02-27 周一 图解机器学习SVM-人脸识别之PCA降维
02-27 周一 图解机器学习SVM分类
| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2023年2月27日09:48:38 | V0.1 | 宋全恒 | 新建文档 |
简介
本文主要是在试图代码分析图解机器学习这本书中5.5人脸识别分类(p60),主要的过程是使用PCA技术和SVM技术进行人脸的分类工作。
准备
数据集
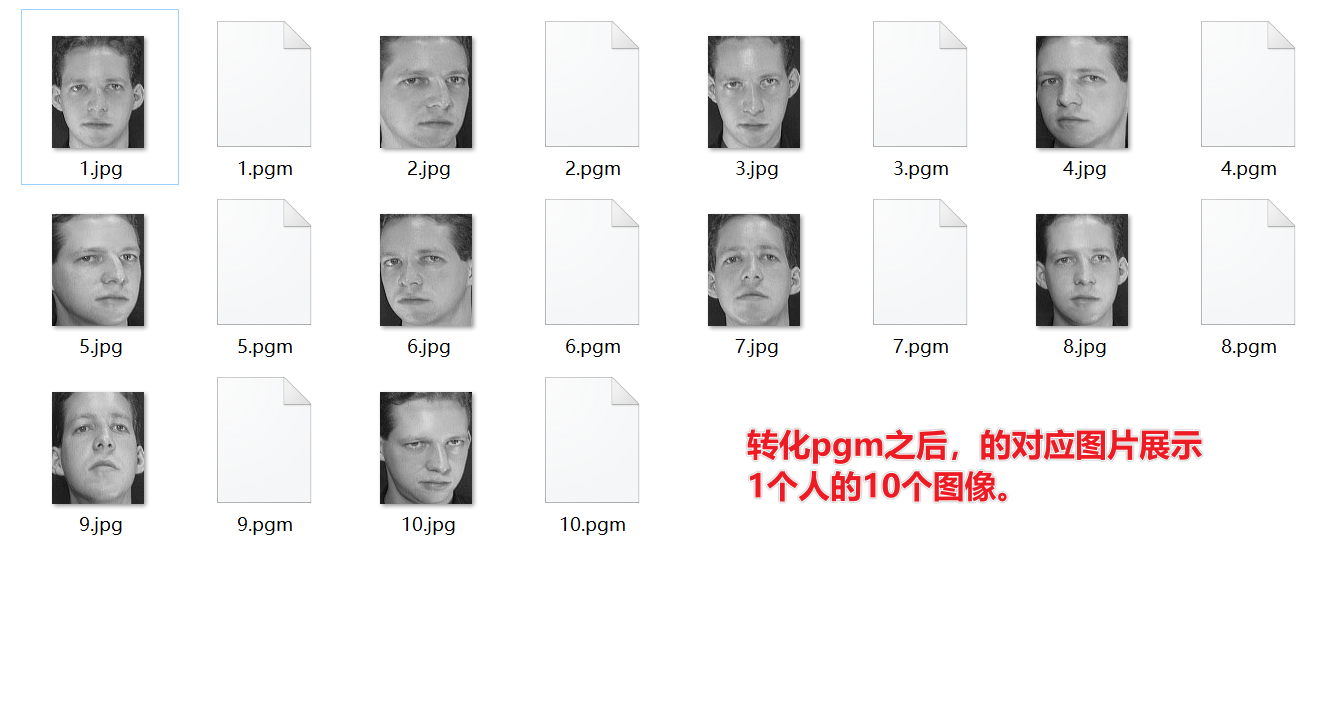
数据集下载,使用的是英国剑桥大学的AT&T人脸数据。程序采用的数据集下载地址为 csdn下载地址,著名人脸识别数据库ORL,已经为大家分类打包好,一共40个人每人10张脸,有正脸、左右侧脸、正脸表情变化等,包括jpg以及pgm格式,保证全面无删减哦。程序使用的是pgm格式,对应的图片如下所示:

注: 核心信息一共有40类样本,每个类中包含包含同一个人的10张图像(112*92)
可以下载pgm格式pgmviewer,但是由于笔者的电脑是win10,无法运行,然后也可以使用线上转换器,查看每个pgm图片的具体图像。
从s1到s40,一共40个文件夹,每个文件夹表示1个人,每个文件夹中一共有10个该人的人脸图片。
环境搭建
由于运行环境使用Linux,并且,需要使用到opencv图像识别库,需要使用python扩展包。
root@9296ffc57f68:/workspace# pip install opencv_python
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting opencv_pythonUsing cached https://pypi.tuna.tsinghua.edu.cn/packages/29/35/a791b550cdeb4efd8b66e921748f2aff938868a29794489d93575d604a02/opencv_python-4.7.0.72-cp37-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (61.8 MB)
Requirement already satisfied: numpy>=1.17.0 in /opt/conda/lib/python3.7/site-packages (from opencv_python) (1.21.2)
Installing collected packages: opencv_python
Successfully installed opencv_python-4.7.0.72
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[notice] A new release of pip available: 22.2.1 -> 23.0.1root@9296ffc57f68:/workspace# pip install opencv-python-headless
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting opencv-python-headlessDownloading https://pypi.tuna.tsinghua.edu.cn/packages/3f/45/21fc904365f9cea3559e0192349bfe3ea2dce52672c1d9127c3b59711804/opencv_python_headless-4.7.0.72-cp37-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (49.2 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 49.2/49.2 MB 506.4 kB/s eta 0:00:00
Requirement already satisfied: numpy>=1.17.0 in /opt/conda/lib/python3.7/site-packages (from opencv-python-headless) (1.21.2)
Installing collected packages: opencv-python-headless
Successfully installed opencv-python-headless-4.7.0.72
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[notice] A new release of pip available: 22.2.1 -> 23.0.1程序调整
程序主要调整了PICTURE_PATH参数的初始值,并且使用os.path.join构造了每个图像的值。
# PICTURE_PATH为图像存放目录位置,注意读者需要修改为自己电脑存放图像的目录
PICTURE_PATH = "/workspace/att_faces"
def get_Image(): #读取图像程序for i in range(1,41): #循环读取所以图片文件for j in range(1,11):path =os.path.join(PICTURE_PATH, "s"+str(i), str(j)+".pgm") #路径img = cv2.imread(path) #使用imread函数读取图像
#生活中大多数看到的彩色图像都是RGB类型,但是图像处理时,需要用到灰度图、二值图、HSV、HSI等颜色制式,opencv的cvtColor()函数来实现这些功能img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)h,w = img_gray.shape #图像的尺寸信息赋值给变量h和wimg_col = img_gray.reshape(h*w) #使用reshape函数对图像进行处理all_data_set.append(img_col) #将图像添加到数据集all_data_set中all_data_label.append(i) #确定图像对应的标签值return h,w
程序理解
全部程序
#%程序5-3 人脸识别程序,名称:facerecognizition.py
#导入相关支持库
from time import time
import logging
import matplotlib.pyplot as plt
import cv2
#从sklearn导入相关模型和svm算法
from numpy import *
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA
from sklearn.svm import SVC
# PICTURE_PATH为图像存放目录位置,注意读者需要修改为自己电脑存放图像的目录
PICTURE_PATH = "/workspace/att_faces"
def get_Image(): #读取图像程序for i in range(1,41): #循环读取所以图片文件for j in range(1,11):path =os.path.join(PICTURE_PATH, "s"+str(i), str(j)+".pgm") #路径img = cv2.imread(path) #使用imread函数读取图像
#生活中大多数看到的彩色图像都是RGB类型,但是图像处理时,需要用到灰度图、二值图、HSV、HSI等颜色制式,opencv的cvtColor()函数来实现这些功能img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)h,w = img_gray.shape #图像的尺寸信息赋值给变量h和wimg_col = img_gray.reshape(h*w) #使用reshape函数对图像进行处理all_data_set.append(img_col) #将图像添加到数据集all_data_set中all_data_label.append(i) #确定图像对应的标签值return h,w all_data_set = [] #变量all_data_set初始化为空
all_data_label = [] # 变量all_data_label初始化为空
h,w = get_Image() #调用定义的get_Image()函数获取图像
X =array(all_data_set) #使用all_data_set作为参数定义数组赋值给变量X
y = array(all_data_label) #使用all_data_ label作为参数定义数组赋值给变量y
n_samples,n_features = X.shape #X数组中的图像信息赋值给变量n_samples,n_features
n_classes = len(unique(y)) #得到变量y的长度赋值给n_classes
target_names = [] #变量target_names初始化为空
for i in range(1,41): #循环读取names = "person" + str(i) #定义变量names,并赋值
target_names.append(names) #变量target_names不断添加信息的names
#打印输出:数据集总规模,n_samples和n_features
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
#程序划分,一部分用于训练集,另一部分用于测试集,这里使用3/4数据用于训练,1/4数据用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
n_components = 20
#打印输出信息
print("Extracting the top %d eigenfaces from %d faces"% (n_components, X_train.shape[0]))
t0 = time()
pca = PCA(n_components=n_components, svd_solver='randomized', #选择一种svd方式whiten=True).fit(X_train) #whiten是一种数据预处理方式,会损失一些数据信息,但可获得更好的预测结果
print("done in %0.3fs" % (time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w)) #特征脸
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train) #得到训练集投影系数
X_test_pca = pca.transform(X_test) #得到测试集投影系数
print("done in %0.3fs" % (time() - t0)) #打印出来时间程序理解
函数定义-实现图像数据和标签
def get_Image(): #读取图像程序for i in range(1,41): #循环读取所以图片文件for j in range(1,11):path =os.path.join(PICTURE_PATH, "s"+str(i), str(j)+".pgm") #路径img = cv2.imread(path) #使用imread函数读取图像
#生活中大多数看到的彩色图像都是RGB类型,但是图像处理时,需要用到灰度图、二值图、HSV、HSI等颜色制式,opencv的cvtColor()函数来实现这些功能img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)h,w = img_gray.shape #图像的尺寸信息赋值给变量h和wimg_col = img_gray.reshape(h*w) #使用reshape函数对图像进行处理all_data_set.append(img_col) #将图像添加到数据集all_data_set中all_data_label.append(i) #确定图像对应的标签值return h,w
上述主要是进行数据的加载,而且是加载了所有的图像,两个没有用过的函数,1个是cv2.imread,一个是reshape。
cv2.imread
具体可参见 cv2.imread,用于将磁盘上的图像文件加载到内存中,读取之后的效果如下:
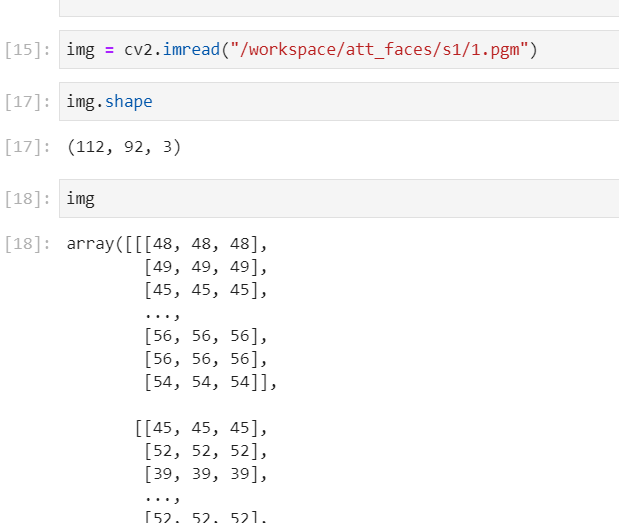
cv2.imread()有两个参数,第一个参数filename是图片路径,第二个参数flag表示图片读取模式,共有三种:
cv2.IMREAD_COLOR:加载彩色图片,这个是默认参数,可以直接写1。
cv2.IMREAD_GRAYSCALE:以灰度模式加载图片,可以直接写0。
cv2.IMREAD_UNCHANGED:包括alpha(包括透明度通道),可以直接写-1
cv2.imread()读取图片后以多维数组的形式保存图片信息,前两维表示图片的像素坐标,最后一维表示图片的通道索引,具体图像的通道数由图片的格式来决定。
cvtCololr
接下来是把三通道的图像转化为灰度图。cv2.cvtColor(p1,p2) 是颜色空间转换函数,p1是需要转换的图片,p2是转换成何种格式。
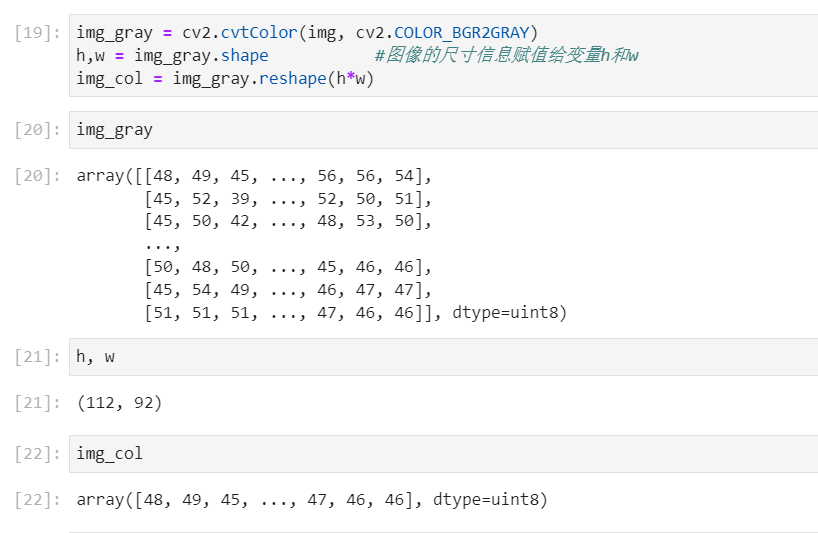
上述代码涉及了颜色空间的转换,具体可以参见 cv2.imread()和cv2.cvtColor() 的使用。灰度图的理解如下:

数据概览
all_data_set = [] #变量all_data_set初始化为空
all_data_label = [] # 变量all_data_label初始化为空
h,w = get_Image() #调用定义的get_Image()函数获取图像
X =array(all_data_set) #使用all_data_set作为参数定义数组赋值给变量X
y = array(all_data_label) #使用all_data_ label作为参数定义数组赋值给变量y
n_samples,n_features = X.shape #X数组中的图像信息赋值给变量n_samples,n_features
n_classes = len(unique(y)) #得到变量y的长度赋值给n_classes
target_names = [] #变量target_names初始化为空
for i in range(1,41): #循环读取names = "person" + str(i) #定义变量names,并赋值target_names.append(names) #变量target_names不断添加信息的names
#打印输出:数据集总规模,n_samples和n_features
print("Total dataset size:")
print(" n_samples: %d" % n_samples)
print(" n_features: %d" % n_features)range(1, 41)返回的数据是1到40的序列,左包含,右不包含。
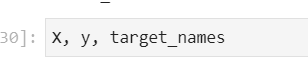
此时X,y,target_names的结果如下:

train_test_split进行训练和测试数据划分

从上可以看出当前样本数一共有400个数据,特征为10304维度。
程序使用train_test_split来进行训练和测试数据的拆分。
train_test_split方法能够将数据集按照用户的需要指定划分为训练集和测试集。一组用来进行训练,而另外一组用来进行测试。
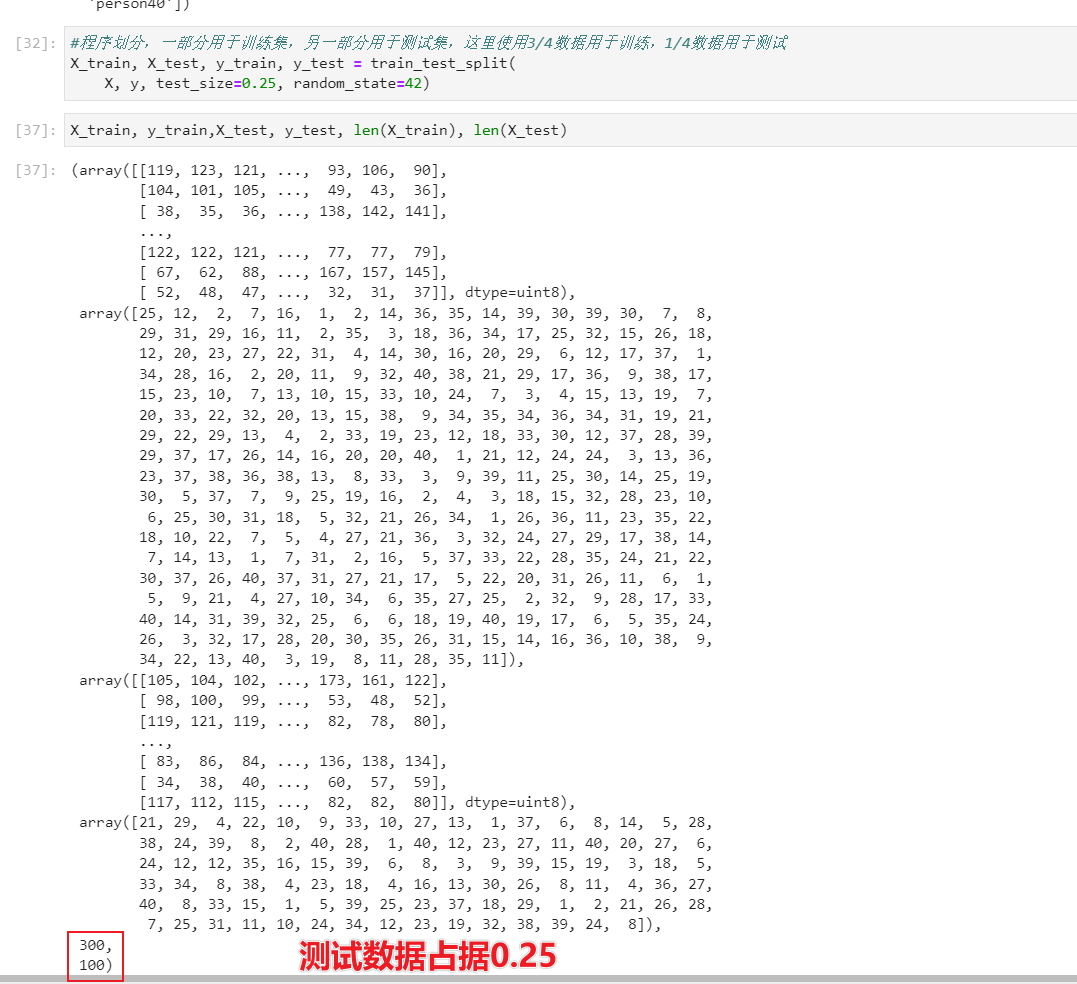
#程序划分,一部分用于训练集,另一部分用于测试集,这里使用3/4数据用于训练,1/4数据用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
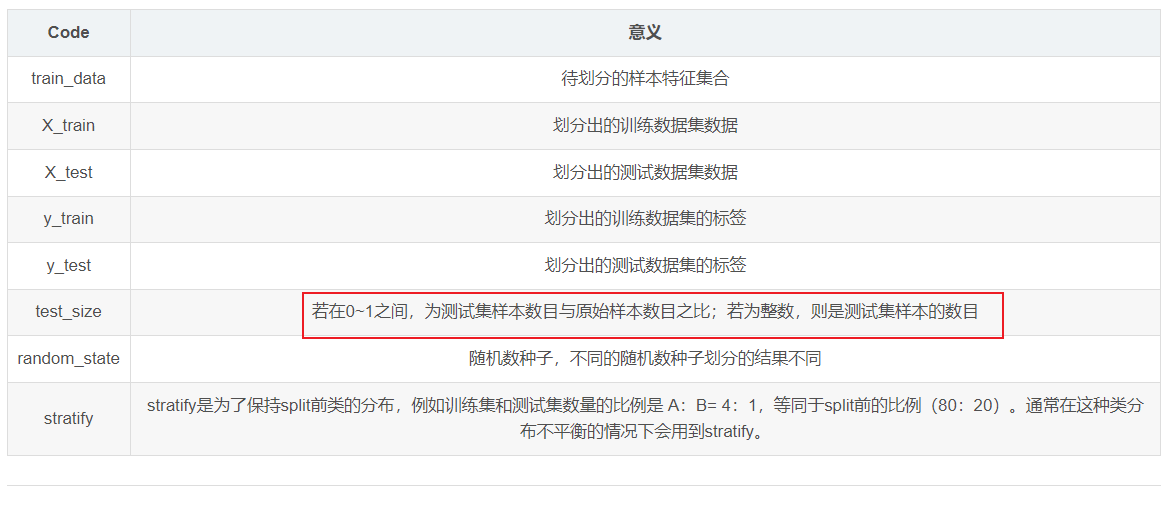
函数参数含义如下:
X_train,X_test, y_train, y_test =train_test_split(train_data,train_target,test_size=0.25, random_state=0,stratify=y)
# train_data:所要划分的样本特征集
# train_target:所要划分的样本结果
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:是随机数的种子。
# 随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
划分结果为:
PCA主成分获取
n_components = 20
#打印输出信息
print("Extracting the top %d eigenfaces from %d faces"% (n_components, X_train.shape[0]))
t0 = time()
pca = PCA(n_components=n_components, svd_solver='randomized', #选择一种svd方式whiten=True).fit(X_train) #whiten是一种数据预处理方式,会损失一些数据信息,但可获得更好的预测结果
print("done in %0.3fs" % (time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w)) #特征脸
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train) #得到训练集投影系数
X_test_pca = pca.transform(X_test) #得到测试集投影系数
print("done in %0.3fs" % (time() - t0)) #打印出来时间

通过PCA,实现降维,然后使用pca转化了训练数据和测试数据,上述代码也打印了降维的耗时。
最后一段,主要是要理解PCA主成分分析。
n_components = 20
#打印输出信息
print("Extracting the top %d eigenfaces from %d faces"% (n_components, X_train.shape[0]))
t0 = time()
pca = PCA(n_components=n_components, svd_solver='randomized', #选择一种svd方式whiten=True).fit(X_train) #whiten是一种数据预处理方式,会损失一些数据信息,但可获得更好的预测结果
print("done in %0.3fs" % (time() - t0)) 通过主成分分析,通过指定鬼脸数(Eigenfaces for Recognition)为20,获取pca。
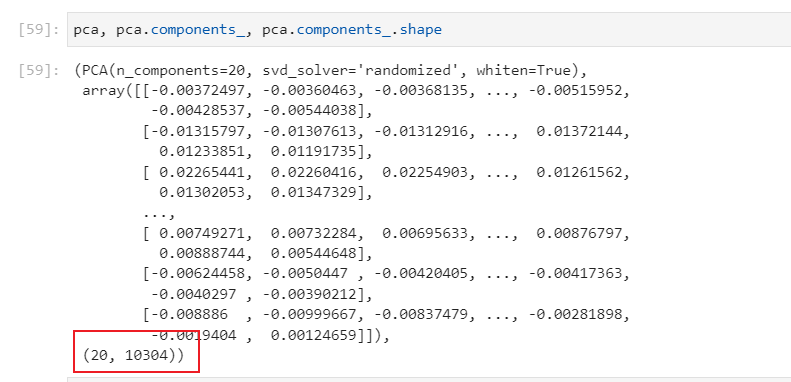
主成分分析方法主要用来降维,因为我们无法直接使用10304维的特征进行SVM,或者说进行协方差矩阵的特征值和特征向量分解,因此通过PCA选择最重要的特征或者说特征向量进行降维,一方面能够保证计算的精(一般PCA的主成分占据95%的特征。)度,同时大大降低计算量。从得到的pca.components_,可以看出得到的特征向量一共20个,在论文中有如下的陈述:
Each individual face can be represented exactly in terms of a linear combination of eigenfaces. Eache face can also be approximated using only the “best” eigenfaces----those that have the largest eigenvalues, and which therefore account for the most variance within the set of face images.The Best M eigenfaces span an M-dimensional subspace—“face space”----of all possible images.
获取投影
最后这部分的代码,主要是使用pca来转化训练数据集和测试数据集,由输出的两个shape可以看出,可以看到300个人脸的特征维度从10304,降维到了20个主成分上了。
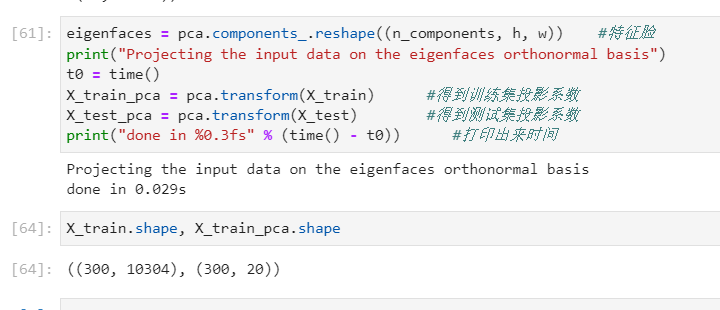
关键
特征脸
特征量的提出是由
一组特征脸可以通过在一大组描述不同人脸的图像上进行主成分分析(PCA)获得。任意一张人脸图像都可以被认为是这些标准脸的组合。例如,**一张人脸图像可能是特征脸1的10%,加上特征脸2的55%,在减去特征脸3的3%。**值得注意的是,它不需要太多的特征脸来获得大多数脸的近似组合。另外,由于人脸是通过一系列向量(每个特征脸一个比例值)而不是数字图像进行保存,可以节省很多存储空间。百度百科。
基本过程是把所有图像组成单一矩阵T,然后计算其协方差矩阵S,计算协方差矩阵S的特征值和特征向量。
这些特征脸可以用于标识已有的和新的人脸:我们可以将一个新的人脸图像(先要减去均值图像)投影到特征脸上,以此来记录这个图像与平均图像的偏差。每一个特征向量的特征值代表了训练集合的图像与均值图像在该方向上的偏差有多大。将图像投影到特征向量的子集上可能丢失信息,但是通过保留那些具有较大特征值的特征向量的方法可以减少这个损失。例如,如果当前处理一个100 x 100的图像,就会得到10000个特征向量。在实际使用中,大多数的图像可以投影到100到150个特征向量上进行识别,因此,10000个特征向量的绝大多数可以丢弃。
感觉这个在读书时,线性代数中是很重要的思想。
特征脸可以参考 特征脸思想。

协方差矩阵的计算过程:
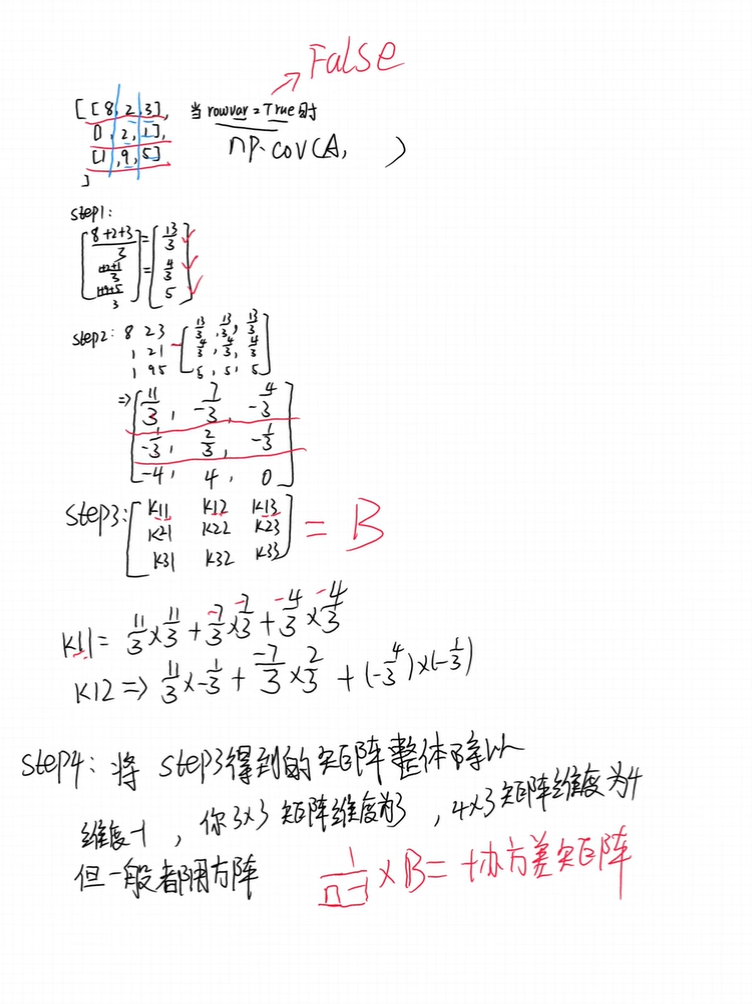

在B站上出了一个特征脸计算的up主分享。


PCA降维
PCA降维可以参考博客 主成分分析(PCA)原理详解
PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。这k维特征称为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。

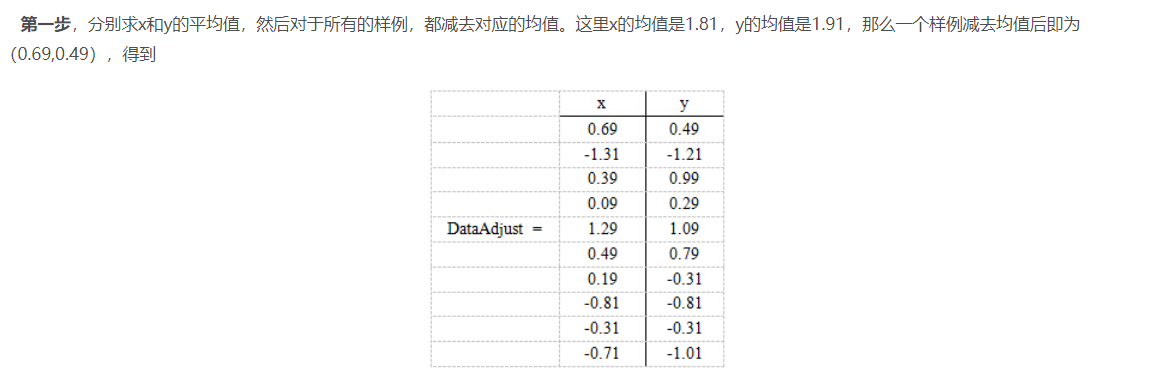


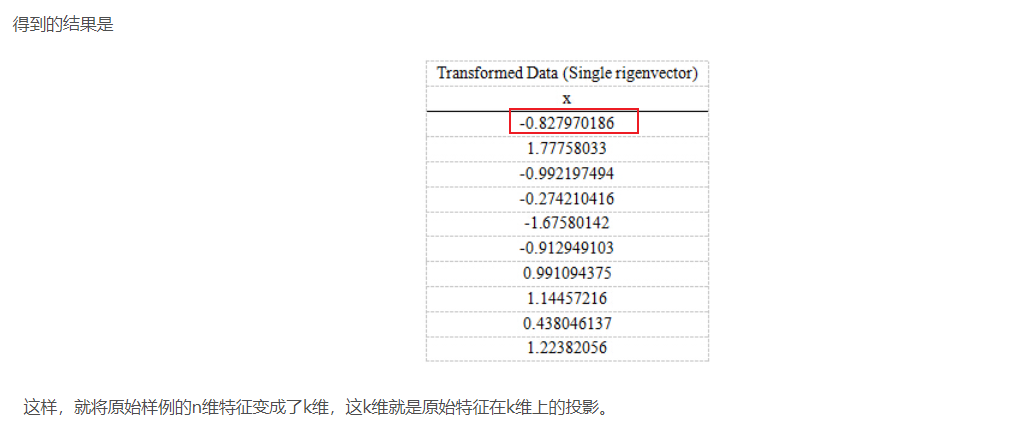
注: 例子表明是将2维特征降低到1维特征。
总结
本文记录了通过PCA降维将原理的(112*92)降维到20个维度的向量的过程。主要是通过该程序串联起了PCA、方差、协方差、标准差,特征值分析和特征值等线性代数,需要恶补。在B站上可以刷到 人脸识别的课程非常的好,一共323分钟。抽时间要好好看一下。
机器学习是一门处理数据的艺术,这个文章简要的描述了由400个样本,通过预处理,得到其协方差矩阵,进而得到协方差矩阵的特征值和特征向量,由这些特征获取主要成分(Principal component)。进而根据主成分得到所有训练样本在主成分即特征向量上的投影。利用降维后的数据进行SVM分类。再保证精度的同时,大大降低了计算的耗时,也算是模糊数学的一种思想实践。

02-27 周一 图解机器学习SVM-人脸识别之PCA降维相关推荐
- 第十九课.基于sklearn的SVM人脸识别
目录 数据集 确定人脸的类别标记 划分训练集和测试集与训练 实验为基于sklearn的SVM人脸识别,使用 SVM 算法对戴眼镜的人脸和不戴眼镜的人脸进行分类,从而完成 识别戴眼镜的人脸 的任务:实验 ...
- 3.4 svm人脸识别
python代码: from __future__ import print_function from time import time import logging import matplotl ...
- 机器学习之人脸识别face_recognition使用
机器学习之人脸识别face_recognition使用 简介 一 二 主要方法介绍 1. load_image_file 加载图像 2. face_locations 定位图中所有人脸 3. face ...
- 麦子学院深度学习视频SVM人脸识别课程代码修改及实现
1.麦子学院深度学习SVM人脸识别原代码对应修改 2.代码实现 1.麦子学院深度学习SVM人脸识别原代码对应修改 1.1 from sklearn.cross_validation import tr ...
- English Learning - L2-3 英音地道语音语调 小元音 [ʌ] [ɒ] [ʊ] [ɪ] [ə] [e] 2023.02.27 周一
English Learning - L2-3 英音地道语音语调 小元音 [ʌ] [ɒ] [ʊ] [ɪ] [ə] [e] 2023.02.27 周一 课前活动 练习方法 大小元音总结 小元音准备工作 ...
- ML之SVM:利用SVM算法对手写数字图片识别数据集(PCA降维处理)进行预测并评估模型(两种算法)性能
ML之SVM:利用SVM算法对手写数字图片识别数据集(PCA降维处理)进行预测并评估模型(两种算法)性能 目录 输出结果 设计思路 核心代码 输出结果 设计思路 核心代码 estimator = PC ...
- 白话机器学习算法理论+实战之PCA降维
1. 写在前面 如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,比如我之前写过的一篇十大机器学习算法的小总结,在这简单的先捋一捋, 常见的机器学习算法: 监督学习算法:逻辑 ...
- svm rbf人脸识别 yale_实操课——机器学习之人脸识别
SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法.在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别.分类以及回归分析.在n维空间中找到一个分类超 ...
- 【机器学习超详细】机器学习案例之SVM人脸识别技术应用 PCA降维 结果可视化 支持向量机
基础知识介绍: LFW人脸识别数据集(http://vis-www.cs.umass.edu/lfw/) 该实验可以在JupyterNotebook上运行,也可在其他Python程序上运行.(本人习惯 ...
最新文章
- 《数据库系统概念》9-附加关系运算
- python内置的读取文件函数_python基础(内置函数+文件操作+lambda)
- db2 两个结构相同的表_从两个工作表提取数据记录,并显示相同记录的报告
- mysql实时增量备份
- java异常日志不要只打一半,要输出全部错误信息
- EasyRecovery如何恢复ps的psd文件
- Apache Flink 零基础入门教程(六):状态管理及容错机制
- 《Python算法教程_中文版》pdf
- 【2021/7/19 更新】【梳理】简明操作系统原理 附录一 虚拟内存子系统案例选讲(VAX/VMS + Linux)(docx)
- dnfdpl服务器维护了,梦想开始的地方丨山东沙排女将王鑫鑫奥运首秀止步八强 怕影响训练父母没来济南探望过...
- 2、slf4j绑定JUL(桥接模式)
- 从理解透视到场景构图
- 安装CentOS 时找不到硬盘( no usable disks have been found)的解决方法
- 内存系列三:内存初始化浅析
- 路由与交换-华为eNSP-交换机上配置DHCP技术
- 模电数电大全百度网盘,本人亲测有效
- 无纸化案例分析之一——21位标准长方形会议室
- 09高温假旅行——青烟蓬长大
- 电脑系统崩溃 or 卡顿?如何重置Windows 1011系统
- CDMA手机鉴权的过程说明