DDD微服务架构设计第三课 DDD领域中的聚合、工厂和仓库、限界上下文
05 聚合、仓库与工厂:傻傻分不清楚
上一讲,我们知道了,要将领域模型最终转换为程序设计,可以落实到 3 种类型的对象设计,即服务、实体与值对象,然后进行一些贫血模型与充血模型的设计思路。但这远远不够,还需要有聚合、仓库与工厂的设计。
聚合的设计思路
聚合是领域驱动设计中一项非常重要的设计与概念,它表达的是真实世界中那些整体与部分的关系,比如订单与订单明细、表单与表单明细、发票与发票明细。以订单为例,在真实世界中,订单与订单明细本来是同一个事物,订单明细是订单中的一个属性。但是,由于在关系型数据库中没有办法在一个字段中表达一对多的关系,因此必须将订单明细设计成另外一张表。
尽管如此,在领域模型的设计中,我们又将其还原到真实世界中,以“聚合”的形式进行设计。在领域模型中,即将订单明细设计成订单中的一个属性,具体代码如下:
public class Order {private Set<Items> items;public void setItems(Set<Item> items){this.items = items;}public Set<Item> getItems(){return this.items;}……
}
有了这样的设计,在创建订单的时候,将不再单独创建订单明细了,而是将订单明细创建在订单中;在保存订单的时候,应当同时保存订单表与订单明细表,并放在同一事务中;在查询订单时,应当同时查询订单表与订单明细表,并将其装配成一个订单对象。这时候,订单就作为一个整体在进行操作,不需要再单独去操作订单明细。
也就是说,对订单明细的操作是封装在订单对象内部的设计实现。对于客户程序来说,去使用订单对象就好了,这就包括了作为属性去访问订单对象中的订单明细,而不再需要关注它内部是如何操作的。
按照以下思路进行的设计就是聚合:
当创建或更新订单时,在订单对象中填入或更新订单的明细就好了;
当保存订单时,只需要将订单对象作为整体去保存,而不需要关心订单数据是怎么保存的、保存到哪几张表中、是不是有事务,保存数据库的所有细节都封装在了订单对象内部;
当删除订单时,删除订单对象就好了,至于如何删除订单明细,是订单对象内部的实现,外部的程序不需要关注;
当查询或装载订单时,客户程序只需要根据查询语句或 ID 查询订单对象就好了,查询程序会在查询过程中自动地去补填订单对应的订单明细。
聚合体现的是一种整体与部分的关系。正是因为有这样的关系,在操作整体的时候,整体就封装了对部分的操作。但并非所有对象间的关系都有整体与部分的关系,而那些不是整体与部分的关系是不能设计成聚合的。因此,正确地识别聚合关系就变得尤为重要。
所谓的整体与部分的关系,就是当整体不存在时,部分就变得没有了意义。部分是整体的一个部分,与整体有相同的生命周期。比如,只有创建了这张订单,才能创建它的订单明细;如果没有了这张订单,那么它的订单明细就变得没有意义,就需要同时删除掉。这样的关系才具备整体与部分的关系,才是聚合。
譬如:订单与用户之间的关系就不是聚合。因为用户不是创建订单时才存在的,而是在创建订单时早就存在了;当删除订单时,用户不会随着订单的删除而删除,因为删除了订单,用户依然还是那个用户。
那么,饭店和菜单的关系是不是聚合关系呢?关键要看系统如何设计。如果系统设计成每个饭店都有各不相同的菜单,每个菜单都是隶属于某个饭店,则饭店和菜单是聚合关系。这种设计让各个饭店都有“宫保鸡丁”,但每个饭店都是各自不同的“宫保鸡丁”,比如在描述、图片或价格上的不同,甚至在数据库中也是有各不相同的记录。这时,要查询菜单就要先查询饭店,离开了饭店的菜单是没有意义的。
但是,饭店和菜单还可以有另外一种设计思路,那就是所有的菜单都是公用的,去每个饭店只是选择有还是没有这个菜品。这时,系统中有一个菜单对象,“宫保鸡丁”只是这个对象中的一条记录,其他各个饭店,如果他们的菜单上有“宫保鸡丁”,则去引用这个对象,否则不引用。这时,菜单就不再是饭店的一个部分,没有这个饭店,这个菜品依然存在,就不再是聚合关系。
因此,判断聚合关系最有效的方法就是去探讨:如果整体不存在时,部分是否存在。如果不存在,就是聚合;反之,则不是。
聚合根——外部访问的唯一入口
有了聚合关系,部分就会被封装在整体里面,这时就会形成一种约束,即外部程序不能跳过整体去操作部分,对部分的操作都必须要通过整体。这时,整体就成了外部访问的唯一入口,被称为 “聚合根”。
也就是说,一旦将对象间的关系设计成了聚合,那么外部程序只能访问聚合根,而不能访问聚合中的其他对象。这样带来的好处就是,当聚合内部的业务逻辑发生变更时,只与聚合内部有关,只需要对聚合内部进行更新,与外部程序无关,从而有效降低了变更的维护成本,提高了系统的设计质量。
然而,这样的设计有时是有效的,但并非都有效。譬如,在管理订单时,对订单进行增删改,聚合是有效的。但是,如果要统计销量、分析销售趋势、销售占比时,则需要对大量的订单明细进行汇总、进行统计;如果每次对订单明细的汇总与统计都必须经过订单的查询,必然使得查询统计变得效率极低而无法使用。
因此,领域驱动设计通常适用于增删改的业务操作,但不适用于分析统计。在一个系统中,增删改的业务可以采用领域驱动的设计,但在非增删改的分析汇总场景中,则不必采用领域驱动的设计,直接 SQL 查询就好了,也就不必再遵循聚合的约束了。
聚合的设计实现
前面谈到了领域驱动设计中一个非常重要的概念:聚合。通过聚合的设计,可以真实地反映现实世界的状况,提高软件设计的质量,有效降低日后变更的成本。然而,前面只提出了聚合的概念,要想真正将聚合落实到软件设计中,还需要两个非常重要的组件:仓库与工厂。
比如,现在创建了一个订单,订单中包含了多条订单明细,并将它们做成了一个聚合。这时,当订单完成了创建,就需要保存到数据库里,怎么保存呢?需要同时保存订单表与订单明细表,并将其做到一个事务中。这时候谁来负责保存,并对其添加事务呢?
过去我们采用贫血模型,那就是通过订单 DAO 与订单明细 DAO 去完成数据库的保存,然后由订单 Service 去添加事务。这样的设计没有聚合、缺乏封装性,不利于日后的维护。那么,采用聚合的设计应当是什么样呢?
采用了聚合以后,订单与订单明细的保存就会封装在订单仓库中去实现。也就是说采用了领域驱动设计以后,通常就会实现一个仓库(Repository) 去完成对数据库的访问。那么,仓库与数据访问层(DAO)有什么区别呢?
一般来说,数据访问层就是对数据库中某个表的访问,比如订单有订单 DAO、订单明细有订单明细 DAO、用户有用户 DAO。
当数据要保存到数据库中时,由 DAO 负责保存,但保存的是某个单表,如订单 DAO 保存订单表、订单明细 DAO 保存订单明细表、用户 DAO 保存用户表;
当数据要查询时,还是通过 DAO 去查询,但查询的也是某个单表,如订单 DAO 查订单表、订单明细 DAO 查订单明细表。
那么,如果在查询订单的时候要显示用户名称,怎么办呢?做另一个订单对象,并在该对象里增加“用户名称”。这样,通过订单 DAO 查订单表时,在 SQL 语句中 Join 用户表,就可以完成数据的查询。这时会发现,在系统中非常别扭地设计了两个或多个订单对象,并且新添加的订单对象与领域模型中的订单对象有较大的差别,显得不够直观。系统简单时还好说,但系统的业务逻辑变得越来越复杂时,程序阅读起来越来越困难,变更就变得越来越麻烦。
因此,在应对复杂业务系统时,我们希望程序设计能较好地与领域模型对应上:领域模型是啥样,程序就设计成啥样。我们就将订单对象设计成这样,订单对象的关联设计代码如下:
public class Order {......private Long customer_id;private Customer customer;private List<OrderItem> orderItems;/*** @return the customerId*/public Long getCustomerId() {return customer_id;}/*** @param customerId the customerId to set*/public void setCustomerId(Long customerId) {this.customer_id = customerId;}/*** @return the customer*/public Customer getCustomer() {return customer;}/*** @param customer the customer to set*/public void setCustomer(Customer customer) {this.customer = customer;}/*** @return the orderItems*/public List<OrderItem> getOrderItems() {return orderItems;}/*** @param orderItems the orderItems to set*/public void setOrderItems(List<OrderItem> orderItems) {this.orderItems = orderItems;}
}

可以看到,在订单对象中加入了对用户对象和订单明细对象的引用:
订单对象与用户对象是多对一关系,做成对象引用;
订单对象与订单明细对象是一对多关系,做成对集合对象的引用。
这样,当订单对象在创建时,在该对象中填入 customerId,以及它对应的订单明细集合 orderItems;然后交给订单仓库去保存,在保存时,就进行了一个封装,同时保存订单表与订单明细表,并在其上添加了一个事务。
这里要特别注意,对象间的关系是否是聚合关系,它们在保存的时候是有差别的。譬如,在本案例中,订单与订单明细是聚合关系,因此在保存订单时还要保存订单明细,并放到同一事务中;然而,订单与用户不是聚合关系,那在保存订单时不会去操作用户表,只有在查询时,比如在查询订单的同时,才要查询与该订单对应的用户。
这是一个比较复杂的保存过程。然而,通过订单仓库的封装,对于客户程序来说不需要关心它是怎么保存的,它只需要在领域对象建模的时候设定对象间的关系,即将其设定为“聚合”就可以了。既保持了与领域模型的一致性、又简化了开发,使得日后的变更与维护变得简单。至于仓库的设计实现,将在后面的课程中讲解。
有了这样的设计,装载与查询又应当怎样去做呢?所谓的 “装载(Load)”,就是通过主键 ID 去查询某条记录。比如,要装载一个订单,就是通过订单 ID 去查询该订单,那么订单仓库是如何实现对订单的装载呢?
首先,比较容易想到的是,用 SQL 语句到数据库里去查询这张订单。与 DAO 不同的是:
订单仓库在查询订单时,只是简单地查询订单表,不会去 Join 其他表,比如 Join 用户表,不会做这些事情;
当查询到该订单以后,将其封装在订单对象中,然后再去通过查询补填用户对象、订单明细对象;
通过补填以后,就会得到一个用户对象、多个订单明细对象,需要将它们装配到订单对象中。
这时,那些创建、装配的工作都交给了另外一个组件——工厂来完成。
DDD 的工厂
DDD 中的工厂,与设计模式中的工厂不是同一个概念,它们是有差别的。在设计模式中,为了避免调用方与被调方的依赖,将被调方设计成一个接口下的多个实现,将这些实现放入工厂中。这样,调用方通过一个 key 值就可以从工厂中获得某个实现类。工厂就负责通过 key 值找到对应的实现类,创建出来,返回给调用方,从而降低了调用方与被调方的耦合度。
而 DDD 中的工厂,与设计模式中的工厂唯一的共同点可能就是,它们都要去做创建对象的工作。
DDD 中的工厂,主要的工作是通过装配,创建领域对象,是领域对象生命周期的起点。譬如,系统要通过 ID 装载一个订单:
这时订单仓库会将这个任务交给订单工厂,订单工厂就会分别调用订单 DAO、订单明细 DAO 和用户 DAO 去进行查询;
然后将得到的订单对象、订单明细对象、用户对象进行装配,即将订单明细对象与用户对象,分别 set 到订单对象的“订单明细”与“用户”属性中;
最后,订单工厂将装配好的订单对象返回给订单仓库。
这些就是 DDD 中工厂要做的事情。
DDD 的仓库
然而,当订单工厂将订单对象返回给订单仓库以后,订单仓库不是简单地将该对象返回给客户程序,它还有一个缓存的功能。在DDD 中“仓库”的概念,就是如果服务器是一个非常强大的服务器,那么我们不需要任何数据库。系统创建的所有领域对象都放在仓库中,当需要这些对象时,通过 ID 到仓库中去获取。
但是,在现实中没有那么强大的仓库,因此仓库在内部实现时,会将领域对象持久化到数据库中。数据库是仓库进行数据持久化的一种内部实现,它也可以有另外一种内部实现,就是将最近反复使用的领域对象放入缓存中。这样,当客户程序通过 ID 去获取某个领域对象时,仓库会通过这个 ID 先到缓存中进行查找:
查找到了,则直接返回,不需要查询数据库;
没有找到,则通知工厂,工厂调用 DAO 去数据库中查询,然后装配成领域对象返回给仓库。
仓库在收到这个领域对象以后,在返回给客户程序的同时,将该对象放到缓存中。
以上是通过 ID 装载订单的过程,那么通过某些条件查询订单的过程又是怎么做呢?查询订单的操作同样是交给订单仓库去完成。
订单仓库会先通过订单 DAO 去查询订单表,但这里是只查询订单表,不做 Join 操作;
订单 DAO 查询了订单表以后,会进行一个分页,将某一页的数据返回给订单仓库;
这时,订单仓库就会将查询结果交给订单工厂,让它去补填其对应的用户与订单明细,完成相应的装配,最终将装配好的订单对象集合返回给仓库。
简而言之,采用领域驱动的设计以后,对数据库的访问就不是一个简单的 DAO 了,这不是一种好的设计。通过仓库与工厂,对原有的 DAO 进行了一层封装,在保存、装载、查询等操作中,加入聚合、装配等操作。并将这些操作封装起来,对上层的客户程序屏蔽。这样,客户程序不需要以上这些操作,就能完成领域模型中的各自业务。技术门槛降低了,变更与维护也变得简便了。
总结
本讲讲解了 DDD 中一个非常重要的设计思想:聚合,以及它的设计实现:工厂与仓库,它们是 DDD 中充血模型设计的重要支柱。通过这些设计我们会发现,它们与我们传统的基于 DAO 的贫血模型设计有诸多的不同。
通过聚合实现了整体与部分的关系,客户程序只能操作整体,而将对部分的操作封装在了仓库与工厂中;
客户程序不必关注对数据库的操作,操作仓库就好了。对缓存、对数据库的操作都封装在了仓库与工厂中,从而降低了业务开发的技术门槛与开发工作量;
对数据的查询不再通过 SQL 语句进行 Join,而是通过工厂进行补填与装配。这样的设计更有利于微服务的设计与大数据的调优。
它们为软件系统提高设计质量、降低维护成本以及应对高并发,提供了很好的设计。
另外,一个值得思考的问题就是,传统的领域驱动设计,是每个模块自己去实现各自的仓库与工厂,这样会大大增加开发工作量。但这些仓库与工厂的设计大致都是相同的,会催生大量的重复代码。能不能通过抽象,提取出共性,形成通用的仓库与工厂,下沉到底层技术中台中,从而进一步降低领域驱动的开发成本与技术门槛?也就是说,实现领域驱动设计还需要相应的平台架构支持。关于这些方面的思路,我们将在 DDD 的架构设计部分进一步探讨。
下一讲将讲解 DDD 的另一个重要概念:限界上下文,以及它在微服务设计中的重要作用。
06 限界上下文:冲破微服务设计困局的利器
上一讲我们以用户下单这个场景,讲解了领域驱动设计的建模、分析与设计的过程,然而,站在更大的电商网站的角度,用户下单只是其中一个很小的场景。
那么,如果要对整个电商网站进行领域驱动设计,应当怎么做呢?它包含那么多场景,每个场景都要包含那么多的领域对象,进而会形成很多的领域对象,并且每个领域对象之间还有那么多复杂的关联关系。这时候,怎样通过领域驱动来设计这个系统呢?怎么去绘制领域模型呢?是绘制一张密密麻麻的大图,还是绘制成一张一张的小图呢?学完本讲后,将能解决这些问题。
问题域和限界上下文
假如将整个系统中那么多的场景、涉及的那么多领域对象,全部绘制在一张大图上,可以想象这张大图需要绘制出密密麻麻的领域对象,以及它们之间纷繁复杂的对象间关系。绘制这样的图,绘制的人非常费劲,看这张图的人也非常费劲,这样的图也不利于我们理清思路、交流思想及提高设计质量。
正确的做法就是将整个系统划分成许多相对独立的业务场景,在一个一个的业务场景中进行领域分析与建模,这样的业务场景称为 “问题子域”,简称“子域”。
领域驱动核心的设计思想,就是将对软件的分析与设计还原到真实世界中,那么就要先分析和理解真实世界的业务与问题。而真实世界的业务与问题叫作 “问题域”,这里面的业务规则与知识叫 “业务领域知识”,譬如:
电商网站的“问题域”是人们如何进行在线购物,购物的流程是怎样的;
在线订餐系统的“问题域”是人们如何在线订餐,饭店如何在线接单,系统又是如何派送骑士去配送的。
然而,不论是电商网站还是在线购物系统,都有一个非常庞大而复杂的问题域。要一次性分析清楚这个问题域对我们来说是有难度的,因此需要采用 “分而治之”的策略,将这个问题域划分成许多个问题子域。比如:
电商网站包含了用户选购、下单、支付、物流等多个子域;
在线订餐系统包含了用户下单、饭店接单、骑士派送等子域。
如果某个子域比较复杂,在子域的基础上还可以进一步划分子域。
因此,一个复杂系统的领域驱动设计,就是以子域为中心进行领域建模,绘制出一张一张的领域模型设计,然后以此作为基础指导程序设计。这一张一张的领域模型设计,称为“限界上下文”(Context Bounds,CB)。
DDD 中限界上下文的设计,很好地体现了高质量软件设计中 “单一职责原则” 的要求,即每个限界上下文中实现的都是软件变化同一个原因的业务。比如,“用户下单”这个限界上下文都是实现用户下单的相关业务。这样,当“用户下单”的相关业务发生变更的时候,只与“用户下单”这个限界上下文有关,只需要对它进行修改就行了,与其他限界上下文无关。这样,需求变更的代码修改范围缩小了,维护成本也就降低了。
在用户下单的过程中,对用户信息的读取是否也应该在“用户下单”这个限界上下文中实现呢?答案是否定的,因为读取用户信息不是用户下单的职责,当用户下单业务发生变更的时候,用户信息不一定变;用户信息变更的时候,用户下单也不一定变,它们是软件变化的两个原因。
因此,应当将读取用户信息的操作交给“用户信息管理”限界上下文,“用户下单”限界上下文只是对它的接口进行调用。通过这样的划分,实现了限界上下文内的高内聚和限界上下文间的低耦合,可以很好地降低日后代码变更的成本、提高软件设计质量。而限界上下文之间的这种相互关系,称为“上下文地图”(Context Map)。
限界上下文与微服务
所谓“限界上下文内的高内聚”,也就是每个限界上下文内实现的功能,都是软件变化的同一个原因的代码。因为这个原因的变化才需要修改这个限界上下文,而不是这个原因的变化就不需要修改这个限界上下文,修改与它无关。正是因为限界上下文有如此好的特性,才使得现在很多微服务团队,运用限界上下文作为微服务拆分的原则,即每个限界上下文对应一个微服务。

按照这样的原则拆分出来的微服务系统,在今后变更维护时,可以很好地将每次的需求变更,快速落到某个微服务中变更。这样,变更这个微服务就实现了该需求,升级该服务后就可以交付用户使用了。这样的设计,使得越来越多的规划开发团队,今后可以实现低成本维护与快速交付,进而快速适应市场变化而提升企业竞争力。
譬如,在电商网站的购物过程中,购物、下单、支付、物流,都是软件变化不同的原因,因此,按照不同的业务场景划分限界上下文,然后以此拆分微服务。那么,当购物变更时就修改购物微服务,下单变更就修改下单微服务,但它们在业务处理过程中都需要读取商品信息,因此调用“商品管理”微服务来获取商品信息。这样,一旦商品信息发生变更,只与“商品管理”微服务有关,与其他微服务无关,那么维护成本将得到降低,交付速度得到提升。
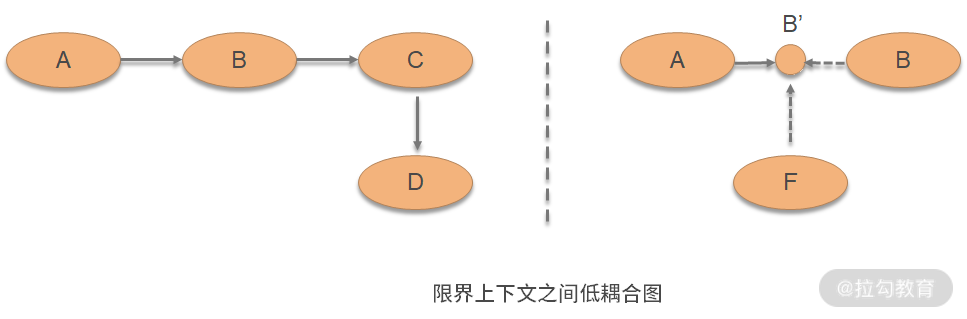
所谓“限界上下文间的低耦合”,就是限界上下文通过上下文地图相互调用时,通过接口进行调用。如下图所示,模块 A 需要调用模块 B,那么它就与模块 B 形成了一种耦合,这时:
如果需要复用模块 A,那么所有有模块 A 的地方都必须有模块 B,否则模块 A 就会报错;
如果模块 B 还要依赖模块 C,模块 C 还要依赖模块 D,那么所有使用模块 A 的地方都必须有模块 B、C、D,使用模块 A 的成本就会非常高昂。
然而,如果模块 A 不是依赖模块 B,而是依赖接口 B',那么所有需要模块 A 的地方就不一定需要模块 B;如果模块 F 实现了接口 B',那么模块 A 调用模块 F 就可以了。这样,调用方和被调用方的耦合就被解开。
在代码实现时,可以通过微服务来实现“限界上下文间”的“低耦合”。比如,“下单”微服务要去调用“支付”微服务。在设计时:
首先在“下单”微服务中增加一个“支付”接口,这样在“下单”微服务中所有对支付的调用,都是对该接口的调用;
接着,在其他“支付”微服务中实现支付,比如,现在设计了 A、 B 两个“支付”微服务,在系统运行时配置的是 A 服务,那么“下单”微服务调用的就是 A;如果配置的是 B 服务,调用的就是 B。
这样,“下单”微服务与“支付”微服务之间的耦合就被解开,使得系统可以通过修改配置,去应对各种不同的用户环境与需求。
有了限界上下文的设计,使得系统在应对复杂应用时,设计质量提高、变更成本降低。
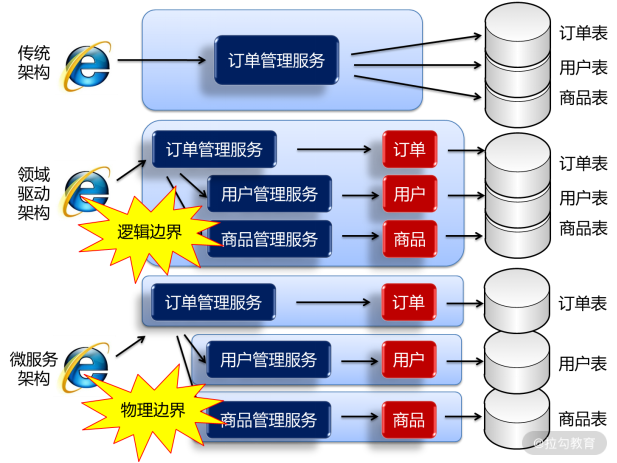
过去,每个模块在读取用户信息时,都是直接读取数据库中的用户信息表,那么一旦用户信息表发生变更,各个模块都要变更,变更成本就会越来越高。
现在,采用领域驱动设计,读取用户信息的职责交给了“用户管理”限界上下文,其他模块都是调用它的接口,这样,当用户信息表发生变更时,只与“用户管理”限界上下文有关,与其他模块无关,变更维护成本就降低了。通过限界上下文将整个系统按照逻辑进行了划分,但从物理上它们都还是一个项目、运行在一个 JVM 中,这种限界上下文只是“逻辑边界”。
今后,将单体应用转型成微服务架构以后,各个限界上下文都是运行在各自不同的微服务中,是不同的项目、不同的 JVM。不仅如此,进行微服务拆分的同时,数据库也进行了拆分,每个微服务都是使用不同的数据库。这样,当各个微服务要访问用户信息时,它们没有访问用户数据库的权限,就只能通过远程接口去调用“用户”微服务开放的相关接口。这时,这种限界上下文就真正变成了“物理边界”,如下图所示:
微服务拆分的困局
现如今,许多软件团队都在加入微服务转型的行列,将原有的越来越复杂的单体应用,拆分为一个一个简单明了的微服务,以降低系统微服务的复杂性,这是没有问题的。然而,现在最大的问题是微服务应当如何拆分。
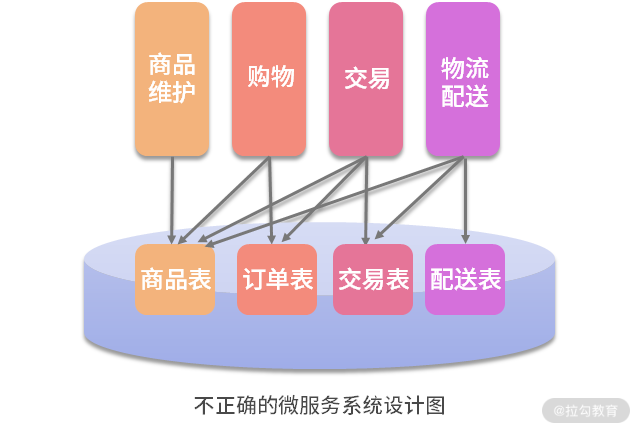
如上图所示,以往许多的系统是这样设计的。现在,如果还按照这样的设计思路简单粗暴地拆分为多个微服务以后,对系统日后的维护将是灾难性的。
当多个模块都要读取商品信息表时,是直接通过 JDBC(Java Database Connectivity)去读取这个表。
接着,按照这样的思路拆分微服务,多个微服务都要读取商品信息表。
这样,一旦商品信息表发生变更,多个微服务都需要变更。不仅多个团队都要为了维护这个需求修改代码,而且他们的微服务需要同时修改、同时发布、同时升级。
如果每次的维护都是这样进行,不仅微服务的优势不能发挥出来,还会使得维护的成本更高。如果微服务被设计成这样,还真不如不用微服务。
这里的关键问题在于,当多个微服务都要读取同一个表时,也就意味着同一个软件变化原因(因商品信息而变更)的代码被分散到多个微服务中。这时,当系统因该原因而变化时,代码的修改自然就会分散到多个微服务上。也就是说,以上设计问题的根源违反了“单一职责原则”,使微服务的设计不再高内聚。微服务该怎样设计、怎样拆分?关键就在于“小而专”,这里的“专”就是高内聚。
因此,微服务设计不是简单的拆分,而是对设计提出了更高的要求,即要做到“高内聚”。只有这样,才能让日后的变更能尽量落到某个微服务上维护,从而降低维护成本。唯有这样才能将微服务的优势发挥出来,才是微服务正确的打开方式。
为了让微服务设计做到高内聚,最佳的实践则是 DDD:
先从 DDD 开始需求分析、领域建模,逐渐建立起多个问题子域;
再将问题子域落实到限界上下文,它们之间的关联形成上下文地图;
最后,各子域落实到微服务中贫血模型或充血模型的设计,从而在微服务之间依据上下文地图形成接口。
唯有这样的设计,才能很好地做到“微服务之间低耦合,微服务之内高内聚”的设计目标。
总结
总而言之,微服务设计的困局就是拆分,拆分的核心就是“小而专”“高内聚”。因此,破解微服务困局的关键就是 DDD。有了 DDD,就使得微服务团队在面对软件越来越复杂的业务时,能够分析清楚业务,能够想明白设计,从而提高微服务的设计质量。
那么,DDD 如何从业务建模,一步一步落地到微服务设计呢?下一讲将通过一个实际项目(在线订餐项目)的演练,更加直观地展现这一过程,到时见!
DDD微服务架构设计第三课 DDD领域中的聚合、工厂和仓库、限界上下文相关推荐
- DDD微服务架构设计第四课 DDD指导微服拆分和落地实现
07 在线订餐场景中是如何开事件风暴会议的? 微服务设计最核心的难题是微服务的拆分,不合理的微服务拆分不仅不能提高研发效率,反倒还使得研发效率更低,因此要讲究"小而专"的设计.&q ...
- DDD微服务架构设计第四课 微服务落地实践的技术中台
10 微服务落地的技术实践 如今,做一个优秀的程序员越来越难.激烈的市场竞争.互联网快速的迭代.软件系统规模化发展,无疑都大大增加了软件设计的难度.因此,对于架构师的能力要求也越来越高,就像我的一本书 ...
- 基于DDD的微服务架构设计
基于DDD的微服务架构设计 1. DDD摘要&概述 每个公司都希望研发的系统具备高扩展性,以便做产品和业务迭代时,成本降到最低,效率提到最高:当下流行的微服务架构.中台架构的目标都是在不同层面 ...
- 微服务架构设计总结实践
- 目录 - 一.微服务架构介绍 二.出现和发展 三.传统开发模式和微服务的区别 四.微服务的具体特征 五.SOA和微服务的区别 六.如何具体实践微服务 七.常见的微服务设计模式和应用 ...
- 一张图搞懂微服务架构设计
前言 当前,微服务架构在很多公司都已经落地实施了,下面用一张图简要概述下微服务架构设计中常用组件.不能说已经使用微服务好几年了,结果对微服务架构没有一个整体的认知,一个只懂搬砖的程序员不是一个好码农! ...
- 全面解析 Netflix 的微服务架构设计
点击上方"朱小厮的博客",选择"设为星标" 后台回复"加群",加入新技术 1简介 多年来,Netflix 一直是全球最出色的在线订阅制视频流 ...
- 微服务架构设计实践系列之五:架构准备阶段
微服务架构设计实践系列之五:架构准备阶段 原文:微服务架构设计实践系列之五:架构准备阶段 版权声明: https://blog.csdn.net/beyondself_77/article/detai ...
- 微服务架构设计实践之七:业务架构
微服务架构设计实践之七:业务架构 原文:微服务架构设计实践之七:业务架构 版权声明: https://blog.csdn.net/beyondself_77/article/details/79842 ...
- 微服务架构设计实践系列之九:应用架构
微服务架构设计实践系列之九:应用架构 原文:微服务架构设计实践系列之九:应用架构 版权声明: https://blog.csdn.net/beyondself_77/article/details/7 ...
最新文章
- 谷歌和 Facebook 是如何给工程师定职级和薪水的?
- LightCounting预测以太网光模块市场未来5年18%增速
- 让SignalR客户端回调支持强类型
- 【网络安全工程师面试合集】—不要随便浏览一些奇怪的小网站哦
- 【UVa】Wavio Sequence(dp)
- 编辑距离、拼写检查与度量空间:一个有趣的数据结构
- vmware workstation 12 打开vm14 不兼容问题解决
- linux台式机双屏幕怎么连接,台式机Linux/Unix多系统安装详细教程
- 网易邮箱大师使用排雷
- PyTorch 单机多GPU 训练方法与原理整理
- 思科路由器:学会看路由表信息,show ip route详解
- 比赛对阵表(女排世界杯对阵表)
- 图的表示(Adjacency List + Adjacency Matrix)
- SpringCloud-使用熔断器防止服务雪崩-Ribbon和Feign方式(附代码下载)
- 客户端服务器通信demo(续) -- 使用二进制协议 (附源码)
- 李建忠设计模式——享元模式
- Selenium WebDriver API 进阶使用,模块化参数化进行自动化测试设计
- 水经注,bigemap 功能对比
- 计算机是通过计算器发明的吗,计算器发明者
- 学习日志 -- Day02