海牛大数据教你Hadoop 如何批量操作多台服务器
原文地址:http://hainiubl.com/topics/80#reply42
1. 每个虚拟机设置静态IP
cd /etc/sysconfig/network-scripts/
ifconfig/ip add 查看网卡的硬件名称和基本信息
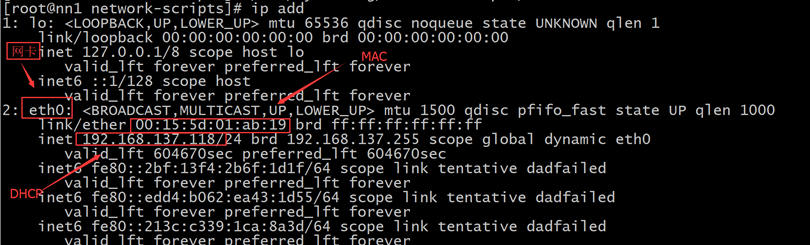
记下这个UUID
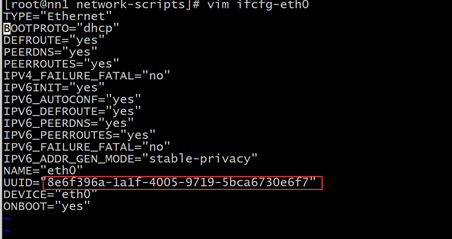
以下内容回帖刷新可见………………#
网卡配置例子
TYPE="Ethernet"
BOOTPROTO="static"
IPADDR="192.168.137.190"
NETMASK="255.255.255.0"
GATEWAY="192.168.137.1"
DNS="192.168.137.1"
NM_CONTROLLED="no"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
NAME="eth0"
DEVICE="eth0"
UUID="ec7dbe05-3175-4f67-9a43-24b144ab51b5"
ONBOOT="yes"
VIM使用,按i进入编辑模式,按gg到文件的顶部,shift+g到文件的底部,dd删除光标所以行,u等于word里的ctrl+z,ctrl+r等于word里的ctrl+y
vim /etc/sysconfig/network-scripts/ifcfg-<网卡的硬件名称>
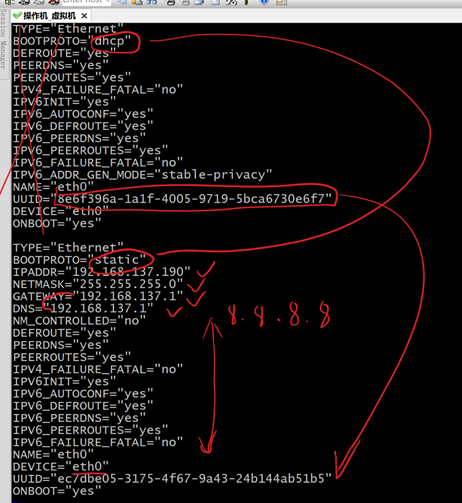
配置完的网卡文件
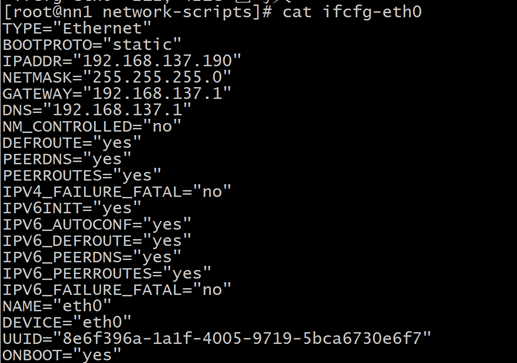
查看结果
原来的
注意修改完文件之后用systemctl restart network.service重启网络服务,当前的ssh就连接不上了,是因为网络IP被改变成你自己设置的静态IP了
修改完成再连接,用ip add查看修改完成的结果
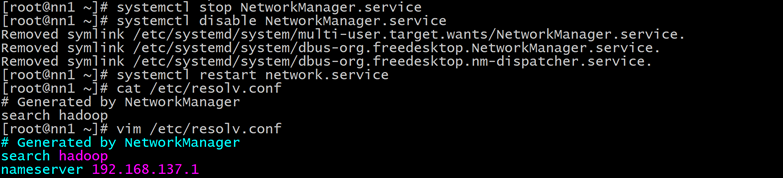
如果上不了网执行以下操作。
cat /etc/resolv.conf 查看nameserver是否被设置正确
systemctl stop NetworkManager.service 停止NetworkManager服务
systemctl disable NetworkManager.service 并设置成开机不启动
systemctl restart network.service 之后重启网络服务
vim /etc/resolv.conf 修改文件,如果不存在nameserver就在文件下面添加,如果存在就修改,把nameserver 设置成自己对应的DNS
2. 修改每个机器的主机名#
修改另外3台的主机名
hostnamectl set-hostname s1.hadoop

3. 配置HOSTS文件#
修改/etc/hosts文件
vim /etc/hosts,把刚才配置的固定IP加到文件里

把其他3台机器的hosts文件也修改成上面这个样子
4. 批量执行与批量分发脚本使用#
首先切换到hadoop用户
ssh到别一台机器上执行命令全,例子:ssh hadoop@s1.hadoop hostname
scp一个文件到别一台机器上,例子:scp /home/hadoop/1 hadoop@s1.hadoop:/home/hadoop/
把hadoop_op1.zip文件用rz命令上传到nn1.hadoop机器上
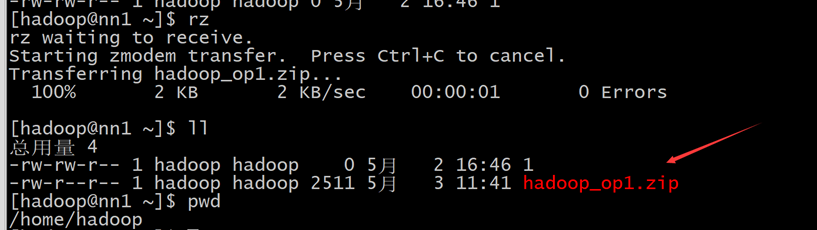
一般先切换到当前使用用户的home目录下
cd/cd ~
unzip hadoop_op1.zip
解压
chmod -R 777 ./hadoop_op1 修改解压之后的文件权限
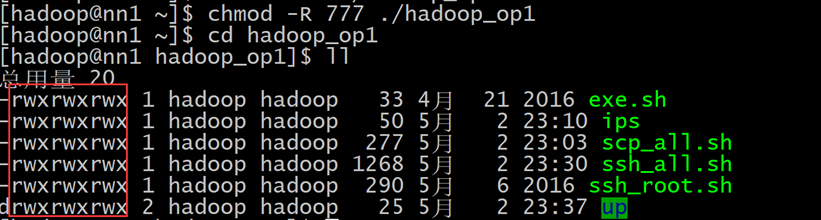
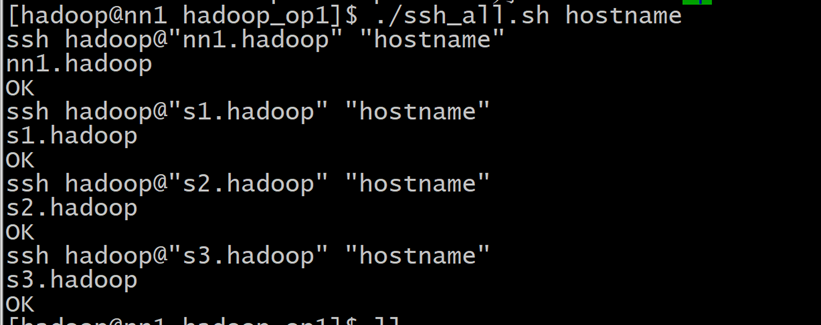
测试批量SSH命令
./ssh_all.sh hostname
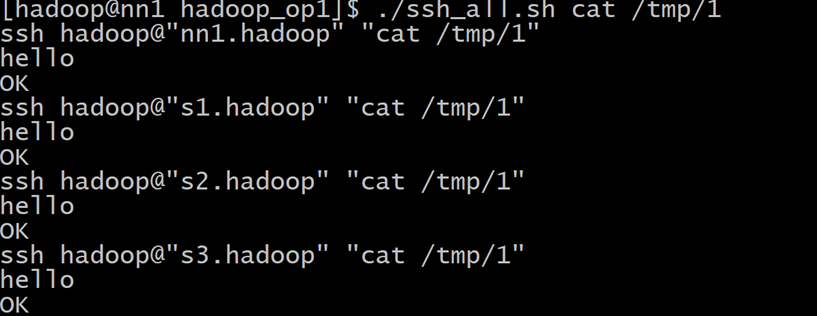
测试批量传文件
首先在/home/hadoop/up/目录下创建个测试文件,这里的文件是“1”
./scp_all.sh ./up/1 /tmp/

可以用./ssh_all.sh cat /tmp/1用这个命令去验证
5. 单机hadoop用户加上免密码切换root用户#
1).sed -i 's/#auth\t\trequired\tpam_wheel.so/auth\t\trequired\tpam_wheel.so/g' '/etc/pam.d/su'
修改/etc/pam.d/su文件,将“#auth\t\trequired\tpam_wheel.so”,替换成“auth\t\trequired\tpam_wheel.so”
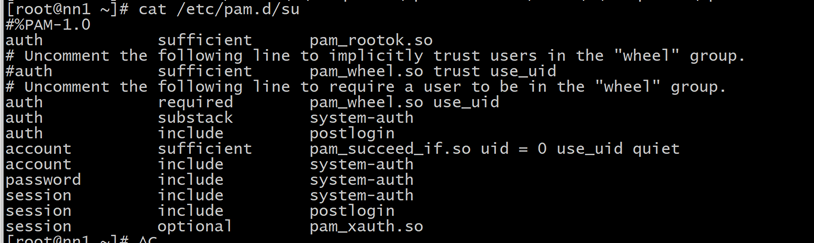
2).cp /etc/login.defs /etc/login.defs_back 先备份一个
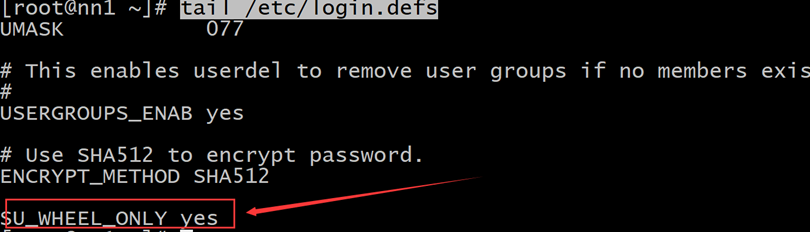
echo "SU_WHEEL_ONLY yes" >> /etc/login.defs 把“SU_WHEEL_ONLY yes”字符串追加到/etc/login.defs文件底部
tail /etc/login.defs 从文件底部查看
3).usermod -a -G wheel hadoop 把hadoop用户加到wheel组里
4).groupmems -g wheel -l 使用这个命令查看wheel组里是否有hadoop用户

5).新建一个hainiu用户验证一下


输入密码之后提示无SU权限,即使密码正确也不好使

6).sed -i 's/#auth\t\tsufficient\tpam_wheel.so/auth\t\tsufficient\tpam_wheel.so/g' '/etc/pam.d/su'
修改/etc/pam.d/su文件将字符串“#auth\t\tsufficient\tpam_wheel.so”替换成“auth\t\tsufficient\tpam_wheel.so”
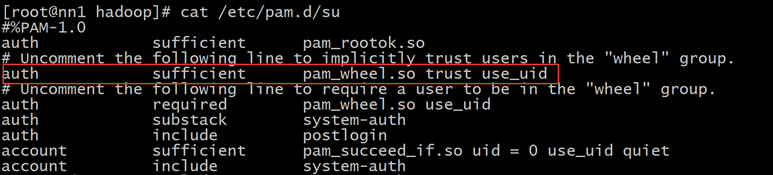
7).验证免密码切换到root用户

6. 给每个机器的hadoop用户加上免密码切换root用户#
配置好每个机器的root ssh免密钥登录
然后在nn1.hadoop机器上切换到root用户
把批量执行脚本用rz上传到root用户的根目录下
用unzip hadoop_op1.zip把文件解压出来
删除没用的只留下以下有用的,并对有用的脚本加上可执行权限chmod -R +x ~/hadoop_op1
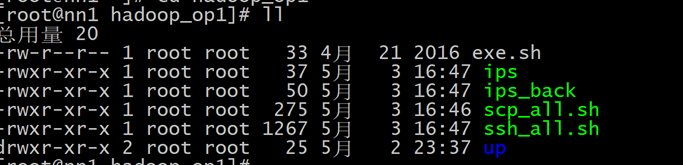
修改脚本 vim ssh_all.sh,将使用用户修改为root用户
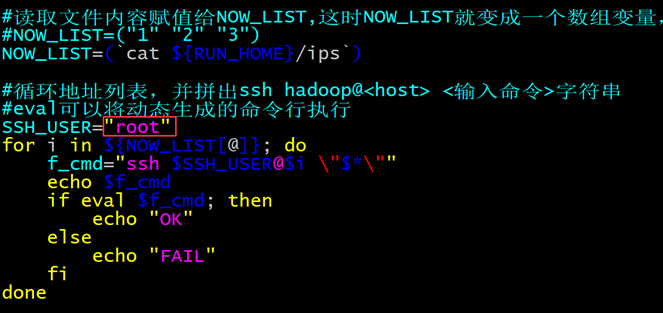
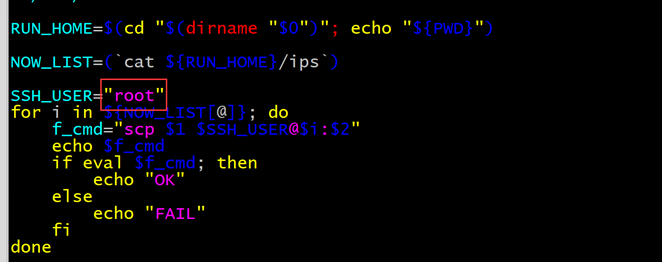
修改脚本vim scp_all.sh,将使用用户修改为root用户
注:在Linux中wheel组就类似于一个管理员的组。将普通用户加入到wheel组,被加入的这个普通用户就成了管理员组内的用户
剥夺普通用户切换root用户
用ssh_all.sh脚本批量修改 /etc/pam.d/su 文件,找到auth required pam_wheel.so use_uid 这一行,将行首的“#”去掉。
~/hadoop_op1/ssh_all.sh sed -i \'s/#auth\t\trequired\tpam_wheel.so/auth\t\trequired\tpam_wheel.so/g\' \'/etc/pam.d/su\'
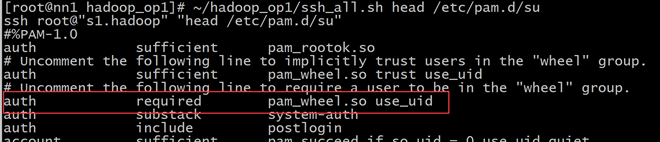
使用~/hadoop_op1/ssh_all.sh head /etc/pam.d/su 查看每个机器上是否修改成功
修改 /etc/login.defs 文件,在最后一行增加“SU_WHEEL_ONLY yes”语句。
~/hadoop_op1/ssh_all.sh "echo \"SU_WHEEL_ONLY yes\" >> /etc/login.defs"
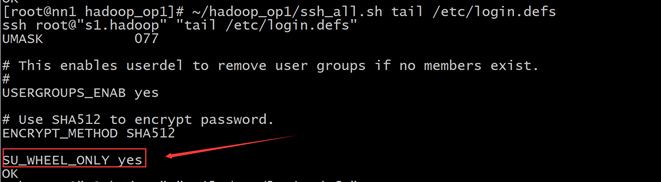
使用~/hadoop_op1/ssh_all.sh tail /etc/login.defs 查看每个机器上是否修改成功
指定某用户能切换到root用户,就将他加到wheel组里
~/hadoop_op1/ssh_all.sh usermod -a -G wheel hadoop
从wheel组移出就不能切换到root用户了
~/hadoop_op1/ssh_all.sh gpasswd -d hadoop wheel
查看wheel组下的用户,也就是能切换到root的用户有那些
使用~/hadoop_op1/ssh_all.sh groupmems -g wheel -l查看每个机器上是否添加成功

解释:如果换成一个不属于wheel组的用户时,执行了su命令后,即使输入了正确的root密码,也无法登录为root用户--普通用户登录为root用户的权限被完全剥夺了
切换到root用户时免密登录
修改 /etc/pam.d/su 文件,找到auth sufficient pam_wheel.so trust use_uid 这一行,将行首的“#”去掉。
~/hadoop_op1/ssh_all.sh sed -i \'s/#auth\t\tsufficient\tpam_wheel.so/auth\t\tsufficient\tpam_wheel.so/g\' \'/etc/pam.d/su\'
使用~/hadoop_op1/ssh_all.sh head /etc/pam.d/su查看每个机器上是否修改成功

7. 在hadoop用户状态下,如何在每个机器上使用root权限去执行命令#
切换到hadoop用户下,并用rz上传exe.sh脚本
然后使用~/hadoop_op1/scp_all.sh ~/hadoop_op1/exe.sh /home/hadoop/
把exe.sh复制到每个机器上
然后使用~/hadoop_op1/ssh_all.sh ls /home/hadoop/每个机器上文件是否被分发成功
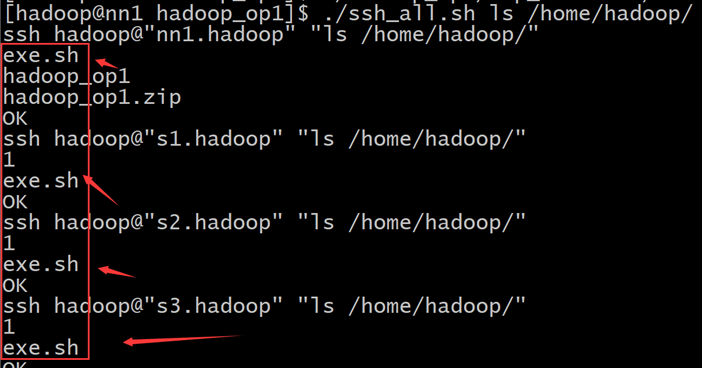
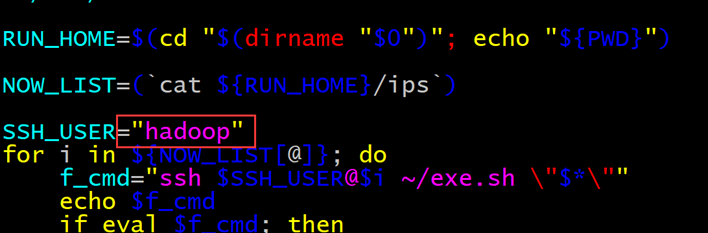
使用vim将ssh_root.sh里的ssh用户更改成hadoop
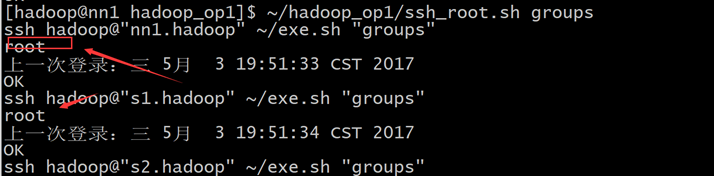
然后使用ssh_root.sh测试一下每台机器是否能从hadoop用户切换到root权限
~/hadoop_op1/ssh_root.sh groups,每台机器切换到root用户并打印root用户所属组
8. 修改每个机器的HOSTS文件#
在nn1.hadoop机器上使用hadoop用户将/etc/hosts文件拷贝到/tmp目录下
cp /etc/hosts /tmp

使用~/hadoop_op1/scp_all.sh /tmp/hosts /tmp/,把nn1.hadoop上配置好的host拷贝到每台机器的/tmp目录下
使用~/hadoop_op1/scp_all.sh ~/hadoop_op1/up/hosts_op.sh /tmp/,把hosts_op.sh脚本拷贝到每台机器的/tmp目录下
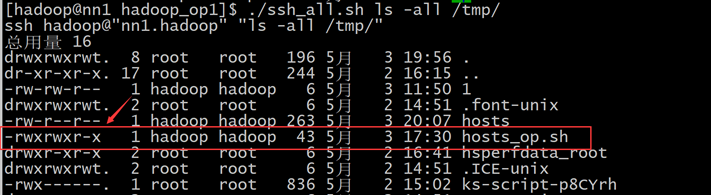
使用~/hadoop_op1/ssh_all.sh ls -all /tmp/确认这两个文件是否拷贝成功,并查看hosts_op.sh脚本是否拥有执行权限
使用 ~/hadoop_op1/ssh_all.sh mv /tmp/hosts /tmp/hosts_log,把每台机器上的tmp目录下的hosts文件重命名为hosts_log
使用 ~/hadoop_op1/ssh_all.sh ls /tmp/ 查看是否重命名成功
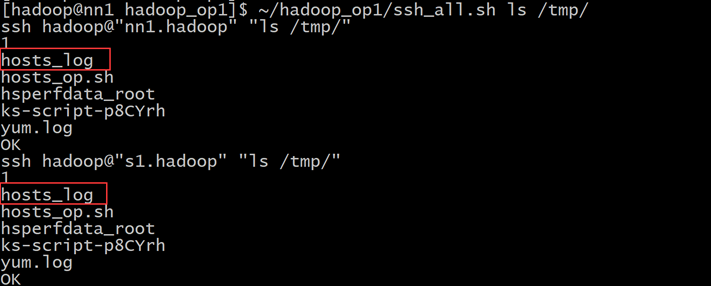
使用~/hadoop_op1/ssh_root.sh /tmp/hosts_op.sh,把每个机器上的hosts文件进行配置好的,也就是hosts_log的内容

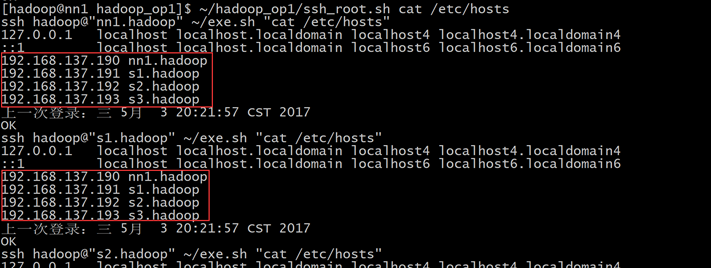
使用~/hadoop_op1/ssh_root.sh cat /etc/hosts,查看每台机器上的hosts文件是否修改成功
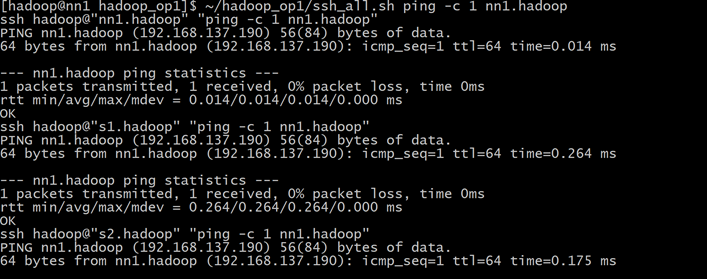
也可以使用~/hadoop_op1/ssh_all.sh ping -c 1 nn1.hadoop,查看每台机器是否能ping通nn1.hadoop,如果能ping通表示hosts修改成功并生效
海牛大数据教你Hadoop 如何批量操作多台服务器相关推荐
- 大数据平台,Hadoop集群架构,概述及原理
目录 一,大数据平台架构概述 1,大数据概念 2,大数据的特征 3,大数据的处理流程和相关技术 4,大数据平台架构的特点 5,大数据平台架构原理 二,Hadoop集群概述 1,HDFS 2,MapRe ...
- 图解大数据 | 分布式平台Hadoop与Map-Reduce详解
作者:韩信子@ShowMeAI 教程地址:https://www.showmeai.tech/tutorials/84 本文地址:https://www.showmeai.tech/article-d ...
- ASP.NET + SqlSever 大数据解决方案 PK HADOOP
ASP.NET + SqlSever 大数据解决方案 PK HADOOP 参考文章: (1)ASP.NET + SqlSever 大数据解决方案 PK HADOOP (2)https://www.cn ...
- 《Spark与Hadoop大数据分析》——1.2 大数据科学以及Hadoop和Spark在其中承担的角色...
1.2 大数据科学以及Hadoop和Spark在其中承担的角色 数据科学的工作体现在以下这两个方面: 要从数据中提取其深层次的规律性,意味着要使用统计算法提炼出有价值的信息.数据产品则是一种软件系统, ...
- hadoop大数据开发基础_Java大数据开发(三)Hadoop(2)经典的Hadoop
点击蓝字关注我 1 什么是大数据 1.Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2.主要解决,海量数据的存储和海量数据的分析计算问题. 3.广义上来说,HADOOP通常是指一个 ...
- 自拍会不会被大数据_大数据教你自拍 脸占画面1/3最漂亮
川北在线核心提示:原标题:大数据教你自拍 脸占画面1/3最漂亮 脸占画面1/3 调成黑白颜色 在这个秀,秀,秀的时代,社交媒体的一大重要功能就是秀自拍,既然大家都在秀,那么怎样才能拍出最引人注目的自拍 ...
- 大数据第一季--Hadoop(day5)-徐培成-专题视频课程
大数据第一季--Hadoop(day5)-1777人已学习 课程介绍 大数据第一季--Hadoop(day5) 课程收益 大数据第一季--Hadoop(day5) 讲师介绍 ...
- 大数据技术之Hadoop(MapReduce)
大数据技术之Hadoop(MapReduce) (作者:大数据研发部) 版本:V1.4 第1章MapReduce入门 map 计算 reduce 规约 1.1 MapReduce定义 Mapreduc ...
- 大数据_07 【hadoop HDFS的shell命令操作】
大数据_07 [hadoop HDFS的shell命令操作] 01 基本语法 02 常用普通命令实操 03 HDFS常用高级命令 04 HDFS适用场景 05 HDFS不适用场景 06 hdfs的安全 ...
最新文章
- vim-go开发环境Tagbar插件和NERTree插件安装
- APK文件的解包打包和修改
- 洛谷 - P2765 魔术球问题(最大流+残余网络上的最大流+路径打印)
- Spring Bean 后置处理器
- python 判断每月最后一天_python获取某年中每个月的第一天和最后一天的两种方法...
- 信息学奥赛一本通C++语言——1127:图像旋转
- webstorm的个性化设置settings
- Eclipse创建Java项目时提示Open Associated Perspective?
- Zemax操作25--像差理论和修正(球差、慧差、像散)
- matlab计算热岛效应强度,城市热岛热岛强度.ppt
- Java-TreeSet与Comparable的详讲与实现
- (HttpClient技术)(58同城系列)58同城登录
- 剑指Offer II --- 2021/9/2
- HHD+SSD重装mac os 10.9记录
- 友盟第三方登录 无法切换账号 退出 取消授权
- 有没有html代码听力的软件吗,有哪些英语听力训练的软件?
- websocket的简介与应用
- 网络新宠儿EyeOS Web版操作系统
- Android P 连接tbox 后热点无法打开的问题
- TensorFlow试用
热门文章
- bzoj 1558: [JSOI2009]等差数列 (线段树)
- dcount函数C语言,Excel数据库函数
- 西门子PLC1200博途V16程序画面例程,具体项目工艺为制药厂生物发酵系统,程序内有报警,模拟量标定处理,温度PID,称重仪表USS通讯和基本的各种数字量控制
- pod install 报 cannot load such file -- executable-hooks/wrapper (LoadError)
- C#的编码规范中文版(www.idesign.net Author: Juval Lowy) 内容
- BERT除以一个根号dk的作用
- vim c++ ide 拼装
- mybatis-plus分页插件(PaginationInnerInterceptor)报错的问题
- wps软件测试线上面试题分享
- 如何避免Unity动画状态机的蛛网地狱