和Android面试题目(自己总结和收集的)
Android面试题目 Java 基础 int占用几个字节 讲一下常见编码方式? UTF-8编码下中文占几个字节 int和Interger的区别 int.char.long各占多少字节数 string ...
- flutter全屏时钟!9次Android面试经验总结,学习路线+知识点梳理
前言 回顾一下自己这段时间的经历,三月份的时候,疫情原因公司通知了裁员,我匆匆忙忙地出去面了几家,但最终都没有拿到offer,我感觉今年的寒冬有点冷.到五月份,公司开始第二波裁员,我决定主动拿赔偿走人 ...
- 从投递到拿到offer,这份Android面试秘籍一文全解,2021年阿里+头条+腾讯大厂Android笔试真题
切勿答非所问,偷换概念.当面试官提出一个你并不是很了解的问题时候,即使冷场也不要答非所问,进行偷换概念.因为面试最讲究的就是真诚二字.你这样做只会加深面试官对你的厌恶. 切勿侃侃而谈.有很多人在面试时 ...
- 【Android 面试基础知识点整理】
针对Android面试中常见的一些知识点整理,Max 仅仅是个搬运工.感谢本文中引用文章的各位作者,给大家分享了这么多优秀文章.对于当中的解析,是原作者个人见解,有错误和不准确的地方,也请大家积极指正 ...
- 我的android面试经历
做了一年的android应用开发,准备换个工作环境,结果在面试中却成了一个典型的面霸,两周的十个工作日里,竟然笔试加面试达到了15次.不过,在这些面试中学到了不少东西!下面把我的android面试经历 ...
- Android面试:Java相关
Android面试常见Java相关问题. 原文链接:http://www.nowcoder.com/discuss/3244 Switch能否用string做参数? 在 Java 7 之前, swit ...
最新文章
- jquery正则匹配URL地址
- Activiti第二篇【管理流程定义、执行任务和流程实例、流程变量】
- centos安装ruby
- c语言 函数的参数传递示例_scalbln()函数以及C ++中的示例
- 范式哈夫曼编码(Canonical Huffman Code)
- 10秒钟的Cat 6A网线认证仪_DSX2-5000 CH
- 中标麒麟安装mysql教程_中标麒麟操作系统安装MySQL5.7.22的步骤教程
- 怎么创建一个网站?【建立网站】
- RDP VS VNC 速度测试
- 奇葩算法系列——猴子排序
- idv和vdi的优劣势_VDI和IDV两种桌面虚拟化的方案对比
- 强化学习蘑菇书Easy RL 第四五章
- 利用正则表达式来验证邮箱
- 【可见光室内定位】(一)概览
- 心里藏着小星星,生活才能亮晶晶
- 集成QQ钱包---踩坑
- [原创] 如何构建成功的QA团队(How to build a successful QA team)
- C#网络编程复习资料
- ThreeJs_投影
- fedora 火狐 html5,Fedora22火狐如何安装Adobe Flash Player