翻译 - Kafka 介绍
本文翻译由有道翻译提供支持,中文不懂的地方,还请参看原文
资料
- 官方站点 http://kafka.apache.org/intro
- 资料集 https://www.zhihu.com/question/56172498
- 牛人博客1 https://blog.csdn.net/lizhitao/article/details/39499283
简介
Kafka 是一个分布式的流处理平台,这是什么意思?
流处理平台有下面三个关键功能:
- 发布和订阅记录流, 类似于消息队列或企业消息传递系统.
- 以容错的持久化方式存储记录流.
- 在流产生的过程中处理它们.
Kafka通常被用于两大类应用:
- 构建实时流数据管道,可靠地在系统或应用程序之间传递数据
- 构建对数据流进行转换或响应的实时流处理应用程序
为了理解卡夫卡是如何做到这些的,让我们从下往上深入挖掘卡夫卡的能力。
首先了解几个概念:
- Kafka在一个或多个服务器上运行,可以跨越多个数据中心。
- Kafka的集群存储了一系列称为Topic(主题)的记录流。
- 每条记录由一个键、一个值和一个时间戳组成。
Kafka有四个核心api:
- Produce API 允许应用程序将记录流发布到一个或多个Kafka主题。
- Consumer AP I允许应用程序订阅一个或多个主题,并处理生成给它们的记录流。
- Streams API 允许应用程序充当流处理器,从一个或多个主题中获取输入流,并生成一个输出流到一个或多个输出主题,有效地将输入流转换为输出流。
- Connector API 允许构建和运行可重用的生产者或消费者,将Kafka主题与现有的应用程序或数据系统连接起来。例如,连接到关系数据库的连接器可能捕获到表的每一个更改。
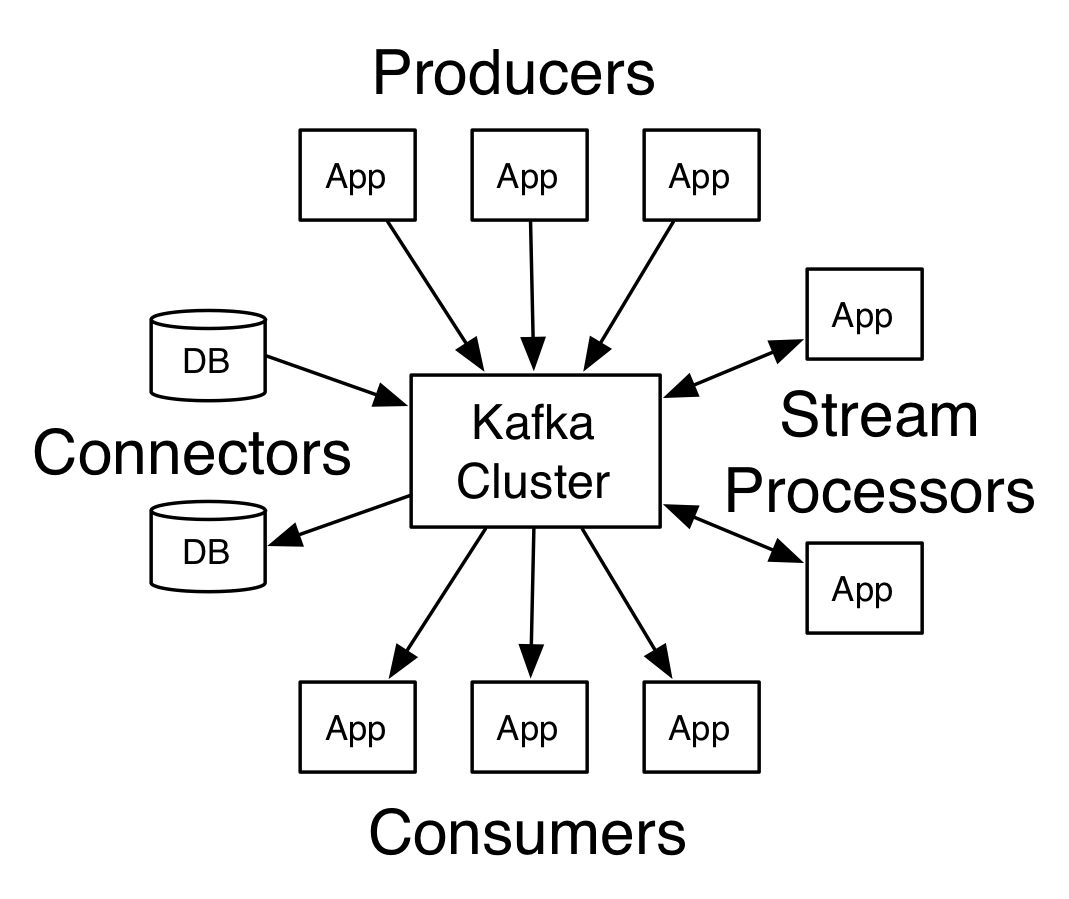
在Kafka中,客户端和服务器之间的通信是通过一个简单的、高性能的、语言无关的TCP协议来完成的。这个协议是版本化的,并且与旧版本保持向后兼容。我们为Kafka提供了一个Java客户端,但是客户端可以使用多种语言。
主题和日志 Topics and Logs
让我们首先深入到卡夫卡提供的核心抽象概念——主题。
主题是记录发布的类别或提要名称。卡夫卡的主题总是多订户;也就是说,一个主题可以有零个、一个或多个订阅了写入它的数据的消费者。
对于每一个主题,卡夫卡集群维护一个分区日志,它看起来是这样的:
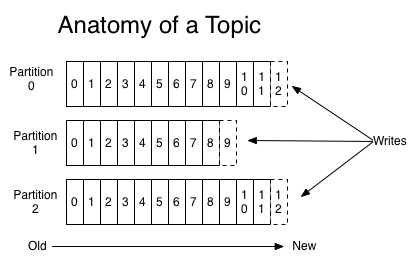
每个分区都是一个有序的、不可变的记录序列,它被不断地附加到一个结构化的提交日志中。分区中的记录都被分配了一个顺序的id号,称为偏移量,它惟一地标识分区内的每条记录。
卡夫卡的集群顽固地坚持所有已发布的记录——不管它们是否被消耗——使用一个可配置的保留期。例如,如果保留策略设置为两天,那么在记录发布后的两天内,它将被用于消费,之后将被丢弃以释放空间。在数据大小方面,卡夫卡的表现实际上是不变的,所以长时间存储数据并不是问题(译注:Kafka理论上的存储效率和数据大小无关)。
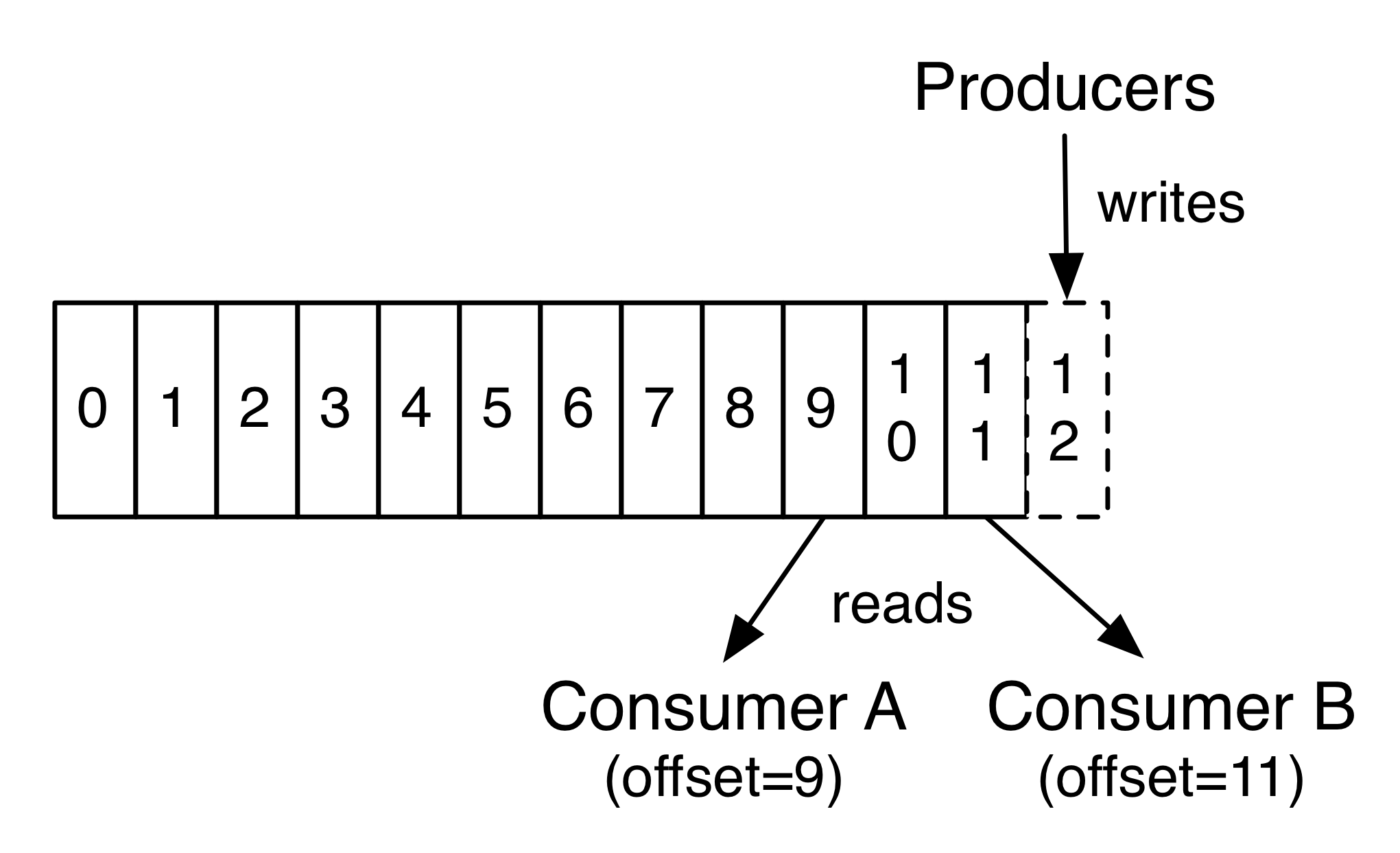
事实上,在每个消费者的基础上保留的唯一元数据是日志中那个消费者的偏移量或位置。这种偏移量是由消费者控制的:通常情况下,消费者会在读取记录时线性地增加偏移量,但事实上,由于这个位置是由消费者控制的,所以它可以按照自己喜欢的顺序来消费记录。例如,消费者可以重置为旧的偏移量,以重新处理过去的数据,或者跳过最近的记录,并开始从“现在”开始消费。
这一特性的组合意味着卡夫卡的消费者非常便宜——他们可以在没有对集群或其他消费者产生很大影响的情况下进行访问。例如,您可以使用我们的命令行工具来“跟踪”任何主题的内容,而不改变任何现有使用者所消耗的内容。
日志中的分区有几个目的。首先,它们允许日志的规模超出单个服务器的大小。每个单独的分区必须适合承载它的服务器,但是一个主题可能有许多分区,因此它可以处理任意数量的数据。第二,它们是并行的单位——更多的是在这一点上。
Distribution 分布式
日志的分区分布在卡夫卡集群中的服务器上,每个服务器处理数据和请求共享分区。每个分区都在可配置数量的服务器上进行复制,以实现容错。 每个分区都有一个充当“领导者”的服务器,而零个或更多的服务器充当“追随者”。当追随者被动地复制领导者时,领导者处理所有的读写请求。如果领导者失败了,一个追随者将自动成为新的领导者。每个服务器都充当某些分区的领导者,并为其他分区提供一个跟随者,因此负载在集群中是很平衡的。
Geo-Replication 异地备份
卡夫卡MirrorMaker为您的集群提供地理复制支持。使用MirrorMaker,消息在多个数据中心或云区域中被复制。您可以在主动/被动场景中使用它来进行备份和恢复;或者在主动/主动场景中,将数据更靠近用户,或者支持数据本地需求。
Producers 生产者
生产者将数据发布到他们选择的主题。生产者负责选择在主题中分配哪个分区的记录。这可以通过循环的方式来完成,仅仅是为了平衡负载,或者可以根据一些语义划分函数(根据记录中的一些键)来完成。More on the use of partitioning in a second!
Consumers 消费者
消费者用一个消费者组名来标记自己,并且每一个发布到一个主题的记录都被传递给每个订阅消费组中的一个消费者实例。消费者实例可以在单独的进程中或在单独的机器上。(译注:消费组和消费者实例就相当于一个线程池和线程的关系,每个记录被唯一一个消费者实例处理)
如果所有的消费者实例都有相同的消费者组,那么记录将有效地在消费者实例上进行负载平衡。
如果所有的消费者实例都有不同的消费者组,那么每个记录将被广播到所有的消费者进程。
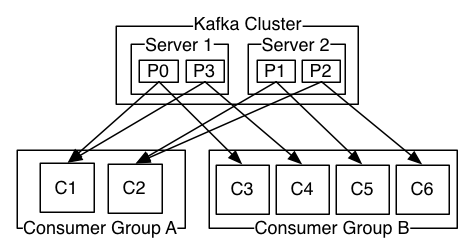
两个服务器卡夫卡集群,承载了四个分区(p0-p3)和两个消费群。消费者组A有两个消费者实例,而B组有4个。
然而,更常见的是,我们发现主题有少量的消费者组,每个组对应一个“逻辑订阅者”。每个组由许多用于可伸缩性和容错的消费者实例组成。这只不过是发布-订阅语义,订阅者是一组消费者,而不是单个进程。
在卡夫卡中实现消费的方式是将日志中的分区划分到消费者实例上,这样每个实例都是在任何时间点上的“公平份额”分区的独占使用者。这个维护组成员的过程是由卡夫卡协议动态处理的。如果新的实例加入了组,他们将从组的其他成员那里接管一些分区;如果一个实例死亡,它的分区将被分配给其余的实例。(译注:也就说消费组中消费者实例数量受分区数量限制)
Kafka only provides a total order over records within a partition, not between different partitions in a topic。对于大多数应用程序来说,每个分区的排序加上通过键对数据进行分区的能力是足够的。但是,如果您需要一个全局有序的记录,那么这可以通过一个只有一个分区的主题来实现,尽管这将意味着每个消费者组只有一个消费过程。(译注:应该说的是记录顺序问题)
Multi-tenancy 多租户
您可以将卡夫卡作为一个多租户解决方案部署。通过配置可以产生或使用数据的主题,可以启用多租户。也有对配额的操作支持。管理员可以定义和强制要求控制代理资源的请求,以控制客户端使用的broker 资源。要了解更多信息,请参阅安全文档。
Guarantees 保证
在一个高可用的卡夫卡中给出了以下保证:
- 一个生产者发送给特定主题分区的消息的顺序就是它们发送的顺序。也就是说,如果记录M1,M2是由相同的生产者发送的,而M1是先发送的,那么M1的偏移量将比M2低,并且在日志中先出现。
- 一个消费者实例获取记录的顺序就是记录在日志中存储的顺序。
- 对于带有复制因子N的主题,我们将容忍多达N-1个服务器故障,而不会丢失对日志的任何记录。
关于这些保证的更多细节在文档的设计部分中给出。
卡夫卡作为消息系统
卡夫卡的“流”概念与传统的企业消息传递系统相比如何?
消息传递传统上有两种模式:队列和发布-订阅。在队列中,一个消费者池可能从服务器读取,每个记录都指向其中一个;在发布-订阅中,记录被广播给所有的消费者。这两个模型中的每一个都有其优点和缺点。队列的优势在于,它允许您在多个消费者实例上划分数据处理,从而使您可以扩展处理。不幸的是,队列不是多订户的,数据只能被单个进程处理。发布-订阅允许你将数据广播到多个进程,但是没有办法扩展处理,因为每条消息都发送给每个订阅者。
卡夫卡的消费者群体概念概括了这两个概念。与队列一样,消费者组允许您在一个进程集合(消费者组的成员)上进行处理。与发布-订阅一样,卡夫卡允许你向多个消费群体广播消息。
卡夫卡的模型的优点是,每个主题都有这些属性——它可以扩展处理,同时也是多订户——不需要选择一个或另一个。
与传统的消息传递系统相比,卡夫卡拥有更强的订阅保证。
传统的队列在服务器上保持记录,如果多个消费者从队列中消费,那么服务器就会按照存储的顺序分发记录。然而,尽管服务器按顺序分发记录,但是这些记录是异步发送给消费者的,因此它们可能会在不同的消费者中出现。这实际上意味着在并行消费的情况下,记录的顺序丢失了。消息传递系统通常通过“独家使用者”的概念来解决这个问题,它只允许一个进程从队列中消费,当然这意味着在处理过程中没有并行性。
卡夫卡做得更好。通过在主题中有并行性的概念,卡夫卡能够在一个消费者流程的池中提供排序保证和负载平衡。这是通过将主题中的分区分配给消费者组中的消费者来实现的,这样每个分区都被组中的一个消费者使用。通过这样做,我们确保使用者是该分区的唯一阅读器,并按顺序使用数据。由于有许多分区,这仍然平衡了许多消费者实例的负载。但是要注意的是,在消费者组中,没有比分区更多的消费者实例。
卡夫卡作为存储系统
任何允许发布消息与消费消息分离的消息队列,实际上都是动态消息的存储系统。卡夫卡的不同之处在于,它是一个非常好的存储系统。
写给卡夫卡的数据被写到磁盘上,并被复制以容错。卡夫卡允许生产者等待确认,这样写就不会被认为是完整的,直到它被完全复制,并且保证即使服务器被写失败,也会一直保持下去。
卡夫卡使用的磁盘结构很好——不管你在服务器上有50 KB或50 TB的持久数据,卡夫卡都会执行同样的操作。
由于认真对待存储,并允许客户端控制其读取位置,您可以将卡夫卡看作是一种特殊用途的分布式文件系统,专门用于高性能、低延迟的提交日志存储、复制和传播。
有关卡夫卡的提交日志存储和复制设计的详细信息,请阅读此页。
卡夫卡作为流处理系统
仅仅阅读、生成和存储数据流是不够的,更多的是实现流的实时处理。
在卡夫卡中,流处理器是任何从输入主题中获取连续数据流的东西,在这个输入上执行一些处理,并产生连续的数据流到输出主题。
例如,一个零售应用程序可能会接收销售和发货的输入流,并输出从这些数据中计算出的新的订单和价格调整流。
可以直接使用生产者和消费者的api进行简单的处理。然而,对于更复杂的转换,卡夫卡提供了一个完全集成的流API。这使得构建能够进行非凡处理的应用程序,这些处理可以计算流中的聚合或连接流。
这个工具帮助解决了这类应用程序面临的难题:处理无序数据,将输入作为代码更改,执行有状态计算等等。
streams API基于卡夫卡提供的核心原语:它使用生产者和消费者的API进行输入,使用卡夫卡进行有状态存储,并在流处理器实例中使用相同的组机制来进行容错。
Putting the Pieces Together 拼接
这种消息传递、存储和流处理的组合可能看起来不同寻常,但对于卡夫卡作为流平台的角色来说,这是至关重要的。
像HDFS这样的分布式文件系统允许存储静态文件进行批处理。实际上,这样的系统只能存储和处理过去的历史数据。
传统的企业消息传递系统允许处理在您订阅后到达的未来消息。以这种方式构建的应用程序将处理未来的数据。
卡夫卡将这两种能力结合在一起,对于卡夫卡的使用来说,这两者的结合对于流应用和流数据管道来说都是至关重要的。
通过合并存储和低延迟订阅,流应用程序可以以同样的方式处理过去和未来的数据。这是一个单一的应用程序可以处理历史的、存储的数据,而不是在它到达最后一个记录时结束,它可以在将来的数据到达时继续处理。这是流处理的一个通用概念,它包含批处理和消息驱动的应用程序。
同样,对于流式数据管道来说,将订阅与实时事件结合在一起,就可以将卡夫卡用于非常低延迟的管道;但是,能够可靠地存储数据的能力使其能够在关键数据中使用它,在这些数据中,必须保证数据的交付,或者与离线系统集成,这些系统只定期加载数据,或者可能会持续很长一段时间用于维护。流处理设施使得在数据到达时转换数据成为可能。
有关卡夫卡提供的担保、api和功能的更多信息,请参阅文档的其余部分
翻译 - Kafka 介绍相关推荐
- [转]kafka介绍
转自 https://www.cnblogs.com/hei12138/p/7805475.html kafka介绍 1.1. 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台 ...
- 微服务 ZooKeeper ,Dubbo ,Kafka 介绍应用
目录 微服务 微服务的优缺点 微服务技术栈 编辑 常见的微服务框架 ZooKeeper 工作原理 ZooKeeper 集中存放管理 ZooKeeper 功能 动物园管理员 ZooKeeper 服务 ...
- matlab英文文献及翻译,外文文献及翻译MATLAB 介绍_蚂蚁文库
外文文献及翻译 MATLAB 介绍 外文原文 Introduction to MATLAB MATLAB (short for Matrix Laboratory) is a special-purp ...
- 介绍计算机硬件的英语作文带翻译,自我介绍作文之英语作文自我介绍带翻译(35页)-原创力文档...
英语作文自我介绍带翻译 [篇一:英文版自我介绍翻译(共4篇)] 篇一:面试用英语自我介绍怎么说 面试用英语自我介绍怎么说? 面试过程中自我介绍是在所难免的,中文自我介绍尚且难倒了很多人,更 何况是英文 ...
- KAFKA介绍(分布式架构)
2019独角兽企业重金招聘Python工程师标准>>> 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是 ...
- GDAL API Tutorial中文翻译(只介绍C++部分)
来源 https://www.gdal.org/gdal_tutorial.html (2018-10-28版) 旧网址已无法访问,新网址()2019-12-4: https://gdal.org/t ...
- Microsoft 离线翻译引擎介绍
随着全球化进程不断加速,中外企业的融合越来越频繁.如何打破语言的限制也成为企业最头疼问题,微软Azure有很强的翻译引擎其中中文到英文的翻译已经达到了人类的翻译水平. 但是在某些场景下,用户无法连接到 ...
- kafka介绍及使用
一.MAC环境下安装启动kafka 1.安装kafka brew install kafka复制代码 安装详情 安装详情里面包含一些使用介绍,主要包括几个部分: 安装kafka前默认安装了zookee ...
- 消息队列Kafka介绍
Kafka用来构建实时数据管道和数据流应用.它是水平可扩展的,具有容错性的,极其快速的,并且已应用于上千家公司的产品环境中. 介绍 Apache Kafka是一个分布式流平台[distributed ...
最新文章
- python关闭读写的所有的文件-Python读写txt文本文件的操作方法全解析
- python linux命令-Python执行Linux系统命令的4种方法
- linux删除旧网卡,如何删除旧网卡驱动
- python清空字典保留变量_python彻底清除字典数据,clear方法使用
- visual studio 2005占用cpu100% -_-...
- (chap6 Http首部) 其他首部字段
- boost::function_types::is_callable_builtin用法的测试程序
- qt 定时器_Qt开源作品23-颜色拾取器
- java垃圾回收机制优化_JVM性能优化--Java的垃圾回收机制
- 2016年《大数据》杂志调查问卷
- springBoot配置,贴个图
- 关于软件项目管理的一些问题
- eXeScope 使用中的小技巧
- ider中的html元素背景操作,idea怎么设置背景颜色
- 深扒ASML 的玩法,对工控企业生态圈的思考
- Second season twenty-fourth episode,Rachel‘s ex-boyfriend is going to marry Rachel‘s maid of honor
- opencv 读取双摄自动对齐参数intrinsics.yml、extrinsics.yml 2021-04-12
- 笔记本完全卸载自带键盘
- 国内移动互联网应用开发分析
- 【已解决】360扫地机X90拖地不出水怎么办?
热门文章
- UEG-F-10H-L抗干扰中继电器
- 《太极熊猫》如何玩好宝藏猎人 实时战场攻略详解
- 题库来源:安全生产模拟考试一点通公众号小程序 电工(中级)模拟考试题根据新电工(中级)考试大纲要求,安全生产模拟考试一点通将电工(中级)模拟考试试题进行汇编,组成一套电工(中级)全真模拟考试试题,学
- python的运维开发课程_老男孩python高级运维开发课程
- git推送代码到(码云)(github)
- WebSphere V8.5 静默安装升级(一)-独立安装每个安装包
- IoC控制反转设计原则——实现松耦合
- USDT/DAPP授权原理/USDT接口实现
- Dynamic .NET TWAIN 扫描-OCR好轻松
- 页面加载慢,Waiting (TTFB)时间长,怎么解决?