ELM——一种适用于经济学和大数据的机器学习方法
2019独角兽企业重金招聘Python工程师标准>>> 
极限学习机的机制
ELM模型
ELM是一种具有快速训练训练集的单层前馈网络,在网络中只有三个层:the Input Layer,the Hidden Layer和the Output Layer。如图所示的三层结构,
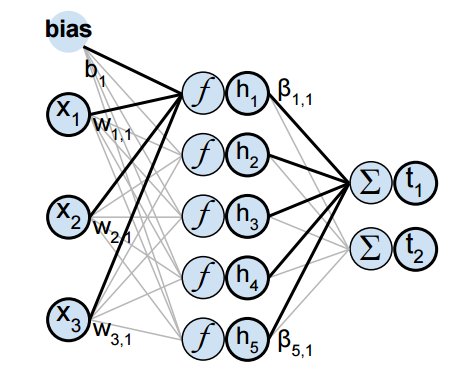
在Input Layer中对于每个训练集的每个样本都会有对应的权值和偏移量,ELM中提供两种方式:一种是手动输入这些权值和偏移量,另一种方式是ELM通过ELM toolbox自动生成权值和偏移量,但是随机并不是随意的生成而是根据原始数据的规模和sigmoid神经元函数来进行生成。对于一个线性的Output Layer,随机生成权值会更能体现ELM性能优势。

隐藏层
隐藏层有两种神经元形式:隐藏神经元和RBF(径向基函数)神经元
这两种神经元主要的区别是激活方式不同,隐藏神经元的激活函数包括:Linear,non-Linear或者其他函数(sigmoid, hyperbolic, tangent, threshold等等);RBF神经元是通过神经元到中心点的距离,权值W(正如输入到隐藏层的距离)

隐藏层的矩阵
如下图将ELM神经网络用矩阵的形式表示

其中X表示输入矩阵,T表示对应的label矩阵,隐藏层的矩阵H如下

理论上讲,只有一个矩阵描述两个线性空间(输入和输出)之间的映射,所以ELM可以看作是两个映射:输入WX和输出 ,映射关系是
,映射关系是 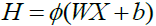 。隐藏的神经元的数量调节矩阵的大小 W,H 和
。隐藏的神经元的数量调节矩阵的大小 W,H 和 ,但是他们并不是分开的。对于不同类型的隐藏神经元,对于每种类型的神经元独立地执行第一映射和变换。 然后,所得到的子矩阵H1连接下一个矩阵,如以下扩充方式:
,但是他们并不是分开的。对于不同类型的隐藏神经元,对于每种类型的神经元独立地执行第一映射和变换。 然后,所得到的子矩阵H1连接下一个矩阵,如以下扩充方式:

线性的神经元则通过简单地将输入复制到ELM的隐藏层中,如下扩充方式

ELM分类
正如开篇所说,ELM是一个回归模型,但也适用于分类
如果不同的类别是分开的并且是独立的,则分别为每个类别创建一个目标,能够匹配的类的目标是1,不匹配的目标设置为0。该编码为每个类别创建单位长度向量,其与所有其他类别的向量正交。不同类别的目标向量之间的距离是相同的,因此保持类独立性。 根据具有最大ELM输出的目标来分配预测类别。
模型结构选择
模型结构选择防止ELM从数据中学习噪声和过拟合。它通过人为地限制ELM的学习能力来实现。模型结构选择过程通过改变模型参数或者对模型应用正则化来找到最优性能
ELM的hyper-parameter是隐藏神经元的数量,其能够控制ELM有效参数的数量。通过验证集,交叉验证或弃一法交叉验证(ELM中最有效)来找到神经元的最佳数量。隐藏的神经元可以被随机地添加和移除,或者它们可以通过它们与问题的相关性来排序。这种排名被称为“最优修剪”,它实现更好的性能与更长的运行时间的权衡。神经元修剪方法对应于L1正则化。
ELM中可用的另一种模型结构选择技术是Tikhonov正则化[34]。它通过减少神经元输出的影响而不用自己去除神经元来减少模型参数的有效数目。 Tikhonov正则化对于实现近单个ELM中的数值稳定性(以及一般的线性问题)是有效的。这种正则化对应于L2-正则化,并且可以与L1组合以获得最佳结果。
模型结构选择在大数据任务中不太重要,因为在大量样本中,模型学习忽略噪声。大型任务通常是复杂的,甚至在硬件的极限情况下也不能超载。此外,大多数模型结构选择方法显着增加运行时间,这是训练大型ELM模型的限制因素。
极限学习机的操作
之前自己简单的学习了一下机器学习的东西主要是从应用层面学习了一下,借助scikit-learn的库进行模型调用,拟合和预测,如下是借用一些国外高等学校的数据和部分模板代码来与我们的elm进行比较,代码很简单,需要跑一下python代码的朋友可以直接邮件我,下面是我的邮箱:
nextowang@stu.xidian.edu.cn
如下图是测试数据原始点的分布
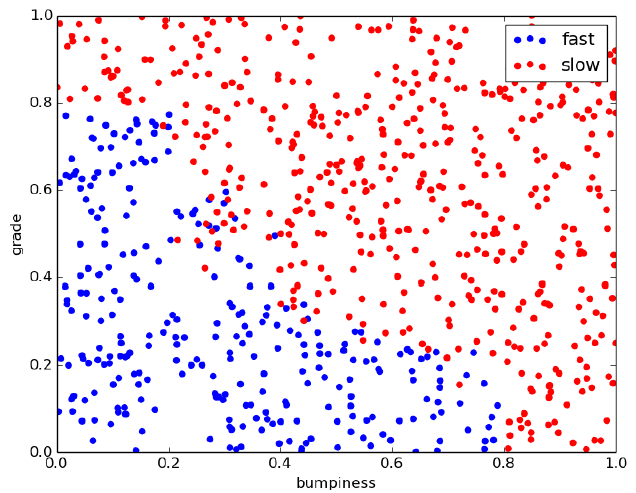
下面是用RandomForest对训练数据拟合,然后对测试数据进行分类,


下面是elm的拟合和预测,


激活函数sigm 激活函数tanh
对应的准确率


极限学习机的性能分析
在大数据集中的分析
大数据集是6个相对较大的数据集,可从具有清晰预测目标的UCI机器学习库获得。每个数据集分为训练和测试部分,以HDF5文件格式存储,并针对所有要素归一化为零均值和单位方差。大型数据集在没有模型结构选择的情况下测试,但是多个ELM是用不同数量的隐藏神经元构建的。
在大数据中的分析
大数据从面部/皮肤检测数据集获得,这些数据是4000张有不同光线,环境及不同肤色的手工制造的人脸面具,皮肤占据所有图像中大约20%的像素。 数据集分为2000个训练和2000个测试图像。将每个图像像素分类为皮肤或非皮肤。,数据集输入是以分类像素为中心的7×7像素的RGB颜色值。 省略图像的3像素宽边界。 总共有7×7×3(RGB)= 147个特征和 (十亿)个数据样本。 当以双精度存储时, 以HDF5格式存储了1.1 TB数据集。 从训练/测试图像创建用于所有训练和所有测试样本的两个单独的数据集。 数据特征(像素的颜色值)被归一化为零均值和单位方差。 单个ELM训练有19,000个神经元,受可用GPU内存的限制。 性能在这些19,000个神经元的不同大小的子集上进行测试。
通过训练一个ELM与19,000 Sigmoid隐藏的神经元来解决在147维空间中具有5亿个训练样本,加权分类用于抵消两个目标类之间的不平衡。计算是通过将数据分成小部分,每个大约1小时的处理时间来完成的。这为了防止在计算机故障的情况下的数据丢失,并且允许并行化。
与大数据集相比,皮肤检测大数据的数据集为ELM模型设置了两个额外的挑战:它需要平衡分类,因为两类中的数据量不均匀(皮肤的17%和非皮的83%);它还需要测试不同数量的神元,以找出19,000隐藏神经元是否满足。如果有任何过拟合,上述两个就会出现相应的问题。由于所使用的平衡分类方法,测试精度图显示了对于皮肤像素分类的非常好的结果。 没有平衡分类的ELM将严重偏向于预测非皮肤的像素,其是数据集中的样本的83%。 皮肤分类精度的改善减慢了超过128个隐藏的神经元,因此较小的ELM可以用于检测皮肤。 然而,非皮肤的分类精度稳定地增加到神经元的最大数量。 这可以通过比皮肤像素掩模更多种类的非皮肤像素面具来解释。 即使在19,000个神经元中,ELM也不会过度拟合,虽然在大量隐藏神经元的情况下性能增益降低。

总结
本文提出了一种用于高度可扩展的极限学习机的方法和工具箱。 此工具包创建广义SLFN(Single-Layer Feed-forward Networks)并使用ELM方法训练它们,但可以是用于未来多层ELM的工作的构建块。 它是快速,易于安装和易于使用。 它解决了各种数据集的分类和回归问题 - 小型模型结构选择和正则化,大型加速计算
转载于:https://my.oschina.net/nextowang/blog/769074
ELM——一种适用于经济学和大数据的机器学习方法相关推荐
- 基于python的分布式扫描器_一种基于python的大数据分布式任务处理装置的制作方法...
本发明涉及数据处理技术,具体是一种基于python的大数据分布式任务处理装置. 背景技术: 本发明提供一种分布式队列任务处理方案和装置,该方法可以提供分布式处理python任务,任务类型包括爬虫及其他 ...
- 三种最典型的大数据存储技术路线
三种最典型的大数据存储技术路线 近期由中关村大数据产业联盟举办的"大数据100分"线上研讨会中,南大通用的CTO.资深业界专家武新博士同众多网友分享了底层数据处理技术的发展趋势和正 ...
- 九种引人瞩目的开源大数据技术
1.Apache Hadoop Apache hadoop是一个开源的分布式计算框架,最初由Doug为支持其开源Web搜索引擎Nutch所创立.通过集成MapReduce技术,Hadoop将大数据分布 ...
- 企业大数据-之机器数据
机器数据的来源 何为机器数据,就对其字面意思理解,机器产生的数据.那机器数据具体都是怎样的?比如:日志数据.监控摄像图传过来的数据.手机传过来的数据.传感器传过来的.扫码.....几乎遍布生活的点点滴 ...
- 不可错过!斯坦福课程3D数据的机器学习方法(Machine Learning for 3D Data)第一部分
可以看出shapeNet数据集很大,种类也很多
- 不可错过!斯坦福课程3D数据的机器学习方法(Machine Learning for 3D Data)第二部分Geometry Foundations: Surface Representations
形状的表示方法 参数化表示 参数化曲线 参数方式的优缺点 隐式表示法与优缺点
- 基于材料数值计算大数据的材料辐照机理发现
点击上方蓝字关注我们 基于材料数值计算大数据的材料辐照机理发现 任帅1,2, 陈丹丹1,2, 储根深1,2, 白鹤1,2, 李慧昭1, 何远杰1, 胡长军1,2 1 北京科技大学计算机与通信工程学院, ...
- 《大数据》2021年第6期目次摘要
点击上方蓝字关注我们 <大数据> 第7卷第6期 2021年11月 大数据2021年第6期 (点击原文链接在官网阅读完整文章) 目次 01 专题导读:大数据支撑的智能应用 周斌, 秦永彬 0 ...
- 2015年《大数据》高被引论文Top10文章No.7——大数据机器学习系统研究进展(上)...
2015年<大数据>高被引论文Top10文章展示 [编者按]本刊将把2015年<大数据>高被引论文Top10的文章陆续发布,欢迎大家关注!本文为高被引Top10论文的No.7, ...
最新文章
- spark on yarn 完全分布式_Spark编程笔记(1)-架构基础与运行原理
- windows7升级安装之初体验
- mysql调用函数可以打断点吗_糖尿病人可以吃杂粮粥吗?不用纠结,注意2点即可...
- Linux学习:静态库和动态库
- Spoken English(001)
- 7个CSS你可能不知道的技巧
- 静态与非静态(转改)
- 解决:com.mysql.jdbc.MysqlDataTruncation: Data truncation: Data too long for column ‘ip‘ at row 1
- 简单粗暴入门JAVA之方法
- 让AI打工!搜狗全体员工于3月12日狗胜节放假一天
- SAP License:更改物料基本计量单位
- HDU1024 Max Sum Plus Plus【最大子段和+DP】
- 机器学习面试-处理聚类问题
- 《修炼之道:.NET开发要点精讲》读书笔记(三)
- 第一篇博客--有志者,事竟成
- 计算机网络期末考试代做,代做计算机作业-易指做帮写网
- 广东外语外贸大学第16届程序设计竞赛-C 井大师的码魂
- MySQL Sending data 查询数据慢
- 魔兽对战平台服务器更新维护什么,官方对战平台每天5点维护是个什么梗
- windows 10 cortana搜索功能失效