爬虫采集-基于webkit核心的客户端Ghost.py [爬虫实例]
对与要时不时要抓取页面的我们来说,是痛苦的~
由于目前的Web开发中AJAX、Javascript、CSS的大量使用,一些网站上的重要数据是由Ajax或Javascript动态生成的,并不能直接通过解析html页面内容就能获得(例如采用urllib2,mechanize、lxml、Beautiful Soup )。要实现对这些页面数据的爬取,爬虫必须支持Javacript、DOM、HTML解析。
比如: 像监控的数据就不能用简单的curl和urllib解析到的。。。
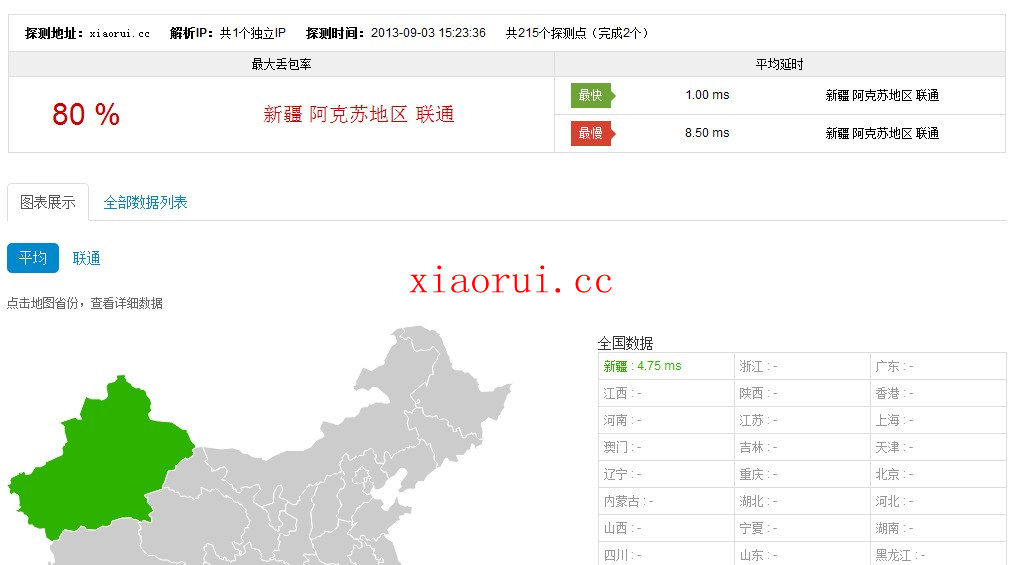
还有这个用ajax 渲染的页面,用urllib2直接解析不了的。
http://rfyiamcool.blog.51cto.com/blog/1030776/1287810
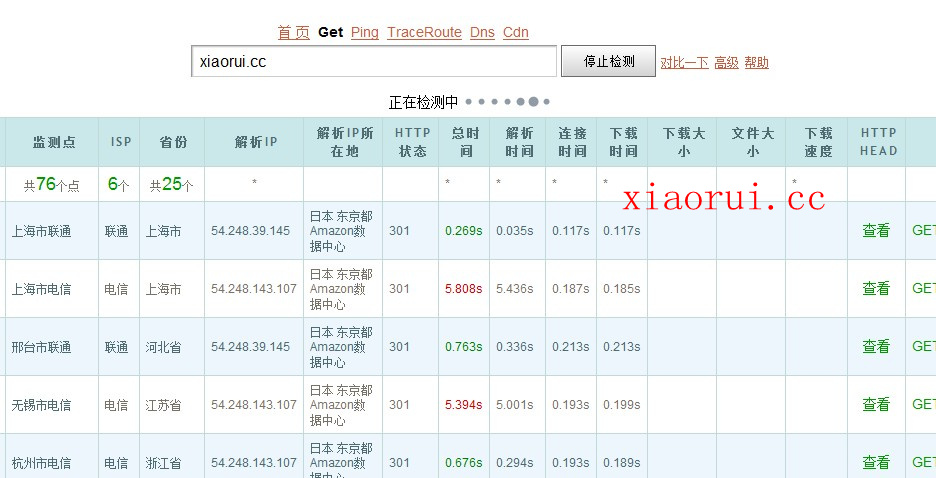
常见的抓数据的方法:
urllib2+urlparse+re
最原始的办法,其中urllib2是python的web库、urlparse能处理url、re是正则库,这种方法写起来比较繁琐,但也比较“实在”
urllib2+beautifulsoup
这里的得力干将是beautifulsoup,beautifulsoup可以非常有效的解析HTML页面,就可以免去自己用re去写繁琐的正则等。
Mechanize+BeautifulSoup
Mechanize是对于urllib2的部分功能的替换,使得除了http以外其他任何连接也都能被打开,也更加动态可配置
http://rfyiamcool.blog.51cto.com/blog/1030776/1287810
其实像上面的页面,要是不嫌麻烦,可以从页面狂找接口,下出来的大多是xml的格式,然后你再费劲的去解析。。。是在他折腾了。
这时候大家可以用 webkit核心的web 客户端。 他会像真正的浏览器一样来解析页面的。
WebKit: Safari, Google Chrome,傲游3 360浏览器 等等都是基于 Webkit 核心开发。
我们一般是终端取值的,这些也有不少封装好的工具
Pyv8,PythonWebKit,Selenium,PhantomJS,Ghost.py 等等。。。。
我这里推荐用ghost.py 。。。。 因为他够直接和实用
发现国内webkit的资料很少,ghost.py的资料就更少了,那我就根据官方的文档,简单的翻译下 ~
http://rfyiamcool.blog.51cto.com/blog/1030776/1287810
一个小例子,感受下Ghost~
from ghost import Ghost
ghost = Ghost()
page, extra_resources = ghost.open("http://xiaorui.cc")
assert page.http_status==200 and 'xiaorui' in ghost.content
安装Ghost.py 以及相关的东东~~
用webkit,我们需要有pyqt或者是PySide
这些都安装好了后,再开始
运气好的直接 pip install Ghost.py
运气不好的:
中间会遇到好多蛋疼的问题,大家多搜搜~
要是解决不了了,请回帖哈~
wget http://sourceforge.net/projects/pyqt/files/sip/sip-4.14.6/sip-4.14.6.tar.gz tar zxvf sip-4.14.6.tar.gz cd sip-4.14.6 python configure.py make sudo make install wget http://sourceforge.net/projects/pyqt/files/PyQt4/PyQt-4.10.1/PyQt-mac-gpl-4.10.1.tar.gz tar zxvf PyQt-mac-gpl-4.10.1.tar.gz cd PyQt-mac-gpl-4.10.1 python configure.py make sudo make install wget http://pyside.markus-ullmann.de/pyside-1.1.1-qt48-py27apple.pkg open pyside-1.1.1-qt48-py27apple.pkg git clone https://github.com/mitsuhiko/flask.git cd flask sudo python setup.py install git clone git://github.com/carrerasrodrigo/Ghost.py.git cd Ghost.py sudo python setup.py install
创建一个实例对象:
from ghost import Ghost ghost = Ghost()
打开一个页面
page, resources = ghost.open('http://my.web.page')
夹带着 javascript代码
result, resources = ghost.evaluate("document.getElementById('my-input').getAttribute('value');")
模拟点击事件
page, resources = ghost.evaluate("document.getElementById('link').click();", expect_loading=True)
填写表单中的字段中的值 (selector, value, blur=True, expect_loading=False):
result, resources = ghost.set_field_value("input[name=username]", "jeanphix")
If you set optional parameter `blur` to False, the focus will be left on the field (usefull for autocomplete tests).
For filling file input field, simply pass file path as `value`.
你可以填写form表单 Ghost.fill(selector, values, expect_loading=False):
result, resources = ghost.fill("form", {"username": "jeanphix","password": "mypassword"
})
提交表单~
page, resources = ghost.fire_on("form", "submit", expect_loading=True)
这是对于高级属性的定义:
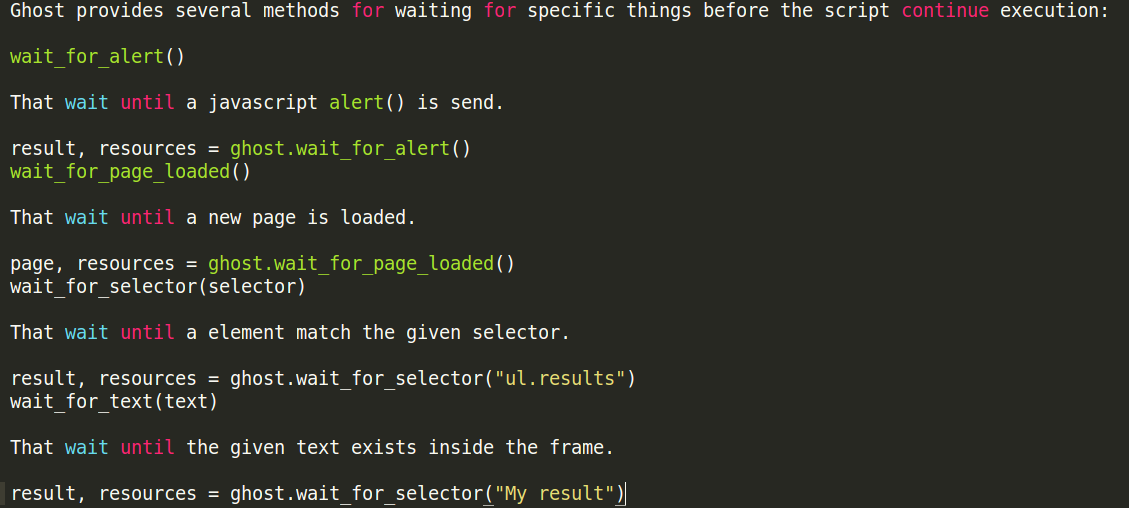
这些有很多好用的属性
wait_for_page_loaded()
That wait until a new page is loaded.
page, resources = ghost.wait_for_page_loaded()
这个是等 页面都加载完毕,类似jquery
$(document).ready(function()
wait_for_selector(selector)
That wait until a element match the given selector.
result, resources = ghost.wait_for_selector("ul.results")
等你指定的dom名称出现
wait_for_text(text)
That wait until the given text exists inside the frame.
result, resources = ghost.wait_for_selector("My result")
等我们要的字符出现
官网出现了 FlASK 的例子:
可以通过ghost.py和unittest实现程序的单元测试:
import unittest
from flask import Flask
from ghost import GhostTestCase
app = Flask(__name__)
@app.route('/')
def home():return 'hello world'
class MyTest(GhostTestCase):port = 5000@classmethoddef create_app(cls):return appdef test_open_home(self):self.ghost.open("http://localhost:%s/" % self.port)self.assertEqual(self.ghost.content, 'hello world')
if __name__ == '__main__':unittest.main()~~~整体的小demo~~~
# Opens the web page
ghost.open('http://www.openstreetmap.org/')
# Waits for form search field
ghost.wait_for_selector('input[name=query]')
# Fills the form
ghost.fill("#search_form", {'query': 'France'})
# Submits the form
ghost.fire_on("#search_form", "submit")
# Waits for results (an XHR has been called here)
ghost.wait_for_selector('#search_osm_nominatim .search_results_entry a')
# Clicks first result link
ghost.click('#search_osm_nominatim .search_results_entry:first-child a')
# Checks if map has moved to expected latitude
lat, resources = ghost.evaluate("map.center.lat")
assert float(lat.toString()) == 5860090.806537
aha,咱们来个实例哈~
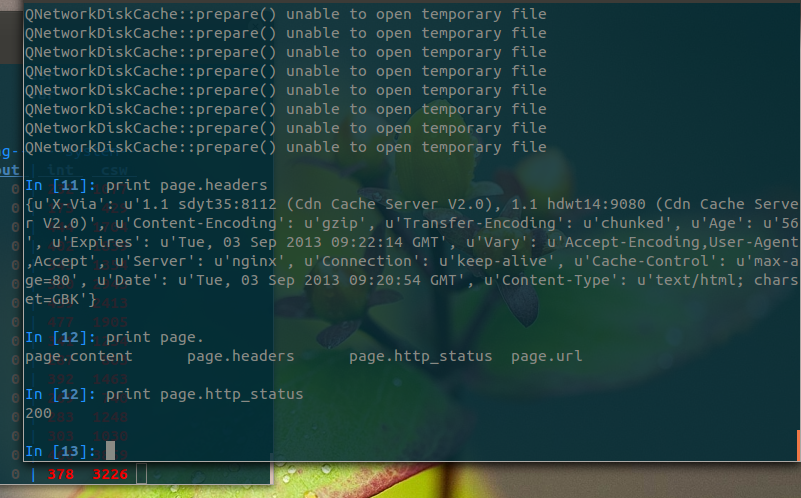
咱们来个简单的 模拟浏览器 到百度去搜 xiaorui.cc 然后看看内容和headers头 :
终端下的操作:
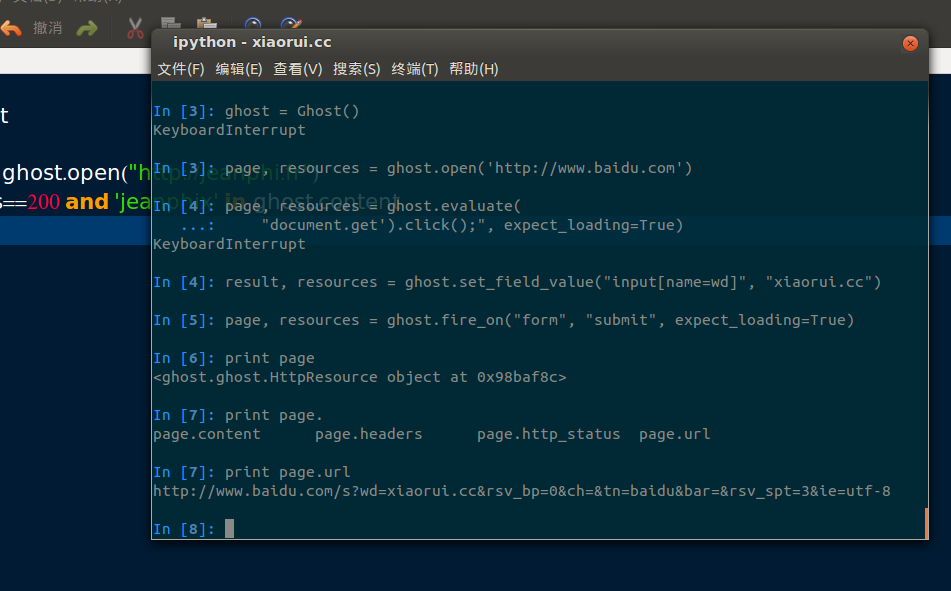
得到的是
http://www.baidu.com/s?wd=xiaorui.cc&rsv_bp=0&ch=&tn=baidu&bar=&rsv_spt=3&ie=utf-8
咱们访问下
看 他的http头
In [10]: print page.headers
{u'BDQID': u'0xf594a31a03344b4f', u'Content-Encoding': u'gzip', u'Set-Cookie': u'BDSVRTM=381; path=/\nH_PS_PSSID=2976_2981_3091; path=/; domain=.baidu.com', u'BDUSERID': u'0', u'Server': u'BWS/1.0', u'Connection': u'Keep-Alive', u'Cache-Control': u'private', u'Date': u'Tue, 03 Sep 2013 09:53:56 GMT', u'Content-Type': u'text/html;charset=utf-8', u'BDPAGETYPE': u'3'}
他的内容:

先这样吧~ 更详细的功能大家看官网吧~
转载于:https://blog.51cto.com/rfyiamcool/1287810
爬虫采集-基于webkit核心的客户端Ghost.py [爬虫实例]相关推荐
- python写爬虫4-多线程爬虫(采集58出租房信息)_python实现多线程爬虫
前言: 本文利用python语言实现了一个多线程爬虫. 正文: 开发环境: ubuntu16.04,python3.6,bs4,virtualenv(虚拟环境) 创建虚拟环境: 创建项目文件夹,并为项 ...
- python极客学院爬虫_基于requests实现极客学院课程爬虫
#coding=utf-8 __author__ = 'scaleworld' importrequestsimportreimportsys reload(sys) sys.setdefaulten ...
- 基于WebKit的网络爬虫
2019独角兽企业重金招聘Python工程师标准>>> https://github.com/emyller/webkitcrawler 一个开源的项目,可以快速入门. http:/ ...
- python爬虫常用流程_爬虫采集基本流程,python爬虫框架排行榜
爬虫其实是通过伪装数据,借用代理IP工具,并模仿用户行为实现采集信息,这爬虫采集基本流程是怎样的呢?爬虫的框架影响采集的效果,在编写爬虫之前,选择怎么样的爬虫框架好? 今天就跟智连代理小编去看看pyt ...
- 【ShoppingWebCrawler】-C#开发的基于Webkit内核开源爬虫蜘蛛引擎
概述 在各个电商平台发展日渐成熟的今天.很多时候,我们需要一些平台上的基础数据.比如:商品分类,分类下的商品详细,甚至业务订单数据.电商平台大多数提供了相应的业务接口.允许ISV接入,用来扩展自身平台 ...
- 5款实用爬虫小工具推荐(云爬虫+采集器)
目前市面上我们常见的爬虫软件大致可以划分为两大类:云爬虫和采集器(特别说明:自己开发的爬虫工具和爬虫框架除外) 云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和 ...
- 5款实用Python爬虫小工具推荐(云爬虫+采集器)
目前市面上我们常见的爬虫软件大致可以划分为两大类:云爬虫和采集器(特别说明:自己开发的爬虫工具和爬虫框架除外) 云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和 ...
- 【19】数据可视化+爬虫:基于 Echarts + Python 实现的动态实时大屏范例 - bilibili排行榜
目录 ❤️效果展示❤️ 1.首先看动态效果图 2.丰富的主题样式 一. 确定需求方案 1.确定产品上线部署的屏幕LED分辨率 2.部署方式 二.整体架构设计 三.爬虫采集关键编码实现 1.确定爬虫目标 ...
- 基于webkit内核webos系统架构
基于webkit内核webos系统架构 WebOS(Web-based Operating System)或者我们称为网络操作系统,是一种基于浏览器的虚拟的操作系统,用户通过浏览器可以在这个WebOS ...
最新文章
- 模拟京东快递单号的查询效果
- 创建第二个 local network - 每天5分钟玩转 OpenStack(84)
- 把女友升级为老婆的时候发生的BUG(转载)
- Python内置函数(57)——setattr
- java中交通灯管理系统_java案例--交通灯管理系统学习
- RHEL7.0 配置网络IP的三种方法
- org manual翻译--2.1 大纲
- 高倍数泡沫装置PHP_泡沫灭火系统,了解这几点就好
- extjs Grid (二)
- 【数据库】sql连表查询
- [STM32]Cubemx+USBAudio声卡+I2S+DMA+WM8978实验记录(未解决)
- 答复: 关于用异常控制程序流程的看法
- 百度翻译API教程(完整Android代码)
- nosqlbooster 延长试用日期
- android fresco的底层,Fresco源码分析之DraweeView
- zigbee菜鸟笔记(一)zigbee的基础知识
- 醋泡三宝可以吃出长寿
- 网络广播mms直播地址
- P1287 盒子与球
- Python 爬取携程所有机票