论文复现:Focal modulation networks
复现论文Focal Modulation Networks(自注意力会被取代?)
该论文提出了一个focal modulation network(FocalNet)使用焦点调制(focal modulation)模块来取代自注意力(SA :self-attention)。作者认为在Transformers中,自注意力可以说是其成功的关键,它支持依赖于输入的全局交互,但尽管有这些优势,由于自注意力二次的计算复杂度效率较低,尤其是对于高分辨率输入。

1 FocalNet论文解读
1.1 参考资料
- 【论文地址】https://arxiv.org/abs/2203.11926
- 【论文源码】https://github.com/microsoft/FocalNet
1.2 论文解读
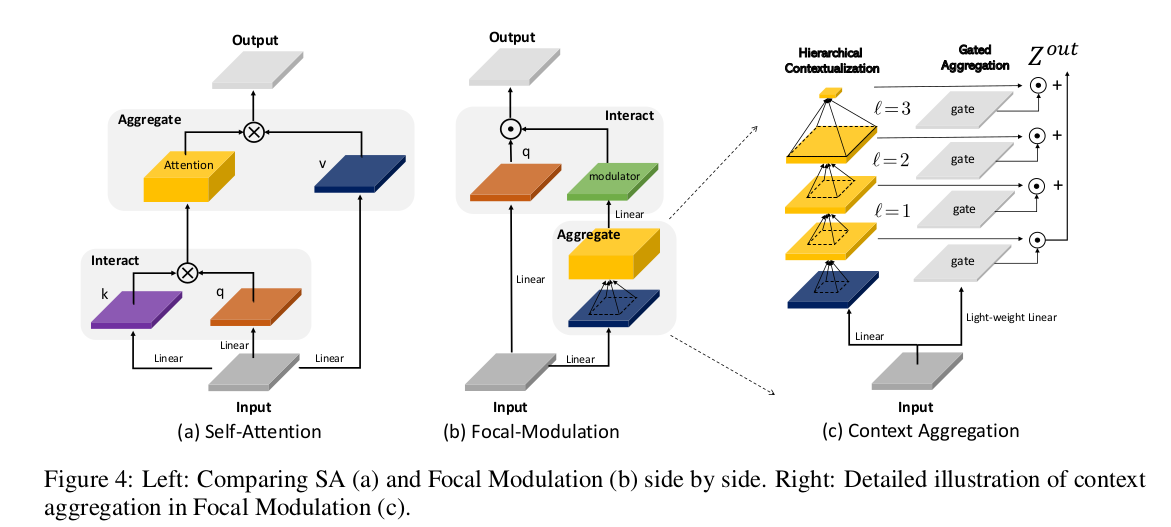
(1)调制或元素级仿射变换,将聚合的特征融合到query中。
自注意力(SA)的计算采用一种先交互后聚合的过程,其公式如下:
y i = M 1 ( T 1 ( x i , X ) , X ) \mathcal{y}_i=\mathcal{M}_1\left(\mathcal{T}_1\left(\boldsymbol{x}_i, \mathbf{X}\right), \mathbf{X}\right) yi=M1(T1(xi,X),X)
论文提出先聚合特征,然后将查询与聚合特征交互以融合上下文信息,公式如下:
y i = T 2 ( M 2 ( x i , X ) , x i ) \mathcal{y}_i=\mathcal{T}_2\left(\mathcal{M}_2\left(\boldsymbol{x}_i, \mathbf{X}\right), \mathcal{x}_i\right) yi=T2(M2(xi,X),xi)
其中 M \mathcal{M} M 表示聚合过程, T \mathcal{T} T表示交互过程。
将两式进行比较可以发现,在的聚合过程 M 2 \mathcal{M_2} M2中,通过共享操作符(例如,深度卷积)减少上下文计算,而SA中的 M 1 \mathcal{M_1} M1计算成本更高,因为它需要对不同查询的不可共享注意力分数求和;交互 T 2 \mathcal{T_2} T2是token与其上下文之间的轻量级操作符,而 T 1 \mathcal{T_1} T1涉及计算token与token的注意力分数,这具有二次复杂性。
论文中定义的焦点调制公式如下:
y i = q ( x i ) ⊙ M 2 ( x i , X ) \mathcal{y}_i=q\left(\mathcal{x}_i\right) \odot \mathcal{M}_2\left(\mathcal{x}_i, \mathbf{X}\right) yi=q(xi)⊙M2(xi,X)
即交互操作符 T 2 \mathcal{T_2} T2仅使用简单的 q ( ⋅ ) q(\cdot) q(⋅)和 ⊙ \odot ⊙, 其中 q ( ⋅ ) q(\cdot) q(⋅)是一个查询映射函数, ⊙ \odot ⊙是按元素的乘法运算符。
(2)分层语义,以在不同粒度级别从局部到全局范围提取上下文信息。
给定输入特征映射X,我们首先将其投影到一个新的特征空间中,该空间具有一个线性层 Z 0 = f z ( X ) ∈ R H × W × C \mathbf{Z}^0=f_z(\mathbf{X}) \in \mathbb{R}^{H \times W \times C} Z0=fz(X)∈RH×W×C。然后 使用L个depth-wise卷积获得上下文的层次表示,输出 Z ℓ \mathbf{Z^{\ell}} Zℓ表示为:
Z ℓ = f a ℓ ( Z ℓ − 1 ) ≜ G e L U ( C o n v d w ( Z ℓ − 1 ) ) \mathbf{Z}^{\ell}=f_a^{\ell}\left(\mathbf{Z}^{\ell-1}\right) \triangleq \mathbf{GeLU}\left(\mathbf{Conv}_{d w}\left(\mathbf{Z}^{\ell-1}\right)\right) Zℓ=faℓ(Zℓ−1)≜GeLU(Convdw(Zℓ−1))
应用depth-wise卷积进行分层语义是因为作者认为与池化(pooling)相比,depth-wise卷积是可学习的,并且具有结构感知能力。与常规卷积相比,它具有通道特性,因此计算成本更低。
层次语境化生成 L级特征图,在第 ℓ \mathbf{\ell} ℓ 级,有效感受野的大小为 r ℓ = 1 + ∑ i = 1 ℓ ( k ℓ − 1 ) r^{\ell}=1+\sum_{i=1}^{\ell}\left(k^{\ell}-1\right) rℓ=1+∑i=1ℓ(kℓ−1),远大于卷积核大小 k ℓ k^{\ell} kℓ。更大的感受野以更粗的粒度捕获更多的全局上下文。为了捕获整个输入的全局上下文,作者在第L级特征映射上应用全局平均池化。由此获得总的(L+1)特征图 ,它们在不同的粒度级别上共同捕获局部和长距离上下文。
(3)门控聚合
通过门控聚合将不同粒度级别的上下文特征浓缩为单个特征向量,即调制器(modulator)。具体来说,使用线性层来获得空间和级别感知的权重 G = f g ( X ) ∈ R H × W × ( L + 1 ) \mathbf{G}=f_{g}(\mathbf{X})\in\mathbb{R}^{H\times W\times(L+1)} G=fg(X)∈RH×W×(L+1),然后,通过元素相乘执行加权和,以获得与输入 X 大小相同的单个特征映射 Z o u t \mathbf{Z^{out}} Zout。
Z o u t = ∑ ℓ = 1 L + 1 G ℓ ⊙ Z ℓ \mathbf{Z}^{\mathrm{out}}~=\sum_{\ell=1}^{L+1}\mathbf{G}^{\ell}\odot\mathbf{Z}^{\ell} Zout=ℓ=1∑L+1Gℓ⊙Zℓ
其中, G ℓ ∈ R H × W × 1 \mathbf{G}^{\ell}\in\mathbb{R}^{H\times W\times1} Gℓ∈RH×W×1 是第 ℓ {\ell} ℓ 级的一个通道。到目前为止,所有聚合都是空间聚合。为了建模不同通道之间的关系,使用了另一个线性层 h ( ⋅ ) h(\cdot) h(⋅) 获得调制器 M = h ( Z o u t ) ∈ R H × W × C \mathbf{M}=h\left(\mathbf{Z}^{\mathrm{out}}\right)\in\mathbb{R}^{H\times W\times C} M=h(Zout)∈RH×W×C。
结合交互和聚合的公式,整体的焦点调制公式可表示为:
y i = q ( x i ) ⊙ h ( ∑ ℓ = 1 L + 1 g i ℓ ⋅ z i ℓ ) y_{i}=q\left(x_{i}\right)\odot h\left(\sum_{\ell=1}^{L+1}g_{i}^{\ell}\cdot z_{i}^{\ell}\right) yi=q(xi)⊙h(ℓ=1∑L+1giℓ⋅ziℓ)
2 复现思路
首先通过阅读论文和查阅相关资料去理解提出的模型和相关公式,然后在本地跑通论文的pytorch代码进一步了解论文的具体实现步骤,然后通过查阅pytorch和paddle的相关API转换为Paddle模型,再还将pytorch预训练模型的权重提取出来保存为Paddle格式,这样就可以通过PaddleDetection和PaddleClas去验证转换后的模型,将复现后的代码进行校验和对齐。
然后参考【PyTorch 1.8 与 Paddle 2.0 API映射表】按层次将Pytorch代码改为PaddlePaddle代码。
论文中在目标检测、图像分类和图像分割都有基准,本次仅复现图像分类。
3 代码复现
3.1 环境检查
import paddle
print(paddle.__version__)
print(paddle.version.cuda())
print(paddle.version.cudnn())
paddle.utils.run_check()
2.3.2
11.2
8.1.1
Running verify PaddlePaddle program ... W1214 20:29:54.098194 182 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1214 20:29:54.102201 182 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.PaddlePaddle works well on 1 GPU.
PaddlePaddle works well on 1 GPUs.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
3.2 FocalNet
开始组网
# transformer 网络常用的函数
import paddle
import paddle.nn as nnfrom paddle.nn.initializer import TruncatedNormal, Constant, Assign
import warnings
warnings.filterwarnings('ignore')# Common initializations
ones_ = Constant(value=1.)
zeros_ = Constant(value=0.)
trunc_normal_ = TruncatedNormal(std=.02)# Common Layers
def drop_path(x, drop_prob=0., training=False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ..."""if drop_prob == 0. or not training:return xkeep_prob = paddle.to_tensor(1 - drop_prob)shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)random_tensor = paddle.floor(random_tensor) # binarizeoutput = x.divide(keep_prob) * random_tensorreturn outputclass DropPath(nn.Layer):def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class Identity(nn.Layer):def __init__(self):super(Identity, self).__init__()def forward(self, input):return input# common funcs
def to_2tuple(x):if isinstance(x, (list, tuple)):return xreturn tuple([x] * 2)def add_parameter(layer, datas, name=None):parameter = layer.create_parameter(shape=(datas.shape), default_initializer=Assign(datas))if name:layer.add_parameter(name, parameter)return parameter# 模型组网
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.vision import transforms# 多层感知机
class Mlp(nn.Layer):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x# 调制器
class FocalModulation(nn.Layer):def __init__(self, dim, focal_window, focal_level, focal_factor=2, bias=True, proj_drop=0.,use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.focal_window = focal_windowself.focal_level = focal_levelself.focal_factor = focal_factorself.use_postln_in_modulation = use_postln_in_modulationself.normalize_modulator = normalize_modulatorself.f = nn.Linear(dim, 2 * dim + (self.focal_level + 1), bias_attr=bias)self.h = nn.Conv2D(dim, dim, kernel_size=1, stride=1, bias_attr=bias)self.act = nn.GELU()self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.focal_layers = nn.LayerList()self.kernel_sizes = []for k in range(self.focal_level):kernel_size = self.focal_factor * k + self.focal_windowself.focal_layers.append(nn.Sequential(nn.Conv2D(dim, dim, kernel_size=kernel_size, stride=1,groups=dim, padding=kernel_size // 2, bias_attr=False),nn.GELU(),))self.kernel_sizes.append(kernel_size)if self.use_postln_in_modulation:self.ln = nn.LayerNorm(dim)def forward(self, x):"""Args:x: input features with shape of (B, H, W, C)"""C = x.shape[-1]# pre linear projection# x = self.f(x).permute(0, 3, 1, 2).contiguous()x = self.f(x).transpose([0, 3, 1, 2])q, ctx, self.gates = paddle.split(x, (C, C, self.focal_level + 1), 1)# context aggreationctx_all = 0for l in range(self.focal_level):ctx = self.focal_layers[l](ctx)ctx_all = ctx_all + ctx * self.gates[:, l:l + 1]ctx_global = self.act(ctx.mean(2, keepdim=True).mean(3, keepdim=True))ctx_all = ctx_all + ctx_global * self.gates[:, self.focal_level:]# normalize contextif self.normalize_modulator:ctx_all = ctx_all / (self.focal_level + 1)# focal modulationself.modulator = self.h(ctx_all)x_out = q * self.modulator# x_out = x_out.permute(0, 2, 3, 1).contiguous()x_out = x_out.transpose([0, 2, 3, 1])if self.use_postln_in_modulation:x_out = self.ln(x_out)# post linear porjectionx_out = self.proj(x_out)x_out = self.proj_drop(x_out)return x_outdef extra_repr(self) -> str:return f'dim={self.dim}'def flops(self, N):# calculate flops for 1 window with token length of Nflops = 0flops += N * self.dim * (self.dim * 2 + (self.focal_level + 1))# focal convolutionfor k in range(self.focal_level):flops += N * (self.kernel_sizes[k] ** 2 + 1) * self.dim# global gatingflops += N * 1 * self.dim# self.linearflops += N * self.dim * (self.dim + 1)# x = self.proj(x)flops += N * self.dim * self.dimreturn flopsclass FocalNetBlock(nn.Layer):r""" Focal Modulation Network Block.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resulotion.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.drop (float, optional): Dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormfocal_level (int): Number of focal levels.focal_window (int): Focal window size at first focal leveluse_layerscale (bool): Whether use layerscalelayerscale_value (float): Initial layerscale valueuse_postln (bool): Whether use layernorm after modulation"""def __init__(self, dim, input_resolution, mlp_ratio=4., drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm,focal_level=1, focal_window=3,use_layerscale=False, layerscale_value=1e-4,use_postln=False, use_postln_in_modulation=False,normalize_modulator=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.mlp_ratio = mlp_ratioself.focal_window = focal_windowself.focal_level = focal_levelself.use_postln = use_postlnself.norm1 = norm_layer(dim)self.modulation = FocalModulation(dim, proj_drop=drop, focal_window=focal_window, focal_level=self.focal_level,use_postln_in_modulation=use_postln_in_modulation, normalize_modulator=normalize_modulator)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() #todoself.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)self.gamma_1 = 1.0self.gamma_2 = 1.0if use_layerscale: # self.gamma_1 = nn.ParameterList(layerscale_value * paddle.ones((dim)))# self.gamma_2 = nn.ParameterList(layerscale_value * paddle.ones((dim)))self.gamma_1 = paddle.create_parameter(shape=[dim], dtype='float32',default_initializer= nn.initializer.Constant(value=1.0 * layerscale_value))self.gamma_1 = paddle.create_parameter(shape=[dim], dtype='float32',default_initializer= nn.initializer.Constant(value=1.0 * layerscale_value))self.H = Noneself.W = Nonedef forward(self, x):H, W = self.H, self.WB, L, C = x.shapeshortcut = x# Focal Modulationx = x if self.use_postln else self.norm1(x)# x = x.view(B, H, W, C)# x = self.modulation(x).view(B, H * W, C)x = x.reshape([B, H, W, C])x = self.modulation(x).reshape([B, H * W, C])x = x if not self.use_postln else self.norm1(x)# FFNx = shortcut + self.drop_path(self.gamma_1 * x)x = x + self.drop_path(self.gamma_2 * (self.norm2(self.mlp(x)) if self.use_postln else self.mlp(self.norm2(x))))return xdef extra_repr(self) -> str:return f"dim={self.dim}, input_resolution={self.input_resolution}, " \f"mlp_ratio={self.mlp_ratio}"def flops(self):flops = 0H, W = self.input_resolution# norm1flops += self.dim * H * W# W-MSA/SW-MSAflops += self.modulation.flops(H * W)# mlpflops += 2 * H * W * self.dim * self.dim * self.mlp_ratio# norm2flops += self.dim * H * Wreturn flopsclass BasicLayer(nn.Layer):""" A basic Focal Transformer layer for one stage.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resolution.depth (int): Number of blocks.window_size (int): Local window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.focal_level (int): Number of focal levelsfocal_window (int): Focal window size at first focal leveluse_layerscale (bool): Whether use layerscalelayerscale_value (float): Initial layerscale valueuse_postln (bool): Whether use layernorm after modulation"""def __init__(self, dim, out_dim, input_resolution, depth,mlp_ratio=4., drop=0., drop_path=0., norm_layer=nn.LayerNorm,downsample=None, use_checkpoint=False,focal_level=1, focal_window=1,use_conv_embed=False,use_layerscale=False, layerscale_value=1e-4,use_postln=False,use_postln_in_modulation=False,normalize_modulator=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.depth = depthself.use_checkpoint = use_checkpoint# build blocksself.blocks = nn.LayerList([FocalNetBlock(dim=dim,input_resolution=input_resolution,mlp_ratio=mlp_ratio,drop=drop,drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer,focal_level=focal_level,focal_window=focal_window,use_layerscale=use_layerscale,layerscale_value=layerscale_value,use_postln=use_postln,use_postln_in_modulation=use_postln_in_modulation,normalize_modulator=normalize_modulator,)for i in range(depth)])if downsample is not None:self.downsample = downsample(img_size=input_resolution,patch_size=2,in_chans=dim,embed_dim=out_dim,use_conv_embed=use_conv_embed,norm_layer=norm_layer,is_stem=False)else:self.downsample = Nonedef forward(self, x, H, W):for blk in self.blocks:blk.H, blk.W = H, Wx = blk(x)if self.downsample is not None:#x = x.transpose(1, 2).reshape(x.shape[0], -1, H, W)x = x.transpose([0, 2, 1]).reshape([x.shape[0], -1, H, W]) #todox, Ho, Wo = self.downsample(x)else:Ho, Wo = H, Wreturn x, Ho, Wodef extra_repr(self) -> str:return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"def flops(self):flops = 0for blk in self.blocks:flops += blk.flops()if self.downsample is not None:flops += self.downsample.flops()return flopsclass PatchEmbed(nn.Layer):r""" Image to Patch EmbeddingArgs:img_size (int): Image size. Default: 224.patch_size (int): Patch token size. Default: 4.in_chans (int): Number of input image channels. Default: 3.embed_dim (int): Number of linear projection output channels. Default: 96.norm_layer (nn.Module, optional): Normalization layer. Default: None"""def __init__(self, img_size=(224, 224), patch_size=4, in_chans=3, embed_dim=96, use_conv_embed=False,norm_layer=None, is_stem=False):super().__init__()patch_size = to_2tuple(patch_size)patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]self.img_size = img_sizeself.patch_size = patch_sizeself.patches_resolution = patches_resolutionself.num_patches = patches_resolution[0] * patches_resolution[1]self.in_chans = in_chansself.embed_dim = embed_dimif use_conv_embed:# if we choose to use conv embedding, then we treat the stem and non-stem differentlyif is_stem:kernel_size = 7padding = 2stride = 4else:kernel_size = 3padding = 1stride = 2self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)else:self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = Nonedef forward(self, x):B, C, H, W = x.shapex = self.proj(x)H, W = x.shape[2:]# x = x.flatten(2).transpose([1, 2]) # B Ph*Pw Cx=paddle.transpose(x.flatten(2), perm=[0, 2, 1]) # B Ph*Pw Cif self.norm is not None:x = self.norm(x)return x, H, Wdef flops(self):Ho, Wo = self.patches_resolutionflops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])if self.norm is not None:flops += Ho * Wo * self.embed_dimreturn flopsclass FocalNet(nn.Layer):r""" Focal Modulation Networks (FocalNets)Args:img_size (int | tuple(int)): Input image size. Default 224patch_size (int | tuple(int)): Patch size. Default: 4in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000embed_dim (int): Patch embedding dimension. Default: 96depths (tuple(int)): Depth of each Focal Transformer layer.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4drop_rate (float): Dropout rate. Default: 0drop_path_rate (float): Stochastic depth rate. Default: 0.1norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.patch_norm (bool): If True, add normalization after patch embedding. Default: Trueuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: Falsefocal_levels (list): How many focal levels at all stages. Note that this excludes the finest-grain level. Default: [1, 1, 1, 1]focal_windows (list): The focal window size at all stages. Default: [7, 5, 3, 1]use_conv_embed (bool): Whether use convolutional embedding. We noted that using convolutional embedding usually improve the performance, but we do not use it by default. Default: Falseuse_layerscale (bool): Whether use layerscale proposed in CaiT. Default: Falselayerscale_value (float): Value for layer scale. Default: 1e-4use_postln (bool): Whether use layernorm after modulation (it helps stablize training of large models)"""def __init__(self,img_size=224,patch_size=4,in_chans=3,num_classes=1000,embed_dim=96,depths=[2, 2, 6, 2],mlp_ratio=4.,drop_rate=0.,drop_path_rate=0.1,norm_layer=nn.LayerNorm,patch_norm=True,use_checkpoint=False,focal_levels=[2, 2, 2, 2],focal_windows=[3, 3, 3, 3],use_conv_embed=False,use_layerscale=False,layerscale_value=1e-4,use_postln=False,use_postln_in_modulation=False,normalize_modulator=False,**kwargs):super().__init__()self.num_layers = len(depths)embed_dim = [embed_dim * (2 ** i) for i in range(self.num_layers)]self.num_classes = num_classesself.embed_dim = embed_dimself.patch_norm = patch_normself.num_features = embed_dim[-1]self.mlp_ratio = mlp_ratio# split image into patches using either non-overlapped embedding or overlapped embeddingself.patch_embed = PatchEmbed(img_size=to_2tuple(img_size),patch_size=patch_size,in_chans=in_chans,embed_dim=embed_dim[0],use_conv_embed=use_conv_embed,norm_layer=norm_layer if self.patch_norm else None,is_stem=True)num_patches = self.patch_embed.num_patchespatches_resolution = self.patch_embed.patches_resolutionself.patches_resolution = patches_resolutionself.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in paddle.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule# build layers# self.layers = nn.ModuleList()self.layers = nn.LayerList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=embed_dim[i_layer],out_dim=embed_dim[i_layer + 1] if (i_layer < self.num_layers - 1) else None,input_resolution=(patches_resolution[0] // (2 ** i_layer),patches_resolution[1] // (2 ** i_layer)),depth=depths[i_layer],mlp_ratio=self.mlp_ratio,drop=drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchEmbed if (i_layer < self.num_layers - 1) else None,focal_level=focal_levels[i_layer],focal_window=focal_windows[i_layer],use_conv_embed=use_conv_embed,use_checkpoint=use_checkpoint,use_layerscale=use_layerscale,layerscale_value=layerscale_value,use_postln=use_postln,use_postln_in_modulation=use_postln_in_modulation,normalize_modulator=normalize_modulator)self.layers.append(layer)self.norm = norm_layer(self.num_features)# self.avgpool = nn.AdaptiveAvgPool1d(1)self.avgpool = nn.AdaptiveAvgPool1D(1)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight)if isinstance(m, nn.Linear) and m.bias is not None:# nn.init.constant_(m.bias, 0)zeros_(m.bias)elif isinstance(m, nn.LayerNorm):# nn.init.constant_(m.bias, 0)# nn.init.constant_(m.weight, 1.0)zeros_(m.bias)ones_(m.weight)def forward_features(self, x):x, H, W = self.patch_embed(x)x = self.pos_drop(x)for layer in self.layers:x, H, W = layer(x, H, W)x = self.norm(x) # B L Cx = self.avgpool(x.transpose([0,2, 1])) # B C 1x = paddle.flatten(x, 1)return xdef forward(self, x):x = self.forward_features(x)x = self.head(x)return xdef flops(self):flops = 0flops += self.patch_embed.flops()for i, layer in enumerate(self.layers):flops += layer.flops()flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)flops += self.num_features * self.num_classesreturn flopsdef build_transforms(img_size, center_crop=False):t = []if center_crop:size = int((256 / 224) * img_size)t.append(transforms.Resize(size, interpolation=_pil_interp('bicubic')))t.append(transforms.CenterCrop(img_size))else:t.append(transforms.Resize(img_size, interpolation=_pil_interp('bicubic')))t.append(transforms.ToTensor())t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))return transforms.Compose(t)def build_transforms4display(img_size, center_crop=False):t = []if center_crop:size = int((256 / 224) * img_size)t.append(transforms.Resize(size, interpolation=_pil_interp('bicubic')))t.append(transforms.CenterCrop(img_size))else:t.append(transforms.Resize(img_size, interpolation=_pil_interp('bicubic')))t.append(transforms.ToTensor())return transforms.Compose(t)model_urls = {"focalnet_tiny_srf": "","focalnet_small_srf": "","focalnet_base_srf": "","focalnet_tiny_lrf": "","focalnet_small_lrf": "","focalnet_base_lrf": "",
}def focalnet_tiny_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_tiny_srf']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_small_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_small_srf']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_base_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, **kwargs)if pretrained:url = model_urls['focalnet_base_srf']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_tiny_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, focal_levels=[3, 3, 3, 3], **kwargs)if pretrained:url = model_urls['focalnet_tiny_lrf']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_small_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, focal_levels=[3, 3, 3, 3], **kwargs)if pretrained:url = model_urls['focalnet_small_lrf']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_base_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, focal_levels=[3, 3, 3, 3], **kwargs)if pretrained:url = model_urls['focalnet_base_lrf']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_tiny_iso_16(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=192, focal_levels=[3], focal_windows=[3], **kwargs)if pretrained:url = model_urls['focalnet_tiny_iso_16']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_small_iso_16(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=384, focal_levels=[3], focal_windows=[3], **kwargs)if pretrained:url = model_urls['focalnet_small_iso_16']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_base_iso_16(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=768, focal_levels=[3], focal_windows=[3],use_layerscale=True, use_postln=True, **kwargs)if pretrained:url = model_urls['focalnet_base_iso_16']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return model# FocalNet large+ models
def focalnet_large_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=192, focal_levels=[3, 3, 3, 3], **kwargs)if pretrained:url = model_urls['focalnet_large_fl3']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_large_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=192, focal_levels=[4, 4, 4, 4], **kwargs)if pretrained:url = model_urls['focalnet_large_fl4']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_xlarge_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=256, focal_levels=[3, 3, 3, 3], **kwargs)if pretrained:url = model_urls['focalnet_xlarge_fl3']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_xlarge_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=256, focal_levels=[4, 4, 4, 4], **kwargs)if pretrained:url = model_urls['focalnet_xlarge_fl4']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_huge_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=352, focal_levels=[3, 3, 3, 3], **kwargs)if pretrained:url = model_urls['focalnet_huge_fl3']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return modeldef focalnet_huge_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=352, focal_levels=[4, 4, 4, 4], **kwargs)if pretrained:url = model_urls['focalnet_huge_fl4']checkpoint = paddle.utils.download.get_weights_path_from_url(url)model.set_state_dict(checkpoint["model"])return model模型结构
# 打印模型汇总
img_size = 224
x = paddle.rand([16, 3, img_size, img_size])
model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, focal_levels=[2, 2, 2, 2]) # focal_tiny_srf
paddle.summary(model, input_size=(16, 3, 224, 224))
# model(x)flops = model.flops()
print(f"number of GFLOPs:{flops / 1e9}")n_parameters = sum(paddle.numel(p) for p in model.parameters())
print(f"number of params:{n_parameters}")
-------------------------------------------------------------------------------------------Layer (type) Input Shape Output Shape Param #
===========================================================================================Conv2D-1 [[16, 3, 224, 224]] [16, 96, 56, 56] 4,704 LayerNorm-1 [[16, 3136, 96]] [16, 3136, 96] 192 PatchEmbed-1 [[16, 3, 224, 224]] [[16, 3136, 96], [], []] 0 Dropout-1 [[16, 3136, 96]] [16, 3136, 96] 0 LayerNorm-2 [[16, 3136, 96]] [16, 3136, 96] 192 Linear-1 [[16, 56, 56, 96]] [16, 56, 56, 195] 18,915 Conv2D-3 [[16, 96, 56, 56]] [16, 96, 56, 56] 864 GELU-2 [[16, 96, 56, 56]] [16, 96, 56, 56] 0 Conv2D-4 [[16, 96, 56, 56]] [16, 96, 56, 56] 2,400 GELU-3 [[16, 96, 56, 56]] [16, 96, 56, 56] 0 GELU-1 [[16, 96, 1, 1]] [16, 96, 1, 1] 0 Conv2D-2 [[16, 96, 56, 56]] [16, 96, 56, 56] 9,312 Linear-2 [[16, 56, 56, 96]] [16, 56, 56, 96] 9,312 Dropout-2 [[16, 56, 56, 96]] [16, 56, 56, 96] 0 FocalModulation-1 [[16, 56, 56, 96]] [16, 56, 56, 96] 0 Identity-1 [[16, 3136, 96]] [16, 3136, 96] 0 LayerNorm-3 [[16, 3136, 96]] [16, 3136, 96] 192 Linear-3 [[16, 3136, 96]] [16, 3136, 384] 37,248 GELU-4 [[16, 3136, 384]] [16, 3136, 384] 0 Dropout-3 [[16, 3136, 96]] [16, 3136, 96] 0 Linear-4 [[16, 3136, 384]] [16, 3136, 96] 36,960 Mlp-1 [[16, 3136, 96]] [16, 3136, 96] 0 FocalNetBlock-1 [[16, 3136, 96]] [16, 3136, 96] 0 LayerNorm-4 [[16, 3136, 96]] [16, 3136, 96] 192 Linear-5 [[16, 56, 56, 96]] [16, 56, 56, 195] 18,915 Conv2D-6 [[16, 96, 56, 56]] [16, 96, 56, 56] 864 GELU-6 [[16, 96, 56, 56]] [16, 96, 56, 56] 0 Conv2D-7 [[16, 96, 56, 56]] [16, 96, 56, 56] 2,400 GELU-7 [[16, 96, 56, 56]] [16, 96, 56, 56] 0 GELU-5 [[16, 96, 1, 1]] [16, 96, 1, 1] 0 Conv2D-5 [[16, 96, 56, 56]] [16, 96, 56, 56] 9,312 Linear-6 [[16, 56, 56, 96]] [16, 56, 56, 96] 9,312 Dropout-4 [[16, 56, 56, 96]] [16, 56, 56, 96] 0 FocalModulation-2 [[16, 56, 56, 96]] [16, 56, 56, 96] 0 DropPath-1 [[16, 3136, 96]] [16, 3136, 96] 0 LayerNorm-5 [[16, 3136, 96]] [16, 3136, 96] 192 Linear-7 [[16, 3136, 96]] [16, 3136, 384] 37,248 GELU-8 [[16, 3136, 384]] [16, 3136, 384] 0 Dropout-5 [[16, 3136, 96]] [16, 3136, 96] 0 Linear-8 [[16, 3136, 384]] [16, 3136, 96] 36,960 Mlp-2 [[16, 3136, 96]] [16, 3136, 96] 0 FocalNetBlock-2 [[16, 3136, 96]] [16, 3136, 96] 0 Conv2D-8 [[16, 96, 56, 56]] [16, 192, 28, 28] 73,920 LayerNorm-6 [[16, 784, 192]] [16, 784, 192] 384 PatchEmbed-2 [[16, 96, 56, 56]] [[16, 784, 192], [], []] 0 BasicLayer-1 [[16, 3136, 96], None, None] [[16, 784, 192], [], []] 0 LayerNorm-7 [[16, 784, 192]] [16, 784, 192] 384 Linear-9 [[16, 28, 28, 192]] [16, 28, 28, 387] 74,691 Conv2D-10 [[16, 192, 28, 28]] [16, 192, 28, 28] 1,728 GELU-10 [[16, 192, 28, 28]] [16, 192, 28, 28] 0 Conv2D-11 [[16, 192, 28, 28]] [16, 192, 28, 28] 4,800 GELU-11 [[16, 192, 28, 28]] [16, 192, 28, 28] 0 GELU-9 [[16, 192, 1, 1]] [16, 192, 1, 1] 0 Conv2D-9 [[16, 192, 28, 28]] [16, 192, 28, 28] 37,056 Linear-10 [[16, 28, 28, 192]] [16, 28, 28, 192] 37,056 Dropout-6 [[16, 28, 28, 192]] [16, 28, 28, 192] 0 FocalModulation-3 [[16, 28, 28, 192]] [16, 28, 28, 192] 0 DropPath-2 [[16, 784, 192]] [16, 784, 192] 0 LayerNorm-8 [[16, 784, 192]] [16, 784, 192] 384 Linear-11 [[16, 784, 192]] [16, 784, 768] 148,224 GELU-12 [[16, 784, 768]] [16, 784, 768] 0 Dropout-7 [[16, 784, 192]] [16, 784, 192] 0 Linear-12 [[16, 784, 768]] [16, 784, 192] 147,648 Mlp-3 [[16, 784, 192]] [16, 784, 192] 0 FocalNetBlock-3 [[16, 784, 192]] [16, 784, 192] 0 LayerNorm-9 [[16, 784, 192]] [16, 784, 192] 384 Linear-13 [[16, 28, 28, 192]] [16, 28, 28, 387] 74,691 Conv2D-13 [[16, 192, 28, 28]] [16, 192, 28, 28] 1,728 GELU-14 [[16, 192, 28, 28]] [16, 192, 28, 28] 0 Conv2D-14 [[16, 192, 28, 28]] [16, 192, 28, 28] 4,800 GELU-15 [[16, 192, 28, 28]] [16, 192, 28, 28] 0 GELU-13 [[16, 192, 1, 1]] [16, 192, 1, 1] 0 Conv2D-12 [[16, 192, 28, 28]] [16, 192, 28, 28] 37,056 Linear-14 [[16, 28, 28, 192]] [16, 28, 28, 192] 37,056 Dropout-8 [[16, 28, 28, 192]] [16, 28, 28, 192] 0 FocalModulation-4 [[16, 28, 28, 192]] [16, 28, 28, 192] 0 DropPath-3 [[16, 784, 192]] [16, 784, 192] 0 LayerNorm-10 [[16, 784, 192]] [16, 784, 192] 384 Linear-15 [[16, 784, 192]] [16, 784, 768] 148,224 GELU-16 [[16, 784, 768]] [16, 784, 768] 0 Dropout-9 [[16, 784, 192]] [16, 784, 192] 0 Linear-16 [[16, 784, 768]] [16, 784, 192] 147,648 Mlp-4 [[16, 784, 192]] [16, 784, 192] 0 FocalNetBlock-4 [[16, 784, 192]] [16, 784, 192] 0 Conv2D-15 [[16, 192, 28, 28]] [16, 384, 14, 14] 295,296 LayerNorm-11 [[16, 196, 384]] [16, 196, 384] 768 PatchEmbed-3 [[16, 192, 28, 28]] [[16, 196, 384], [], []] 0 BasicLayer-2 [[16, 784, 192], None, None] [[16, 196, 384], [], []] 0 LayerNorm-12 [[16, 196, 384]] [16, 196, 384] 768 Linear-17 [[16, 14, 14, 384]] [16, 14, 14, 771] 296,835 Conv2D-17 [[16, 384, 14, 14]] [16, 384, 14, 14] 3,456 GELU-18 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 Conv2D-18 [[16, 384, 14, 14]] [16, 384, 14, 14] 9,600 GELU-19 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 GELU-17 [[16, 384, 1, 1]] [16, 384, 1, 1] 0 Conv2D-16 [[16, 384, 14, 14]] [16, 384, 14, 14] 147,840 Linear-18 [[16, 14, 14, 384]] [16, 14, 14, 384] 147,840 Dropout-10 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 FocalModulation-5 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 DropPath-4 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-13 [[16, 196, 384]] [16, 196, 384] 768 Linear-19 [[16, 196, 384]] [16, 196, 1536] 591,360 GELU-20 [[16, 196, 1536]] [16, 196, 1536] 0 Dropout-11 [[16, 196, 384]] [16, 196, 384] 0 Linear-20 [[16, 196, 1536]] [16, 196, 384] 590,208 Mlp-5 [[16, 196, 384]] [16, 196, 384] 0 FocalNetBlock-5 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-14 [[16, 196, 384]] [16, 196, 384] 768 Linear-21 [[16, 14, 14, 384]] [16, 14, 14, 771] 296,835 Conv2D-20 [[16, 384, 14, 14]] [16, 384, 14, 14] 3,456 GELU-22 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 Conv2D-21 [[16, 384, 14, 14]] [16, 384, 14, 14] 9,600 GELU-23 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 GELU-21 [[16, 384, 1, 1]] [16, 384, 1, 1] 0 Conv2D-19 [[16, 384, 14, 14]] [16, 384, 14, 14] 147,840 Linear-22 [[16, 14, 14, 384]] [16, 14, 14, 384] 147,840 Dropout-12 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 FocalModulation-6 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 DropPath-5 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-15 [[16, 196, 384]] [16, 196, 384] 768 Linear-23 [[16, 196, 384]] [16, 196, 1536] 591,360 GELU-24 [[16, 196, 1536]] [16, 196, 1536] 0 Dropout-13 [[16, 196, 384]] [16, 196, 384] 0 Linear-24 [[16, 196, 1536]] [16, 196, 384] 590,208 Mlp-6 [[16, 196, 384]] [16, 196, 384] 0 FocalNetBlock-6 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-16 [[16, 196, 384]] [16, 196, 384] 768 Linear-25 [[16, 14, 14, 384]] [16, 14, 14, 771] 296,835 Conv2D-23 [[16, 384, 14, 14]] [16, 384, 14, 14] 3,456 GELU-26 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 Conv2D-24 [[16, 384, 14, 14]] [16, 384, 14, 14] 9,600 GELU-27 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 GELU-25 [[16, 384, 1, 1]] [16, 384, 1, 1] 0 Conv2D-22 [[16, 384, 14, 14]] [16, 384, 14, 14] 147,840 Linear-26 [[16, 14, 14, 384]] [16, 14, 14, 384] 147,840 Dropout-14 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 FocalModulation-7 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 DropPath-6 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-17 [[16, 196, 384]] [16, 196, 384] 768 Linear-27 [[16, 196, 384]] [16, 196, 1536] 591,360 GELU-28 [[16, 196, 1536]] [16, 196, 1536] 0 Dropout-15 [[16, 196, 384]] [16, 196, 384] 0 Linear-28 [[16, 196, 1536]] [16, 196, 384] 590,208 Mlp-7 [[16, 196, 384]] [16, 196, 384] 0 FocalNetBlock-7 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-18 [[16, 196, 384]] [16, 196, 384] 768 Linear-29 [[16, 14, 14, 384]] [16, 14, 14, 771] 296,835 Conv2D-26 [[16, 384, 14, 14]] [16, 384, 14, 14] 3,456 GELU-30 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 Conv2D-27 [[16, 384, 14, 14]] [16, 384, 14, 14] 9,600 GELU-31 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 GELU-29 [[16, 384, 1, 1]] [16, 384, 1, 1] 0 Conv2D-25 [[16, 384, 14, 14]] [16, 384, 14, 14] 147,840 Linear-30 [[16, 14, 14, 384]] [16, 14, 14, 384] 147,840 Dropout-16 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 FocalModulation-8 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 DropPath-7 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-19 [[16, 196, 384]] [16, 196, 384] 768 Linear-31 [[16, 196, 384]] [16, 196, 1536] 591,360 GELU-32 [[16, 196, 1536]] [16, 196, 1536] 0 Dropout-17 [[16, 196, 384]] [16, 196, 384] 0 Linear-32 [[16, 196, 1536]] [16, 196, 384] 590,208 Mlp-8 [[16, 196, 384]] [16, 196, 384] 0 FocalNetBlock-8 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-20 [[16, 196, 384]] [16, 196, 384] 768 Linear-33 [[16, 14, 14, 384]] [16, 14, 14, 771] 296,835 Conv2D-29 [[16, 384, 14, 14]] [16, 384, 14, 14] 3,456 GELU-34 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 Conv2D-30 [[16, 384, 14, 14]] [16, 384, 14, 14] 9,600 GELU-35 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 GELU-33 [[16, 384, 1, 1]] [16, 384, 1, 1] 0 Conv2D-28 [[16, 384, 14, 14]] [16, 384, 14, 14] 147,840 Linear-34 [[16, 14, 14, 384]] [16, 14, 14, 384] 147,840 Dropout-18 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 FocalModulation-9 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 DropPath-8 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-21 [[16, 196, 384]] [16, 196, 384] 768 Linear-35 [[16, 196, 384]] [16, 196, 1536] 591,360 GELU-36 [[16, 196, 1536]] [16, 196, 1536] 0 Dropout-19 [[16, 196, 384]] [16, 196, 384] 0 Linear-36 [[16, 196, 1536]] [16, 196, 384] 590,208 Mlp-9 [[16, 196, 384]] [16, 196, 384] 0 FocalNetBlock-9 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-22 [[16, 196, 384]] [16, 196, 384] 768 Linear-37 [[16, 14, 14, 384]] [16, 14, 14, 771] 296,835 Conv2D-32 [[16, 384, 14, 14]] [16, 384, 14, 14] 3,456 GELU-38 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 Conv2D-33 [[16, 384, 14, 14]] [16, 384, 14, 14] 9,600 GELU-39 [[16, 384, 14, 14]] [16, 384, 14, 14] 0 GELU-37 [[16, 384, 1, 1]] [16, 384, 1, 1] 0 Conv2D-31 [[16, 384, 14, 14]] [16, 384, 14, 14] 147,840 Linear-38 [[16, 14, 14, 384]] [16, 14, 14, 384] 147,840 Dropout-20 [[16, 14, 14, 384]] [16, 14, 14, 384] 0
FocalModulation-10 [[16, 14, 14, 384]] [16, 14, 14, 384] 0 DropPath-9 [[16, 196, 384]] [16, 196, 384] 0 LayerNorm-23 [[16, 196, 384]] [16, 196, 384] 768 Linear-39 [[16, 196, 384]] [16, 196, 1536] 591,360 GELU-40 [[16, 196, 1536]] [16, 196, 1536] 0 Dropout-21 [[16, 196, 384]] [16, 196, 384] 0 Linear-40 [[16, 196, 1536]] [16, 196, 384] 590,208 Mlp-10 [[16, 196, 384]] [16, 196, 384] 0 FocalNetBlock-10 [[16, 196, 384]] [16, 196, 384] 0 Conv2D-34 [[16, 384, 14, 14]] [16, 768, 7, 7] 1,180,416 LayerNorm-24 [[16, 49, 768]] [16, 49, 768] 1,536 PatchEmbed-4 [[16, 384, 14, 14]] [[16, 49, 768], [], []] 0 BasicLayer-3 [[16, 196, 384], None, None] [[16, 49, 768], [], []] 0 LayerNorm-25 [[16, 49, 768]] [16, 49, 768] 1,536 Linear-41 [[16, 7, 7, 768]] [16, 7, 7, 1539] 1,183,491 Conv2D-36 [[16, 768, 7, 7]] [16, 768, 7, 7] 6,912 GELU-42 [[16, 768, 7, 7]] [16, 768, 7, 7] 0 Conv2D-37 [[16, 768, 7, 7]] [16, 768, 7, 7] 19,200 GELU-43 [[16, 768, 7, 7]] [16, 768, 7, 7] 0 GELU-41 [[16, 768, 1, 1]] [16, 768, 1, 1] 0 Conv2D-35 [[16, 768, 7, 7]] [16, 768, 7, 7] 590,592 Linear-42 [[16, 7, 7, 768]] [16, 7, 7, 768] 590,592 Dropout-22 [[16, 7, 7, 768]] [16, 7, 7, 768] 0
FocalModulation-11 [[16, 7, 7, 768]] [16, 7, 7, 768] 0 DropPath-10 [[16, 49, 768]] [16, 49, 768] 0 LayerNorm-26 [[16, 49, 768]] [16, 49, 768] 1,536 Linear-43 [[16, 49, 768]] [16, 49, 3072] 2,362,368 GELU-44 [[16, 49, 3072]] [16, 49, 3072] 0 Dropout-23 [[16, 49, 768]] [16, 49, 768] 0 Linear-44 [[16, 49, 3072]] [16, 49, 768] 2,360,064 Mlp-11 [[16, 49, 768]] [16, 49, 768] 0 FocalNetBlock-11 [[16, 49, 768]] [16, 49, 768] 0 LayerNorm-27 [[16, 49, 768]] [16, 49, 768] 1,536 Linear-45 [[16, 7, 7, 768]] [16, 7, 7, 1539] 1,183,491 Conv2D-39 [[16, 768, 7, 7]] [16, 768, 7, 7] 6,912 GELU-46 [[16, 768, 7, 7]] [16, 768, 7, 7] 0 Conv2D-40 [[16, 768, 7, 7]] [16, 768, 7, 7] 19,200 GELU-47 [[16, 768, 7, 7]] [16, 768, 7, 7] 0 GELU-45 [[16, 768, 1, 1]] [16, 768, 1, 1] 0 Conv2D-38 [[16, 768, 7, 7]] [16, 768, 7, 7] 590,592 Linear-46 [[16, 7, 7, 768]] [16, 7, 7, 768] 590,592 Dropout-24 [[16, 7, 7, 768]] [16, 7, 7, 768] 0
FocalModulation-12 [[16, 7, 7, 768]] [16, 7, 7, 768] 0 DropPath-11 [[16, 49, 768]] [16, 49, 768] 0 LayerNorm-28 [[16, 49, 768]] [16, 49, 768] 1,536 Linear-47 [[16, 49, 768]] [16, 49, 3072] 2,362,368 GELU-48 [[16, 49, 3072]] [16, 49, 3072] 0 Dropout-25 [[16, 49, 768]] [16, 49, 768] 0 Linear-48 [[16, 49, 3072]] [16, 49, 768] 2,360,064 Mlp-12 [[16, 49, 768]] [16, 49, 768] 0 FocalNetBlock-12 [[16, 49, 768]] [16, 49, 768] 0 BasicLayer-4 [[16, 49, 768], None, None] [[16, 49, 768], [], []] 0 LayerNorm-29 [[16, 49, 768]] [16, 49, 768] 1,536
AdaptiveAvgPool1D-1 [[16, 768, 49]] [16, 768, 1] 0 Linear-49 [[16, 768]] [16, 1000] 769,000
===========================================================================================
Total params: 28,427,116
Trainable params: 28,427,116
Non-trainable params: 0
-------------------------------------------------------------------------------------------
Input size (MB): 9.19
Forward/backward pass size (MB): 4652.97
Params size (MB): 108.44
Estimated Total Size (MB): 4770.60
-------------------------------------------------------------------------------------------number of GFLOPs: 4.412630784
number of params: Tensor(shape=[1], dtype=int64, place=Place(gpu:0), stop_gradient=False,[28427116])
3.3 精度测试
ImageNet-1K验证集
论文中FocalNet的精度也是采用ImageNet-1K验证集评估的
# 解压ImageNet 1K数据集
%cd /home/aistudio
!mkdir data/ILSVRC2012
!unzip -qo ~/data/data182091/ILSVRC2012_val.zip -d ~/data/ILSVRC2012/
/home/aistudio
定义并获取数据集
# 生成验证集Dataset和基于论文参数配置transforms
import os
import cv2
import numpy as np
import paddle
import paddle.vision.transforms as T
from PIL import Image# 构建数据集
class ILSVRC2012(paddle.io.Dataset):def __init__(self, root, label_list, transform, backend='pil'):self.transform = transformself.root = rootself.label_list = label_listself.backend = backendself.load_datas()def load_datas(self):self.imgs = []self.labels = []with open(self.label_list, 'r') as f:for line in f:img, label = line[:-1].split(' ')self.imgs.append(os.path.join(self.root, img))self.labels.append(int(label))def __getitem__(self, idx):label = self.labels[idx]image = self.imgs[idx]if self.backend=='cv2':image = cv2.imread(image)else:image = Image.open(image).convert('RGB')image = self.transform(image)return image.astype('float32'), np.array(label).astype('int64')def __len__(self):return len(self.imgs)# 定义验证集验证前的处理,用于对齐论文
val_transforms = T.Compose([T.Resize(int(224 / 0.875), interpolation='bicubic'),T.CenterCrop(224),T.ToTensor(),T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 验证集
val_dataset = ILSVRC2012('data/ILSVRC2012/ILSVRC2012_val', transform=val_transforms, label_list='data/data182091/ILSVRC2012_val_list.txt', backend='pil')
# 开始评估focalnet_tiny_srf模型focalnet_tiny_srl = focalnet_tiny_srf()
# 载入对应的权重(由论文预训练模型转换而来)
focalnet_tiny_srl.load_dict(paddle.load('data/data182091/focalnet_tiny_srf.pdparams')) focalnet_tiny_srl = paddle.Model(focalnet_tiny_srl)
focalnet_tiny_srl.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 模型评估 224 resolution
acc = focalnet_tiny_srl.evaluate(val_dataset, batch_size=32, num_workers=0, verbose=1)
print(acc)
Eval begin...
step 1563/1563 [==============================] - acc_top1: 0.8206 - acc_top5: 0.9595 - 291ms/step
Eval samples: 50000
{'acc_top1': 0.82056, 'acc_top5': 0.95948}
# 验证 focalnet_small_srf 模型
focalnet_small_srl= focalnet_small_srf()
focalnet_small_srl.load_dict(paddle.load('data/data182091/focalnet_small_srf.pdparams'))focalnet_small_srl = paddle.Model(focalnet_small_srl)
focalnet_small_srl.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 模型评估
acc = focalnet_small_srl.evaluate(val_dataset, batch_size=32, num_workers=0, verbose=1)
print(acc)
Eval begin...
step 1563/1563 [==============================] - acc_top1: 0.8336 - acc_top5: 0.9644 - 293ms/step
Eval samples: 50000
{'acc_top1': 0.83356, 'acc_top5': 0.96436}
# 验证 focalnet_base_srf 模型
focalnet_base_srl= focalnet_base_srf()
focalnet_base_srl.load_dict(paddle.load('data/data182091/focalnet_base_srf.pdparams'))focalnet_base_srl = paddle.Model(focalnet_base_srl)
focalnet_base_srl.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 模型评估
acc = focalnet_base_srl.evaluate(val_dataset, batch_size=32, num_workers=0, verbose=1)
print(acc)
Eval begin...
step 1563/1563 [==============================] - acc_top1: 0.8372 - acc_top5: 0.9661 - 330ms/step
Eval samples: 50000
{'acc_top1': 0.83716, 'acc_top5': 0.96614}
模型精度表现
在ImageNet-1K 验证集上的精度表现

- Strict comparison with multi-scale Swin and Focal Transformers(精度验证在最后一列):
| Model | Depth | Dim | Kernels | #Params. (M) | FLOPs (G) | Throughput (imgs/s) | Top-1 | Top-1(精度验证) |
|---|---|---|---|---|---|---|---|---|
| FocalNet-Tiny | [2,2,6,2] | 96 | [3,5] | 28.4 | 4.4 | 743 | 82.1 | 82.056 |
| FocalNet-Tiny | [2,2,6,2] | 96 | [3,5,7] | 28.6 | 4.5 | 696 | 82.3 | 82.198 |
| FocalNet-Small | [2,2,18,2] | 96 | [3,5] | 49.9 | 8.6 | 434 | 83.4 | 83.356 |
| FocalNet-Small | [2,2,18,2] | 96 | [3,5,7] | 50.3 | 8.7 | 406 | 83.5 | 83.462 |
| FocalNet-Base | [2,2,18,2] | 128 | [3,5] | 88.1 | 15.3 | 280 | 83.7 | 83.716 |
| FocalNet-Base | [2,2,18,2] | 128 | [3,5,7] | 88.7 | 15.4 | 269 | 83.9 | 83.824 |
由于ImageNet的训练集超过100G,无法在aistudio上解压,为了达成可训练模型的目的,取ImageNet的前100个分类重新划分了训练集和验证集。
# 解压imagenet-100
!unzip -qo /home/aistudio/data/data182091/ImageNet-100.zip -d /home/aistudio/data/
%cd ~
import paddle
import paddle.vision.transforms as T
# 模型训练
net= focalnet_base_srf(num_classes=100)
# 使用预训练模型
#net.load_dict(paddle.load('data/data182091/focalnet_base_srf.pdparams'))
model = paddle.Model(net)
# 学习率策略
scheduler = paddle.optimizer.lr. LinearWarmup( learning_rate=0.0001, warmup_steps=30, start_lr = 0.000001, end_lr=0.0001, verbose=True ) # 训练前的配置准备
model.prepare(optimizer= paddle.optimizer.AdamW( learning_rate=scheduler, parameters=model.parameters(), beta1=0.9,beta2=0.999, epsilon=1e-08, weight_decay=0.05,),loss=paddle.nn.CrossEntropyLoss(),metrics=paddle.metric.Accuracy(topk=(1, 5)))# 训练图片处理,暂不是用论文中的自动增强
train_transforms = T.Compose([T.Resize(256, interpolation='bicubic'),T.RandomCrop(224),T.RandomHorizontalFlip(0.5),T.ToTensor(),T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.2, 0.2, 0.2])
])val_transforms = T.Compose([T.Resize(int(224 / 0.875), interpolation='bicubic'),T.CenterCrop(224),T.ToTensor(),T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.2, 0.2, 0.2])
])mini_train_dataset = paddle.vision.datasets.DatasetFolder( 'data/ImageNet-100/train', loader=None, transform=train_transforms)
mini_val_dataset = paddle.vision.datasets.DatasetFolder( 'data/ImageNet-100/val', loader=None, transform=val_transforms)visualdl=paddle.callbacks.VisualDL(log_dir='output/visual_log') # 开启训练可视化
# print(len(mini_train_dataset))
# print(len(mini_val_dataset))
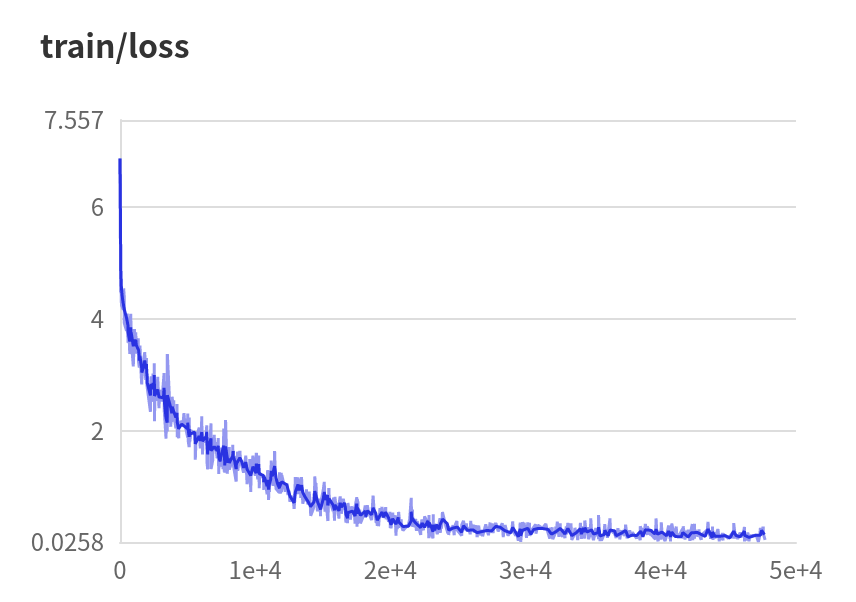
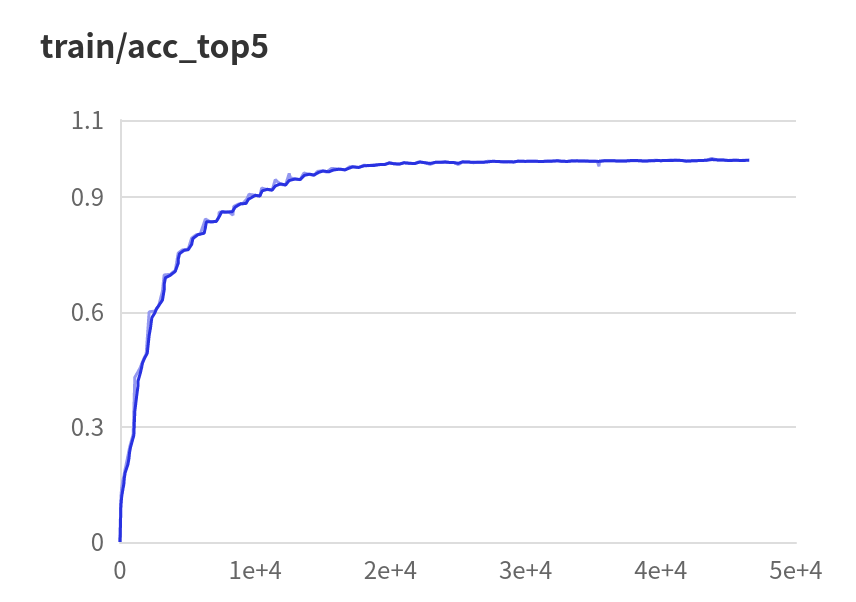
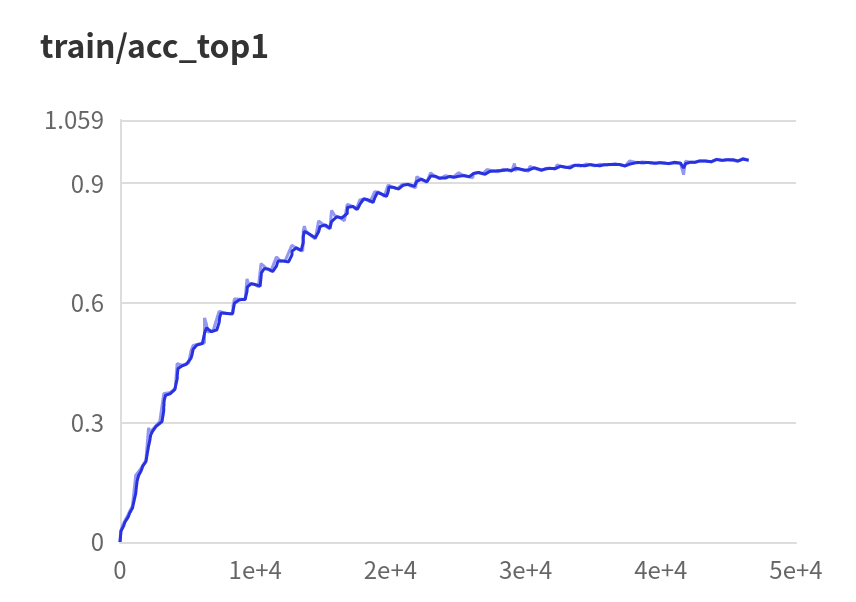
model.fit( train_data=mini_train_dataset, eval_data=mini_val_dataset, batch_size=48, epochs=300,verbose=1,eval_freq =1,log_freq=10,save_dir='output',save_freq=20,callbacks=[visualdl]
)
|
|
|
# 评估训练的模型
focalnet_base_srl= focalnet_base_srf()
focalnet_base_srl.load_dict(paddle.load('/home/aistudio/output/final.pdparams'))focalnet_base_srl = paddle.Model(focalnet_base_srl)
focalnet_base_srl.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 模型评估
acc = focalnet_base_srl.evaluate(mini_val_dataset, batch_size=32, num_workers=0, verbose=1)
print(acc)
3.4 集成到PaddleClas中评估和训练
# 克隆PaddleClas
#!git clone https://gitee.com/paddlepaddle/PaddleClas.git
# 如果中断也可以直接解压
!unzip -qo ~/PaddleClas.zip -d /home/aistudio/
# 集成FocalNet到PaddleClas
! cp -r work/classification/* PaddleClas/
%cd PaddleClas
# 安装PaddleClas
! python setup.py install
# 开始验证 focalnet_base_srf(如果报错,请重启内核释放内存在尝试)
%cd /home/aistudio/PaddleClas
!python tools/eval.py \-c ./ppcls/configs/ImageNet/FocalNet/FocalNet_base_srf.yaml \-o Global.pretrained_model=/home/aistudio/data/data182091/focalnet_base_srf -o Global.print_batch_step=100FoclNet_base_srf 的 Top1 为 0.83348 ,与论文精度有一点偏差。
现在也可以在直接PaddleClas中训练:
# 生成数据集标签和图片对应列表
with open('/home/aistudio/data/ImageNet-100/train_list.txt','w') as f:samples = mini_train_dataset.samplesfor img, label in samples:f.write('/home/aistudio/'+img+' '+ str(label)+"\n")
with open('/home/aistudio/data/ImageNet-100/val_list.txt','w') as f:samples = mini_val_dataset.samplesfor img, label in samples:f.write('/home/aistudio/'+img+' '+ str(label)+"\n")
# 模型训练
%cd /home/aistudio/PaddleClas
!python tools/train.py \-c ./ppcls/configs/ImageNet/FocalNet/FocalNet_base_srf.yaml \-o DataLoader.Train.dataset.image_root='/home/aistudio/data/ImageNet-100/train' -o DataLoader.Train.dataset.cls_label_path='/home/aistudio/data/ImageNet-100/train_list.txt' \-o DataLoader.Eval.dataset.image_root='/home/aistudio/data/ImageNet-100/val' -o DataLoader.Eval.dataset.cls_label_path='/home/aistudio/data/ImageNet-100/val_list.txt' \-o Global.epochs=300 -o Global.use_visualdl=True -o Global.pretrained=False -o Args.class_num=100
4 总结
- 使用Paddle框架重新实现了FocalNet并模型训练和验证的操作。
- 在精度表现上,转换的参考项目模型参数的精度表现与论文的精度基本一致。
- 与论文中给出的精度数据也基本相似,某些模型甚至稍微有些许提升。
- 因复现过程经验不足和时间关系,在目标检测和图像分割方面未能复现。
此文章为搬运
原项目链接
论文复现:Focal modulation networks相关推荐
- PaddlePaddle飞桨论文复现营——3D Residual Networks for Action Recognition学习笔记
PaddlePaddle飞桨论文复现营--3D Residual Networks for Action Recognition学习笔记 1 背景知识 1.1 C3D C3D是一种3D卷积提取视频特征 ...
- 论文复现:Learning Efficient Convolutional Networks through Network Slimming
论文核心 论文提出了一种结构化剪枝策略,剪枝对象为 channel ,对 channel 重要性的评价标准使用的是 Batch Normalization 层中的缩放因子,这不会给网络带来额外的开销. ...
- 【PaddlePaddle论文复现营】Temporal Pyramid Network for Action Recognition
[PaddlePaddle论文复现营]Temporal Pyramid Network for Action Recognition 写在前面的话 论文简介 从视频分类领域中的一个痛点谈起 相关工作 ...
- 论文无法复现「真公开处刑」,PapersWithCode上线「论文复现报告」
点击上方"视学算法",选择加"星标"或"置顶" 重磅干货,第一时间送达 来源丨机器之心 编辑丨极市平台 导读 近日,机器学习资源网站 Pap ...
- 经典论文复现 | LSGAN:最小二乘生成对抗网络
来源:PaperWeekly 本文约2500字,建议阅读10分钟. 本文介绍了经典AI论文--LSGAN,它比常规GAN更稳定,比WGAN收敛更迅速. 笔者这次选择复现的是 Least Squares ...
- 经典论文复现 | ICML 2017大热论文:Wasserstein GAN
过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含"伪代码".这是今年 AAAI ...
- 经典论文复现 | InfoGAN:一种无监督生成方法
过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含"伪代码".这是今年 AAAI ...
- 经典论文复现 | PyraNet:基于特征金字塔网络的人体姿态估计
过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含"伪代码".这是今年 AAAI ...
- 【PaddlePaddle】【论文复现】U-GAT-IT
[PaddlePaddle][论文复现]Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normal ...
最新文章
- 责任链模式 mashibing代码
- 使用postman模拟百度通用文字识别
- (50)IO的延迟约束(输入延迟约束)
- 贺利坚老师汇编课程54笔记:ZF零标志ZERO FLAG
- openstarck安装指南(图文详解,超小白版本)
- SpringCloud视频教程 百度云盘
- 表的增删改查(一)(MySQL)
- 新闻接口调用之新浪滚动新闻
- 冰刃 IceSword1.22 中文版
- (已解决)windows和linux系统中使用 pycharm 时设置打印字体颜色和背景色
- 英文pdf的划词翻译阅读方法
- GBK-unicode对照
- 非功能性需求之性能需求分析
- 台式电脑计算机被限制,gpedit.msc 无法运行 提示本次操作由于这台计算机的限制而被取消(超强解决方案)...
- 用c 语言求纸对折的次数,纸张对折新纪录:13次
- 2021年上海市安全员C证考试试题及上海市安全员C证操作证考试
- 3 Kong 管理运维
- 李开复给中国大学生的第一封信—从诚信谈起
- 《当程序员的那些狗日日子》(五十七)迟来的爱恋
- ManytoMany字段属性through和through_fields
热门文章
- xp下如何配置oracle监听,黑鲨研习win10系统oracle监听服务无法打开的办法
- 线程与go协程的区别
- 看漫画学python下载_Python下载漫画
- Android hibernation 导致的冻屏问题分析
- Apache httpd.conf配置文件AllowOverride参数详解
- Cannot resolve overloaded method 'aggregate'
- 国产护眼灯哪个品牌好?分享优质护眼台灯测评
- 思维经验 | 如何刻意练习提升用户思维?
- 华为荣耀新款鸿蒙,华为鸿蒙重大升级,性能提升42% 支持5年老机型,荣耀手机也有份...
- 语音识别学习日志 2018-7-19 语音识别基础知识准备(5)[Viterbi算法]