word2vec 笔记
word2vec 是 Google 于 2013年开源的一个用于获取词向量的工具包,作者是 Tomas Mikolov,不过现在他已经从 Google Brain 跳槽到了 Facebook Research,后来还参与了 fasttext 项目的研究。下面是我读博客 word2vec 中的数学原理 的一些笔记和总结。
Language Model (语言模型)
统计语言模型(statistical language model)是自然语言处理里比较常见的一个概念,是建立在一段序列(比如一句话)上联合概率分布。比如 “我/特别/喜欢/跑步”这句话(’/’符号表示分词,假设我们序列的基本单位是词语),其概率可以分解(factorize)成
观察一下条件概率就可以发现,如果尝试对上面的每个概率建立概率分布,词表的大小将会非常大,要拟合的参数也非常大。因此上面只是理论分析,并不是实用,我们可以考虑一些近似的计算。考虑做 N-1 阶马尔可夫假设,即第 N 个词的概率,只依赖于其前面 N-1 个词的概率。这样就得到了 N-gram 模型。写成链式法则(chain rule)就是
如 N=2 时,叫做 bigram 模型,每个词出现的概率只和前一个词有关,那么例子里的公式退化成,
如果词汇表的大小是 |V|
,那么 bigram 要学习的参数就是 p(wi|wj)
,共 |V|2
个。具体训练的做法就是,抽取一句话中的单词 w
和其对应的上下文 Context(w)
,最大化对数似然函数(log-likelihood function),即最大化概率 p(w|Context(w))
.
当然,除了 N-gram 模型,还有其他方法来做 language model,比如 Recurrent Neural Network Language Model 这篇论文。没错,作者也是 Tomas Mikolov,这个是他做 word2vec 之前的工作。
Word Vector (词向量)
词向量的概念由 Bengio 在 2003 年的经典论文《A Neural Probabilistic Language Model》提出。他尝试用神经网络来学一个语言模型。在表示一个词的时候,如果用词典的序号表示,词与词之间的距离是序号之差,这样很没道理;如果用 one-hot 编码,可以保证每个词语之间的距离都是相等的,每个词语的维度都是词典的大小。
但是这篇论文则首次尝试了词嵌入(word embedding)的工作,即用更小的维度来表示一个词语,每个词都是这个连续的空间的一个稠密(dense)向量,这样可以表达更丰富的语义。这种用低维向量表示词的方法叫做词向量的分布式表示(Distributed Representation),因为词的语义被分散地存储在了向量的各个维度中(像分布式系统一样),每个维度都包含部分语义信息。不同词之间的相似度,可以用余弦距离来计算。
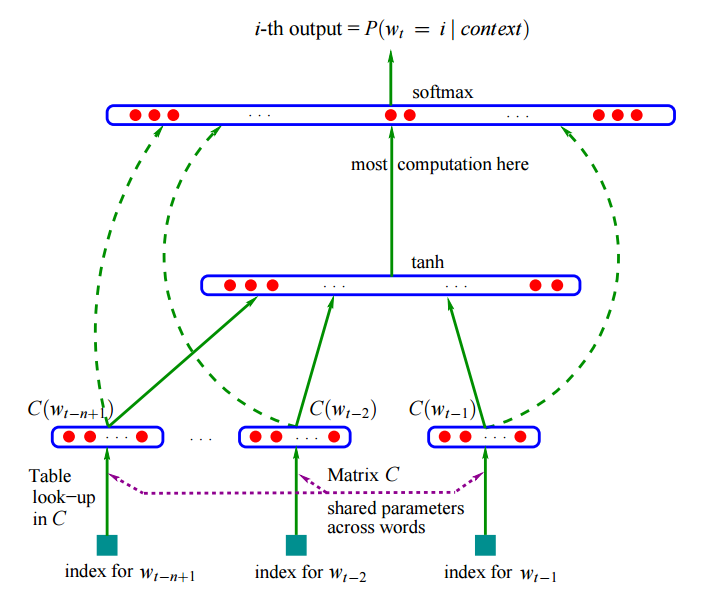
论文里的模型(见下图)也很简单,词嵌入使用一个矩阵 C 来表示,大小是词表大小乘以嵌入的维度,而前 n-1 个词在 C 中找到对应的词向量后,直接拼接到一起经过一个隐层神经元,再经过 Softmax 即可得到预测词的概率分布。模型的公式如下,
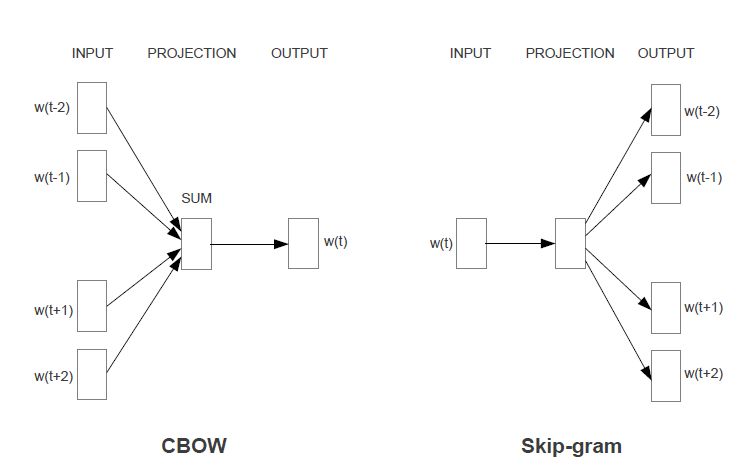
CBOW 和 Skip-gram 模型
我们设置一个大小为 t 的窗口,在语料库里随机抽取一个词 wt
,这个核心词的前 c
个和后 c
个单词构成该词的上下文,即
在 word2vec 的第一篇论文《Efficient Estimation of Word Representations in Vector Space, 2013a》中,设计了两个模型来训练词向量,分别是 CBOW(Continuous Bag-of-Words)和 Skip-gram 模型。下图是取窗口大小 c = 2 的例子,
- CBOW 模型
- 最大化概率 p(w|context(w))
,用 context(w) 去预测 w
- 最大化概率 p(w|context(w))
- Skip-gram 模型
- 最大化概率 p(context(w)|w)
,用 w 去预测 context(w)
- 最大化概率 p(context(w)|w)
然而这篇论文里没有提到模型具体是怎么构建的,但是在第二篇论文《Distributed Representation of Words and Phrases and their Compositionality, 2013c》中,本来是要讲层次 Softmax 和负采样,顺便提了一下 Skip-gram 模型的公式。
Skip-gram 模型是尝试用 wt
预测 context(w)
,具体是最大化“均值对数似然概率”,
而两个词之间的 skip-gram 概率 p(wt+j|wt)
可以这样定义,
分子是把 w
对应的词向量和 context(w)
里的某个词对应的词向量做内积,分母是把 w
对应的词向量和词汇表中的所有词向量做内积。最后得到的结果要经过一个 Softmax,得到真正的概率。
由此可见,这两个模型的原始做法都是做内积,经过 Softmax 后得到概率,因此复杂度很高。【此处该有复杂度分析】所以才有了 2013c 中的两种改进方法,即层次 Softmax 和负采样。
Hierarchical Softmax
上面的 Softmax 每次和全部的词向量做内积,复杂度是 O(V)
, V
是词典大小。如果考虑把每个词都放到哈夫曼树的叶节点上,那么复杂度就可以降为 O(logV)
,即树的高度,因为只需要预测从根节点到相应叶节点的路径即可。哈夫曼树的构造,是根据词的词频,逐渐把小的两个词频合并,从底向上知道合并只剩根节点这样子逐渐构建,然后往右子树的分叉都编号 0,左边都编号 1 得到。最后词频较大的,离根节点也会近,相应的哈夫曼编码也会很短。
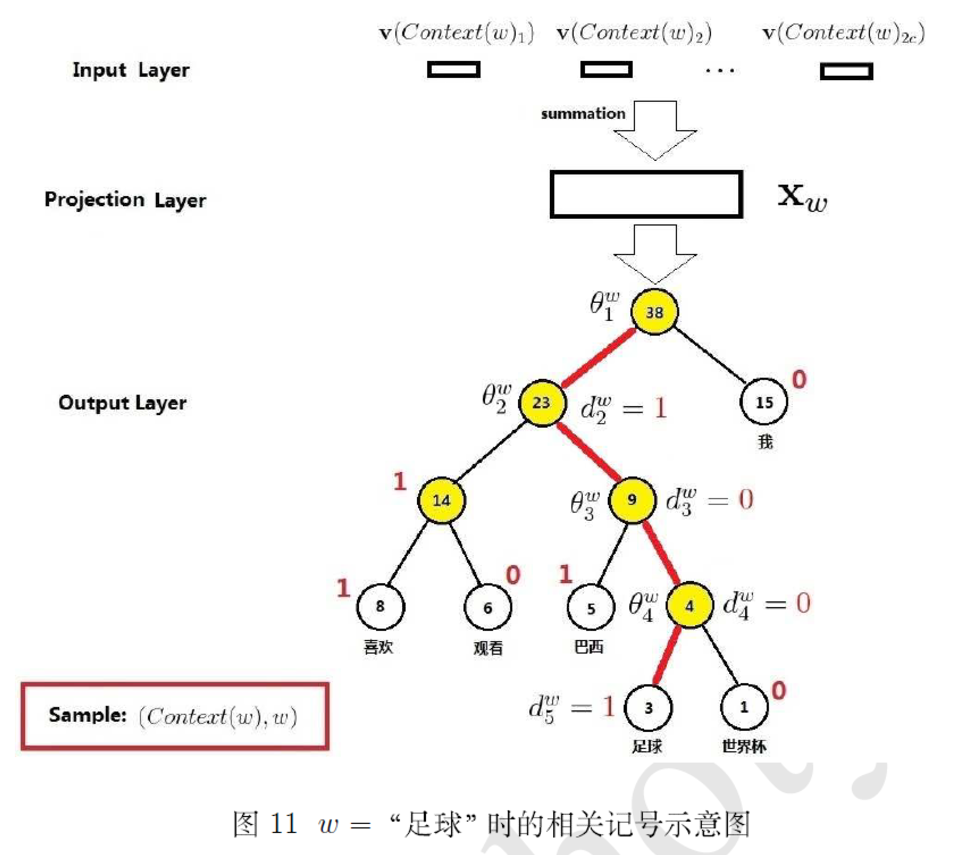
如上图所示,是 CBOW + Hierarchical Softmax 组合的模型,如果是要预测这个词,那么要沿着路径(图中红色的线) (root,dw2,dw3,dw4,dw5)=(root,1,0,0,1)
一直走到目标叶节点。优化目标就是让每个非叶节点去预测要选择的路径,即让 σ(w⋅θwi)
趋近 dwi+1
的值。总体的目标函数就是,
其中 xw
是 context(w)
里所有词向量叠加后都得到的值, l(w)
是从根节点到 w
的路径的,θ
是路径上的参数,维度和词向量维度一样。 p(⋅)
是当前参数预测的节点走向(0或者1,左子树还是右子树)的概率,计算如下,
哈夫曼树有个性质,叶节点的数量正好比非叶子结点多一个。这里的叶子节点个数就是词典大小,非叶子结点是 Hierarchical Softmax 的训练参数 θ
,因此这里的参数不能当做是词向量。词向量要用前面那套,即图里的 v
.
Negative Sampling (负采样)
基于负采样的训练方法感觉有点暴力,相当于是直接用多个二分类来做多分类问题。比如 CBOW + Negative Sampling 的模型,是用 xw
预测 w
,直接让 σ(xw⋅w)
预测 1,随机采几个词作为负例 u∈NEG(w)
,让 σ(xw⋅u)
预测 0,写成目标函数就是,
直接最大化该目标函数即可。
Skip-gram + Negative Sampling 的过程也类似,就不阐述了。
常见面试问题
问题 1,介绍一下 word2vec
- word2vec 的两个模型分别是 CBOW 和 Skip-gram,两个加快训练的 Loss 是 HS(Hierarchical Softmax )和负采样。
- 假设一个训练样本是又核心词 w
和其上下文 context(w)
组成,那么 CBOW 就是用 context(w)
去预测 w
;而 Skip-gram 则反过来,是用 w
去预测 context(w)
里的所有词。 - HS 是试图用词频建立一棵哈夫曼树,那么经常出现的词路径会比较短。树的叶子节点表示词,共词典大小多个,而非叶子结点是模型的参数,比词典个数少一个。要预测的词,转化成预测从根节点到该词所在叶子节点的路径,是多个二分类问题。
- 对于负采样,则是把原来的 Softmax 多分类问题,直接转化成一个正例和多个负例的二分类问题。让正例预测 1,负例预测 0,这样子更新局部的参数。
问题 2,对比 Skip-gram 和 CBOW
- 训练速度上 CBOW 应该会更快一点,因为每次会更新 context(w)
的词向量,而 Skip-gram 只更新核心词的词向量。 - Skip-gram 对低频词效果比 CBOW,因为是尝试用当前词去预测上下文,当前词是低频词还是高频词没有区别。但是 CBOW 相当于是完形填空,会选择最常见或者说概率最大的词来补全,因此不太会选择低频词。
- Skip-gram 在大一点的数据集可以提取更多的信息。总体比 CBOW 要好一些。
问题 3,对比 HS 和 负采样
- 负采样更快一些,特别是词表很大的时候。
问题 4,负采样为什么要用词频来做采样概率?
- 因为这样可以让频率高的词先学习,然后带动其他词的学习。
问题 5,为什么训练完有两套词向量,为什么一般只用前一套?
- 对于 Hierarchical Softmax 来说,哈夫曼树中的参数是不能拿来做词向量的,因为没办法和词典里的词对应。负采样中的参数其实可以考虑做词向量,因为中间是和前一套词向量做内积,应该也是有意义的。但是考虑负样本采样是根据词频来的,可能有些词会采不到,也就学的不好。
问题 6,对比字向量和词向量
- 字向量其实可以解决一些问题,比如未登陆词,还有做一些任务的时候还可以避免分词带来的误差。
- 而词向量它的语义空间更大,更加丰富,语料足够的情况下,词向量是能够学到更多的语义的。
参考资料
- 训练文本
- 中文语料
- 百度百科
- 维基百科
- 搜狗实验室的新闻数据
- 英文语料
- GoogleNews Pretrained Model
- Where to obtain the training data
- 中文语料
- 模型工具
- Google 开源的 wordvec
- gensim word2vec
- 是对上面的 Google C++ 版本的 python 接口封装
博客参考
- 中英文维基百科语料上的Word2Vec实验
- gensim, word2vec tutorial
- word2vec 中的数学原理 (重点推荐)
- tensorflow word2vec tutorial
论文
- Efficient Estimation of Word Representations in Vector Space, 2013a
- Exploiting Similarities among Language for Machine Translation, 2013b
- Distributed Representation of Words and Phrases and their Compositionality, 2013c
- Distributed Representations of Sentences and Documents, 2014
word2vec 笔记相关推荐
- 深度学习word2vec笔记之算法篇
本文转载自<深度学习word2vec笔记之算法篇>对排版和内容作了部分调整,感谢大佬分享. PDF版本关注微信公众号:[终南樵],回复:[word2vec基础]获取 1. 声明 该博文是G ...
- 深度学习word2vec笔记之基础篇
深度学习word2vec笔记之基础篇 声明: 1)该博文是多位博主以及多位文档资料的主人所无私奉献的论文资料整理的.具体引用的资料请看参考文献.具体的版本声明也参考原文献 2)本文仅供学术交流,非商用 ...
- 深度学习word2vec笔记之应用篇
深度学习word2vec笔记之应用篇 声明: 1)该博文是Google专家以及多位博主所无私奉献的论文资料整理的.具体引用的资料请看参考文献.具体的版本声明也参考原文献 2)本文仅供学术交流,非商用. ...
- 深度学习word2vec笔记
基础篇 算法篇 应用篇 深度学习word2vec笔记之基础篇 一.前言 伴随着深度学习的大红大紫,只要是在自己的成果里打上deep learning字样,总会有人去看.深度学习可以称为当今机器学习领域 ...
- Word2Vec笔记
单词嵌入是文档词汇表最流行的表示形式之一. 它能够捕获文档中单词的上下文,语义和句法相似性,与其他单词的关系等. 词嵌入到底是什么? 松散地说,它们是特定单词的向量表示. 话虽如此,接下来是如何生成它 ...
- 自然那语言处理之深度学习word2vec笔记之应用篇
好不容易学了一个深度学习的算法,大家是否比较爽了?但是回头想想,学这个是为了什么?吹牛皮吗?写论文吗?参加竞赛拿奖吗? 不管哪个原因,都显得有点校园思维了. 站在企业的层面,这样的方式显然是不符合要求 ...
- BERT通俗笔记:从Word2Vec/Transformer逐步理解到BERT
前言 我在写上一篇博客<22下半年>时,有读者在文章下面评论道:"july大神,请问BERT的通俗理解还做吗?",我当时给他发了张俊林老师的BERT文章,所以没太在意. ...
- 秒懂词向量Word2vec的本质
[NLP] 秒懂词向量Word2vec的本质 穆文 4 个月前 转自我的公众号: 『数据挖掘机养成记』 1. 引子 大家好 我叫数据挖掘机 皇家布鲁斯特大学肄业 我喝最烈的果粒橙,钻最深的牛角尖 -- ...
- Word2vec 讨论
我没有在自然语言处理完成.但基于Deep Learning 关注,自然知道一些Word2vec强大. Word2vec 是google 在2013年提供的一款将词表征为实数值向量的高效工具.而Word ...
最新文章
- A02 创建实验环境快照
- .c和.cpp的区别
- java命令修改user.home file.encoding等参数值
- 1.1 sikuli 安装
- 【安全】Apache HDFS 上配置 kerberos
- 几种无线通讯介绍与比较(蓝牙,WiFi,IrDA,NFC,Zigbee,UWB)
- 方差公式初三_初中数学,一元二次方程的解法:公式法、因式分解法和十字相乘法基础练习...
- 2021 年百度之星·程序设计大赛 - 初赛二 1002 随机题意(区间贪心)
- FatMouse’ Trade
- Python爬虫实践(二) -- 爬虫进阶:爬取数据处理、数据库存储
- 麒麟系统下安装win10_win10系统安装图文详细教程
- 泛微协同办公平台E-cology9.0版本最全帮助文档
- 使用dd命令测试裸盘性能评测
- Mysql 中英文排序
- PTA 天梯赛 L1-7 天梯赛的善良 (20 分)
- 区块链熊市交易量不减,市场为何需要OKEx合约交易?
- 江湖中传说珊瑚虫--到底应该抓谁?
- 站群网站批量文章翻译发布插件
- 花生壳动态动态域名解析路由器解析语法
- 基于STM32单片机和RFID的智能考勤系统设计