CNN 可视化卷积核
Deep Visualization:可视化并理解CNN
https://blog.csdn.net/zchang81/article/details/78095378 caffe版本
卷积神经网络CNN:Tensorflow实现(以及对卷积特征的可视化)
本文主要是实现了一个简单的卷积神经网络,并对卷积过程中的提取特征进行了可视化.
![]()
卷积神经网络最早是为了解决图像识别的问题,现在也用在时间序列数据和文本数据处理当中,卷积神经网络对于数据特征的提取不用额外进行,在对网络的训练的过程当中,网络会自动提取主要的特征.
卷积神经网络直接用原始图像的全部像素作为输入,但是内部为非全连接结构.因为图像数据在空间上是有组织结构的,每一个像素在空间上和周围的像素是有关系的,和相距很远的像素基本上是没什么联系的,每个神经元只需要接受局部的像素作为输入,再将局部信息汇总就能得到全局信息.
权值共享和池化两个操作使网络模型的参数大幅的减少,提高了模型的训练效率.
- 权值共享:
在卷积层中可以有多个卷积核,每个卷积核与原始图像进行卷积运算后会映射出一个新的2D图像,新图像的每个像素都来自同一个卷积核.这就是权值共享.- 池化:
降采样,对卷积(滤波)后,经过激活函数处理后的图像,保留像素块中灰度值最高的像素点(保留最主要的特征),比如进行 2X2的最大池化,把一个2x2的像素块降为1x1的像素块.
- 池化:
# 卷积网络的训练数据为MNIST(28*28灰度单色图像)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
- 1
- 2
- 3
- 4
- 5
- 6
训练参数
train_epochs = 100 # 训练轮数
batch_size = 100 # 随机出去数据大小
display_step = 1 # 显示训练结果的间隔
learning_rate= 0.0001 # 学习效率
drop_prob = 0.5 # 正则化,丢弃比例
fch_nodes = 512 # 全连接隐藏层神经元的个数- 1
- 2
- 3
- 4
- 5
- 6
网络结构

![]()
输入层为输入的灰度图像尺寸: -1 x 28 x 28 x 1
第一个卷积层,卷积核的大小,深度和数量 (5, 5, 1, 16)
池化后的特征张量尺寸: -1 x 14 x 14 x 16
第二个卷积层,卷积核的大小,深度和数量 (5, 5, 16, 32)
池化后的特征张量尺寸: -1 x 7 x 7 x 32
全连接层权重矩阵 1568 x 512
输出层与全连接隐藏层之间, 512 x 10- 1
- 2
- 3
- 4
- 5
- 6
- 7
一些辅助函数
# 网络模型需要的一些辅助函数
# 权重初始化(卷积核初始化)
# tf.truncated_normal()不同于tf.random_normal(),返回的值中不会偏离均值两倍的标准差
# 参数shpae为一个列表对象,例如[5, 5, 1, 32]对应
# 5,5 表示卷积核的大小, 1代表通道channel,对彩色图片做卷积是3,单色灰度为1
# 最后一个数字32,卷积核的个数,(也就是卷基层提取的特征数量)
# 显式声明数据类型,切记
def weight_init(shape):weights = tf.truncated_normal(shape, stddev=0.1,dtype=tf.float32)return tf.Variable(weights)# 偏置的初始化
def biases_init(shape):biases = tf.random_normal(shape,dtype=tf.float32)return tf.Variable(biases)# 随机选取mini_batch
def get_random_batchdata(n_samples, batchsize):start_index = np.random.randint(0, n_samples - batchsize)return (start_index, start_index + batchsize)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
# 全连接层权重初始化函数xavier
def xavier_init(layer1, layer2, constant = 1):Min = -constant * np.sqrt(6.0 / (layer1 + layer2))Max = constant * np.sqrt(6.0 / (layer1 + layer2))return tf.Variable(tf.random_uniform((layer1, layer2), minval = Min, maxval = Max, dtype = tf.float32))- 1
- 2
- 3
- 4
- 5
# 卷积
def conv2d(x, w):return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME')# 源码的位置在tensorflow/python/ops下nn_impl.py和nn_ops.py
# 这个函数接收两个参数,x 是图像的像素, w 是卷积核
# x 张量的维度[batch, height, width, channels]
# w 卷积核的维度[height, width, channels, channels_multiplier]
# tf.nn.conv2d()是一个二维卷积函数,
# stirdes 是卷积核移动的步长,4个1表示,在x张量维度的四个参数上移动步长
# padding 参数'SAME',表示对原始输入像素进行填充,卷积后映射的2D图像与原图大小相等
# 填充,是指在原图像素值矩阵周围填充0像素点
# 如果不进行填充,假设 原图为 32x32 的图像,卷积和大小为 5x5 ,卷积后映射图像大小 为 28x28- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Padding
卷积核在提取特征时的动作成为padding,它有两种方式:SAME和VALID。卷积核的移动步长不一定能够整除图片像素的宽度,所以在有些图片的边框位置有些像素不能被卷积。这种不越过边缘的取样就叫做 valid padding,卷积后的图像面积小于原图像。为了让卷积核覆盖到所有的像素,可以对边缘位置进行0像素填充,然后在进行卷积。这种越过边缘的取样是 same padding。如过移动步长为1,那么得到和原图一样大小的图像。如果步长很大,超过了卷积核长度,那么same padding,得到的特征图也会小于原来的图像。
- 1
- 2
- 3
# 池化
def max_pool_2x2(x):return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')# 池化跟卷积的情况有点类似
# x 是卷积后,有经过非线性激活后的图像,
# ksize 是池化滑动张量
# ksize 的维度[batch, height, width, channels],跟 x 张量相同
# strides [1, 2, 2, 1],与上面对应维度的移动步长
# padding与卷积函数相同,padding='VALID',对原图像不进行0填充- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# x 是手写图像的像素值,y 是图像对应的标签
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
# 把灰度图像一维向量,转换为28x28二维结构
x_image = tf.reshape(x, [-1, 28, 28, 1])
# -1表示任意数量的样本数,大小为28x28深度为一的张量
# 可以忽略(其实是用深度为28的,28x1的张量,来表示28x28深度为1的张量)- 1
- 2
- 3
- 4
- 5
- 6
- 7
第一层卷积+池化
w_conv1 = weight_init([5, 5, 1, 16]) # 5x5,深度为1,16个
b_conv1 = biases_init([16])
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) # 输出张量的尺寸:28x28x16
h_pool1 = max_pool_2x2(h_conv1) # 池化后张量尺寸:14x14x16
# h_pool1 , 14x14的16个特征图- 1
- 2
- 3
- 4
- 5
- 6
第二层卷积+池化
w_conv2 = weight_init([5, 5, 16, 32]) # 5x5,深度为16,32个
b_conv2 = biases_init([32])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2) # 输出张量的尺寸:14x14x32
h_pool2 = max_pool_2x2(h_conv2) # 池化后张量尺寸:7x7x32
# h_pool2 , 7x7的32个特征图- 1
- 2
- 3
- 4
- 5
- 6
全连接层
# h_pool2是一个7x7x32的tensor,将其转换为一个一维的向量
h_fpool2 = tf.reshape(h_pool2, [-1, 7*7*32])
# 全连接层,隐藏层节点为512个
# 权重初始化
w_fc1 = xavier_init(7*7*32, fch_nodes)
b_fc1 = biases_init([fch_nodes])
h_fc1 = tf.nn.relu(tf.matmul(h_fpool2, w_fc1) + b_fc1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 全连接隐藏层/输出层
# 为了防止网络出现过拟合的情况,对全连接隐藏层进行 Dropout(正则化)处理,在训练过程中随机的丢弃部分
# 节点的数据来防止过拟合.Dropout同把节点数据设置为0来丢弃一些特征值,仅在训练过程中,
# 预测的时候,仍使用全数据特征
# 传入丢弃节点数据的比例
#keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob=drop_prob)# 隐藏层与输出层权重初始化
w_fc2 = xavier_init(fch_nodes, 10)
b_fc2 = biases_init([10])# 未激活的输出
y_ = tf.add(tf.matmul(h_fc1_drop, w_fc2), b_fc2)
# 激活后的输出
y_out = tf.nn.softmax(y_)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
# 交叉熵代价函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y * tf.log(y_out), reduction_indices = [1]))# tensorflow自带一个计算交叉熵的方法
# 输入没有进行非线性激活的输出值 和 对应真实标签
#cross_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_, y))# 优化器选择Adam(有多个选择)
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)# 准确率
# 每个样本的预测结果是一个(1,10)的vector
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_out, 1))
# tf.cast把bool值转换为浮点数
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
# 全局变量进行初始化的Operation
init = tf.global_variables_initializer()- 1
- 2
# 加载数据集MNIST
mnist = input_data.read_data_sets('MNIST/mnist', one_hot=True)
n_samples = int(mnist.train.num_examples)
total_batches = int(n_samples / batch_size)- 1
- 2
- 3
- 4
# 会话
with tf.Session() as sess:sess.run(init)Cost = []Accuracy = []for i in range(train_epochs):for j in range(100):start_index, end_index = get_random_batchdata(n_samples, batch_size)batch_x = mnist.train.images[start_index: end_index]batch_y = mnist.train.labels[start_index: end_index]_, cost, accu = sess.run([ optimizer, cross_entropy,accuracy], feed_dict={x:batch_x, y:batch_y})Cost.append(cost)Accuracy.append(accu)if i % display_step ==0:print ('Epoch : %d , Cost : %.7f'%(i+1, cost))print 'training finished'# 代价函数曲线fig1,ax1 = plt.subplots(figsize=(10,7))plt.plot(Cost)ax1.set_xlabel('Epochs')ax1.set_ylabel('Cost')plt.title('Cross Loss')plt.grid()plt.show()# 准确率曲线fig7,ax7 = plt.subplots(figsize=(10,7))plt.plot(Accuracy)ax7.set_xlabel('Epochs')ax7.set_ylabel('Accuracy Rate')plt.title('Train Accuracy Rate')plt.grid()plt.show()
#----------------------------------各个层特征可视化-------------------------------# imput imagefig2,ax2 = plt.subplots(figsize=(2,2))ax2.imshow(np.reshape(mnist.train.images[11], (28, 28)))plt.show()# 第一层的卷积输出的特征图input_image = mnist.train.images[11:12]conv1_16 = sess.run(h_conv1, feed_dict={x:input_image}) # [16, 28, 28 ,1] conv1_transpose = sess.run(tf.transpose(conv1_16, [3, 0, 1, 2]))fig3,ax3 = plt.subplots(nrows=1, ncols=16, figsize = (16,1))for i in range(16):ax3[i].imshow(conv1_transpose[i][0]) # tensor的切片[row, column]plt.title('Conv1 16x28x28')plt.show()# 第一层池化后的特征图pool1_16 = sess.run(h_pool1, feed_dict={x:input_image}) # [16, 14, 14, 1]pool1_transpose = sess.run(tf.transpose(pool1_16, [3, 0, 1, 2]))fig4,ax4 = plt.subplots(nrows=1, ncols=16, figsize=(16,1))for i in range(16):ax4[i].imshow(pool1_transpose[i][0])plt.title('Pool1 16x14x14')plt.show()# 第二层卷积输出特征图conv2_32 = sess.run(h_conv2, feed_dict={x:input_image}) # [32, 14, 14, 1]conv2_transpose = sess.run(tf.transpose(conv2_32, [3, 0, 1, 2]))fig5,ax5 = plt.subplots(nrows=1, ncols=32, figsize = (32, 1))for i in range(32):ax5[i].imshow(conv2_transpose[i][0])plt.title('Conv2 32x14x14')plt.show()# 第二层池化后的特征图pool2_32 = sess.run(h_pool2, feed_dict={x:input_image}) #[32, 7, 7, 1]pool2_transpose = sess.run(tf.transpose(pool2_32, [3, 0, 1, 2]))fig6,ax6 = plt.subplots(nrows=1, ncols=32, figsize = (32, 1))plt.title('Pool2 32x7x7')for i in range(32):ax6[i].imshow(pool2_transpose[i][0])plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
Epoch : 1 , Cost : 1.7629557
Epoch : 2 , Cost : 0.8955871
Epoch : 3 , Cost : 0.6002768
Epoch : 4 , Cost : 0.4222347
Epoch : 5 , Cost : 0.4106165
Epoch : 6 , Cost : 0.5070749
Epoch : 7 , Cost : 0.5032627
Epoch : 8 , Cost : 0.3399751
Epoch : 9 , Cost : 0.1524799
Epoch : 10 , Cost : 0.2328545
Epoch : 11 , Cost : 0.1815660
Epoch : 12 , Cost : 0.2749544
Epoch : 13 , Cost : 0.2539429
Epoch : 14 , Cost : 0.1850740
Epoch : 15 , Cost : 0.3227096
Epoch : 16 , Cost : 0.0711472
Epoch : 17 , Cost : 0.1688010
Epoch : 18 , Cost : 0.1442217
Epoch : 19 , Cost : 0.2415594
Epoch : 20 , Cost : 0.0848383
Epoch : 21 , Cost : 0.1879225
Epoch : 22 , Cost : 0.1355369
Epoch : 23 , Cost : 0.1578972
Epoch : 24 , Cost : 0.1017473
Epoch : 25 , Cost : 0.2265745
Epoch : 26 , Cost : 0.2625684
Epoch : 27 , Cost : 0.1950202
Epoch : 28 , Cost : 0.0607868
Epoch : 29 , Cost : 0.0782418
Epoch : 30 , Cost : 0.0744723
Epoch : 31 , Cost : 0.0848689
Epoch : 32 , Cost : 0.1038134
Epoch : 33 , Cost : 0.0848786
Epoch : 34 , Cost : 0.1219746
Epoch : 35 , Cost : 0.0889094
Epoch : 36 , Cost : 0.0605406
Epoch : 37 , Cost : 0.0478896
Epoch : 38 , Cost : 0.1100840
Epoch : 39 , Cost : 0.0168766
Epoch : 40 , Cost : 0.0479708
Epoch : 41 , Cost : 0.1187883
Epoch : 42 , Cost : 0.0707371
Epoch : 43 , Cost : 0.0471128
Epoch : 44 , Cost : 0.1206998
Epoch : 45 , Cost : 0.0674985
Epoch : 46 , Cost : 0.1218394
Epoch : 47 , Cost : 0.0840694
Epoch : 48 , Cost : 0.0468497
Epoch : 49 , Cost : 0.0899443
Epoch : 50 , Cost : 0.0111846
Epoch : 51 , Cost : 0.0653627
Epoch : 52 , Cost : 0.1446207
Epoch : 53 , Cost : 0.0320902
Epoch : 54 , Cost : 0.0792156
Epoch : 55 , Cost : 0.1250363
Epoch : 56 , Cost : 0.0477339
Epoch : 57 , Cost : 0.0249218
Epoch : 58 , Cost : 0.0571465
Epoch : 59 , Cost : 0.0152223
Epoch : 60 , Cost : 0.0373616
Epoch : 61 , Cost : 0.0417238
Epoch : 62 , Cost : 0.0710011
Epoch : 63 , Cost : 0.0654174
Epoch : 64 , Cost : 0.0234730
Epoch : 65 , Cost : 0.0267291
Epoch : 66 , Cost : 0.0329132
Epoch : 67 , Cost : 0.0344089
Epoch : 68 , Cost : 0.1151591
Epoch : 69 , Cost : 0.0555586
Epoch : 70 , Cost : 0.0213475
Epoch : 71 , Cost : 0.0567649
Epoch : 72 , Cost : 0.1207196
Epoch : 73 , Cost : 0.0407380
Epoch : 74 , Cost : 0.0580697
Epoch : 75 , Cost : 0.0352901
Epoch : 76 , Cost : 0.0420529
Epoch : 77 , Cost : 0.0016548
Epoch : 78 , Cost : 0.0184542
Epoch : 79 , Cost : 0.0657262
Epoch : 80 , Cost : 0.0185127
Epoch : 81 , Cost : 0.0211956
Epoch : 82 , Cost : 0.0709701
Epoch : 83 , Cost : 0.1013358
Epoch : 84 , Cost : 0.0876017
Epoch : 85 , Cost : 0.1351897
Epoch : 86 , Cost : 0.1239478
Epoch : 87 , Cost : 0.0147001
Epoch : 88 , Cost : 0.0155131
Epoch : 89 , Cost : 0.0425102
Epoch : 90 , Cost : 0.0912542
Epoch : 91 , Cost : 0.0445287
Epoch : 92 , Cost : 0.0823120
Epoch : 93 , Cost : 0.0155016
Epoch : 94 , Cost : 0.0869377
Epoch : 95 , Cost : 0.0641734
Epoch : 96 , Cost : 0.0498264
Epoch : 97 , Cost : 0.0289681
Epoch : 98 , Cost : 0.0271511
Epoch : 99 , Cost : 0.0131940
Epoch : 100 , Cost : 0.0418167
training finished
- 训练交叉熵代价

![]()
训练的准确率

![]()
训练数据中的一个样本

![]()
第一个卷积层提取的特征
![]()
2x2池化后的特征
![]()
第二层卷积提取特征
![]()
2x2池化后的特征
![]()
https://blog.csdn.net/u014281392/article/details/74316028
基于Keras的卷积神经网络(CNN)可视化
https://blog.csdn.net/weiwei9363/article/details/79112872
卷积神经网络可视化
- 本文整理自Deep Learning with Python,书本上完整的代码在 这里的5.4节,并陪有详细的注释。
- 深度学习一直被人们称为“黑盒子”,即内部算法不可见。但是,卷积神经网络(CNN)却能够被可视化,通过可视化,人们能够了解CNN识别图像的过程。
- 介绍三种可视化方法
- 卷积核输出的可视化(Visualizing intermediate convnet outputs (intermediate activations),即可视化卷积核经过激活之后的结果。能够看到图像经过卷积之后结果,帮助理解卷积核的作用
- 卷积核的可视化(Visualizing convnets filters),帮助我们理解卷积核是如何感受图像的
- 热度图可视化(Visualizing heatmaps of class activation in an image),通过热度图,了解图像分类问题中图像哪些部分起到了关键作用,同时可以定位图像中物体的位置。
卷积核输出的可视化(Visualizing intermediate convnet outputs (intermediate activations)
- 想法很简单:向CNN输入一张图像,获得某些卷积层的输出,可视化该输出
- 代码中,使用到了cats_and_dogs_small_2.h5模型,这是在原书5.2节训练好的模型,当然你完全可以使用keras.applications 中的模型,例如VGG16等。
- 可视化结果如下图。
- 结论:
- 第一层卷积层类似边缘检测的功能,在这个阶段里,卷积核基本保留图像所有信息
- 随着层数的加深,卷积核输出的内容也越来越抽象,保留的信息也越来越少。
- 越深的层数,越多空白的内容,也就说这些内容空白卷积核没有在输入图像中找到它们想要的特征



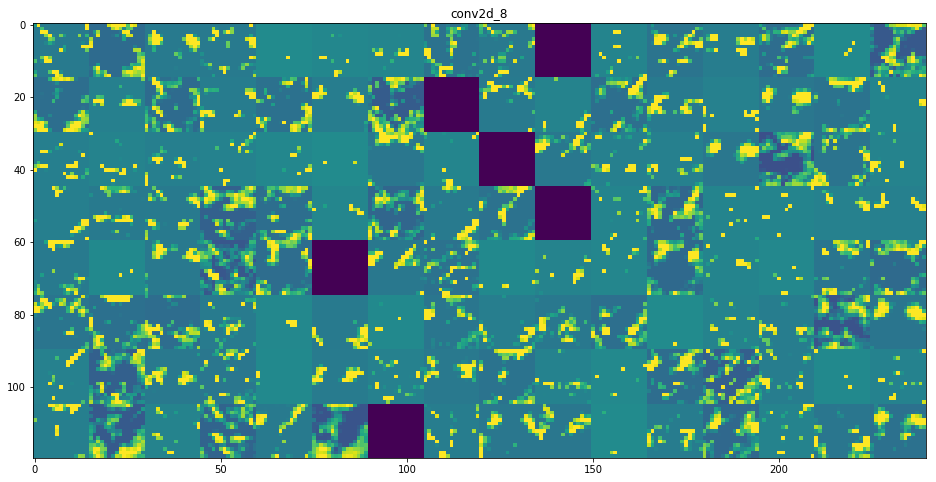
卷积核的可视化(Visualizing convnets filters)
- 卷积核到底是如何识别物体的呢?想要解决这个问题,有一个方法就是去了解卷积核最感兴趣的图像是怎样的。我们知道,卷积的过程就是特征提取的过程,每一个卷积核代表着一种特征。如果图像中某块区域与某个卷积核的结果越大,那么该区域就越“像”该卷积核。
- 基于以上的推论,如果我们找到一张图像,能够使得这张图像对某个卷积核的输出最大,那么我们就说找到了该卷积核最感兴趣的图像。
- 具体思路:输入一张随机内容的图像II, 求某个卷积核FF对图像的梯度 G=∂F/∂IG=∂F/∂I,用梯度上升的方法迭代更新图像 I=I+η∗GI=I+η∗G,ηη是类似于学习率的东西。
- 代码中,使用以及训练好的VGG16模型,可视化该模型的卷积核。结果如下
- block1_conv1
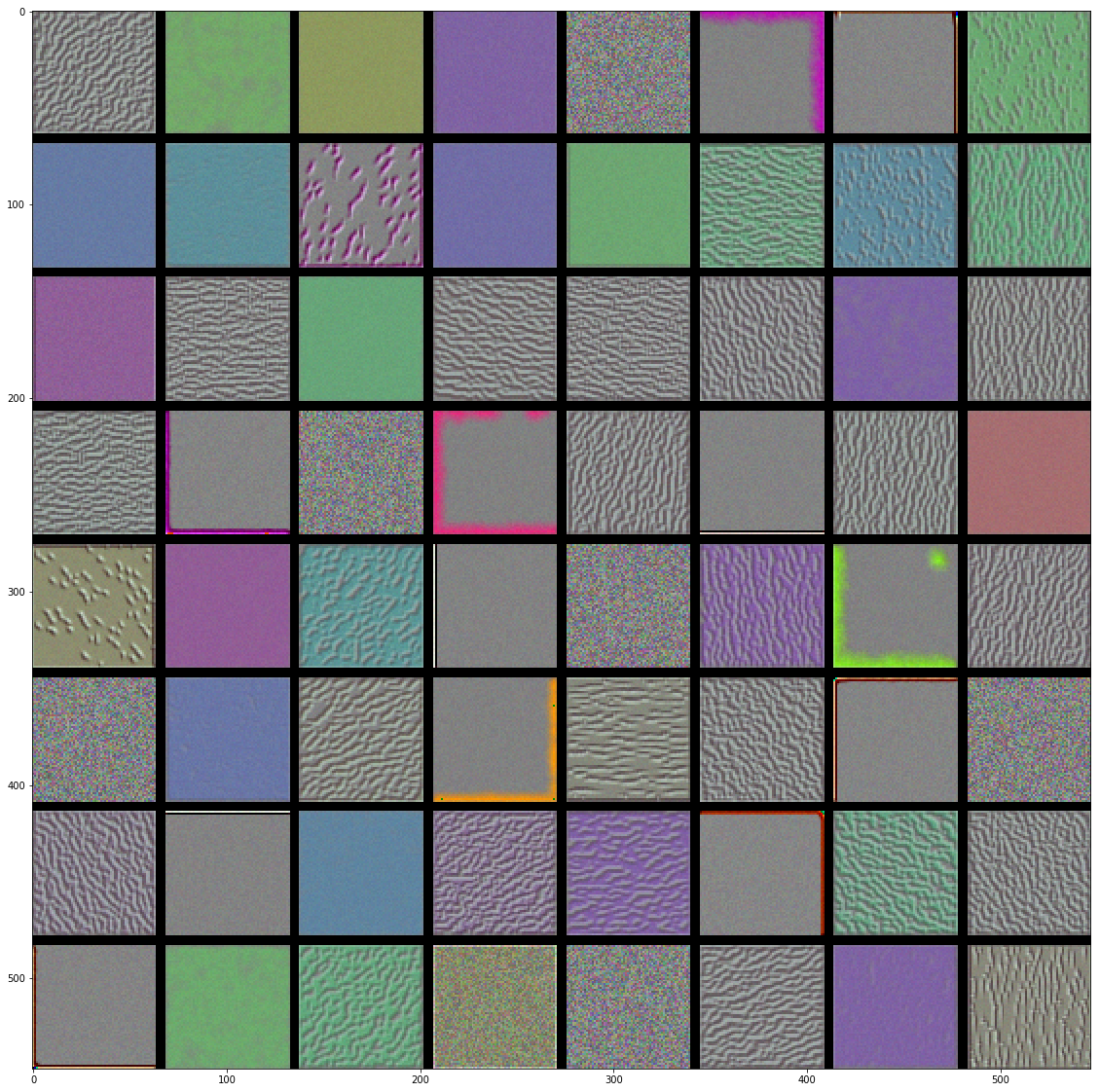
- block2_conv1
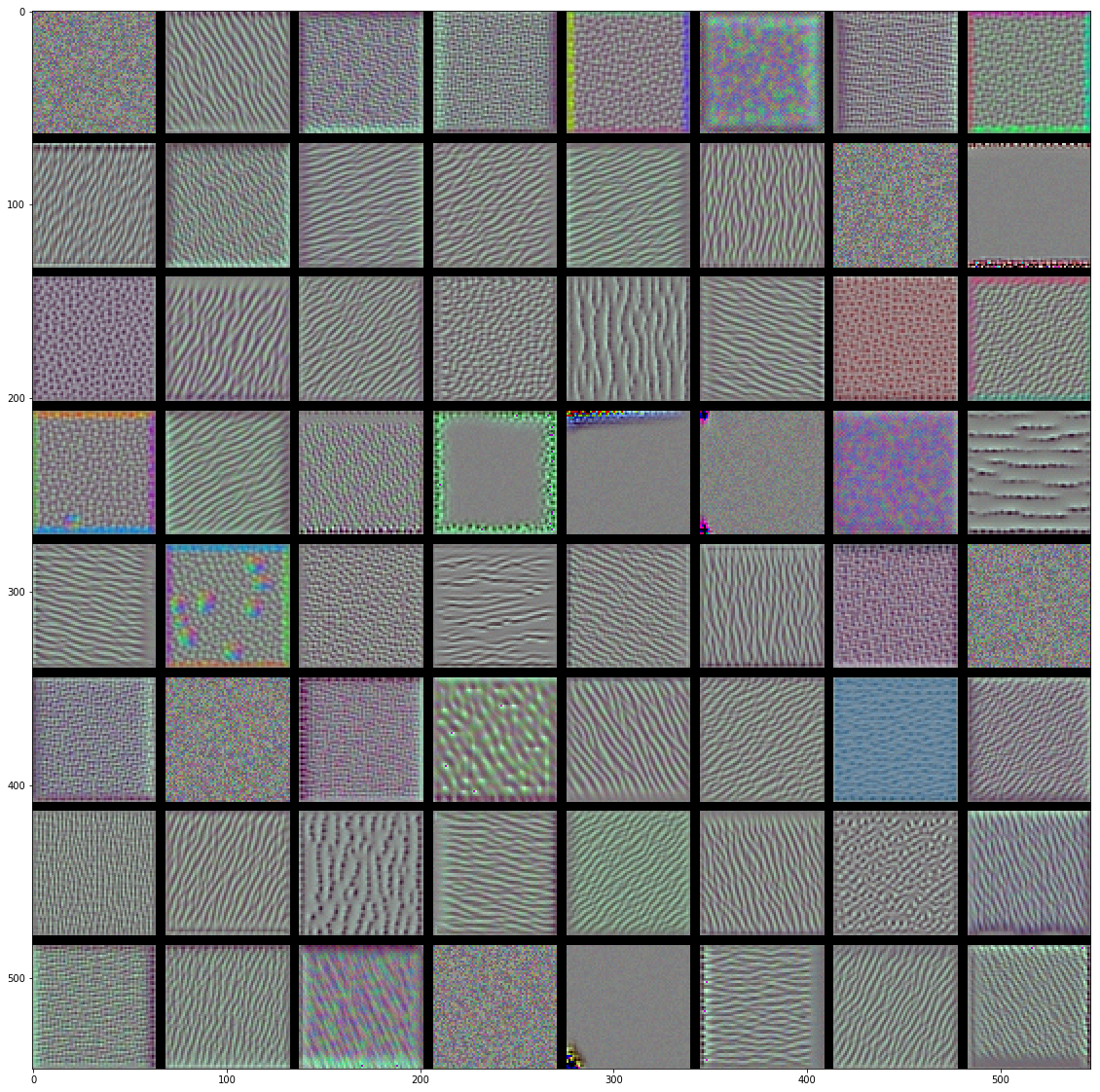
- block3_conv1
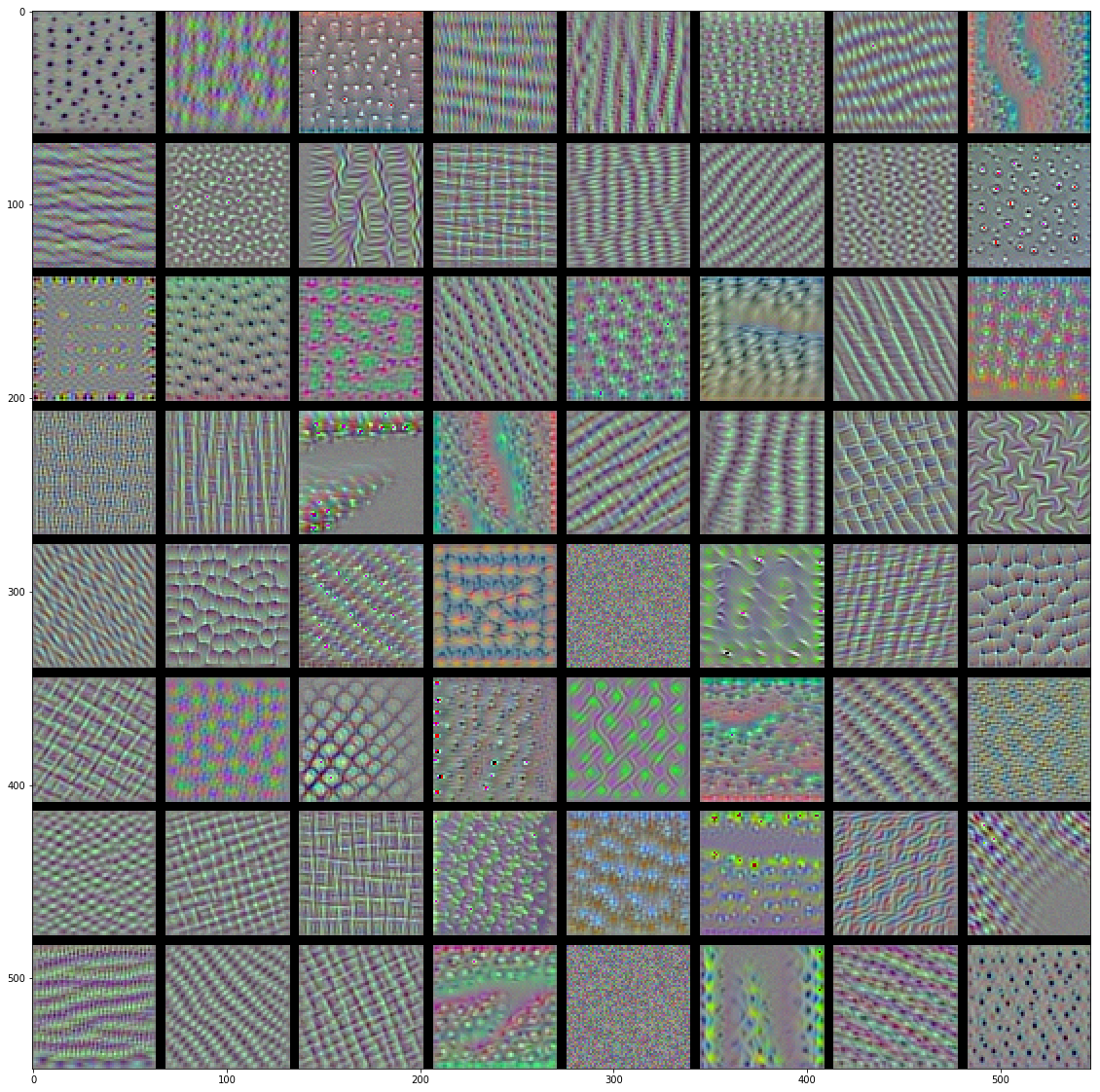
- block4_conv1
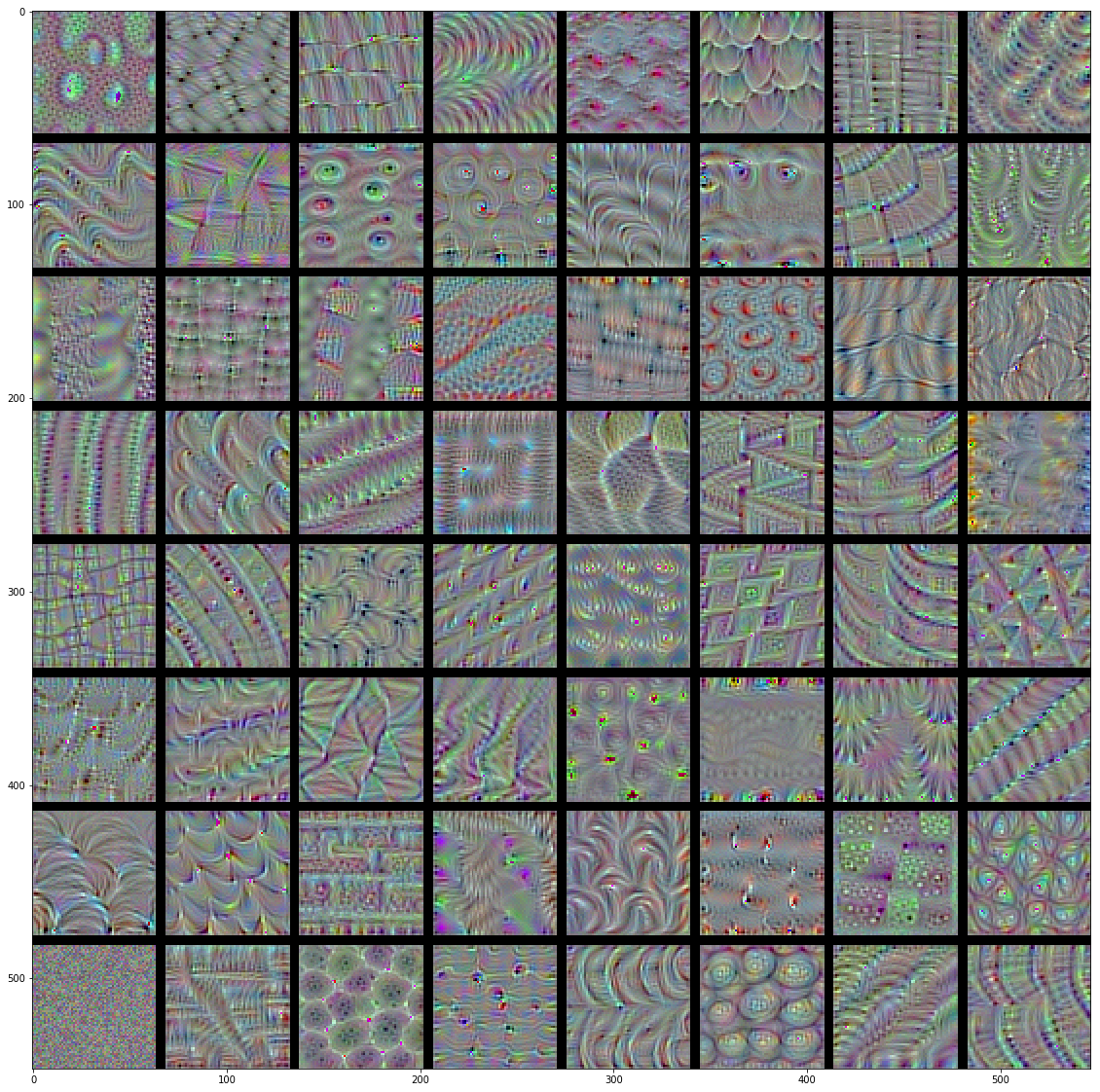
- block5_conv1

- block1_conv1
- 结论:
- 低层的卷积核似乎对颜色,边缘信息感兴趣。
- 越高层的卷积核,感兴趣的内容越抽象(非常魔幻啊),也越复杂。
- 高层的卷积核感兴趣的图像越来越难通过梯度上升获得(block5_conv1有很多还是随机噪声的图像)
热度图可视化(Visualizing heatmaps of class activation in an image)
- 在图像分类问题中,假设网络将一张图片识别成“猫”的概率是0.9,我想了解到底最后一层的卷积层对这0.9的概率的贡献是多少。换句话时候,假设最后一层卷积层有512个卷积核,我想了解这512个卷积核对该图片是”猫”分别投了几票。投票越多的卷积核,就越确信图片是“猫”,因为它们提取到的特征趋向猫的特征。
- 代码中,输入了一张大象的图片,然后获得最后一层卷积层的热度图,最后将热度图叠加到原图像,获得图像中起到关键分类作用的部分。结果如下:

CNN 可视化卷积核相关推荐
- AI:IPPR的数学表示-CNN可视化语义分析
前言: ANN是个语义黑箱的意思是没有通用明确的函数表示,参数化的模型并不能给出函数的形式,更进而不能表示函数的实际意义. 而CNN在图像处理方面具有天然的理论优势,而Conv层和Polling层,整 ...
- CNN可视化技术总结(一)--特征图可视化
导言: 在CV很多方向所谓改进模型,改进网络,都是在按照人的主观思想在改进,常常在说CNN的本质是提取特征,但并不知道它提取了什么特征,哪些区域对于识别真正起作用,也不知道网络是根据什么得出了分类结果 ...
- CNN可视化最新研究方法进展(附结构、算法)
译者 | reason_W 责编 | 明 明 出品 | AI科技大本营(公众号ID:rgznai100) [AI科技大本营导读]深度学习一直被看做是一个难以解释的"黑匣子".一方面 ...
- DL之CNN可视化:利用SimpleConvNet算法【3层,im2col优化】基于mnist数据集训练并对卷积层输出进行可视化
DL之CNN可视化:利用SimpleConvNet算法[3层,im2col优化]基于mnist数据集训练并对卷积层输出进行可视化 导读 利用SimpleConvNet算法基于mnist数据集训练并对卷 ...
- 一维卷积filter_面试题:CNN的卷积核是单层的还是多层的?
CNN的卷积核是单层的还是多层的? 解析: 一般而言,深度卷积网络是一层又一层的.层的本质是特征图, 存贮输入数据或其中间表示值. 一组卷积核则是联系前后两层的网络参数表达体, 训练的目标就是每个卷积 ...
- CNN为什么卷积核的大小都是奇数
CNN的卷积核大小都是奇数而没有偶数主要有以下两点原因: 1.奇数卷积核有中心像素点 如下图中,奇数大小的卷积核有唯一的中心像素点,而偶数大小的卷积核没有中心像素点 ...
- CNN可视化!从CVPR 2022出发,聊聊CAM是如何激活我们文章的热度!
点击下方卡片,关注"CVer"公众号 AI/CV重磅干货,第一时间送达 转载自:极市平台 | 作者:matrix明仔 导读 本文从CVPR2022中三篇不同领域的文章中CAM的表 ...
- 深度学习笔记:卷积神经网络的可视化--卷积核本征模式
目录 1. 前言 2. 代码实验 2.1 加载模型 2.2 构造返回中间层激活输出的模型 2.3 目标函数 2.4 通过随机梯度上升最大化损失 2.5 生成滤波器模式可视化图像 2.6 将多维数组变换 ...
- CNN可视化技术 -- CAM Grad-CAM详解及pytorch简洁实现
文章目录 前言 1. CAM(Class Activation Map) 2. Grad-CAM 3. PyTorch中的hook机制 4. Grad-CAM的PyTorch简洁实现 参考资料 前言 ...
最新文章
- Microsoft StreamInsight 构建物联网
- 用自然语言指导强化学习agent打游戏,这是斯坦福的最新研究
- 微软亚研提出VL-BERT:通用的视觉-语言预训练模型
- Java学习之二-Java反射机制
- C++日志系统log4cxx使用总结
- arm架构的linux芯片方案,ARM推64位处理器架构ARMV8及芯片[多图]
- Redis遇到的那些坑
- B树插入和删除的各种情况分析
- html——陆海网站练习
- discuz自定义接口开发——一键发帖,自动发帖,站外发帖(主题)
- ACPC2015 K 树的直径
- 关于KOT、KOL、KOC 理解
- 结构型设计模式(7种)
- Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
- SecureCRT 乱码问题
- 内存数据库中的索引技术
- [Python3]数独计算器
- bullmind在线思维导图软件,bullmind在线流程图软件
- K8S实战集训第二课 K8S 存储 之 Ceph 分布式存储系统
- 《乐高EV3机器人搭建与编程》——1.5 主控器和电池