pytorch搭建DCGAN
我们知道gan的过程是对生成分布拟合真实分布的一个过程,理想目标是让判别器无法识别输入数据到底是来源于生成器生成的数据还是真实的数据。
当然这是一个博弈的过程并且相互促进的过程,其真实的过程在于首先判别器会先拟合真实数据的分布,然后生成器拟合判别器的分布,从而达到生成器对真实数据分布的拟合。
![]()
图中蓝色部分为生成器,生成器的功能在于输入一个随机向量经过生成器一系列层的处理输出一个与真实数据尺寸一样的图片。 然后将生成器产生的图片与真实的图片信息一同的输入到判别器中,让判别器去区分该图片信息的源头,如果是判别器产生的图片则识别为fake,如果是生成器产生的图片,则判定为real,因此对于判别器的损失函数就为MSELoss(Pg,torch.zeros_like(Pg)) + MSELoss(Pr, torch.ones_like(Pr))
Pg表示生成器生成的数据,Pr表示真实数据)
而对于生成器来说它的目的在于生成的数据要欺骗判别器,也就是说让判别器都认为它产生的图片就是真实的图片数据(与真实图片无差别),所以生成器的损失函数就是
MSELoss(Pg, torch.ones_like(Pg))
DCGAN相对于普通的GAN只不过是在网络模型中采用了CNN模型
其中主要包含以下几点:
(1)使用指定步长的卷积层代替池化层
(2)生成器和判别器中都使用BatchNormlization
(3)移除全连接层
(4)生成器除去输出层采用Tanh外,全部使用ReLU作为激活函数
(5)判别器所有层都使用LeakyReLU作为激活函数
![]()
class Gernerator(nn.Module):def __init__(self, IMAGE_CHANNELS, NOISE_CHANNELS, feature_channels):super(Gernerator, self).__init__()self.features = nn.Sequential(self._Conv_block(in_channels=NOISE_CHANNELS, out_channels=feature_channels*4, stride=1, kernel_size=4,padding=0),self._Conv_block(in_channels=feature_channels*4, out_channels=feature_channels*8, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels*8, out_channels=feature_channels*4, stride=2, kernel_size=3,padding=1),nn.ConvTranspose2d(in_channels=feature_channels*4, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,padding=1),nn.Tanh(),)def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):feature = nn.Sequential(nn.ConvTranspose2d(in_channels=in_channels,out_channels=out_channels,stride=stride,padding=padding,kernel_size=kernel_size,bias=False),# nn.BatchNorm2d(num_features=out_channels),nn.ReLU())return featuredef forward(self, x):return self.features(x)```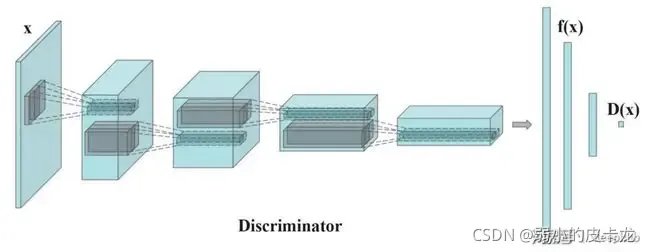```pythonclass Discriminator(nn.Module):def __init__(self, IMAGE_CHANNELS, feature_channels):super(Discriminator, self).__init__()self.features = nn.Sequential(self._Conv_block(in_channels=IMAGE_CHANNELS, out_channels=feature_channels, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels, out_channels=feature_channels * 2, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels * 2, out_channels=feature_channels * 4, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels * 4, out_channels=feature_channels * 2, stride=2, kernel_size=3,padding=1),nn.Conv2d(in_channels=feature_channels * 2, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,padding=1),nn.Sigmoid())def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):feature = nn.Sequential(nn.Conv2d(in_channels=in_channels,out_channels=out_channels,stride=stride,padding=padding,kernel_size=kernel_size,bias=False),# nn.BatchNorm2d(num_features=out_channels),nn.LeakyReLU(negative_slope=0.2))return featuredef forward(self, x):return torch.sigmoid(self.features(x))具体的情况需要具体设计相应的Generator和Discriminator
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as Transforms
from torchvision.datasets import ImageFolder
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import osclass Gernerator(nn.Module):def __init__(self, IMAGE_CHANNELS, NOISE_CHANNELS, feature_channels):super(Gernerator, self).__init__()self.features = nn.Sequential(self._Conv_block(in_channels=NOISE_CHANNELS, out_channels=feature_channels*4, stride=1, kernel_size=4,padding=0),self._Conv_block(in_channels=feature_channels*4, out_channels=feature_channels*8, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels*8, out_channels=feature_channels*4, stride=2, kernel_size=3,padding=1),nn.ConvTranspose2d(in_channels=feature_channels*4, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,padding=1),nn.Tanh(),)def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):feature = nn.Sequential(nn.ConvTranspose2d(in_channels=in_channels,out_channels=out_channels,stride=stride,padding=padding,kernel_size=kernel_size,bias=False),# nn.BatchNorm2d(num_features=out_channels),nn.ReLU())return featuredef forward(self, x):return self.features(x)class Discriminator(nn.Module):def __init__(self, IMAGE_CHANNELS, feature_channels):super(Discriminator, self).__init__()self.features = nn.Sequential(self._Conv_block(in_channels=IMAGE_CHANNELS, out_channels=feature_channels, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels, out_channels=feature_channels * 2, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels * 2, out_channels=feature_channels * 4, stride=2, kernel_size=3,padding=1),self._Conv_block(in_channels=feature_channels * 4, out_channels=feature_channels * 2, stride=2, kernel_size=3,padding=1),nn.Conv2d(in_channels=feature_channels * 2, out_channels=IMAGE_CHANNELS, stride=2, kernel_size=3,padding=1),nn.Sigmoid())def _Conv_block(self, in_channels, out_channels, kernel_size, stride, padding):feature = nn.Sequential(nn.Conv2d(in_channels=in_channels,out_channels=out_channels,stride=stride,padding=padding,kernel_size=kernel_size,bias=False),# nn.BatchNorm2d(num_features=out_channels),nn.LeakyReLU(negative_slope=0.2))return featuredef forward(self, x):return torch.sigmoid(self.features(x))def initialize_weights(model):# Initializes weights according to the DCGAN paperfor m in model.modules():if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):nn.init.normal_(m.weight.data, 0.0, 0.02)IMAGE_CHANNELS = 3
NOISE_CHANNELS = 100
FEATURE_CHANNELS = 32
BATCH_SIZE = 16
NUM_EPOCHS = 5
LEARN_RATE = 2e-4
IMAGE_SIZE = 64
D_PATH = 'logs/121_D.pth'
G_PATH = 'logs/41q_G.pth'mytransformers = Transforms.Compose([Transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),Transforms.ToTensor(),Transforms.Normalize(std=[0.6585589, 0.55756074, 0.54101795], mean=[0.28972548, 0.28038123, 0.26353073]),
])
trainset = ImageFolder(root=r'D:\QQPCmgr\Desktop\gan\A', transform=mytransformers)
trainloader = DataLoader(dataset=trainset,batch_size=BATCH_SIZE,shuffle=True
)writer_real = SummaryWriter(f"logs/real")
writer_fake = SummaryWriter(f"logs/fake")
step = 0if __name__ == '__main__':device = torch.device("cpu" if torch.cuda.is_available() else "cpu")print("cuda:0" if torch.cuda.is_available() else "cpu")Dnet = Discriminator(IMAGE_CHANNELS, FEATURE_CHANNELS).to(device)initialize_weights(Dnet)# Dnet.load_state_dict(torch.load(D_PATH))Gnet = Gernerator(IMAGE_CHANNELS, NOISE_CHANNELS, FEATURE_CHANNELS).to(device)initialize_weights(Gnet)Dnet.train()Gnet.train()# Gnet.load_state_dict(torch.load(G_PATH))noise = torch.randn((BATCH_SIZE, NOISE_CHANNELS, 1, 1)).to(device)ceritionG = nn.BCELoss(reduction='mean')ceritionD = nn.BCELoss(reduction='mean')optimizerG = torch.optim.Adam(params=Gnet.parameters(), lr=0.0002, betas=(0.5, 0.999))optimizerD = torch.optim.Adam(params=Dnet.parameters(), lr=0.0002, betas=(0.5, 0.999))for epoch in range(1000):for i, data in enumerate(trainloader, 1):optimizerD.zero_grad()optimizerG.zero_grad()r_img, _ = datar_img = r_img.to(device)fake_img = Gnet.forward(noise)r_label = (torch.ones_like(Gnet.forward(r_img))).to(device)f_label = torch.ones_like(Gnet.forward(r_img)).to(device)lossG = ceritionD(Dnet.forward(Gnet.forward(noise)), r_label)lossD = ceritionD(Dnet.forward(r_img), r_label) / 2 + ceritionD(Dnet.forward(Gnet.forward(noise)), f_label) / 2lossG.backward()lossD.backward()optimizerD.step(retain_graph=True)optimizerG.step(retain_graph=True)print('[epoch:%d],[lossD:%f],[lossG:%f]...........%d/10000' % (epoch, lossD.item(), lossG.item(), i*BATCH_SIZE))if i % 50 == 0:with torch.no_grad():img_grid_real = torchvision.utils.make_grid(r_img, normalize=True,)img_grid_fake = torchvision.utils.make_grid(fake_img, normalize=True)writer_fake.add_image("fake_img", img_grid_fake, global_step=step)writer_real.add_image("real_img", img_grid_real, global_step=step)step += 1
![]()
pytorch搭建DCGAN相关推荐
- 【项目实战课】基于Pytorch的DCGAN人脸嘴部表情图像生成实战
欢迎大家来到我们的项目实战课,本期内容是<基于Pytorch的DCGAN人脸嘴部表情图像生成实战>. 所谓项目实战课,就是以简单的原理回顾+详细的项目实战的模式,针对具体的某一个主题,进行 ...
- 一、pytorch搭建实战以及sequential的使用
一.pytorch搭建实战以及sequential的使用 1.A sequential container 2.搭建cifar10 model structure 3.创建实例进行测试(可以检查网络是 ...
- 【深度学习】——利用pytorch搭建一个完整的深度学习项目(构建模型、加载数据集、参数配置、训练、模型保存、预测)
目录 一.深度学习项目的基本构成 二.实战(猫狗分类) 1.数据集下载 2.dataset.py文件 3.model.py 4.config.py 5.predict.py 一.深度学习项目的基本构成 ...
- 基于PyTorch搭建CNN实现视频动作分类任务代码详解
数据及具体讲解来源: 基于PyTorch搭建CNN实现视频动作分类任务 import torch import torch.nn as nn import torchvision.transforms ...
- Pytorch搭建自己的模型
前言 PyTorch.TensorFlow都是主流的深度学习框架,今天主要讲解一下如何快速使用pytorch搭建自己的模型.至于为什么选择讲解pytorch,这里我就简单说明一下自己的使用感受(相对T ...
- Educoder 机器学习 神经网络 第四关:使用pytorch搭建卷积神经网络识别手写数字
任务描述 相关知识 卷积神经网络 为什么使用卷积神经网络 卷积 池化 全连接网络 卷积神经网络大致结构 pytorch构建卷积神经网络项目流程 数据集介绍与加载数据 构建模型 训练模型 保存模型 加载 ...
- 使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割)学习笔记
使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割)学习笔记 https://www.bilibili.com/video/BV1rq4y1w7xM?spm_id_from=33 ...
- 睿智的目标检测30——Pytorch搭建YoloV4目标检测平台
睿智的目标检测30--Pytorch搭建YoloV4目标检测平台 学习前言 什么是YOLOV4 代码下载 YOLOV4改进的部分(不完全) YOLOV4结构解析 1.主干特征提取网络Backbone ...
- 使用pytorch搭建AlexNet网络模型
使用pytorch搭建AlexNet网络模型 AlexNet详解 AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Ch ...
最新文章
- ListView自动滚到底部
- 《linux内核完全剖析:基于0.12内核》读书笔记一
- POJ1151(线段树+扫描线求矩形面积并)
- [刷题]算法竞赛入门经典(第2版) 4-3/UVa220 - Othello
- LoRaWAN的四大优势及适用领域
- lintcode-easy-Delete Node in the Middle of Singly Linked List
- android中jni数据加密,Android jni字符串如何加密
- win7允许远程桌面连接这台计算机,教你怎样win7远程桌面连接设置
- 小白spss学习笔记(一)
- 在线解答:怎么拥有TrustedInstaller权限?
- 【IIS问题】——默认网站localhost无法打开,错误类型404
- 计算机维护与维修毕业论文,计算机维修与维护毕业论文.doc
- K60 FTM定时器 定时中断
- C语言:房贷计算器(等额本息与等额本金对比计算器)
- Nginx报错:nginx: [error] invalid PID number in /run/nginx.pid的解决方案
- 最新冰盾DDoS防火墙V9.1 新增防护功能更强大
- 霍营派出所办理居住证
- 树莓派蜂鸣器python代码_树莓派+蜂鸣器=整点报时器
- 怎么用python画sin函数图像_Python绘制正余弦函数图像的方法
- 大数据重新定义未来,2018 中国大数据技术大会(BDTC)豪华盛宴抢先看!