将redis加入到elk日志系统里
之前在http://blog.51cto.com/chenx1242/2048014 里面,我画的那个架构图里说了整个架构可以加入redis,但是在文章里我没有写到redis怎么加进去。为了让整个系统更好的分层,是非常建议引入 Redis 的,毕竟Redis 服务器是logstash官方推荐的broker选择。Redis 作为一个缓存,能够帮助我们在主节点上屏蔽掉多个从节点之间不同日志文件的差异,负责管理日志端(从节点)的人可以专注于向 Redis 里生产数据,而负责数据分析聚合端的人则可以专注于从 Redis 内消费数据。所以这一次实验要把redis加进去,同时也要部署一个nginx,让elk再去采集nginx的日志。
整个架构图图下:

部署redis
安装redis的方法请去看http://blog.51cto.com/chenx1242/1793895 ,我这里使用的redis版本是4.0.6,在执行#make test的时候可能会有如下的错误:

那就安装新一点的tcl吧,方法如下:
wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz
tar xzvf tcl8.6.1-src.tar.gz -C /usr/local/
cd /usr/local/tcl8.6.1/unix/
./configure
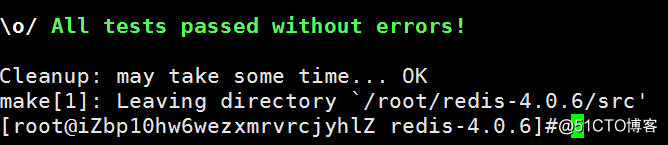
make && make install然后重新去#make test就会看到成功的字样,如图:
现在redis的漏洞比较多,大多数就是因为密码太简单导致的,所以把redis密码改一下,在redis.conf里,改成如下的样子:
bind 内网IP地址 127.0.0.1 ###仅允许内网和本机访问
protected-mode yes ###保护模式开启
port 6379 ###端口默认为6379,按需修改
daemonize yes ###守护模式开启
pidfile /usr/local/redis/redis.pid ###指定pid文件路径和文件名
logfile "/usr/local/redis/redis.log" ###指定日志文件路径和文件名
dbfilename redis.rdb ###指定数据文件RDB文件名
dir /usr/local/redis/ ###指定数据文件RDB文件的存放路径
requirepass 『YOURPASSWORD』 ###设置访问密码,提升密码强度保存之后启动redis即可。
如果redis是主从配置,若master配置了密码则slave也要配置相应的密码参数否则无法进行正常复制的。需要在slave的redis.conf里找到“#masterauth mstpassword”,去掉注释,也改成跟master一样的密码,重启一下即可。
nginx的安装这里就不写了,直接看http://www.runoob.com/linux/nginx-install-setup.html 这个就行了。
安装x-pack
x-pack是elk官方提供的认证授权插件,安装方法很简单,分别找到下面三个文件,然后后面加上“install x-pack”即可:
./elasticsearch-plugin install x-pack --batch
./logstash-plugin install x-pack
./kibana-plugin install x-pack如果要查看已经安装的插件,那就是:
[root@chen-elk-001 bin]# ./elasticsearch-plugin list
x-pack
[root@chen-elk-001 bin]# ./kibana-plugin list
x-pack@5.6.4如果kibana-plugin要卸载x-pack,那就是:
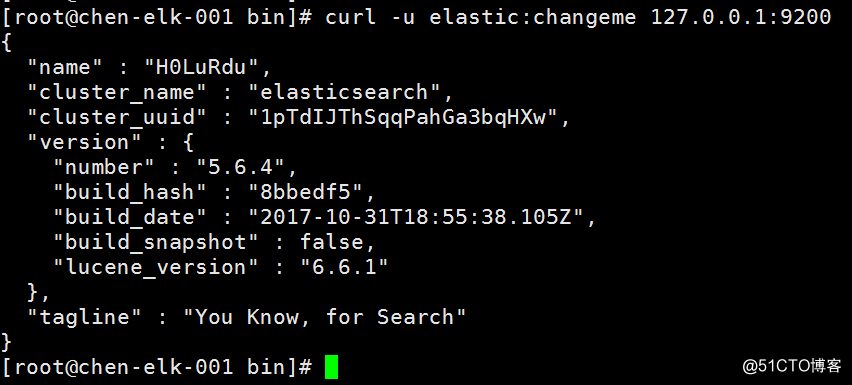
./kibana-plugin remove x-pack重启服务即可登录,默认的登录用户名: elastic 密码:changeme。
这里注意一下,#./logstash-plugin install x-pack 的时候可能是出现ruby源的错误,如图:

这是因为中国特色社会主义的网络限制访问https://rubygems.org ,一般来说,可以把它更改成阿里的ruby源https://ruby.taobao.org/ ,不过如果你的服务器无法跨越长城的话,那么更改也是不好使的,所以在这一步,我选择离线安装x-pack。也就是先把https://artifacts.elastic.co/downloads/packs/x-pack/x-pack-5.6.4.zip 这个文件下载到本地上传到服务器的root文件夹里,然后安装:
[root@chen-logstash-001 bin]# ./logstash-plugin install file:///root/x-pack-5.6.4.zip
Installing file: /root/x-pack-5.6.4.zip
Install successful配置filebeat
由于这个nginx我们需要先让filebeat把nginx.log和error.log先推到redis存储,然后再由redis推到logstash。配置filebeat.yml的具体信息如下:
[root@iZbp10hw6wezxmrvrcjyhlZ filebeat]# grep -iv '#' /etc/filebeat/filebeat.yml | grep -iv '^$'
filebeat.prospectors:
- input_type: logpaths:- /usr/local/nginx/logs/*.log #这里是nginx的日志文件夹output.redis: #以下这部分都是新加的enabled: truehosts: ["127.0.0.1:6379"]key: logindexer_list #与redis配置文件里的key遥相呼应password: 『YOURPASSWORD』 #跟上面的密码遥相呼应配置完毕之后,启动filebeat,命令语句:#/etc/init.d/filebeat start -c /etc/filebeat/filebeat.yml。
配置logstash
由于这台logstash已经开启了一个logstash进程,那么再收集nginx的日志需要新开一个logstash进程,也需要新写一个conf文件,假设新的conf文件是nginx-logstash.conf,它的写法如下:
input {redis {host => "10.168.173.181"type => "redis-input"data_type => "list"key => "logindexer_list"port => 6379password => "ChenRedi$"}
}# filter configration here
output {elasticsearch {hosts => [ "10.162.80.192:9200" ]user => elasticpassword => changemeindex => "nginxlogstash-%{+YYYY.MM.dd}" #这个是新的索引}
stdout {codec => rubydebug}
}现在logstash不支持多个实例共享一个path.data,所以要在在启动不同实例的时候,命令行里增加"--path.data PATH " ,为不同实例指定不同的路径。启动logstash之后,看到显示如下:

再到nginx的日志看一下,因为logstash里没有做日志的切割,所以是整个一个类似字符串的形式发送了过来:

果然有这样的日志,可见logstash与nginx的redis已经正确连接。在elasticsearch里,使用#curl -u 账号密码 'localhost:9200/_cat/indices?v' 查询索引的时候,就会看到那个"nginxlogstash",如图:

参考资料:https://doc.yonyoucloud.com/doc/logstash-best-practice-cn/input/redis.html
最后的最后,如果您觉得本文对您升职加薪有帮助,那么请不吝赞助之手,刷一下下面的二维码,赞助本人继续写更多的博文!
来源:http://blog.51cto.com/chenx1242/2054719
将redis加入到elk日志系统里相关推荐
- 创业公司如何做数据分析(四)ELK日志系统
作为系列文章的第四篇,本文将重点探讨数据采集层中的ELK日志系统.日志,指的是后台服务中产生的log信息,通常会输入到不同的文件中,比如Django服务下,一般会有nginx日志和uWSGI日志.这些 ...
- 创业公司做数据分析(四)ELK日志系统
作为系列文章的第四篇,本文将重点探讨数据采集层中的ELK日志系统.日志,指的是后台服务中产生的log信息,通常会输入到不同的文件中,比如Django服务下,一般会有nginx日志和uWSGI日志. ...
- 日志审计系统及ELK日志系统
日志审计系统 1.日志审计 1.1 背景 1.2 原理 核心目标 1.3 功能 日志采集 关联分析 实时警告 日志取证分析 监管合规 1.4 日志审计系统常见模块 2.ELK 日志系统介绍 2.1 背 ...
- ELK日志系统的写入优化
日志系统的写入优化 1. 日志集群优化的基本原则 对于日志收集系统来说,就是使用尽可能少的资源来存储尽可能多的日志,所以需要结合日志集群的特点进行优化.这些优化一般可以分为两个方面,一个方面是提升服务 ...
- 第二十三周微职位elk日志系统
利用ELK+redis搭建一套nginx日志分析平台. logstash,elasticsearch,kibana 怎么进行nginx的日志分析呢?首先,架构方面,nginx是有日志文件的,它的每个请 ...
- ELK日志系统之使用Rsyslog快速方便的收集Nginx日志
常规的日志收集方案中Client端都需要额外安装一个Agent来收集日志,例如logstash.filebeat等,额外的程序也就意味着环境的复杂,资源的占用,有没有一种方式是不需要额外安装程序就能实 ...
- ELK日志系统搭建完整详细步骤
文章目录 一.ELK 是什么? 二.安装部署 Elasticsearch 1.下载 2.解压到指定目录 3.修改配置文件 4.新建用户并赋权 5.切换至新建的用户并启动 Elasticsearch 错 ...
- ES冷热分离架构设计:一招让你的ELK日志系统节省 50% 的硬盘成本
文章目录 引言 1.冷热数据分离思想 2.数据层:Data tiers 2.1 内容层:Content Tier 2.2 热数据层:Hot Tier 2.3 温数据层:Warm Tier 2.4 冷数 ...
- windows下springboot项目部署elk日志系统教程elasticsearch与logstash与kibana
1.项目中加入依赖: compile 'net.logstash.logback:logstash-logback-encoder:6.0' 如果是maven项目的话:字符串中的冒号为隔断,第一个为g ...
最新文章
- ICRA 2022 | 基于多模态变分自编码器的任意时刻三维物体重建
- 哈佛、MIT学者联手,创下矩阵乘法运算最快纪录
- Day2 : iOS第三方框架MBProgressHUD学习笔记
- r k-means 分类结果_R语言信用评分卡:数据分箱(binning)
- android 请求参数打印,Android开发-----关于解决Retrofit打印HttpLog和设置连接超时的问题...
- Visual Studio Code: 利用 MSSQL 插件创建数据库 IDE
- strcasecmp()--忽略大小写比较字符串
- Linux命令:ls、grep、wc统计目录下文件及文件夹的个数。
- 开源不止,前进不息:2018 OpenInfra Days China 来了!
- Python 中的全局变量
- Centos7安装官方JDK
- c#中动态调用webService
- 基于MATLAB实现四阶龙格库塔法求解一、二阶微分方程实例
- 如何用php建立图库,教你搭建自己的图片库
- “程序员猝死”引发的思考
- Adobe Reader XI已停止工作的解决办法
- HTML+CSS 编辑的(多列布局、相册、百度首页)、盒子模型
- 如何在 Windows 中快速查找文档
- 修改so文件的关键方法
- 西电计算机学院崔江涛,“师德标兵”崔江涛:人才培养的研究者与实践者