FUTURES模型 | 4. Demand 需求子模块
r.futures.demand模块决定预期的土地变化总量,它基于历史人口和土地发展数据之间的相关关系,创建了一个需求表格,记录在每个分区的每个步骤上转换的细胞数量。demand使用简单回归计算人口(自变量)和开发地区(因变量)之间的关系,我们甚至可以手动创建一个自定义demand文件,然后使用最合适的方法从运行中获取每一列的值。
输入数据:
- 两景以上来自以往不同年份的 土地发展栅格数据 (1表示已发展,0表示未发展),按照时间顺序进行排列
- 对应于土地发展栅格数据年限的历史分区 人口数据 ,在程序中以observed_population参数表示,输入格式为 *.csv
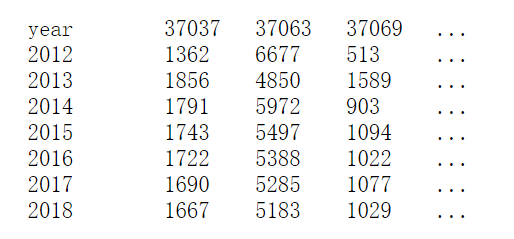
- 人口数据的格式表示如下图所示,第一列表示年份(与development参数表示的年份相符合),每一行表示当年内不同分区的人口数据,年份的间隔可以由separator参数来调整。
- 对于人口预测数据而言,也是同样的文件格式(对应于projected_population参数)

- 注意:
- 每个分区的代码在三个输入文件中应当是相同的
- simulation_times参数是一个逗号分隔的年份列表,表示需要被模拟的年份,可以利用python生成这个参数
','.join([str(i) for i in range(2015, 2031)])
输出数据:
- 输出的demand表格格式如下图,输出的格式为空格分隔的CSV文件,可以用任意记事本打开
- 表格中第一列表示年份,其余的列表示一个分区,每一行代表一个年份,表中的每一个值代表该区域每年新发展的细胞数量
- 注意,当发展需求为负值时(例如人口减少,或需求关系为反比时),demand表中的值设为0,因为模型不会模拟从已发展地区到未发展地区的变化
模型模拟
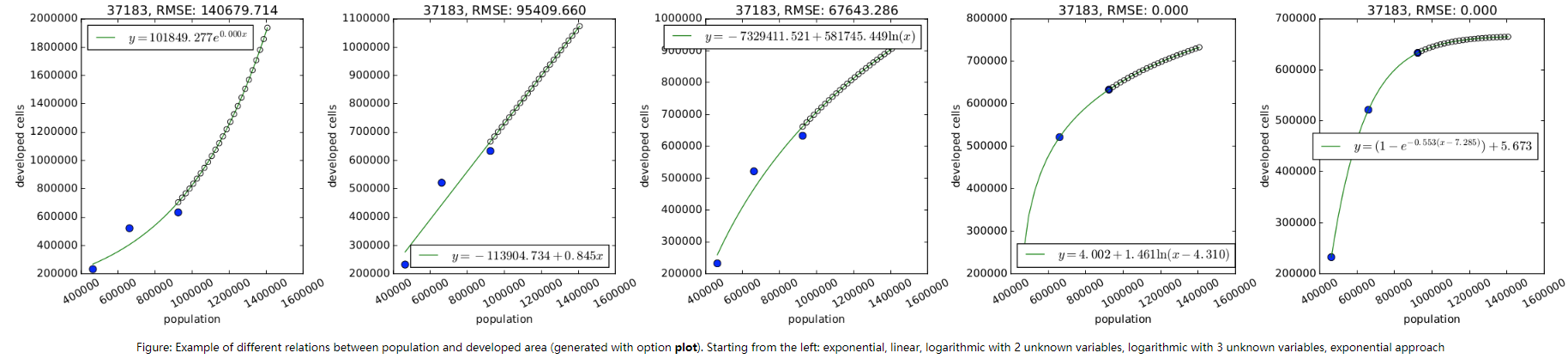
- 在模型中允许选择人口与已开发地区之间的关系类型,例如线性、对数(2种)、指数、指数逼近等。
- 如果利用了多种关系类型进行拟合,则使用RMSE选择最佳拟合模型。
- 推荐的方法有对数法、对数平方法、线性法和指数法,指数法和对数法要求scipy包和至少3个数据点(即三年以上的已发展地区的栅格图)
- 注:RMSE方法,即(Root Mean Squard Error)均方根误差法,线性回归的损失函数开根号,用来衡量观测值同真值之间的偏差
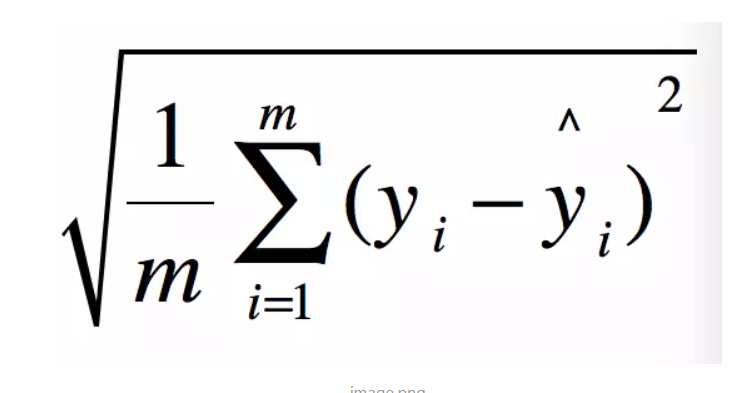
模拟结果
- 可以选择输出不同模型模拟结果的散点图,借此可以更有效地评估适合每个子区域的关系,文件的格式由扩展名决定,可以是PNG、PDF、SVG等
源码解析
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
##############################################################################
#
# MODULE: r.futures.demand
#
# AUTHOR(S): Anna Petrasova (kratochanna gmail.com)
#
# PURPOSE: create demand table for FUTURES
#
# COPYRIGHT: (C) 2015 by the GRASS Development Team
#
# This program is free software under the GNU General Public
# License (version 2). Read the file COPYING that comes with GRASS
# for details.
#
###############################################################################%module
#% description: Script for creating demand table which determines the quantity of land change expected.
#% keyword: raster
#% keyword: demand
#%end
#%option G_OPT_R_INPUTS
#% key: development
#% description: Names of input binary raster maps representing development
#% guisection: Input maps
#%end
#%option G_OPT_R_INPUT
#% key: subregions
#% description: Raster map of subregions
#% guisection: Input maps
#%end
#%option G_OPT_F_INPUT
#% key: observed_population
#% description: CSV file with observed population in subregions at certain times
#% guisection: Input population
#%end
#%option G_OPT_F_INPUT
#% key: projected_population
#% description: CSV file with projected population in subregions at certain times
#% guisection: Input population
#%end
#%option
#% type: integer
#% key: simulation_times
#% multiple: yes
#% required: yes
#% description: For which times demand is projected
#% guisection: Output
#%end
#%option
#% type: string
#% key: method
#% multiple: yes
#% required: yes
#% description: Relationship between developed cells (dependent) and population (explanatory)
#% options: linear, logarithmic, exponential, exp_approach, logarithmic2
#% descriptions:linear;y = A + Bx;logarithmic;y = A + Bln(x);exponential;y = Ae^(BX);exp_approach;y = (1 - e^(-A(x - B))) + C (SciPy);logarithmic2;y = A + B * ln(x - C) (SciPy)
#% answer: linear,logarithmic
#% guisection: Optional
#%end
#%option G_OPT_F_OUTPUT
#% key: plot
#% required: no
#% label: Save plotted relationship between developed cells and population into a file
#% description: File type is given by extension (.pfd, .png, .svg)
#% guisection: Output
#%end
#%option G_OPT_F_OUTPUT
#% key: demand
#% description: Output CSV file with demand (times as rows, regions as columns)
#% guisection: Output
#%end
#%option G_OPT_F_SEP
#% label: Separator used in input CSV files
#% guisection: Input population
#% answer: comma
#%endimport sys
import math
import numpy as npimport grass.script.core as gcore
import grass.script.utils as gutilsdef exp_approach(x, a, b, c):return (1 - np.exp(-a * (x - b))) + cdef logarithmic2(x, a, b, c):return a + b * np.log(x - c)def logarithmic(x, a, b):return a + b * np.log(x)def magnitude(x):return int(math.log10(x))def main():developments = options['development'].split(',')#待输入栅格数据的名称(文件名)observed_popul_file = options['observed_population']#历史人口调查数据projected_popul_file = options['projected_population']#未来人口预测数据sep = gutils.separator(options['separator'])#预测发展年之间的间隔subregions = options['subregions']#分区的输入栅格数据methods = options['method'].split(',')#选择的回归模型plot = options['plot']#拟合散点图simulation_times = [float(each) for each in options['simulation_times'].split(',')]#预测的年份时间#遍历选择的方法,确定是否有scipy包的支持(exp_approach和logarithmic2这两种方法)for each in methods:if each in ('exp_approach', 'logarithmic2'):try:from scipy.optimize import curve_fitexcept ImportError:gcore.fatal(_("Importing scipy failed. Method '{m}' is not available").format(m=each))# 模型需要输入两个以上的样本,而指数方法需要至少三个样本if len(developments) <= 2 and ('exp_approach' in methods or 'logarithmic2' in methods):gcore.fatal(_("Not enough data for method 'exp_approach'"))if len(developments) == 3 and ('exp_approach' in methods and 'logarithmic2' in methods):gcore.warning(_("Can't decide between 'exp_approach' and 'logarithmic2' methods"" because both methods can have exact solutions for 3 data points resulting in RMSE = 0"))#读取历史及预测人口数据,得到年份信息作为第一列observed_popul = np.genfromtxt(observed_popul_file, dtype=float, delimiter=sep, names=True)projected_popul = np.genfromtxt(projected_popul_file, dtype=float, delimiter=sep, names=True)year_col = observed_popul.dtype.names[0]observed_times = observed_popul[year_col]year_col = projected_popul.dtype.names[0]projected_times = projected_popul[year_col]#避免人口和栅格数据的年份不匹配if len(developments) != len(observed_times):gcore.fatal(_("Number of development raster maps doesn't not correspond to the number of observed times"))#计算每个分区中的已发展类型的细胞数gcore.info(_("Computing number of developed cells..."))table_developed = {}subregionIds = set()#遍历输入栅格数据for i in range(len(observed_times)):#显示进度条信息gcore.percent(i, len(observed_times), 1)#分区读取数据#read_command:将所有参数传递给pipe_command,然后等待进程完成,返回其标准输出#r.univar:对栅格像元数据进行分区统计(Zonal Statistics),包括求和、计数、最大最小值、范围、算术平均值、总体方差、标准差、变异系数等#g:在shell中打出运行状态,t:以表格形式输出而不是以标准流格式#zone:用于分区的的栅格地图,必须是CELL类型 map:输入栅格的名称(路径)data = gcore.read_command('r.univar', flags='gt', zones=subregions, map=developments[i])#遍历每一行的数据,即每一年的不同区域的信息for line in data.splitlines():stats = line.split('|')#跳过表头if stats[0] == 'zone':continue#获取分区的id,以及已发展细胞数(即sum值)subregionId, developed_cells = stats[0], int(stats[12])#分区id数组subregionIds.add(subregionId)#第一个年份,作为基准不计入if i == 0:table_developed[subregionId] = []#已发展地区的细胞数量计数数组table_developed[subregionId].append(developed_cells)gcore.percent(1, 1, 1)#对分区id进行排序subregionIds = sorted(list(subregionIds))# linear interpolation between population points#在人口数量样本点之间线性插值,获取模拟的人口点population_for_simulated_times = {}#以年份进行遍历for subregionId in table_developed.keys():#interp():一维线性插值函数#x: 要估计坐标点的x坐标值 xp:x坐标值 fp:y坐标值population_for_simulated_times[subregionId] = np.interp(x=simulation_times,xp=np.append(observed_times, projected_times),fp=np.append(observed_popul[subregionId],projected_popul[subregionId]))# regression# 模型的回归demand = {}i = 0#引入matplotlib画图if plot:import matplotlibmatplotlib.use('Agg')import matplotlib.pyplot as pltn_plots = np.ceil(np.sqrt(len(subregionIds)))fig = plt.figure(figsize=(5 * n_plots, 5 * n_plots))#遍历分区for subregionId in subregionIds:i += 1rmse = dict()predicted = dict()simulated = dict()coeff = dict()#遍历选择的每一种回归模型for method in methods:# observed population points for subregion# 历史人口数据值reg_pop = observed_popul[subregionId]# 线性插值之后的人口值simulated[method] = np.array(population_for_simulated_times[subregionId])if method in ('exp_approach', 'logarithmic2'):# we have to scale it firsty = np.array(table_developed[subregionId])magn = float(np.power(10, max(magnitude(np.max(reg_pop)), magnitude(np.max(y)))))x = reg_pop / magny = y / magnif method == 'exp_approach':initial = (0.5, np.mean(x), np.mean(y)) # this seems to work best for our data for exp_approachelif method == 'logarithmic2':popt, pcov = curve_fit(logarithmic, x, y)initial = (popt[0], popt[1], 0)with np.errstate(invalid='warn'): # when 'raise' it stops every time on FloatingPointErrortry:popt, pcov = curve_fit(globals()[method], x, y, p0=initial)except (FloatingPointError, RuntimeError):rmse[method] = sys.maxsize # so that other method is selectedgcore.warning(_("Method '{m}' cannot converge for subregion {reg}".format(m=method, reg=subregionId)))if len(methods) == 1:gcore.fatal(_("Method '{m}' failed for subregion {reg},"" please select at least one other method").format(m=method, reg=subregionId))else:predicted[method] = globals()[method](simulated[method] / magn, *popt) * magnr = globals()[method](x, *popt) * magn - table_developed[subregionId]coeff[method] = poptrmse[method] = np.sqrt((np.sum(r * r) / (len(reg_pop) - 2)))else:#简单对数回归 转换xif method == 'logarithmic':reg_pop = np.log(reg_pop)#指数回归if method == 'exponential':y = np.log(table_developed[subregionId])#线性回归 获得y值else:y = table_developed[subregionId]#回归A = np.vstack((reg_pop, np.ones(len(reg_pop)))).T#拟合 获取斜率和截距m, c = np.linalg.lstsq(A, y)[0] # y = mx + ccoeff[method] = m, c#对结果进行预测if method == 'logarithmic':predicted[method] = np.log(simulated[method]) * m + c#计算离差r = (reg_pop * m + c) - table_developed[subregionId]elif method == 'exponential':predicted[method] = np.exp(m * simulated[method] + c)r = np.exp(m * reg_pop + c) - table_developed[subregionId]else: # linearpredicted[method] = simulated[method] * m + cr = (reg_pop * m + c) - table_developed[subregionId]# RMSE# 计算均方根误差 rmse[method] = np.sqrt((np.sum(r * r) / (len(reg_pop) - 2)))#均方根误差最小的方法method = min(rmse, key=rmse.get)gcore.verbose(_("Method '{meth}' was selected for subregion {reg}").format(meth=method, reg=subregionId))# write demand# 组织需求数据demand[subregionId] = predicted[method]demand[subregionId] = np.diff(demand[subregionId])if np.any(demand[subregionId] < 0):gcore.warning(_("Subregion {sub} has negative numbers"" of newly developed cells, changing to zero".format(sub=subregionId)))demand[subregionId][demand[subregionId] < 0] = 0if coeff[method][0] < 0:demand[subregionId].fill(0)gcore.warning(_("For subregion {sub} population and development are inversely proportional,""will result in zero demand".format(sub=subregionId)))# draw# 做拟合模型的散点图if plot:ax = fig.add_subplot(n_plots, n_plots, i)ax.set_title("{sid}, RMSE: {rmse:.3f}".format(sid=subregionId, rmse=rmse[method]))ax.set_xlabel('population')ax.set_ylabel('developed cells')# plot known pointsx = np.array(observed_popul[subregionId])y = np.array(table_developed[subregionId])ax.plot(x, y, marker='o', linestyle='', markersize=8)# plot predicted curvex_pred = np.linspace(np.min(x),np.max(np.array(population_for_simulated_times[subregionId])), 30)cf = coeff[method]if method == 'linear':line = x_pred * cf[0] + cf[1]label = "$y = {c:.3f} + {m:.3f} x$".format(m=cf[0], c=cf[1])elif method == 'logarithmic':line = np.log(x_pred) * cf[0] + cf[1]label = "$y = {c:.3f} + {m:.3f} \ln(x)$".format(m=cf[0], c=cf[1])elif method == 'exponential':line = np.exp(x_pred * cf[0] + cf[1])label = "$y = {c:.3f} e^{{{m:.3f}x}}$".format(m=cf[0], c=np.exp(cf[1]))elif method == 'exp_approach':line = exp_approach(x_pred / magn, *cf) * magnlabel = "$y = (1 - e^{{-{A:.3f}(x-{B:.3f})}}) + {C:.3f}$".format(A=cf[0], B=cf[1], C=cf[2])elif method == 'logarithmic2':line = logarithmic2(x_pred / magn, *cf) * magnlabel = "$y = {A:.3f} + {B:.3f} \ln(x-{C:.3f})$".format(A=cf[0], B=cf[1], C=cf[2])ax.plot(x_pred, line, label=label)ax.plot(simulated[method], predicted[method], linestyle='', marker='o', markerfacecolor='None')plt.legend(loc=0)labels = ax.get_xticklabels()plt.setp(labels, rotation=30)if plot:plt.tight_layout()fig.savefig(plot)# write demand# 输出需求数据with open(options['demand'], 'w') as f:header = observed_popul.dtype.names # the order is kept heref.write('\t'.join(header))f.write('\n')i = 0for time in simulation_times[1:]:f.write(str(int(time)))f.write('\t')# put 0 where there are more counties but are not in regionfor sub in header[1:]: # to keep order of subregionsif sub not in subregionIds:f.write('0')else:f.write(str(int(demand[sub][i])))if sub != header[-1]:f.write('\t')f.write('\n')i += 1if __name__ == "__main__":options, flags = gcore.parser()sys.exit(main())
FUTURES模型 | 4. Demand 需求子模块相关推荐
- FUTURES模型 | 5. Potential 潜力子模块
POTENTIAL潜力值是由一组与地点适应性因子相关的系数计算得到的,表达的是某个地块被开发的可能性.这些系数通过R语言中的Ime4包进行多级逻辑回归得到,系数随着区域的变化而变化,最佳的模型由MuM ...
- 软件项目管理相关内容1:项目介绍与背景 2:乙方投标书 3:合同 4:生存期模型 5:需求规格说明书 6:WBS 7:成本估算 8:甘特图 9:进度计划 10:质量计划 11:项目总结
软件项目管理相关内容 内容太多只选取部分内容 点击链接查看全部文档和项目 1:项目介绍与背景 一.项目名称 (一)项目背景 第二课堂被认为是实施素质教育的重要途径和有效方式,它能够能够培养学生与人相处 ...
- 【Netty】Netty 入门案例分析 ( Netty 线程模型 | Netty 案例需求 | IntelliJ IDEA 项目导入 Netty 开发库 )
文章目录 一. Netty 线程模型 二. Netty 案例需求 三. IntelliJ IDEA 引入 Netty 包 一. Netty 线程模型 1 . Netty 中的线程池 : Netty 中 ...
- 43_pytorch nn.Module,模型的创建,构建子模块,API介绍,Sequential(序号),ModuleList,ParameterList,案例等(学习笔记)
1.40.PyTorch nn.Module 1.40.1.模型的创建 1.40.2.构建子模块 1.40.3.nn.Module API介绍 1.40.3.1.核心功能 1.40.3.2.查看模块 ...
- python对于一元线性回归模型_Python一元线性回归分析实例:价格与需求的相关性...
来自烟水暖的学习笔记 回归分析(Regression analysis) 回归分析(Regression analysis),是研究因变量与自变量之间相关性的一种数学方法,并将相关性量化,即得到回归方 ...
- 【产品经理】常用需求优先级评估模型
阐述了其在事件中认为比较有效的3种排序模型,以及适用的场景.另外也对需求评估的目标以及拒绝需求的个人实战经验,做了一些分享.相信对各位B端新人能够带来帮助,欢迎阅读. B 端产品的需求来源通常有老板. ...
- LEAP能源供应转换、能源需求及碳排放预测中的基础数据搜集及处理、能源平衡表核算、模型框架构建、模型操作、情景设计、结果分析、优化、预测结果不确定性分析
采用部门分析法建立的LEAP(Long Range Energy Alternatives Planning System/ Low emission analysis platform,长期能源可替 ...
- [Power Designer]创建需求模型RQM
软件工程标准词汇表中对"需求"的定义: 用户为了解决问题或实现目标所需具备的条件或能力: 系统或系统组件为达到合同.标准.规范或其他正式文档中所规定的要求而需要具备的条件或能力: ...
- excel多元线性拟合_Python一元线性回归分析实例:价格与需求的相关性
来自烟水暖的学习笔记 回归分析(Regression analysis) 回归分析(Regression analysis),是研究因变量与自变量之间相关性的一种数学方法,并将相关性量化,即得到回归方 ...
最新文章
- C#中自定义PictureBox控件
- 微信视频号推荐算法上分技巧
- 算法练习day4——190321(小和、逆序对、划分、荷兰国旗问题)
- CSS3那些不为人知的高级属性
- Qt之QProcess(一)运行cmd命令
- html5 retina 1像素,走向视网膜(Retina)的Web时代
- 服务器电源维修接灯泡,维修串接灯泡电路图
- 8. jQuery 效果 - 动画
- 拓端tecdat|R语言非线性回归nls探索分析河流阶段性流量数据和评级曲线、流量预测可视化
- mysql 分页 order_mysql学习笔记:九.排序和分页(order by、limit)
- 最新小浣熊5.0漫画CMS精仿土豪漫画系统源码
- 2019版PHP自动发卡平台源码
- eeupdate使用说明_Fedora如何修改网络接口名称?Fedora修改网络接口名称的方法
- 计算机重新启动后打印机脱机,重启电脑后打印机脱机怎么办
- 【NISP一级】考前必刷九套卷(九)
- 博通无线网卡驱动安装linux,Ubuntu下Broadcom 802.11g无线网卡驱动安装方法
- Java知识点的总结(一)
- 2018中国初创企业融资近千亿 人工智能领跑新经济破局
- 全志A33移植openharmony3.1标准系统之添加产品编译
- Android延时执行事件的方法
热门文章
- React兼容IE8
- Spring Cloud Security OAuth2结合网关
- Oracle闪回报错,Oracle闪回恢复 - osc_pnw2apz4的个人空间 - OSCHINA - 中文开源技术交流社区...
- python表达式3or5的值为_表达式 3 or 5 的值为________。(5.0分)_学小易找答案
- 王者荣耀服务器什么时候增加人数,王者荣耀服务器连续两天崩!春节每人游戏时间暴涨75%,玩家要背锅?...
- 【GPGPU编程模型与架构原理】第一章 1.1 GPGPU 与并行计算机
- 7-14 然后是几点 (15分)
- 快乐的牛奶商 c语言6,C语言程序设计基础实训手册
- truetype字体怎么转换成普通字体_字体 – 如何将位图字体(.FON)转换为truetype字体(.TTF)?...
- su、sudo、su - root的区别