Linux 高可用(HA)集群之DRBD详解
http://freeloda.blog.51cto.com/2033581/1275384
大纲
一、前言
二、DRBD 是什么
三、DRBD 主要功能
四、DRBD 工作原理
五、DRBD与HA 集群
六、DRBD 复制模式
七、DRBD 配置工具
八、DRBD 配置文件
九、DRBD 资源
十、DRBD 支持的底层设备
十一、DRBD 配置步骤
十二、安装与配置 DRBD 详解
十三、DRBD 双主模式配置示例
一、前言
在这一篇博文中我们主要讲解DRBD,在这里说点题外话,其实学习任何Linux知识点,最好的方式就是去看官方文档,这是Linux的特点,也是开源精神的体现,不但提供软件,还提供学习资料,这里DRBD的官方文档http://www.drbd.org/users-guide/把DRBD讲的非常详细,但是全是英文的,学习Linux有点好,就是有很多博友受开源精神影响,也会去做很无私事,这不有哥们就把我们的文档翻译出来了,这是翻译版供大家参考http://blog.csdn.net/liuyunfengheda/article/details/6460814,我在这里主要说一下DRBD的重要知识点,有时间的博友可以认真的学习一下官方文档。
二、DRBD 是什么
简单的说,DRBD (Distributed Replicated Block Device,分布式复制块设备)是由内核模块和相关脚本而构成,用以构建高可用性的集群。其实现方式是通过网络来镜像整个设备。你可以把它看作是一种网络RAID1。
三、DRBD 主要功能
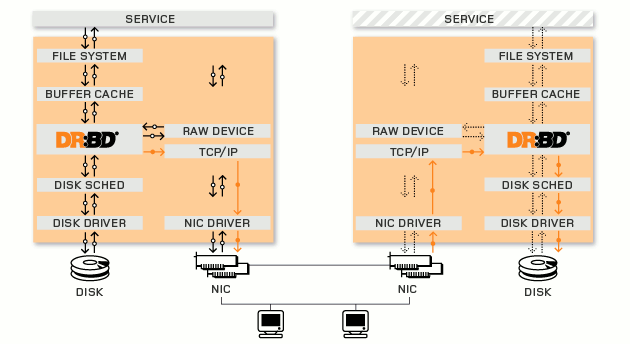
简单说一下DRBD主要功能,DRBD 负责接收数据,把数据写到本地磁盘,然后通过网络将同样的数据发送给另一个主机,另一个主机再将数据存到自己的磁盘中。
四、DRBD 工作原理
每个设备(drbd 提供了不止一个设备)都有一个状态,可能是‘主’状态或‘从’状态。在主节点上,应用程序应能运行和访问drbd设备(/dev/drbd*)。每次写入都会发往本地磁盘设备和从节点设备中。从节点只能简单地把数据写入它的磁盘设备上。 读取数据通常在本地进行。 如果主节点发生故障,心跳(heartbeat或corosync)将会把从节点转换到主状态,并启动其上的应用程序。(如果您将它和无日志FS 一起使用,则需要运行fsck)。如果发生故障的节点恢复工作,它就会成为新的从节点,而且必须使自己的内容与主节点的内容保持同步。当然,这些操作不会干扰到后台的服务。
五、DRBD与HA 集群
大部分现行高可用性集群(如:惠普、IBM、Dell)使用的是共享存储器,因此存储器连接多个节点(用共享的SCSI 总线或光纤通道就可以做到)。DRBD 也可以作为一个共享的设备,但是它并不需要任何不常见的硬件。它在IP 网络中运行,而且在价格上IP 网络要比专用的存储网络经济的多。目前,DRBD 每次只允许对一个节点进行读写访问,这对于通常的故障切换高可用性集群来讲已经足够用了。现在的版本将支持两个节点同时进行读写存取。这很有用,比如对GFS 来讲就是如此。兼容性DRBD可以在IDE、SCSI 分区和整个驱动器之上运行,但不能在回路模块设备上运行。(如果您硬要这样做,它就会发生死锁)。DRBD 也不能在回送网络设备中运行。(因为它同样会发生死锁:所有请求都会被发送设备占用,发送流程也会阻塞在sock_sendmsg()中。有时,接收线程正从网络中提取数据块,并试图把它放在高速缓存器中;但系统却要把一些数据块从高速缓存器中取到磁盘中。这种情况往往会在接收器的环境下发生,因为所有的请求都已经被接收器块占用了。
六、DRBD 复制模式
协议A:异步复制协议。本地写成功后立即返回,数据放在发送buffer中,可能丢失。
协议B:内存同步(半同步)复制协议。本地写成功并将数据发送到对方后立即返回,如果双机掉电,数据可能丢失。
协议C:同步复制协议。本地和对方写成功确认后返回。如果双机掉电或磁盘同时损坏,则数据可能丢失。
一般用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,我们在生产环境中还是用C协议。
七、DRBD 配置工具
drbdadm:高级管理工具,管理/etc/drbd.conf,向drbdsetup和drbdmeta发送指令。
drbdsetup:配置装载进kernel的DRBD模块,平时很少直接用。
drbdmeta:管理META数据结构,平时很少直接用。
八、DRBD 配置文件
DRBD的主配置文件为/etc/drbd.conf;为了管理的便捷性,目前通常会将些配置文件分成多个部分,且都保存至/etc/drbd.d目录中,主配置文件中仅使用"include"指令将这些配置文件片断整合起来。通常,/etc/drbd.d目录中的配置文件为global_common.conf和所有以.res结尾的文件。其中global_common.conf中主要定义global段和common段,而每一个.res的文件用于定义一个资源。
在配置文件中,global段仅能出现一次,且如果所有的配置信息都保存至同一个配置文件中而不分开为多个文件的话,global段必须位于配置文件的最开始处。目前global段中可以定义的参数仅有minor-count, dialog-refresh, disable-ip-verification和usage-count。
common段则用于定义被每一个资源默认继承的参数,可以在资源定义中使用的参数都可以在common段中定义。实际应用中,common段并非必须,但建议将多个资源共享的参数定义为common段中的参数以降低配置文件的复杂度。
resource段则用于定义drbd资源,每个资源通常定义在一个单独的位于/etc/drbd.d目录中的以.res结尾的文件中。资源在定义时必须为其命名,名字可以由非空白的ASCII字符组成。每一个资源段的定义中至少要包含两个host子段,以定义此资源关联至的节点,其它参数均可以从common段或drbd的默认中进行继承而无须定义。
九、DRBD 资源
Resource name:可以是除了空白字符的任意的ACSII码字符
DRBD device:在双方节点上,此DRBD设备的设备文件;一般为/dev/drbdN,其主设备号147
Disk configuration:在双方节点上,各自提供的存储设备
Nerwork configuration:双方数据同步时所使用的网络属性
案例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
resource web { #资源名为“web”
on node1.magedu.com { #设置节点cluster1
device /dev/drbd0 ; #指出drbd的标示名
disk /dev/sda5 ; #指出作为drbd的设备
address 172.16.100.11:7789; #指定ip和端口号
meta-disk internal; #网络通信属性,指定drbd的元数据在本机
}
on node2.magedu.com {
device /dev/drbd0 ;
disk /dev/sda5 ;
address 172.16.100.12:7789;
meta-disk internal;
}
}
|
十、DRBD 支持的底层设备
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一块物理的磁盘,可以在商脉内创建文件系统。DRBD所支持的底层设备有以下这些类:
一个磁盘,或者是磁盘的某一个分区。
一个soft raid 设备。
一个LVM的逻辑卷。
一个EVMS(Enterprise Volume Management System,企业卷管理系统)的卷。
其他任何的块设备。
十一、DRBD 配置步骤
安装drbd
配置资源文件(定义资料名称,磁盘,节点信息,同步限制等)
将drbd加入到系统服务chkconfig --add drbd
初始化资源组drbdadm create-md resource_name
启动服务 service drbd start
设置primary主机,并同步数据
分区、格式化/dev/drbd*
一个节点进行挂载
查看状态
十二、安装与配置 DRBD 详解
1.实验拓扑
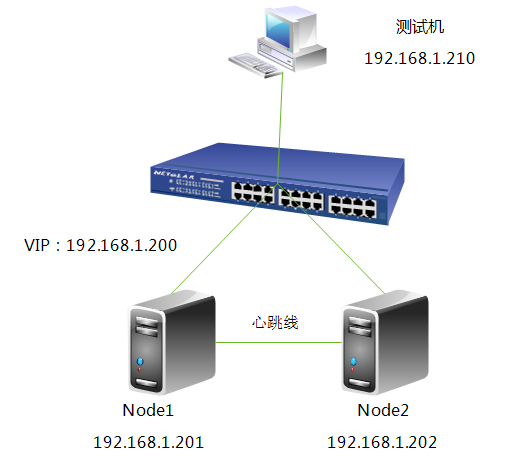
2.实验环境
(1).操作系统
CentOS 6.4 X86_64
(2).软件环境
kmod-drbd84-8.4.2-1.el6_3.elrepo.x86_64
drbd84-utils-8.4.2-1.el6.elrepo.x86_64
(3).安装epel源
node1:
|
1
2
3
4
5
6
7
8
|
[root@node1 src] # wget http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
[root@node1 src] # rpm -ivh epel-release-6-8.noarch.rpm
warning: epel-release-6-8.noarch.rpm: Header V3 RSA /SHA256Signature , key ID 0608b895: NOKEY
Preparing... ########################################### [100%]
1:epel-release ########################################### [100%]
[root@node1 src] # rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
[root@node1 ~] # rpm -ivh http://elrepo.org/elrepo-release-6-5.el6.elrepo.noarch.rpm
[root@node1 ~] # yum list
|
node2:
|
1
2
3
4
5
6
7
8
|
[root@node2 src] # wget http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
[root@node2 src] # rpm -ivh epel-release-6-8.noarch.rpm
warning: epel-release-6-8.noarch.rpm: Header V3 RSA /SHA256Signature , key ID 0608b895: NOKEY
Preparing... ########################################### [100%]
1:epel-release ########################################### [100%]
[root@node2 src] # rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
[root@node2 ~] # rpm -ivh http://elrepo.org/elrepo-release-6-5.el6.elrepo.noarch.rpm
[root@node2 ~] # yum list
|
3.安装DRBD
说明:drbd共有两部分组成:内核模块和用户空间的管理工具。其中drbd内核模块代码已经整合进Linux内核2.6.33以后的版本中,因此,如果您的内核版本高于此版本的话,你只需要安装管理工具即可;否则,您需要同时安装内核模块和管理工具两个软件包,并且此两者的版本号一定要保持对应。CentOS 6.4的内核版本是2.6.32-358.el6.x86_64,所以还提安装内核模块。
node1:
|
1
|
[root@node1 ~] # yum -y install drbd84 kmod-drbd84
|
node2:
|
1
|
[root@node2 ~] # yum -y install drbd84 kmod-drbd84
|
4.配置DRBD
(1).查看一下配置文件
|
1
2
3
4
5
|
[root@node1 ~] # ll /etc/drbd.conf /etc/drbd.d/
-rw-r--r-- 1 root root 133 9月 6 2012 /etc/drbd .conf
/etc/drbd .d/:
总用量 4
-rw-r--r-- 1 root root 1650 9月 6 2012 global_common.conf
|
注:drbd配置文件是分为模块化的,drbd.conf是主配置文件,其它模块配置文件在/etc/drbd.d/下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
[root@node1 ~] # vim /etc/drbd.conf #查看主配置文件
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf" ;
include "drbd.d/*.res" ;
[root@node1 ~] # cat /etc/drbd.d/global_common.conf #查看主配置文件
global {
usage-count yes ;
# minor-count dialog-refresh disable-ip-verification
}
common {
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f" ;
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f" ;
local -io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f" ;
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
}
disk {
# size max-bio-bvecs on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
}
net {
# protocol timeout max-epoch-size max-buffers unplug-watermark
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
}
}
|
(2).修改全局配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
[root@node1 ~] # cat /etc/drbd.d/global_common.conf
global {
usage-count no; #让linbit公司收集目前drbd的使用情况,yes为参加,我们这里不参加设置为no
# minor-count dialog-refresh disable-ip-verification
}
common {
handlers {
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f" ;
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f" ;
local -io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f" ;
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
}
disk {
# size max-bio-bvecs on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
on-io-error detach; #同步错误的做法是分离
}
net {
# protocol timeout max-epoch-size max-buffers unplug-watermark
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
cram-hmac-alg "sha1" ; #设置加密算法sha1
shared-secret "mydrbdlab" ; #设置加密key
}
}
|
(3).增加资源
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@node1 drbd.d] # cat web.res
resource web {
on node1. test .com {
device /dev/drbd0 ;
disk /dev/sdb ;
address 192.168.1.201:7789;
meta-disk internal;
}
on node2. test .com {
device /dev/drbd0 ;
disk /dev/sdb ;
address 192.168.1.202:7789;
meta-disk internal;
}
}
|
(4).将配置文件同步到node2
|
1
2
3
4
5
6
7
8
|
[root@node1 drbd.d] # scp global_common.conf web.res node2:/etc/drbd.d/
The authenticity of host 'node2 (192.168.1.202)' can't be established.
RSA key fingerprint is da:20:3d:2a:ef:4f:03: bc :4d:91:5e:82:25:e7:8c:ec.
Are you sure you want to continue connecting ( yes /no )? yes ^[[A
Warning: Permanently added 'node2,192.168.1.202' (RSA) to the list of known hosts.
root@node2's password:
global_common.conf 100% 1724 1.7KB /s 00:00
web.res 100% 285 0.3KB /s 00:00
|
(5).node1与node2上初始化资源
node1:
|
1
2
3
4
5
|
[root@node1 ~] # drbdadm create-md web
Writing meta data...
initializing activity log
NOT initializing bitmap
New drbd meta data block successfully created.
|
node2:
|
1
2
3
4
5
|
[root@node2 ~] # drbdadm create-md web
Writing meta data...
initializing activity log
NOT initializing bitmap
New drbd meta data block successfully created.
|
(6).node1与node2上启动DRBD服务
node1:
|
1
2
3
4
5
6
7
8
|
[root@node1 ~] # service drbd start
Starting DRBD resources: [
create res: web
prepare disk: web
adjust disk: web
adjust net: web
]
.
|
node2:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[root@node2 ~] # service drbd start
Starting DRBD resources: [
create res: web
prepare disk: web
adjust disk: web
adjust net: web
]
..........
***************************************************************
DRBD's startup script waits for the peer node(s) to appear.
- In case this node was already a degraded cluster before the
reboot the timeout is 0 seconds. [degr-wfc-timeout]
- If the peer was available before the reboot the timeout will
expire after 0 seconds. [wfc-timeout]
(These values are for resource 'web' ; 0 sec -> wait forever)
To abort waiting enter 'yes' [ 11]:
.
|
(7).查看一下启动状态
node1:
|
1
2
3
4
5
|
[root@node1 ~] # cat /proc/drbd
version: 8.4.2 (api:1 /proto :86-101)
GIT- hash : 7ad5f850d711223713d6dcadc3dd48860321070c build by dag@Build64R6, 2012-09-06 08:16:10
0: cs:Connected ro:Secondary /Secondary ds:Inconsistent /Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20970844
|
node2:
|
1
2
3
4
5
|
[root@node2 ~] # cat /proc/drbd
version: 8.4.2 (api:1 /proto :86-101)
GIT- hash : 7ad5f850d711223713d6dcadc3dd48860321070c build by dag@Build64R6, 2012-09-06 08:16:10
0: cs:Connected ro:Secondary /Secondary ds:Inconsistent /Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20970844
|
(8).命令查看一下
node1:
|
1
2
|
[root@node1 ~] # drbd-overview
0:web /0 Connected Secondary /Secondary Inconsistent /Inconsistent C r-----
|
node2:
|
1
2
|
[root@node2 ~] # drbd-overview
0:web /0 Connected Secondary /Secondary Inconsistent /Inconsistent C r-----
|
从上面的信息中可以看出此时两个节点均处于Secondary状态。于是,我们接下来需要将其中一个节点设置为Primary。在要设置为Primary的节点上执行如下命令:drbdsetup /dev/drbd0 primary –o ,也可以在要设置为Primary的节点上使用如下命令来设置主节点: drbdadm -- --overwrite-data-of-peer primary web
(9).将node1设置为主节点
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@node1 ~] # drbd-overview #node1为主节点
0:web /0 SyncSource Primary /Secondary UpToDate /Inconsistent C r---n-
[>...................] sync 'ed: 5.1% (19440 /20476 )M
注:大家可以看到正在同步数据,得要一段时间
[root@node2 ~] # drbd-overview #node2为从节点
0:web /0 SyncTarget Secondary /Primary Inconsistent /UpToDate C r-----
[==>.................] sync 'ed: 17.0% (17016 /20476 )M
同步完成后,查看一下
[root@node1 ~] # drbd-overview
0:web /0 Connected Primary /Secondary UpToDate /UpToDate C r-----
[root@node2 ~] # drbd-overview
0:web /0 Connected Secondary /Primary UpToDate /UpToDate C r-----
|
(10).格式化并挂载
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
[root@node1 ~] # mke2fs -j /dev/drbd
drbd/ drbd1 drbd11 drbd13 drbd15 drbd3 drbd5 drbd7 drbd9
drbd0 drbd10 drbd12 drbd14 drbd2 drbd4 drbd6 drbd8
[root@node1 ~] # mke2fs -j /dev/drbd0
mke2fs 1.41.12 (17-May-2010)
文件系统标签=
操作系统:Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe blocks
1310720 inodes, 5242711 blocks
262135 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=4294967296
160 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
正在写入inode表: 完成
Creating journal (32768 blocks):
完成
Writing superblocks and filesystem accounting information: 完成
This filesystem will be automatically checked every 28 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@node1 ~] #
[root@node1 ~] # mkdir /drbd
[root@node1 ~] # mount /dev/drbd0 /drbd/
[root@node1 ~] # mount
/dev/sda2 on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw)
/dev/sda1 on /boot type ext4 (rw)
/dev/sda3 on /data type ext4 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
/dev/drbd0 on /drbd type ext3 (rw)
[root@node1 ~] # cd /drbd/
[root@node1 drbd] # cp /etc/inittab /drbd/
[root@node1 drbd] # ll
总用量 20
-rw-r--r-- 1 root root 884 8月 17 13:50 inittab
drwx------ 2 root root 16384 8月 17 13:49 lost+found
|
(11).切换Primary和Secondary节点
说明:对主Primary/Secondary模型的drbd服务来讲,在某个时刻只能有一个节点为Primary,因此,要切换两个节点的角色,只能在先将原有的Primary节点设置为Secondary后,才能原来的Secondary节点设置为Primary。
node1:
|
1
2
|
[root@node1 ~] # umount /drbd/
[root@node1 ~] # drbdadm secondary web
|
查看状态node1
|
1
2
3
4
|
[root@node1 ~] # drbd-overview
0:web /0 Connected Secondary /Secondary UpToDate /UpToDate C r-----
node2:
[root@node2 ~] # drbdadm primary web
|
查看状态node2
|
1
2
3
4
|
[root@node2 ~] # drbd-overview
0:web /0 Connected Primary /Secondary UpToDate /UpToDate C r-----
[root@node2 ~] # mkdir /drbd
[root@node2 ~] # mount /dev/drbd0 /drbd/
|
使用下面的命令查看在此前在主节点上复制至此设备的文件是否存在
|
1
2
3
4
|
[root@node2 ~] # ll /drbd/
总用量 20
-rw-r--r-- 1 root root 884 8月 17 13:50 inittab
drwx------ 2 root root 16384 8月 17 13:49 lost+found
|
十三、DRBD 双主模式配置示例
drbd 8.4中第一次设置某节点成为主节点的命令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
[root@node ~] # drbdadm primary --force resource
配置资源双主模型的示例:
resource mydrbd {
net {
protocol C;
allow-two-primaries yes ;
}
startup {
become-primary-on both;
}
disk {
fencing resource-and-stonith;
}
handlers {
# Make sure the other node is confirmed
# dead after this!
outdate-peer "/sbin/kill-other-node.sh" ;
}
on node1.magedu.com {
device /dev/drbd0 ;
disk /dev/vg0/mydrbd ;
address 172.16.200.11:7789;
meta-disk internal;
}
on node2.magedu.com {
device /dev/drbd0 ;
disk /dev/vg0/mydrbd ;
address 172.16.200.12:7789;
meta-disk internal;
}
}
|
注:大家可以根据需要配置主/从模式或双主模式,好了今天的博文就到这边,在下一篇博文中我们将为大家演示Corosync+Pacemaker+DRBD+Mysql实现高可用的Mysql集群。^_^……
Linux 高可用(HA)集群之DRBD详解相关推荐
- corosync+pacemaker实现高可用(HA)集群(二)
部署方案二(推荐):corosync+pacemaker 利用ansible自动安装corosync和pacemaker 注:关于ansible的具体使用可参见"ansible实现自动化自动 ...
- 高可用(HA)集群原理概述
一.高可用集群(High Availability Cluster) 集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源.每一个单个的计算机系统都叫集群节点(node).随着 ...
- mysql keepalived主主同步_KEEPALIVED+MYSQL主主同步=MYSQL高可用(HA)集群
1.这个环境最大的缺陷在于主机写入速度极慢,主键重复. 2.mysql最好采用5.6以上集群版本,5.5以下单线程版本不大适合.博客中的mysql为5.5,实际测试挺差的,换成5.6之后十分完美,请各 ...
- Redis Cluster高可用(HA)集群环境搭建详细步骤
1.为什么要有集群 由于Redis主从复制架构每个数据库都要保存整个集群中的所有数据,容易形成木桶效应,所以Redis3.0之后的版本添加特性就是集群(Cluster) 2.Redis集群架构说明 架 ...
- Hadoop分布式高可用HA集群搭建笔记(含Hive之构建),java高级架构师视频
| HOSTNAME | IP | 操作系统 | | - | - | - | | masterndoe | 192.168.122.128 | Manjaro 20.1 | | slavenode1 ...
- Hadoop分布式高可用HA集群搭建笔记(含Hive之构建),java类加载过程面试题
[]( )1.2.4 修改主机名 修改三台机器的/etc/hosts文件 加入如下内容.为了等下能在物理主机上访问HDFS web管理工具.还需要在本地进行该映射.不过在Windows下,要修改的是C ...
- Ceph RGW高可用HA集群keepalived+Haproxy
部署了入口服务的主机有 N 个.每个主机都有一个 haproxy 守护进程和一个 keepalived 守护进程.一次仅在其中一台主机上自动配置虚拟 IP. 每个keepalived 守护进程每隔几秒 ...
- Hadoop HA集群部署 - A - 详解
理论简介: HA 概念以及作用 HA(High Available), 高可用性群集,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点.通常把正在执行业务 ...
- Linux 高可用(HA)集群之Pacemaker详解
大纲 说明:本来我不想写这篇博文的,因为前几篇博文都有介绍pacemaker,但是我觉得还是得写一下,试想应该会有博友需要,特别是pacemaker 1.1.8(CentOS 6.4)以后,pacem ...
最新文章
- [转载] 七龙珠第一部——第004话 掳人的妖怪——乌龙
- RSA加密算法破解及原理
- React + TypeScript:元素引用的传递
- 根据测试路径自动生成测试用例_自拍教程75Python 根据测试用例选择测试资源
- Bind view的master与slave部署与测试
- Android中BroadCast与Activity之间的通信
- 流浪的python博客园_python学习心得第一章
- 求f(x,n)(信息学奥赛一本通-T1166)
- 如何快速搭建yum源和成功检测第三方软件
- 关于java中判断字符串相等==和equal 详解
- RedisTemplate和StringRedisTemplate的区别
- 借助JavaEE中Timer API实现定时关闭计算机的功能
- win10背景显示计算机名,如何自定义Win10计算机的开始菜单背景和图片
- 计算机应用水平测试excel,职称计算机考试Excel操作题及答案
- 关于GetTickCount函数的用法
- Flash 3D引擎比较
- 如何从道客巴巴上下载收费文档之我见
- 达芬奇剪辑调色专用键盘DaVinci Resolve Speed Editor
- 10分钟教你如何在win10上操作win10上的虚拟机中的docker容器,保证学会
- 已知随机变量X的协方差矩阵求去X的特征值 特征向量 PCA投影矩阵