python爬取气象台每日天气图代码
特别鸣谢以下更多python教程请到友情连接: 菜鸟教程https://www.piaodoo.com
初中毕业读什么技校 http://cntkd.net
茂名一技http://www.enechn.com
ppt制作教程步骤 http://www.tpyjn.cn
兴化论坛http://www.yimoge.cn
电白论坛 http://www.fcdzs.com
永城信息港 http://www.1l4u.com
茂名一技有什么专业 http://www.jeob.cn
茂名市高级技工学校 http://www.szsyby.net
初中毕业读什么技校 http://www.ausq.cn
目录
- 前言
- 1.安装Selenium
- 2. 安装chromedriver
- 3.代码
前言
中央气象台网站更新后,以前的爬虫方式就不太能用了,我研究了一下发现主要是因为网站上天气图的翻页模式从点击变成了滑动,页面上的图片src也只显示当前页面的,因此,按照网络通俗的方法去爬取就只能爬出一张图片。看了一些大佬的教程后自己改出来一个代码。
1.安装Selenium
Selenium是一个Web的自动化(测试)工具,它可以根据我们的指令,让浏览器执行自动加载页面,获取需要的数据等操作。
pip install selenium
2. 安装chromedriver
Selenium 自身并不具备浏览器的功能,Google的Chrome浏览器能方便的支持此项功能,需安装其驱动程序Chromedriver
下载地址:http://chromedriver.storage.googleapis.com/index.html
在google浏览器的地址栏输入‘chrome://version/’,可以查看版本信息,下载接近版本的就可以。
3.代码
从图里可以看到,向前翻页指令对应的id是'prev'
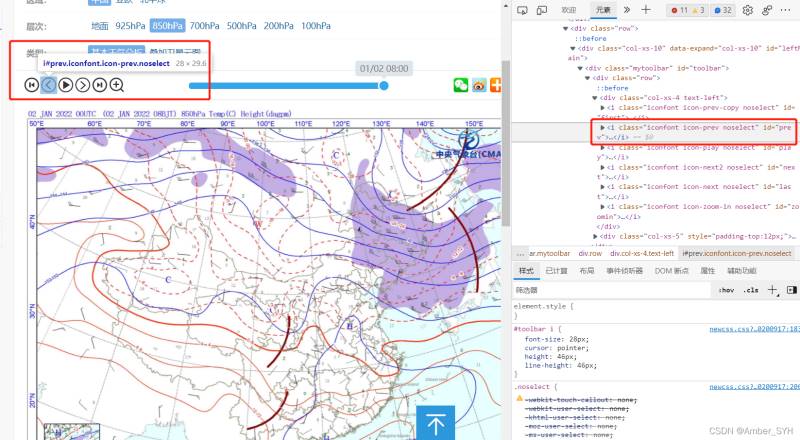
from selenium import webdriver ## 导入selenium的浏览器驱动接口 from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.ui import Select import time import os import urllib.request level=['地面','925hPa','850hPa','700hPa','500hPa','100hPa']
chrome_driver = ‘路径/chromedriver.exe’ #chromedriver的文件位置
driver = webdriver.Chrome(executable_path = chrome_driver) #加载浏览器驱动
driver.get(‘http://www.nmc.cn/publish/observations/china/dm/weatherchart-h000.htm’) #打开页面
time.sleep(1)
#模拟鼠标选择高度层
for z in level:
button1=driver.find_element_by_link_text(z) #通过link文字精确定位元素
action = ActionChains(driver).move_to_element(button1) #鼠标悬停在一个元素上
action.click(button1).perform() #鼠标单击
time.sleep(1)
for p in range(0,6): #下载最近6个时次的天气图
str_p=str§
#模拟鼠标选择时间
button2=driver.find_element_by_id(‘prev’) #通过id精确定位元素
action = ActionChains(driver).move_to_element(button2) #鼠标悬停在一个元素上
action.click(button2).perform() #鼠标单击
time.sleep(1)
#模拟鼠标选择图片
elem_pic = driver.find_element_by_id(‘imgpath’) #通过id精确定位元素
action = ActionChains(driver).move_to_element(elem_pic)
#action.context_click(elem_pic).perform() #鼠标右击
filename= str(elem_pic.get_attribute(‘src’)).split(’/’)[-1].split(’?’)[0] #获取文件名
#获取图片src
src1=elem_pic.get_attribute(‘src’)
if os.path.exists(‘存图路径/’+z+’’) is not True :
os.makedirs(‘存图路径/’+z+’’)
urllib.request.urlretrieve(src1 , ‘存图路径/’+z+’/’+filename)
print(filename)
time.sleep(1)
然后就可以轻松的爬取所有图片

到此这篇关于python爬取气象台每日天气图代码的文章就介绍到这了,更多相关python爬取天气图内容请搜索菜鸟教程www.piaodoo.com以前的文章或继续浏览下面的相关文章希望大家以后多多支持菜鸟教程www.piaodoo.com!
python爬取气象台每日天气图代码相关推荐
- Python爬取自然风景图片代码
Python爬取自然风景图片代码 \qquad 需要用到python的etree库和requests库,需要提前下载安装. from lxml import etree import requests ...
- Python爬取携程机票代码实例
Python爬取携程机票代码实例 现在携程的页面是通过接口传递数据的,不能直接使用xpath进行解析,需要模拟调用接口的步骤 dcity是指出发地的城市编码 acity是指目的地的城市编码 其他参数是 ...
- python爬取中央气象台每日预报结果
爬取中央气象台每日预报结果 目录 爬取中央气象台每日预报结果 1.数据网站介绍 2.python爬取代码 3.windows定时任务 1.数据网站介绍 中央气象台网站提供了1-7天的各要素预报信息 ...
- python爬取网页书籍名称代码_python爬取亚马逊书籍信息代码分享
我有个需求就是抓取一些简单的书籍信息存储到mysql数据库,例如,封面图片,书名,类型,作者,简历,出版社,语种. 我比较之后,决定在亚马逊来实现我的需求. 我分析网站后发现,亚马逊有个高级搜索的功能 ...
- Python爬取金山词霸每日一句,存储到MySQL中
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/7/3 20:25 # @Author : baoshan # @Site : ...
- 用 Python 爬取分析每日票房数据
♚ 作者:小李子,某外企分析师,主要从事IT行业,但个人非常喜欢电影市场分析,所以经常会写一些电影领域的文章. 博客:http://blog.sina.com.cn/leonmovie 不知不觉又过了 ...
- Python爬取NBA每日比赛比分
自从学会了爬虫的基本用法之后,一些网页上的基本信息都可以很容易的爬取下来.今天练习爬取了腾讯NBA官网上的每日赛程的比分,就是这个: 这个网站的信息同样是存储在json文件中,在其HTML静态文件中找 ...
- 写一段python爬取付费音乐的代码
这里是一段爬取付费音乐的 Python 代码: import requests import json# 请求头 headers = {"User-Agent": "Mo ...
- python怎么做网页制作_[源代码]Python爬取网页制作电子书代码发布
最近,在GitChat发布一场Chat(Chat地址请猛戳这里),人数当天就达标了,今天把文章完成提交,同时将文章中的代码发布到码云,我就等待大家前来捧场了,Chat地址请猛戳这里. 有人爬取数据分析 ...
最新文章
- 【转】Winform输入法控制
- 解析EXCEL CSV格式文件的方法
- 交叉验证python_急!请教一个python里交叉验证的问题
- 页面生成周期中的两个Application池的详情小弟了解
- 写在方法中的路由跳转
- 合泰单片机数码管c语言,合泰单片机定时器数码管显示
- [css] 你是怎样对css文件进行压缩合并的?
- ASP.NET Session 的详细解释
- 抖音后台开发社招面试
- dubbo 数据传输大小配置
- RTSP的音频视频要各SETUP一次
- plsql导出单表数据
- 如何在Linux下逛B站看视频
- 在单个虚拟机中搭建DPDK测试环境
- php 只打印某个区域,PHP打印代码页面固定区域
- python中datetime与str的互相转化
- java 硬件中断_Java异步事件:轮询与中断
- 一招去除迅雷客户端首页视频 斩掉流氓特性 回归下载本质
- 几款超实用的知识管理软件,你都GET了吗?
- “金三银四”是找工作的最佳时期吗?那倒未必